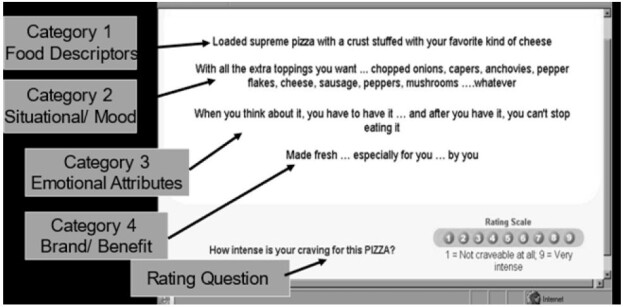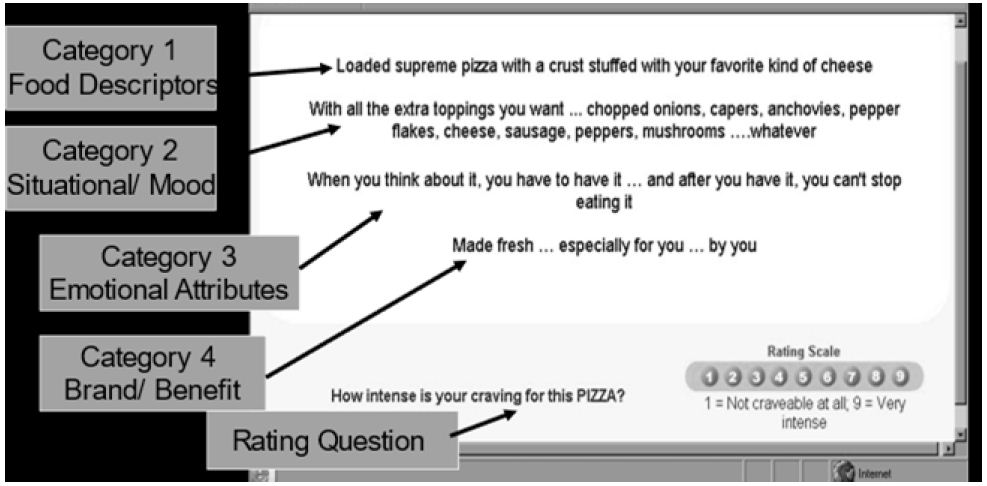
Abstract
Arizona’s COVID-19 Reopening Phase 3 began on March 5, 2021. It is the sixth largest in size of the United States 50 states about the same size as Italy. There were declines in the weekly COVID-19 cases during the spring and early summer. There were three case surges — in the summer and fall with Delta variant and the winter with Omicron variant. This one-year longitudinal study examined changes in the number of new COVID-19 cases, hospitalized cases, deaths, vaccinations, and COVID-19 tests. There was an increase of more than one million cases during the study period. The data source used was from the Arizona Department of Health Services COVID-19 dashboard database. Even with the case surges, the new normal was low number of severe cases, manageable hospitalization numbers, and low number of deaths
Keywords
COVID-19; Arizona returning to normal; Longitudinal study; Arizona and COVID-19
Introduction
On March 9, 2022, Johns Hopkins University reports that there are 451,611,588 total COVID-19 cases and 6,022,199 deaths associated with the virus in the world. The United States has the highest total cases (79,406,602) and deaths (963,819) in the world [1]. COVID-19 (coronavirus) is a respiratory disease (attacks primarily the lungs) that spreads by person to person through respiratory droplets (coughs, sneezes, and talks) and contaminated surfaces or objects.
The world combats the virus with vaccines and therapeutics as well as encourages the public to practice preventive health behaviors that reduce the risks of getting respiratory infections (e.g., coronavirus, flu, and cold). The behaviors include, but not limited to, practicing physical and social distancing, washing hands frequently and thoroughly, and wearing face masks. Johns Hopkins reports that more than 10.63 billion vaccine doses administered in the world (March 9) [1]. The United States (U.S.) ranks third in the world in vaccine doses administered following China and India [1].
Of the 50 U.S. states, Arizona is ranked 13th in total COVID-19 cases (1,980,769) and 11th in total deaths (28,090) on March 9 [1]. During Arizona’s Reopening Phase 2 winter surge, ABC and NBC News report that the state has the highest new cases per capital in the world [2,3]. Arizona is the sixth largest in size (113,990 square miles / 295,233 square kilometers) of the U.S. 50 states [4]. It is about the same size as Italy (301,340 square kilometer) [5]. The state population estimate is 7,276,316 on July 1, 2021 [6].
