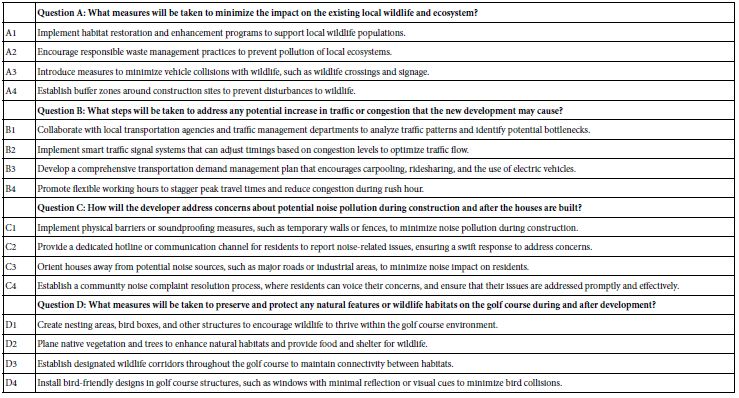
Abstract
Objectives: To assess the effectiveness of patients to remove urinary catheters by themselves after pelvic floor surgery done as day cases.
Design: This was a non-randomized, single centre, prospective pilot study which included patients who have had pelvic floor surgeries (anterior and/ or posterior colporrhaphies and colpocleisis) done as day cases between February 2021 and November 2023.
Sefling: UK DGH hospital urogynecology department.
Population: All patients who had anterior, posterior colporrhaphy, and colpocleisis and fulfilled our inclusion criteria for an elective day-case surgery
Methods: Non-randomized, single centre, prospective pilot study which assess the effectiveness of day-case pelvic floor surgeries, with patients being discharged home with urinary catheters. They were instructed on how to remove these catheters on the first day following the operation. Subsequently, participants were monitored postoperatively and attended a clinic appointment six weeks later. Additionally, they were provided with a questionnaire to fill out, which was to be returned one week after the procedure.
Results: The data obtained was over a 33-month period between February 2021 and November 2023. A total of 123 patients were included in the study. 65 patients (52%) had anterior repairs; 42 rectoceles (34%); 6 Enterocele (4%) and 10 colpoclesis (8%). Ages of the participants ranged from 42 years to 89 years.
Overall, 77% of feedback questionnaires were returned. Amongst the enrolled patients, 98% would prefer not to wait for another admission date where a bed will be available, 97% of our patients removed the urinary catheter by themselves and found it to be easy, 88% of our patients would prefer not to come to the hospital or have a nurse sent to their homes to remove the catheter, and finally, 89% of our patients would recommend this service to a friend.
Conclusion: Our study demonstrated that removal of patient’s own catheter following pelvic floor surgery is cost-saving and highly acceptable to this cohort of patients.
Introduction
The COVID-19 pandemic has led to a significantly increase in pressure on the already stretched National Health Service (NHS) with high demands of hospital bed space and prolonged waiting times for outpatient appointments and elective surgeries across the country [1].
A lot of healthcare services across the NHS had to be adjusted to cope with increased pressures. To help reduce waiting times for urogynaecological operations and effectively manage hospital bed space, we have introduced a new service by performing pelvic floor surgery as day cases and allowing patients to go home with an urinary catheter to be removed by themselves day 1 (D1) postoperatively. This begun as a quality improvement project and has evolved into a change of practice [2].
Before the onset of the pandemic, patients who are having elective anterior and posterior colporrhaphy would be admitted for an overnight stay in the hospital and discharged the following day provided that their trial-without-catheter (TWOC) was successful.
Due to the growing demand for hospital beds, we have initially adapted the service by performing the pelvic floor surgeries as day cases and allowing women to be discharged with urinary catheters, which would be taken out by a nurse at their homes on the first day after surgery. Nevertheless, considering the increasing COVID-19 cases and the emergence of new strains, we initiated an innovative quality improvement project to evaluate the capability of patients to self-remove their urinary catheters after undergoing day-case anterior or posterior colporrhaphy without compromising the quality of their care. The service was extended to encompass colpocleisis procedures as the study progressed.
