Abstract
Background/objective: Optimal blood pressure parameters for patients that undergo successful mechanical thrombectomy (MT) are not clearly defined. Our study sought to investigate the relationship of blood pressure variability on clinical outcomes after successful revascularization and determine optimal thresholds for BP parameters that correlate with a poor functional outcome.
Keywords
Mechanical thrombectomy, Stroke, Blood pressure, Variability, Risk score
Introduction
Intravenous (IV) thrombolysis and endovascular therapy with mechanical thrombectomy (MT) increase functional independence, improve mortality and are standard of care in patients with acute ischemic stroke (AIS) due to large vessel occlusion (LVO) [1-3]. While these advancements have revolutionized stroke care, optimal blood pressure management following successful MT has yet to be definitively determined. Hypertension and impairment of cerebral autoregulation are common after AIS, and procedural management can predispose patients to blood pressure variability, including hypotension [4-6]. If cerebral autoregulation is impaired, small fluctuations in blood pressure may result in excessive changes in cerebral blood flow and contribute to secondary brain injury (SBI) [7].
To date there are no randomized controlled trial data regarding blood pressure management after successful MT, resulting in heterogeneity in post MT management [8]. Most institutions have adopted target values of Systolic Blood Pressure (SBP) less than 180, extrapolated from retrospective studies, thrombolysis trials and post-tPA guidelines [1,2,8-10]. Allowance of SBP of up to 180/105 by the American Heart Association/American Stroke Association is largely based on the assumption that increasing cerebral perfusion pressure to an ischemic area may curtail further ischemia or infarction. However, these BP recommendations were made based on sustained revascularization rates from tPA of under 40%, and does not take into consideration the effect of higher recanalization rates from MT of 70-80% [11-13]. After successful revascularization, there is a concern of reperfusion-related hemorrhagic transformation (HT), therefore lower BP goals have been suggested, for instance the DAWN trial investigators used SBP<140 for 24 hours post-MT in these patients [14].
Many studies focus on maximum values of BP parameters, even though BP variability may also play an important role in functional outcomes in patients receiving MT [13,15,16]. Recent studies show that blood pressure reductions before and/or during MT [17-19] as well as blood pressure increases and fluctuations following MT [13,16] are associated with worse outcomes [15,16]. These variable conclusions highlight the complexity of BP management after MT and suggest that perhaps blood pressure management should be tailored to patient physiology such as autoregulatory capacity, phase of injury and success of the intervention. We aimed to study if acute blood pressure variability, rather than absolute parameters affected functional outcome after successful revascularization. We hypothesized that a higher BP variability after successful MT would correlate with poor functional outcomes and sought to determine optimal BP cutoffs that correlated with poor outcome. In addition, our goal was to develop an individualized risk score to predict a patient’s functional outcome 90 days after successful revascularization based on their post-MT BP parameters and demographics.
Methods
Study Design and Patient Selection
We conducted a retrospective observational study on a consecutive sample of 314 AIS patients between January 2015 and December 2017 at the only tertiary medical center in the state of West Virginia. Of 314 patients that were reviewed, 107 patients underwent MT for LVO. LVO was defined as a proximal middle cerebral artery (M1, M2), terminal intracranial internal carotid artery (ICA) occlusion, or tandem occlusions. Tandem occlusions were defined as simultaneous extracranial cervical ICA critical stenosis or complete occlusion with concomitant large vessel intracranial occlusion. Posterior circulation occlusions were excluded from this analysis. Out of 107 patients, 20 were excluded due to unsuccessful recanalization. Success of recanalization was quantified using the Thrombolysis in Cerebral Infarction (TICI) score, categorized as unsuccessful for TICI 0, 1, 2a and successful for TICI 2b, 2c and 3. Of the 87 patients who had successful MT, 44 received tPA. IV tPA was not given if they met our institutional tPA exclusion criteria, and the most common reason it was withheld in our population was due to being outside of the tPA window. The study was approved by the Institutional Review Board of West Virginia University and the need for informed consent was waived.
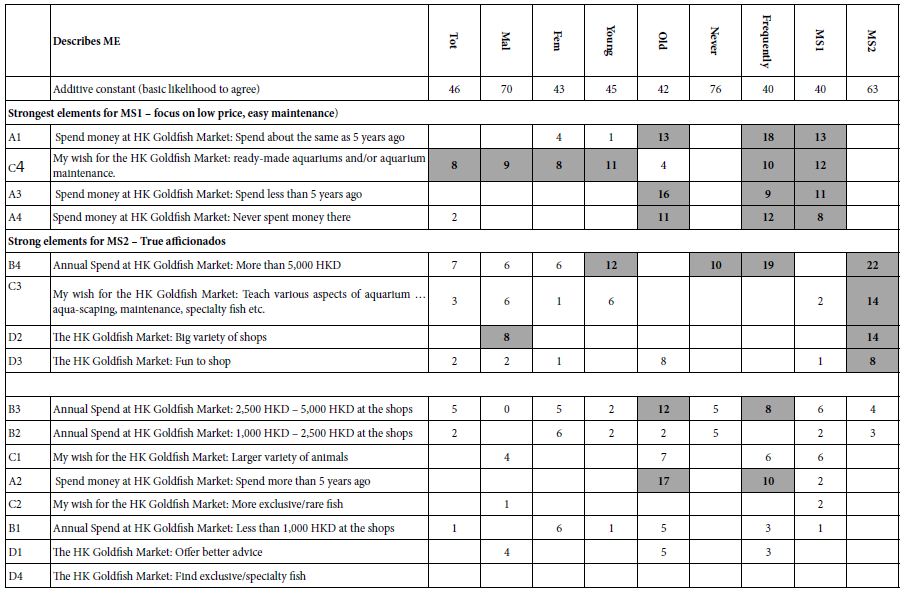
Patients’ baseline characteristics and demographics including age, gender, National Institutes of Health Stroke Scale (NIHSS) at admission and BP values, were collected and included in our data analysis. SBP, diastolic blood pressure (DBP) and Mean arterial Pressure (MAP) values were measured and recorded at least once every hour for the first 24 hours following MT as standard of care. These demographics are displayed in Table 1, which demonstrates baseline demographics of the cohort, stratified by outcome.