The United States requires a partnership between the federal government and each of the 50 states to address the COVID-19 pandemic [7]. The federal government provides the national guidance and needed logistical support (e.g., provide federal supplemental funding, needed medical personnel and resources, and other needed assistance), while the states decide on what actions to take and when to carry out those actions; the state COVID-19 restrictions; and when to carry out each reopening phase; and the state vaccination plan.
On March 5, 2021, Arizona Governor Douglas Ducey begin Reopening Phase 3 after the state had administered more than two million vaccine doses and several weeks of declining cases [8,9]. This begins the next phase of easing of COVID-19 restrictions. As more people become vaccinated and those infected recovered and have immunity against the virus; the numbers of cases, hospitalizations, and deaths will be low; COVID-19 will be manageable; and the state will be able to return to normal.
To get back to normal, the state needs to reach high enough population immunity to reduce the ease of the virus transmission (herd immunity level). The remainder of the paper examined Arizona Reopening Phase 3 (March 5, 2021 to March 9, 2022) looking at changes in the number of new COVID-19 cases, hospitalizations, and deaths.
Methods
This was a one-year longitudinal study. It examined the changes in the numbers of new COVID-19 cases, hospitalized cases, deaths, vaccines administered, and tests given. The data source for the study was from the Arizona Department of Health Services (the state health department) COVID-19 dashboard database.
There were several data limitations. The COVID-19 case numbers represented the numbers of positive tests reported. When more than one test given to the same person (e.g., during hospitalization, at work, and mandatory testing), there were individual case duplications. Aggressive testing resulted in increases in false positive and false negative testing results. There were delays in the data submitted daily to the state health department that affected the timeliness of data reported and caused fluctuations in the number of cases, hospitalizations, deaths, and vaccinations. The state health department continued to adjust the reported numbers that may take more than a month to correct the numbers. The deaths associated with the coronavirus may cause by more than one serious underlying medical condition, and the virus may not be the primary cause of death.
Results
A case could be mild (no symptoms), moderate (sick, but can recover at home), and severe (require hospitalization and/or result in death). There were three case surges during the Reopening Phase 3: summers, fall, and winters (Figure 1). Unlike 2020 summer and winter surges, there was no significant decline in cases during the 2021 summer, fall, and winter surges. The 2022 winter surge peak was twice as high as 2020-21 winters. Figure 1 shows the Arizona weekly COVID-19 cases during January 1, 2020 to March 6, 2022.
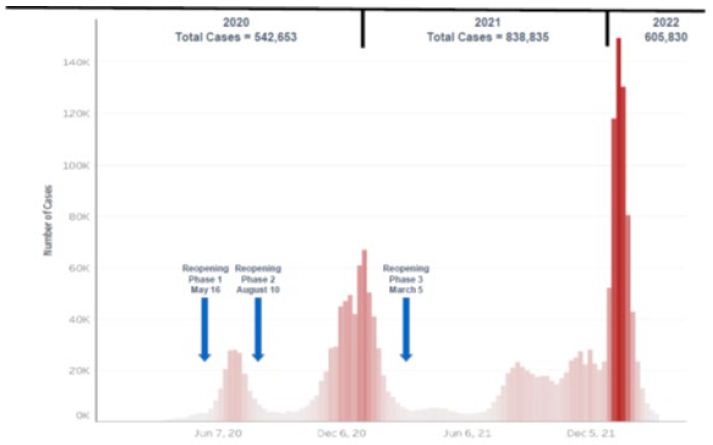
Figure 1: Arizona Reopening Phases 1-3 Weekly COVID-19 Cases: January 1, 2020 to March 6, 2022.
Source: Arizona Department of Health Services Arizona COVID-19 Weekly Case Graph.
At the end of the first year of Arizona Reopening Phase 3 (March, 9, 2021), there were 1,162,199 COVID-19 cases, 49,894 case hospitalizations, and 11,767 deaths associated with the virus in Arizona (Table 1). There were more cases, hospitalizations, and deaths in the second half of the year than the first half, but the percent of hospitalizations and deaths for those diagnosed with COVID-19 were lower in the second half.