Anterior colporrhaphy can be described as surgically correcting a vaginal wall defect resulting from the protrusion of the bladder into the vagina, while a posterior repair addresses a defect in the vaginal wall that causes the rectum to protrude into the vagina. These defects tend to affect the quality of life of these patients and can be associated with a range of bowel , urinary and sexual symptoms [3].
Colpocleisis is a surgical intervention employed to address pelvic organ prolapse in women. This procedure entails excising a portion of the vaginal wall and then joining the remaining tissue together to provide support for the pelvic organs [4].
In a previous study by Weemhoff et al. 2011, the importance of inserting urinary catheters following vaginal wall surgeries to address postoperative urinary retention was highlighted. This finding is particularly significant as it was observed that 40% of patients experienced urinary retention when the catheter was removed on the same day [5].
The primary objective of this study is to evaluate the effectiveness and safety of patients self-removal of urinary catheters after undergoing pelvic floor surgery.
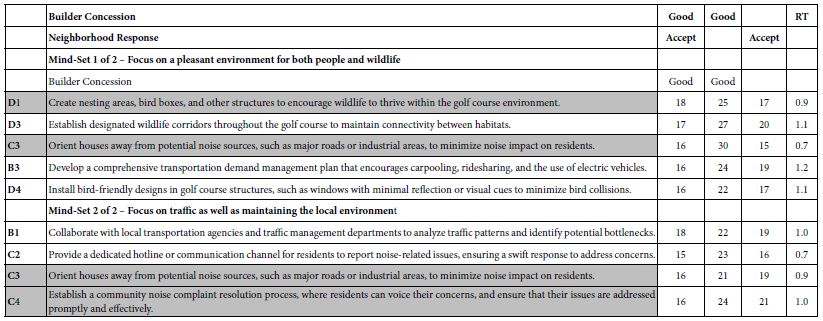
Methodology
We have conducted a prospective pilot study in a single DGH hospital. Patients who were having pelvic floor surgeries were recruited between February 2021 to November 2023. A total of 123 patients were enrolled in the study.
Given that this project is focused on quality improvement and service development, ethical approval was not indicated.
The process commenced at the urogynaceology outpatient clinic, where patients received information and provided consent for the surgical procedure. A member of the urogynaecology team facilitated the consent to participate in the study.
Patients who met the inclusion criteria were subsequently counseled about the study, which entailed them independently removing their urinary catheter at home on D1 postoperatively.
A practical demonstration is done in clinic and the patients are given a hands-on experience to ensure that they were confident in deflating the catheter balloon and removing the catheter. All questions and concerns are addressed during this session.
Our inclusion and exclusion criteria are listed below:
Inclusion Criteria
- Fit and well women with no significant co-morbidities and suitable for day-case procedures.
- Must be consented to partake in the study.
- Women must have someone to care for them at home for the first 24 hours.
Exclusion Criteria
- Visually impaired.
- Women with cognitive disorders or learning disabilities.
- Patients with no support at home or living on their own.
- Patients who do not want a day surgery.
- Patients with significant medical.
On the day of the surgery, a repeated practical demonstration of deflating the catheter balloon is performed in the morning, and the patients’ willingness to participate is confirmed.
The surgical procedure begins with infiltration with 40 mls 1: 200,000 Adrenaline in 0.25% Marcaine to the vaginal wall. A vertical elliptical incision was made at the lowest point of 1 cm above POP: Q(Aa) in an anterior repair and POP: Q(Ap) in a posterior repair. Dissection was performed to the paravaginal tissue and opposed in midline by plication of fascia using 3/0 PDS. The vagina was closed with interrupted 3/0 PDS and completed by a continuous locking haemostatic 3/0 PDS. None of our patients required a vaginal pack. All patients were catheterized after the procedure and was sent home when they met the discharge criteria. Upon discharge, patients were given Voltarol suppository, either 50 mg or 100 mg to be used at night. For those sensitive to non-steroidal anti-inflammatory drugs, an alternative of Co-dydramol 10/500 mg tablets (2 tablets taken four times a day) were provided, or simply paracetamol 1g four times a day if codeine could not be tolerated. To prevent constipation, patients were prescribed Lactulose, to be taken in 10 ml doses twice daily. The postoperative medications are given for a duration of 5 days Additionally, they were sent home with a 10ml syringe, which is to be used for deflating their urinary catheters at 7am the next morning.