Table 1: Baseline Characteristics of Sample Population, displayed by event outcome.
|
Outcome |
Poor MRS at 90 days | Death at 90 days |
HT |
|||
|
Variable |
No (n = 45) | Yes (n = 33) | No (n = 60) | Yes (n = 18) | No (n = 54) | Yes (n = 33) |
| Age | 65.3 (15.9) | 74.0 (11.3) | 67.5 (15.9) | 74.1 (8.0) | 70.8 (13.9) |
63.3 (17.9) |
|
NIHSS |
12.8 (7.9) | 18.3 (7.6) | 14.4 (8.4) | 17.5 (7.1) | 15.1 (8.9) | 15.6 (7.1) |
| Female | 19 (42.2%) | 19 (57.6%) | 29 (48.3%) | 9 (50.0%) | 30 (55.6%) |
13 (39.4%) |
|
Male |
26 (57.8%) | 14 (42.4%) | 31 (51.7%) | 9 (50.0%) | 24 (44.4%) | 20 (60.6%) |
| SBP Mean | 122.9 (13.1) | 126.1 (11.9) | 122.9 (13.0) | 128.7 (10.5) | 123.4 (13.8) |
125.3 (9.3) |
|
SBP SD |
13.0 (4.2) | 15.6 (4.5) | 13.5 (4.3) | 16.0 (4.8) | 14.2 (4.8) | 13.3 (3.6) |
| SBP Range | 55.2 (17.3) | 67.6 (20.0) | 58.2 (19.1) | 68.1 (18.9) | 60.8 (21.2) |
56.9 (15.2) |
|
DBP Mean |
64.4 (10.0) | 63.4 (10.1) | 63.5 (9.8) | 65.7 (10.8) | 62.8 (10.6) | 67.4 (9.2) |
| DBP SD | 11.0 (4.2) | 12.4 (4.3) | 11.4 (4.4) | 12.3 (3.9) | 12.1 (4.5) |
10.4 (3.3) |
|
DBP Range |
50.2 (21.7) | 58.1 (20.0) | 51.9 (21.7) | 58.8 (19.2) | 55.0 (21.5) | 49.0 (19.5) |
| MAP Mean | 83.9 (9.1) | 84.3 (9.4) | 83.3 (9.1) | 86.7 (9.2) | 83.0 (9.7) |
86.7 (7.5) |
|
MAP SD |
10.1 (3.1) | 11.4 (3.3) | 10.4 (3.1) | 11.5 (3.4) | 11.0 (3.5) | 9.8 (2.5) |
| MAP Range | 44.8 (15.6) | 52.2 (17.6) | 46.5 (16.4) | 52.4 (17.6) | 49.1 (17.7) |
44.1 (14.5) |
HT, Hemorrhagic Transformation; DBP, diastolic blood pressure; MAP, mean arterial pressure; SBP, systolic blood pressure, Min, Minimum; Max, Maximum; SD, Standard Deviation. Values are reported as mean (sd), n (%). Nine subjects removed from Poor MRS and Death due to missing MRS score.
BP was measured using arterial lines, or if unavailable, non-invasive BP cuffs. Maximum, minimum, ranges and standard deviation (SD) of SBP, DBP and MAP values during this 24-hour period were extracted or calculated. Additional data that was collected for each patient included stroke etiology, stroke risk factors, NIHSS at time of discharge, mRS at 90days, death at 90 days, and presence of any HT. MRS at discharge, death at discharge and symptomatic HT, which we defined as evidence of HT on neuro-imaging in conjunction with NIHSS increase ≥4 were initially recorded but excluded from analysis given the few number of events in our small sample size. Choice of procedural anesthesia as well as a device for MT were chosen by the Neuro-interventionalist.
Outcome Definition
Primary outcomes of this study were to determine if absolute values and variability of SBP, DBP, MAP, when modeled separately and together, were associated with poor functional outcomes. Functional outcomes were measured as poor mRS (MRS 3-6) and mortality rates at 90days. Secondary outcomes of this study included HT during admission.