Table 1: Arizona Reopening Phase 3 Total Numbers of COVID-19 Cases, Hospitalizations, and Deaths: March 7, 2021 to March 9, 2022.
|
Time Period |
Cases | Hospitalizations |
Deaths |
| March 7, 2021 to September 4, 2021 |
202,240 |
14,859
(7.35%) |
2,674 (1.32%) |
| September 5, 2021 to March 9, 2022 |
959,959 |
35,035
(3.65%) |
9,093 (0.95%) |
| March 7, 2021 to March 9, 2022 |
1,162,199 |
49,894 |
11,767 |
Source: Arizona Department of Health Services COVID-19 Dashboard.
Arizona 2021 population estimate is 7,276,316, July 1, 2021 – U.S. Census.
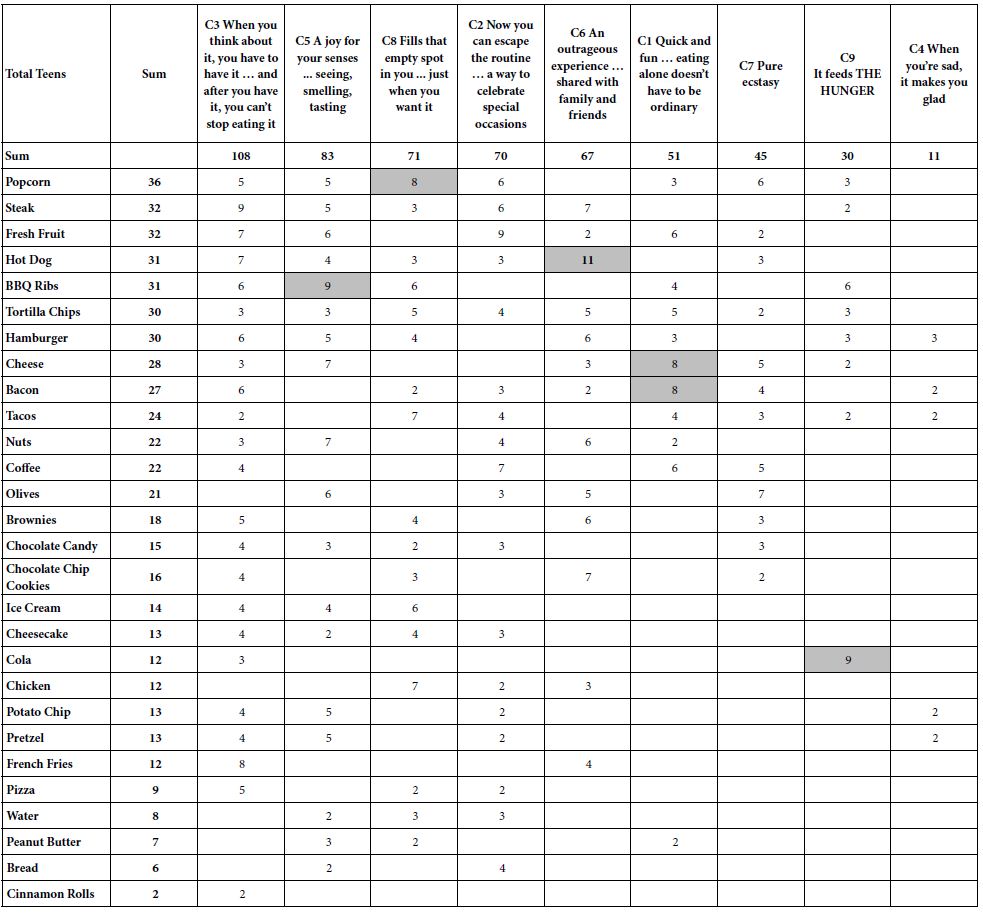
Tables 2 and 3 track tri-weekly total and weekly numbers of COVID-19 cases, hospitalized cases, deaths, fully vaccinated individuals, and test given. The largest numbers of cases (141,475) and hospitalizations (3,514) occurred in the week of January 16 to 22, 2022, while the largest weekly number of deaths occurred in week of January 23 to 29 (626).