Statistical Analysis
Logistic regression was used to model the outcomes of interest, which were stratified into binary outcomes. Associations between the predictors and outcome variables were explored using both ULR and MLR analyses. Optimum cutoffs of variables of interest were identified based on known prevalence of these outcomes for poor functional outcomes of interest. We used the same set of predictors in Table 1 for conducting both analyses. Continuous variables were reported using descriptive methods with measures of central tendency (mean, median), and variability (standard deviation) based on the normality of the distribution. Categorical variables were reported using proportions and percentages. We used Akaike Information Criterion (AIC) for selecting which predictors to include in an optimal multivariate model. Predictors without a table entry were not selected by the stepwise AIC algorithm. Demographic variables that were not selected in the stepwise procedure were added to results of the logistic regression model and the logistic regressions were re-run to create a final multivariate regression model. Receiver Operating Characteristic (ROC) analysis was performed for poor functional outcomes of interest to determine the overall highest average area under the curve (AUC) for both analyses. Statistical analysis and graphical representations were performed using R statistical programming environment (Version 4.1.0). We used 95% Confidence Intervals (CI) to express statistical results with a two-sided significance level of 0.05. Study design and all statistical analyses were conducted in consultation with a professional biostatistician.
Results
A total of 87 patients met our inclusion criteria. The baseline characteristics of the sample population are shown in Table 1.
Univariate Association of Blood Pressure Parameters and Poor Functional Neurologic Outcome after MT
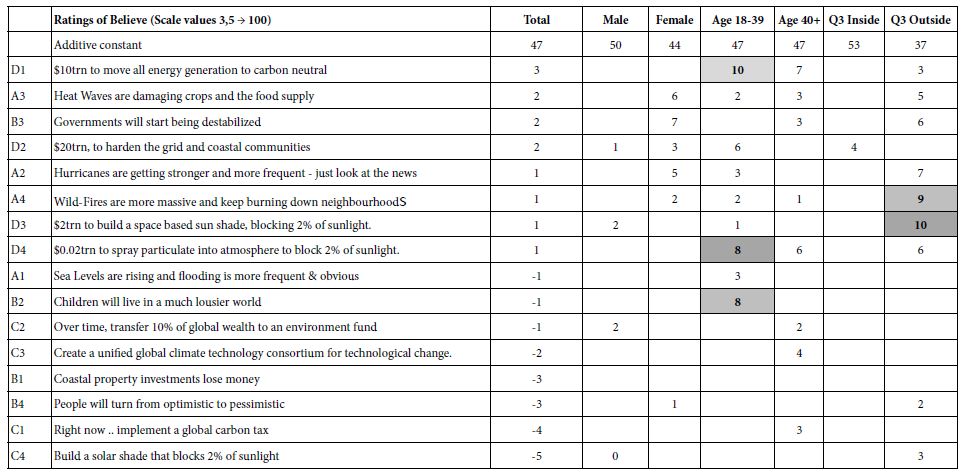
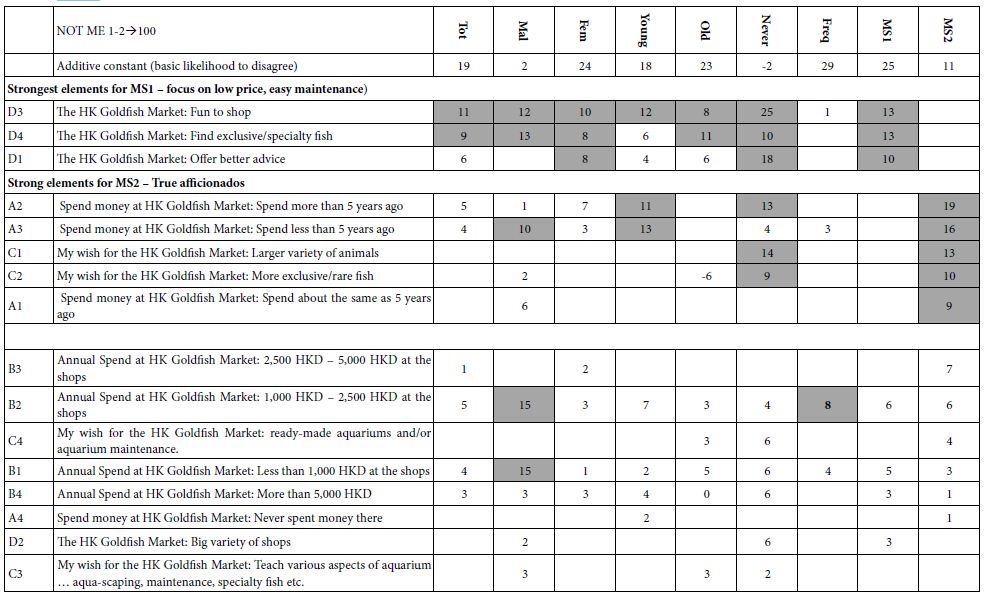
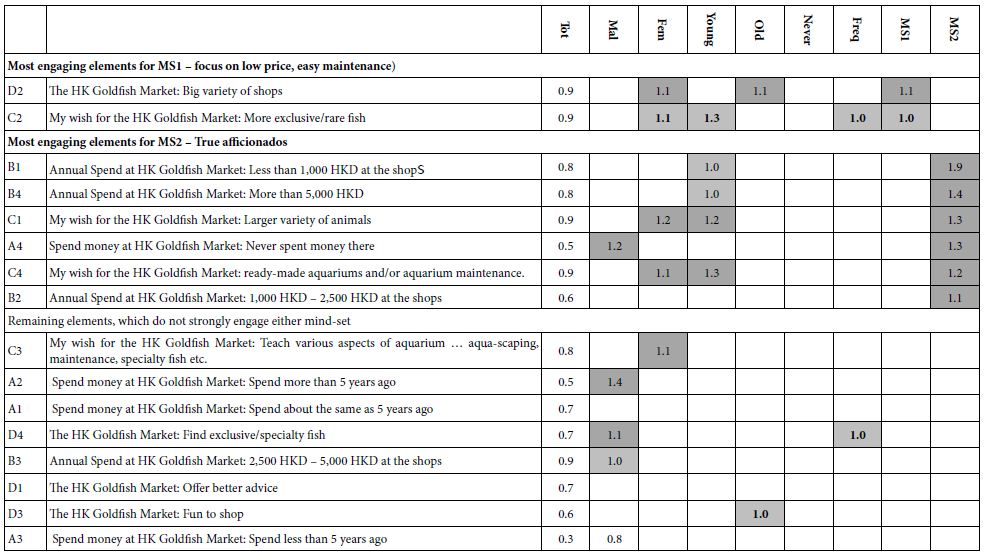