Table 2: Arizona Reopening Phase 3 Tri-Weekly State Total and Weekly Numbers of COVID-19 Cases, Hospitalizations, and Deaths: February 28, 2021 to February 26, 2022.
|
Week |
Total Cases | Wk. Case | Total Hospital | Wk. Hospital | Total Deaths |
Wk. Deaths |
| 02-28 to 03-06 |
825,119 |
9,412 | 57,863 | 355 | 16,323 |
356 |
| 03-21 to 03-27 |
839,334 |
3,569 | 58,912 | 242 | 16,912 |
179 |
| 04-11 to 04-17 |
853,050 |
4,029 | 59,604 | 282 | 17,151 |
59 |
| 05-02 to 05-08 |
868,382 |
4,811 | 60,700 | 369 | 17,407 |
69 |
| 05-23 to 05-29 |
880,466 |
4,055 | 61,651 | 377 | 17,628 |
81 |
| 06-13 to 06-19 |
889,342 |
2,938 | 62,518 | 305 | 17,838 |
77 |
| 07-04 to 07-10 |
900,636 |
4,118 | 65,951 | 273 | 18,029 |
54 |
| 07-25 to 07-31 |
927,235 |
11,575 | 67,191 | 608 | 18,246 |
76 |
| 08-15 to 08-21 |
982,775 |
20,365 | 70,143 | 1,220 | 18,597 |
135 |
| 09-05 to 09-11 |
1,045,835 |
18,476 | 74,501 | 1,779 | 19,183 |
186 |
| 09-26 to 10-02 |
1,100,167 |
18,377 | 77,411 | 688 | 20,134 |
328 |
| 10-17 to 10-23 |
1,148,341 |
16,365 | 79,295 | 628 | 20,851 |
351 |
| 11-07 to 11-13 |
1,211,333 |
24,856 | 81,600 | 848 | 21,651 |
243 |
| 11-28 to 12-04 |
1,288,234 |
25,660 | 87,517 | 2,363 | 22,561 |
337 |
| 12-19 to 12-25 |
1,354,708 |
20,647 | 90,300 | 774 | 23,983 |
467 |
| 01-09 to 01-15 |
1,588,155 |
126,522 | 96,160 | 1,993 | 25,171 |
467 |
| 01-30 to 02-05 |
1,911,655 |
66,743 | 103,031 | 1,416 | 26,628 | 445 |
| 02-20 to 02-26 |
1,976,890 |
11,231 | 106,496 | 436 | 27,946 | 328 |
Source: Arizona Department of Health Services Coronavirus Database.
Arizona 2021 population estimate is 7,276,316, July 1, 2021 – U.S. Census.
Table 3: Arizona Reopening Phase 3 Tri-Weekly State Total and Weekly Numbers of Fully Vaccinated Persons and COVID-19 Testing: February 27, 2021 to February 26, 2022.
|
Week |
Total Vaccine | Week Vaccine | Week | Total Testing |
Week Testing |
| 02-27 to 03-05 |
711,074 |
214,577 | 02-28 to 03-06 | 4,271,425 |
85,839 |
| 03-20 to 03-26 |
1,211,279 |
136,567 | 03-21 to 03-27 | 4,473,079 |
51,621 |
| 04-10 to 04-16 |
1,812,090 |
197,061 | 04-11 to 04-17 | 4,630,490 |
51,273 |
| 05-01 to 05-07 |
2,416,859 |
144,358 | 05-02 to 05-08 | 4,783,625 |
50,407 |
| 05-22 to 05-28 |
2,759,177 |
60,481 | 05-23 to 05-29 | 4,921,306 |
45,655 |
| 06-12 to 06-18 |
3,041,625 |
85,694 | 06-13 to 06-19 | 5,039,927 |
38,162 |
| 07-03 to 07-09 |
3,192,966 |
37,218 | 07-04 to 07-10 | 5,144,503 |
31,929 |
| 07-24 to 07-30 |
3,341,364 |
28,211 | 07-25 to 07-31 | 5,273,201 |
51,388 |
| 08-14 to 08-20 |
3,451,880 |
44,584 | 08-15 to 08-21 | 5,516,055 |
97,680 |
| 09-04 to 09-10 |
3,588,303 |
32,433 | 09-05 to 09-11 | 5,796,559 |
76,540 |
| 09-25 to 10-01 |
3,703,834 |
38,345 | 09-26 to 10-02 | 6,029,558 |
76,008 |
| 10-16 to 10-22 |
3,675,384 |
10,300 | 10-17 to 10-23 | 13,422,057 |
200.955 |
| 11-06 to 11-12 |
3,820,202 |
22,862 | 11-07 to 11-13 | 14,098,439 |
248,598 |
| 11-27 to 12-03 |
3,883,284 |
23,029 | 11-28 to 12-04 | 14,767,374 |
222,428 |
| 12-18 to 12-24 |
3,940,418 |
17,536 | 12-19 to 12-25 | 15,447,386 |
233,443 |
| 01-08 to 01-14 |
4,005,295 |
28,316 | 01-09 to 01-15 | 16,459,838 |
468,734 |
| 01-29 to 02-04 |
4,196,274 |
144,853 | 01-30 to 02-05 | 17,701,703 |
338,584 |
| 02-19 to 02-25 |
4,284,855 |
30,044 | 02-20 to 02-26 | 18,277,270 |
151,628 |
Source: Arizona Department of Health Services Coronavirus Database.