Our univariate logistic regression (ULR) analysis, shown in Table 2, demonstrated that of the variables of interest, age, NIHSS, SBP SD, SBP range and DBP mean were found to significantly correlate with poor outcome measures. A higher SD of SBP from the mean (OR=1.150, CI 1.033-1.299) and wider SBP range (OR=1.037, CI 1.011-1.066) in the first 24 hours after MT were associated with poor MRS at 90 days. Specific cutoffs with a high sensitivity and moderate specificity for SD of SBP from mean and SBP range leading to poor MRS at 90 days could be identified, with a SBP SD>12 (sensitivity=83.4%, specificity=42.2%) and SBP range>55mmHg (sensitivity=75.8%, specificity=51.1%), being associated with poor functional outcomes. A SBP SD>12 (sensitivity=86.2%, specificity=36.7%) was also associated with increased mortality at 90 days. A higher DBP mean (OR=1.045, CI 1.002-1.094), at a cutoff of mean DBP>60mmHg (sensitivity=73.9%, specificity=50.0%) was associated with a higher risk of HT. These relationships are displayed in Table 3. A higher age (OR=1.052, CI 1.013-1.100), at a cutoff of >68 (sensitivity=75.8%, specificity=48.9%) and NIHSS (OR=1.096, CI 1.031-1.173), at a cutoff of >14 (sensitivity=81.8%, specificity=62.2%) were associated with a poor MRS at 90 days, however a higher age, at a cutoff of 68 (sensitivity=75.8%, specificity=48.9%) was associated with a lower risk of HT (OR=0.970, CI 0.940-0.997) in our study. MAP parameters again were not correlated with any of the outcomes we measured. The fitted probabilities of univariate analysis of BP parameters for functional outcomes was not robust, with an AUC range of 0.6-0.7, so we followed up our analysis with a comprehensive MLR approach to identify more complex relationships between blood pressure and functional outcomes after MT.
Table 2: Results of univariate logistic regression analysis modeled for 3 functional outcomes.
| Variable |
Poor MRS at 90 days |
Death at 90 days |
HT |
| Age |
1.052 (1.013, 1.100) |
0.970 (0.940, 0.997) |
|
| NIHSS |
1.096 (1.031, 1.173) |
||
| SBP SD |
1.150 (1.033, 1.299) |
1.132 (1.005, 1.289) | |
| SBP Range |
1.037 (1.011, 1.066) |
||
| DBP Mean |
1.045 (1.002, 1.094) |
Results are displayed as Odds Ratios for 95% confidence intervals for 3 functional outcomes: Poor MRS at 90, Hemorrhagic Transformation (HT) and Mortality at 90 days. Sex, SBP mean and MAP variables were not statistically significant and removed for conciseness.
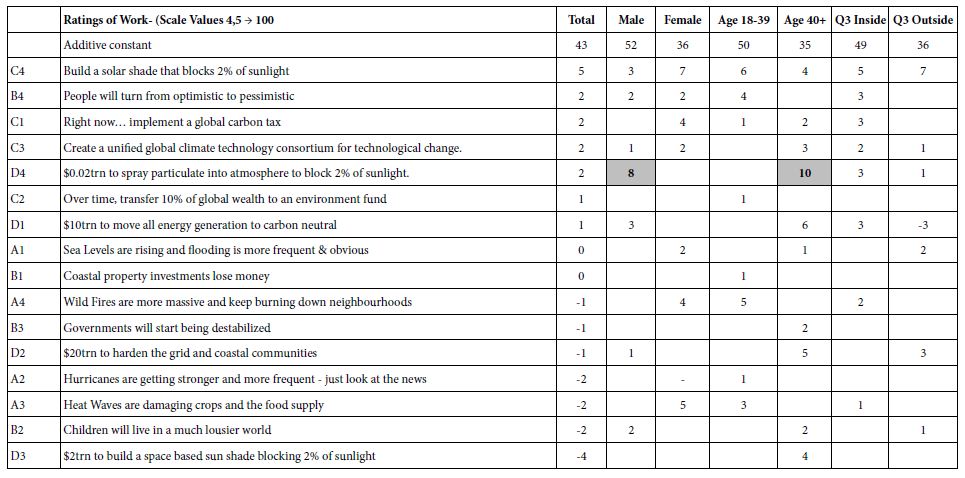
Table 3: Using univariate logistic regression analysis, cut-offs, or points that maximized sensitivity and specificity were identified for significant predictors.