Arizona 2021 population estimate is 7,276,316, July 1, 2021 – U.S. Census.
During the year, there were increases in the numbers of fully vaccinated individuals – 3,605,435 (March 6, 2021 to March 9, 2022) and testing – 14,190,759 (March 7, 2021 to March 9, 2022). The largest numbers of fully vaccinated person occurred in the week of April 17 to 23, 2021 (249,755). The week of January 15 to 21, 2022 had the largest weekly numbers of tests done (492,774).
Figures 2-4 compare the numbers of COVID-19 cases, hospitalized cases, and deaths by age groups on March 6, 2021 and March 9, 2022. A case could be mild, moderate, and severe. Most people recovered and did not require hospitalization. There was an increase of 1,162,199 cases during the study period. The 20-44 years age group had the largest number of cases and had an increase of 480,268 (Figure 2). There were more females (52.4%) than males (47.6%) who got the virus on March 9, 2022.
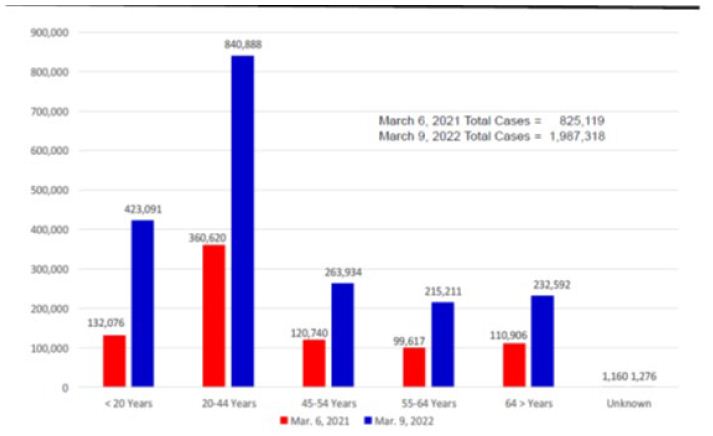
Figure 2: Arizona Reopening Phases 3 COVID-19 Cases by Age Groups on March 6, 2021 and March 9, 2022.
Source: Arizona Department of Health Services COVID-19 Cases by Age Groups Statistics.
The percentages of total hospitalized cases (severe cases) decrease from 7 percent on March 6, 2021 to 5 percent on March 9, 2022. The case hospitalizations had increased from 57,863 to 107,757. As expected, seniors had the highest numbers of the total hospitalizations (42.5% on March 9) and those under 20 years of age had the lowest numbers (4.4%). Twenty percent (19.7%) of seniors diagnosed with COVID-19 hospitalized, while 1.1 percent of those less than 20 years of age hospitalized. There were more males (52.3%) than females (47.7%) hospitalized. Figure 3 shows the hospitalization numbers for each age group with the virus on March 6 and March 9.
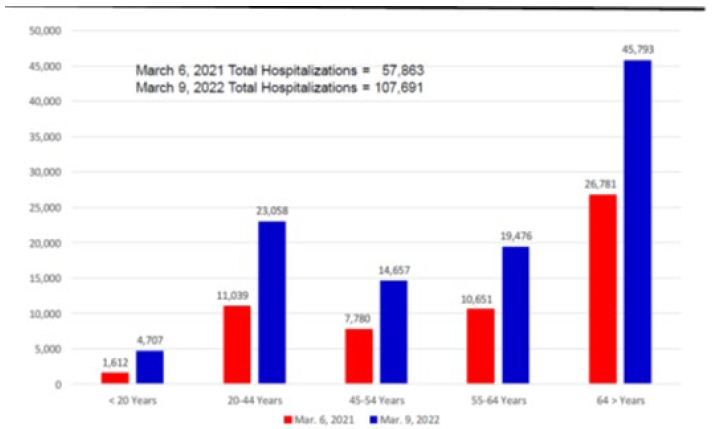
Figure 3: Arizona Reopening Phases 3 Hospitalized COVID-19 Cases by Age Groups on March 6, 2021 and March 9, 2022.
Source: Arizona Department of Health Services Hospitalized COVID-19 Cases by Age Groups Statistic.
The numbers of deaths had increased from 16,323 on March 6 to 28,090 on March 9. The rates of fatalities per 100,000 population increased 227.05 to 390.70. As expected, seniors had the highest numbers of total deaths (70.5% on March 9) and those under 20 years of age had the lowest numbers — 0.2% (Figure 4). Eight percent (8.5%) of the seniors diagnosed with COVID-19 died, while 0.01 percent of those under 20 years of age died. There were more males (59%) than females (41%) who died.
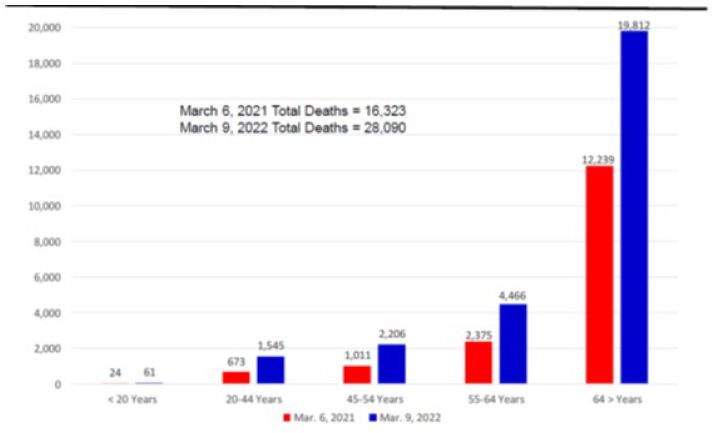
Figure 4: Arizona Reopening Phases 3 Weekly COVID-19 Deaths by Age Groups on March 6, 2021 and March 9, 2022.
Source: Arizona Department of Health Services COVID-19 Deaths by Age Groups Statistics.
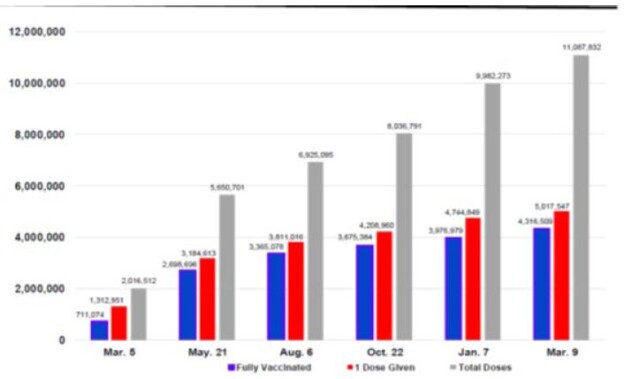
The first U.S. COVID-19 vaccine, Pfizer/BioNTech, approved for emergency use authorization on December 11, 2020. In late December, Arizona began to administer vaccines. During Reopening Phase 3 (March 5, 2021 to March 9, 2022), there were 9,071,320 vaccine doses administered, and 3,605,435 fully vaccinated against the virus. Three vaccines were available in Arizona (Pfizer/BioNTech, Moderna, and Johnson & Johnson). The vaccines provided different levels of protection against COVID-19 and its variants. The vaccination percentages of those who had received at least one dose by five age groups were less than 20 years — 33.7%; 20-44 years — 65.0%; 45-54 years — 73.2%; 55-64 years – 79.8%; and 65 years and older — 97.2% on March 9. Figure 5 shows the numbers of COVID-19 vaccines given in Arizona (total doses given, persons receiving at least 1 dose, and persons fully vaccinated) during Reopening Phase 3.