| Outcome |
Variable |
Cutoff | Sensitivity | Specificity |
PLR |
| Poor MRS at 90 days |
Age |
68.0 | 75.8% | 48.9% |
1.48 |
|
NIHSS |
14.0 | 81.8% | 62.2% |
2.17 |
|
|
SBP SD |
12.0 | 83.4% | 42.2% | 1.44 | |
| SBP Range | 55.0 | 75.8% | 51.1% |
1.55 |
|
| Death at 90 days |
SBP SD |
12.0 | 86.2% | 36.7% |
1.36 |
| Hemorrhagic Transformation |
Age |
70.0 | 72.7% | 59.3% | 1.79 |
| DBP Mean | 60.0 | 73.9% | 50.0% |
1.48 |
Multivariate Association of Blood Pressure Parameters and Poor Functional Neurologic Outcome after MT and Development of a Risk Score
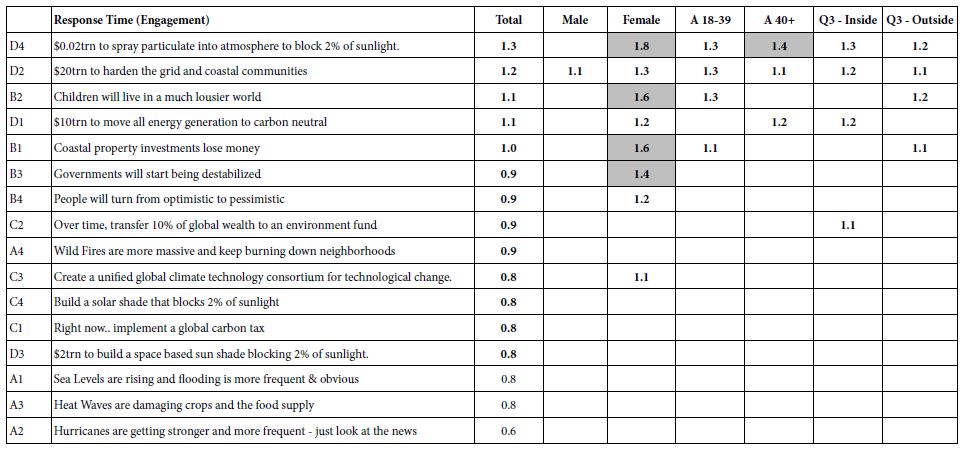
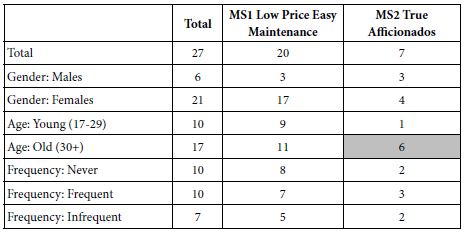
The results of our final MLR analysis of patients with AIS that underwent successful MT is displayed in Table 4. Due to the nature of the stepwise AIC selection, not all of the predictors selected to be included in the algorithm exhibited a ‘statistically significant’ confidence interval but despite this, we retained and described these variables as the importance or contribution of a predictor in a MLR model should not be judged solely on the grounds of ‘statistical significance’ [20]. Our MLR analysis confirmed findings from our ULR analysis that a higher SBP SD from the mean was associated with a poor MRS at 90 days (OR=1.156, CI 1.020-1.34) and a higher DBP mean was selected as predictive of HT(OR=1.045, CI 0.995-1.10). In addition, MLR analysis found that a higher overall SBP mean was associated with higher death at 90 days (OR=1.055, CI 1.055-1.11) and a higher DBP range was selected as predictive of HT (OR=1.066, CI 0.997, 1.15). MAP parameters again were not correlated with any of the outcomes we measured.
Table 4: Odds ratios and 95% confidence intervals of the multivariable logistic regression analysis for variables shown in Table 1, modeled for 3 functional outcomes.
| Parameter |
Poor MRS at 90 Days |
Death at 90 Days |
HT |
| Age |
1.038 (0.998, 1.09) |
1.051 (0.998, 1.12) |
0.980 (0.947, 1.01) |
| NIHSS |
1.087 (1.019, 1.17) |
1.040 (0.973, 1.12) |
1.008 (0.951, 1.07) |
| SBP SD |
1.156 (1.020, 1.34) |
||
| SBP Range | |||
| SBP Mean |
1.055 (1.005, 1.11) |
||
| DBP SD |
0.660 (0.442, 0.94) |
||
| DBP Range |
1.066 (0.997, 1.15) |
||
| DBP Mean |
1.045 (0.995, 1.10) |
3 functional outcomes are Poor MRS at 90 days, Death at 90 days, Hemorrhagic Transformation. Intervals excluding 1 correspond to p < 0.05. Empty cells denote that the parameter was not selected during the stepwise selection procedure and entire rows with no entries were removed for conciseness.
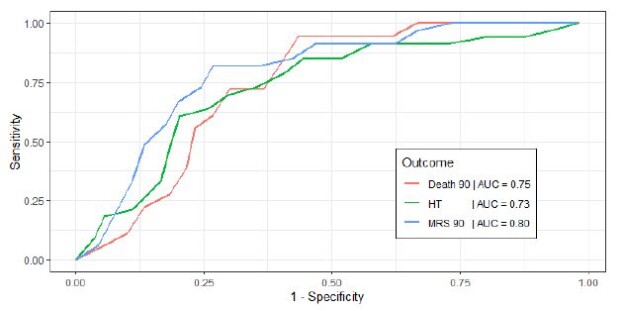
It also confirmed our ULR findings that a higher age and NIHSS were associated with poor functional outcomes including MRS at 90 days (OR=1.038, CI 0.998-1.09; OR=1.087, CI 1.019-1.17) and death at 90 days (OR=1.051, CI=0.998-1.12, OR=1.040, CI=0.973-1.12) respectively. A higher age was associated with a lower HT (OR=0.980, CI 0.947, 1.01). MAP parameters were removed from the logistic regression model as they were not selected using our stepwise AIC algorithm as they due to lack of contribution to predictive power. This MLR approach reinforced that no single BP parameter by itself was a strong predictor of functional outcome, but our MLR model that included age, NIHSS and BP parameters had a strong predictive value for the outcome MRS at 90 days (AUC=0.80), followed by death at 90 days (AUC=0.75) and HT (AUC=0.73). ROC analysis using the multivariate model to determine a poor functional outcome are displayed in Figure 1. Using age, NIHSS, BP predictor variables, we attempted to develop a risk model equation for developing poor MRS at 90 days, and the predictive performance of this equation was determined by the Area Under the Receiver Operating Characteristic (AUROC) curve (AUROC=0.80).
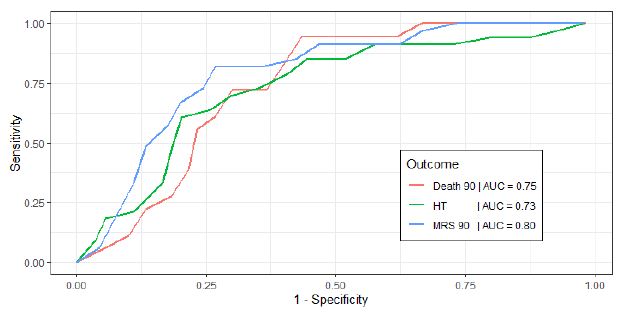
Figure 1: Receiver Operating Characteristic (ROC) curves for each functional outcome, from multivariate logistic regression analysis. Outcomes are Death 90, death at 90 days; HT, Hemorrhagic Transformation during hospitalization; MRS 90, Modified Rankin Scale at 90 days.
Log odds of having a poor MRS at 90 days=-6.245 + (Age)*0.037 + (NIHSS)*0.083 + (SBP SD)*0.145
The AUROC curve for this risk model was 0.80, or in other words, there is a 80% chance that this equation will be able to distinguish between patients who will develop a poor functional outcome at 90 days, and those who won’t develop this outcome based on their demographic and 24 hour blood pressure data.
Discussion
In patients with successful MT, our results demonstrate that a higher SBP variation from the mean in the first 24 hours was associated with poor MRS at 90 days using both ULR and MLR analyses. This is corroborated by other studies that showed that higher BP parameters after MT such as absolute SBP15,16 and MAP are associated with poor outcomes [15,16]. Goyal et al. stratified patients into three BP groups and found that high maximum SBP following MT was independently associated with increased likelihood of mortality and functional dependence at 3 months. Rather than maximum BP parameters, our study suggests that SBP variation of >12mmHg from the mean was associated with poor functional outcomes and this may be a useful treatment determinant to study prospectively in the future. Some literature suggests that a BP below a cutoff such as 130/70 yields favorable outcomes, but many of these studies did not take into account success of revascularization, which can have a major impact on brain physiology post MT [21]. In addition, studying variation from the mean factors in individual blood pressures rather than relying on an arbitrary cutoff. This is important because individual autoregulatory capacities could vary immensely, and treatment based on a BP cutoff for one patient with adequate collateralization and intact autoregulation may be suboptimal for a patient with different physiology.
According to our findings, a higher DBP mean and range, or maximal fluctuations from the mean were associated with a higher odd of developing HT, complementary to several other studies that had similar findings [13,15,22,23]. Following successful revascularization in AIS in the setting of impaired cerebrovascular autoregulation, systemic blood pressure may be directly transmitted to the cerebral vasculature, leading to hyperemia from reperfusion injury, HT, cerebral edema, further oligemia due to cerebral edema, neuronal death and result in poor functional outcomes. These can be accelerated in the presence of compromised blood brain barrier integrity and HT can be a marker of reperfusion injury in this setting [13,24]. This phenomenon has been well described after carotid revascularization but also likely occurs after AIS. In addition, presence of viable collaterals likely factor into development of HT as well, adding to the complexity of determination of ideal blood pressure management surrounding MT. In the aging population where arterial stiffness and widened pulse pressure are prevalent, small changes in DBP can result in marked changes in cerebral perfusion pressure [25]. If this occurs below the lower limit of autoregulation (LLA), cerebral perfusion becomes passive during systole, and completely arrests in diastole, resulting in periods of interrupted blood flow and worsened ischemia [26]. Conversely when the DBP is higher than limit of autoregulation, it can be associated with hyperemia and amplified in the setting of impaired cerebrovascular autoregulation due to AIS or poor collateral circulation.