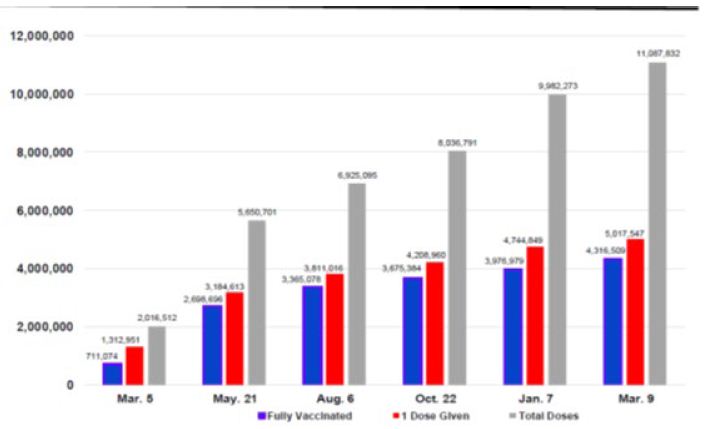
Figure 5: Arizona Reopening Phases 3 COVID-19 Vaccination Numbers: March 5, 2021 to March 9, 2022*.
Source: Arizona Department of Health Services COVID-19 Testing Statistics.
*Dates reported at 6-week intervals. Time period between February 5 and March 9 is 4½ weeks.
The number of COVID-19 tests done in Arizona had increased by 14,190,759 from March 6, 2021 to March 9, 2022 (Figure 6). On March 9, there were 18,462,184 total tests done.
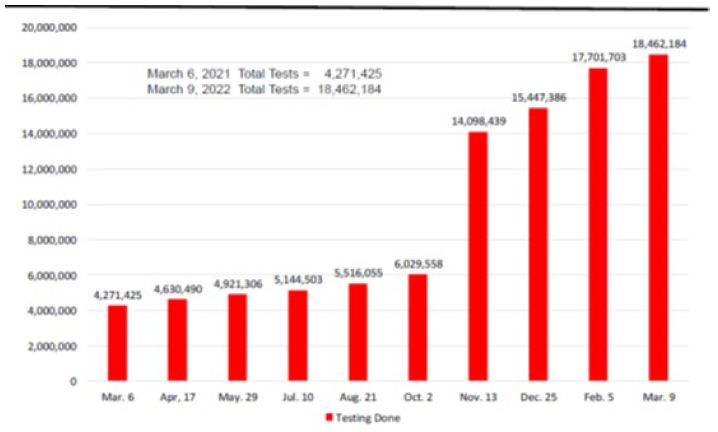
Figure 6: Arizona Reopening Phases 3 COVID-19 Testing Numbers: March 6, 2021 and March 9, 2022*.
Source: Arizona Department of Health Services COVID-19 Testing Statistics.
*Dates reported at 6-week intervals. Time period between February 5 and March 9 is 4½ weeks.
Discussion
The United States declared the COVID-19 pandemic as a national emergency on March 13, 2020 [10-12]. Since then, almost two years later, there had been 1,987,318 COVID-19 cases, 107,757 case hospitalizations, 28,090 deaths associated with the virus, and 11,087,832 vaccine doses administered in Arizona (March 9, 2022). More than 1 million new cases occurred during the Reopening Phase 3.
On March 5, 2021, the Arizona Governor began Reopening Phase 3 after the state had administered more than two million vaccine doses and several weeks of declining cases [8,9]. The state continued its efforts to vaccinate its population. The number of vaccine dosages administered had increase from 2,016,512 on March 5, 2021 to 11,087,832 on March 9, 2022. Fifty-nine percent (4,316,509) of the state population were fully vaccinated. The largest numbers of fully vaccinated persons occurred in the week of April 17 to 23, 2021 (249,755). The pace of vaccination began to slow down in June.
Arizona case numbers had decreased in the spring and early summer. At the end of June, the Arizona State Legislature and Governor had rescinded many of the state COVID-19 restrictions. During the month of July, the highly contagious Delta variant appeared in the state and began the summer surge.