Our study found that a higher age was associated with poor functional outcomes except for HT, corroborated by other studies that found an association between age and worse functional outcome and greater length of stay in AIS [27]. As expected, a higher NIHSS score was also associated with poor MRS at 90 days. This probably speaks to stroke burden, degree of cerebral autoregulation impairment and other complications associated with malignant infarction such as cerebral edema, HT, respiratory failure, infections, as well as withdrawal of life supporting measures. We suspect that the association between a higher age with lower odds of HT reflect the strong negative correlation that age had with DBP mean in our study, rather than a true relationship as current literature supports a positive correlation between advancing age and HT in AIS [28,29]. For instance, higher DBP mean was associated with higher HT but also a lower age, which makes sense physiologically, as mean DBP and pulse pressure decrease with ageing due to loss of arterial elastance [25,30]. But since DBP mean was negatively correlated with age, lower age appeared to be associated with higher HT. This highlights the limitations of a retrospective nature of this study that is unable to correct for variables with close associations and limited to identifying associations rather than cause-and-effect relationships.
Even though our results demonstrate important associations between SBP variability, mean DBP and poor functional outcomes, it is important to note that all BP parameters influence one another, and accounting for the BP variables together along with age and NIHSS results in a much better predictive ability than consideration and treatment of a single parameter alone. For instance, BP parameters when modeled together using MLR had a much better AUC (0.73-0.80) or predictive ability for a poor functional outcome, compared to being studied individually using ULR (AUC of 0.60-0.70) for the same functional outcomes. The MLR model accounts for complex inter-relationships between BP parameters, thus increasing the explanatory and predictive power of the model. Moreover, heterogeneity in patient pathophysiology for instance in stroke etiology and variation in autoregulatory capacity may have been accounted for better in the MLR model. This suggests that future prospective studies should consider that BP parameters are inter-dependent, and perhaps they should be considered together, along with patient age and NIHSS when developing treatment targets in future interventional trials. In addition, using this stronger predictive model, we were able to model a risk score for the development of a poor functional outcome in these patients, which can practically be used to predict patient’s functional outcome at 90 days from successful revascularization based on 24 hour post MT BP data.
Our study has several limitations. The retrospective design limits our findings to associations and limits our ability to consider other potentially important variables such as performance of decompressive hemicraniectomy and degree of impaired cerebral autoregulation which may influence functional outcome. The small sample size reduces the power of our study and limited our statistical ability to assess and incorporate potential curvilinear (eg. U-shaped) relationships in the predictor variables. A limitation of using a ULR is that the results may be multifaceted as only one parameter is considered at a time, however our results are exploratory with an intention to reproduce the results with larger prospective study. The single center retrospective design may result in a systematic selection bias and limit generalizability, though the homogenous management strategies including blood pressure, type of anesthesia and choice of neuro-interventional devices may have served as strengths in our study.
A key unresolved issue is whether elevated blood pressures post MT marks the presence of dysregulated cerebrovascular physiology in patients destined for a poor outcome, or whether treatment of these targets, when optimized can modify outcome. Further large, prospective randomized controlled trial studies are needed to assess the impact of BP control after successful MT prior to drawing practice-changing conclusions.
Conclusions
Our study demonstrates that a higher SBP variability within the first 24 hours after successful MT is associated with a higher likelihood of poor 90-day functional outcome, and a higher mean as well as fluctuations of DBP are associated with a higher rate of HT. A SBP variability of >12mmHg was associated with poor 90-day functional outcomes and this may be a useful treatment determinant to study in the future. We developed a risk model with excellent discrimination based on BP parameters and patient demographics to predict poor functional outcome at 90 days after revascularization. Further large prospective randomized control trials considering BP variability and ranges are needed to validate optimal BP targets following successful MT to optimize recovery in these patients.
Competing Interests
The authors declare that they have no competing interests.
Funding Information
This was not a sponsored study and therefore, there was no funding involvement.
References
- Tissue Plasminogen Activator for Acute Ischemic Stroke. New England Journal of Medicine. (1995) 333: 1581-1588. [crossref]
- Hacke W, Kaste M, Bluhmki E, Brozman M, Dávalos A, et al. (2008) Thrombolysis with Alteplase 3 to 4.5 Hours after Acute Ischemic Stroke. New England Journal of Medicine 359: 1317-1329. [crossref]
- Yang P, Zhang Y, Zhang L, Zhang Y, Treurniet KM, et al. (2020) Endovascular Thrombectomy with or without Intravenous Alteplase in Acute Stroke. New England Journal of Medicine 382: 1981-1993 [crossref]
- Qureshi AI, Ezzeddine MA, Nasar A, Suri MF, Kirmani JF, et al. (2007) Prevalence of elevated blood pressure in 563704 adult patients with stroke presenting to the ED in the United States The American Journal of Emergency Medicine 25: 32-38. [crossref]
- Aries MJ, Elting JW, Keyser JD, Kremer BP, Vroomen PC (2010) Cerebral Autoregulation in Stroke. Stroke 41: 2697-2704. [crossref]
- Valent A, Sajadhoussen A, Maier B, Lapergue B, Labeyrie MA, et al. (2020) A 10% blood pressure drop from baseline during mechanical thrombectomy for stroke is strongly associated with worse neurological outcomes. Journal of NeuroInterventional Surgery 12: 363-369.
- Blanco PJ, Müller LO, Spence JD (2017) Blood pressure gradients in cerebral arteries: a clue to pathogenesis of cerebral small vessel disease. Stroke Vasc Neurol 2: 108-117.
- Mistry EA, Mayer SA, Khatri P (2018) Blood Pressure Management after Mechanical Thrombectomy for Acute Ischemic Stroke: A Survey of the StrokeNet Sites. Journal of stroke and cerebrovascular diseases 27: 2474-2478. [crossref]
- Yong M, Kaste M (2008) Association of Characteristics of Blood Pressure Profiles and Stroke Outcomes in the ECASS-II Trial. Stroke 39: 366-372. [crossref]
- Powers WJ, Rabinstein AA, Ackerson T, Adeoye OM, Bambakidis NC, et al. (2018) 2018 Guidelines for the Early Management of Patients With Acute Ischemic Stroke: A Guideline for Healthcare Professionals From the American Heart Association/American Stroke Association. Stroke 49: e46-e99. [crossref]
- Bhatia R, Hill MD, Shobha N, Menon B, Bal S, et al. (2010) Low rates of acute recanalization with intravenous recombinant tissue plasminogen activator in ischemic stroke: real-world experience and a call for action. Stroke 41: 2254-2258. [crossref]
- Demchuk AM, Goyal M, Yeatts SD, Carrozzella J, Foster LD, et al. (2014) Recanalization and Clinical Outcome of Occlusion Sites at Baseline CT Angiography in the Interventional Management of Stroke III Trial. Radiology 273: 202-210. [crossref]
- Mistry EA, Mistry AM, Nakawah MO, Khattar NK, Fortuny EM, et al. (2017) Systolic Blood Pressure Within 24 Hours After Thrombectomy for Acute Ischemic Stroke Correlates With Outcome. J Am Heart Assoc 6: e006167. [crossref]
- Nogueira RG, Jadhav AP, Haussen DC, Bonafe A, Budzik RF, et al. (2018) Thrombectomy 6 to 24 Hours after Stroke with a Mismatch between Deficit and Infarct. New England Journal of Medicine 378: 11-21. [crossref]
- Anadani M, Orabi MY, Alawieh A, Goyal N, Alexandrov AV, et al. (2019) Blood Pressure and Outcome After Mechanical Thrombectomy With Successful Revascularization. Stroke 50: 2448-2454. [crossref]
- Goyal N, Tsivgoulis G, Pandhi A, Chang JJ, Dillard K, et al. (2017) Blood pressure levels post mechanical thrombectomy and outcomes in large vessel occlusion strokes. Neurology 89: 540-547. [crossref]
- Maïer B, Fahed R, Khoury N, Labreuche J, Taylor G, et al. (2019) Association of Blood Pressure During Thrombectomy for Acute Ischemic Stroke With Functional Outcome. Stroke 50: 2805-2812. [crossref]
- Valent A, Sajadhoussen A, Maier B, Lapergue B, Labeyrie MA, et al. (2019) A 10% blood pressure drop from baseline during mechanical thrombectomy for stroke is strongly associated with worse neurological outcomes. Journal of NeuroInterventional Surgery 12: 363-369. [Crossref].
- Petersen NH, Ortega-Gutierrez S, Wang A, Lopez GV, Strander S, et al. (2019) Decreases in Blood Pressure During Thrombectomy Are Associated With Larger Infarct Volumes and Worse Functional Outcome. Stroke 50: 1797-1804. [crossref]
- Wasserstein RL, Lazar NA (2016) The ASA Statement on p-Values: Context, Process, and Purpose. The American Statistician 70: 129-133.
- Choi KH, Kim JM, Kim JH, Kim JT, Park MS, et al. (2019) Optimal blood pressure after reperfusion therapy in patients with acute ischemic stroke. Scientific reports 9: 5681.
- Blech B, Chong BW, Sands KA, Wingerchuk DM, Jackson WT, et al. (2019) Are Postprocedural Blood Pressure Goals Associated With Clinical Outcome After Mechanical Thrombectomy for Acute Ischemic Stroke? Neurologist 24: 44-47. [crossref]
- McCarthy DJ, Ayodele M, Luther E, Sheinberg D, Bryant JP, et al. (2020) Prolonged Heightened Blood Pressure Following Mechanical Thrombectomy for Acute Stroke is Associated with Worse Outcomes. Neurocrit Care. 32: 198-205. [crossref]
- Park JH, Ovbiagele B (2017) Post-stroke diastolic blood pressure and risk of recurrent vascular events. Eur J Neurol 24: 1416-1423. [crossref]
- Pinto E (2007) Blood pressure and ageing. Postgrad Med J 83: 109-114. [crossref]
- Varsos GV, Richards HK, Kasprowicz M, Reinhard M, Smielewski P, et al. (2014) Cessation of Diastolic Cerebral Blood Flow Velocity: The Role of Critical Closing Pressure. Neurocritical Care 20: 40-48. [crossref]
- Black-Schaffer RM, Winston C (2004) Age and functional outcome after stroke. Topics in stroke rehabilitation 11: 23-32. [crossref]
- Marsh EB, Llinas RH, Schneider ALC, Hillis AE, Lawrence E, et al. (2016) Predicting Hemorrhagic Transformation of Acute Ischemic Stroke: Prospective Validation of the HeRS Score. Medicine (Baltimore) 95: 2430-2430. [crossref]
- Pande SD, Win MM, Khine AA, Zaw EM, Manoharraj N, et al. (2020) Haemorrhagic transformation following ischaemic stroke: A retrospective study. Scientific reports 10: 5319.
- Steppan J, Barodka V, Berkowitz DE, Nyhan D (2011) Vascular stiffness and increased pulse pressure in the aging cardiovascular system. Cardiol Res Pract 263585. [crossref]