The state and locate health departments increased their vaccination efforts as the Delta variant rose. The number of vaccination sites expanded throughout the state that included pharmacy chains, doctor offices, and community centers and clinics. The state targeted vaccination efforts to hard-to-reach minority and rural communities. The local governments, schools and universities, and private employers acted on their own to address the virus increases.
Even with the increase vaccination efforts and other actions, they were not enough to stop the Delta variant. The easing of the COVID-19 restrictions (e.g., those working at home returning to their workplaces, children and college students returning to in person classroom learning, and fans attending sport and entertainment events) made it easier for the virus to spread. This resulted in the fall surge and the case remained high in November. In December, the Omicron variant appeared in the state and surge in January and the cases remained high into early March. The Centers for Disease Control and Prevention (CDC) changed the COVID-19 transmission risk level for most of the state from high to medium on March 3. Medium transmission is 10 to 50 cases per 100,000 people or a positive rate between 5 and 8 percent for seven days.
There were many factors that contribute to the increase of cases. The Omicron variant was more contagious than the Delta variant. Even through 4,316,509 were fully vaccinated, there were significant number of state residents not vaccinated (40.8% as of March 9). Some of these unvaccinated had acquired natural immunity. Most of new cases were unvaccinated individuals. There were breakthrough infections of fully vaccinated or/and those received booster shots. Many who believe Omicron variant is a mild virus decided not to adhere to the preventive health protocols. Aggressive COVID-19 testing resulted in high number of identified cases. There was influx of out-of-state visitors (e.g., snowbirds and those attending Arizona events from out of state) who had or exposed to the virus.
Even though the case numbers rose, the numbers of hospitalizations and deaths were low because of COVID-19 vaccines and therapeutic drugs. The number of severe cases was low because significant numbers of the high-risk individuals and elderly vaccinated. On March 9, there were 97.2 percent of adults 65 and older had received 1 or 2 COVID-19 vaccine shots. There were several drugs approved by the FDA for treating COVID-19 (e.g., remdesivir, nirmatrelvir/ritonavir and molnupiavir) that reduced hospital length of stay and deaths.
Conclusion
The three vaccines and therapeutics kept the number of hospitalizations and deaths low. Even with the occasion case surges, the state normal were low number of severe cases, manageable hospitalization numbers, and low number of deaths.
References
- Johns Hopkins University Coronavirus Resource Center, https://coronavirus.jhu.edu/.
- Deliso Meredith (2021) “Arizona ‘hottest hot spot’ for COVID-19 as health officials warn of hospital strain: The state has the highest infections per capita globally, based on JHU data, ABC News. 2021. https://abcnews.go.com/US/arizona-hottest-hot-spot-covid-19-health-officials/story?id=75062175.
- Chow Denise, Joe Murphy (2021) These three states have the worst Covid infection rates of anywhere in the world: Arizona currently has the highest per capita rate of new Covid-19 infections, with 785 cases per 100,000 people over the past seven days, followed closely by California and Rhode Island, NBC News. https://www.nbcnews.com/science/science-news/these-three-states-have-worst-covid-infection-rates-anywhere-world-n1252861.
- Britannica, Arizona state, United States, https://www.britannica.com/place/Arizona-state.
- My Life Elsewhere, Arizona is around the same size as Italy.
- https://www.mylifeelsewhere.com/country-size-comparison/arizona-usa/italy.
- United States Census Bureau, Quick Facts, https://www.census.gov/quickfacts/AZ.
- Eng H (2020) Arizona and COVID-19. Medical & Clinical Research 5: 175-178.
- Eng H (2021) Arizona Reopening Phase 2: Rise and Fall of COVID-19 Cases. Medical & Clinical Research 6: 114-118.
- Eng H (2021) Arizona Reopening Phase 3 and COVID-19: Returning to Normal. Medical & Clinical Research 6: 687-669.
- White House Proclamation on Declaring a National Emergency Concerning the Novel Coronavirus Disease (COVID-19) Outbreak. 2020.
- https://www.whitehouse.gov/presidential-actions/proclamation-declaring-national-emergency-concerning-novel-coronavirus-disease-covid-19-outbreak/.