Some adjustments had to be made during the study as we noticed that the catheter was removed with ease when filled with 8 ml of saline rather than the standard 10mls. We then modified our practice by using silicone catheters, rather than the latex made ones which were previously used after a patient reported with a faulty latex catheter. Participants were provided with safety net advice along with an emergency contact number for seeking advice or expressing concerns in the postoperative period. Patients were provided with feedback questionnaires prior to discharge, and they were encouraged to complete them one week following the procedure. A follow-up appointment with the consultant was also scheduled for 4-6 weeks postoperatively.
Initially, for the first 17 patients, follow-up calls were scheduled on the first day postoperatively. This involved two calls in the morning and one in the afternoon. However, the team later determined that these multiple calls were unnecessary. As a result, the protocol was adjusted to only one call made by a team member from the urogynecology department in the evening. All patients were provided with an emergency contact number in case they experienced any issues. Patients who experienced difficulties with catheter removal or were suspected of being in urinary retention were encouraged to visit our gynecology ward for a comprehensive assessment. Patients who experienced urinary retention underwent re-catheterization. Following this, a subsequent follow-up appointment with our nurse specialist was arranged for a repeat TWOC in a week’s time.
Results
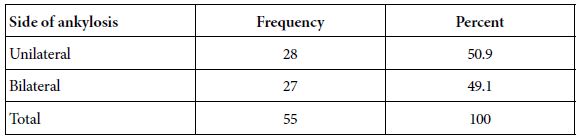
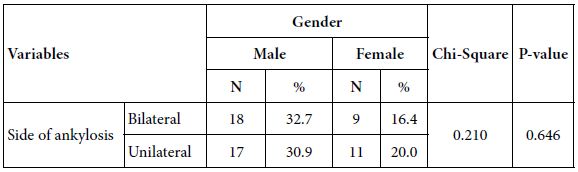
The data obtained from the prospective study was obtained over a 33-month period. A total of 123 patients were included in our study. This included 65 patients (53%) who had anterior repairs; 42 rectoceles (34%); 6 Enterocele (4%) and 10 colpoclesis (8%) (Figure 1).
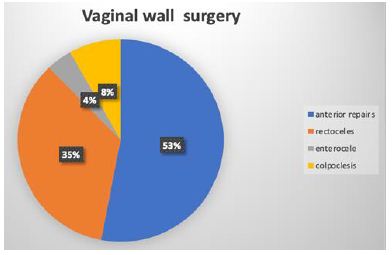
Figure 1: Distribution of cases in percentages.
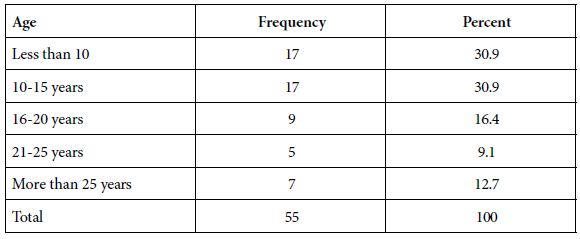
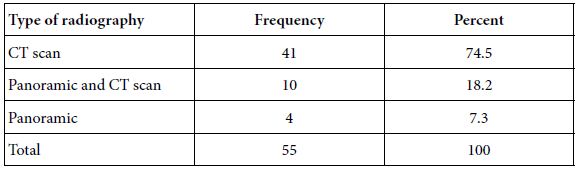
The ages of the participants ranged from 42 years to 89 years, with a mean age of 67 years. Majority of the patients enrolled were between 70-79 years and the least number of patients were aged between 40-49 as illustrated in Figure 2.
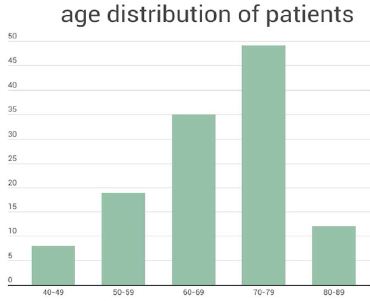
Figure 2: Age distribution of patients in the study (the x-axis shows the age groups of the patients and the Y-axis shows the number of patients in each group).
Ninety-five questionnaires were returned, yielding a response rate of 77% and the outcomes were highly favorable.
One participant out of the 123 (0.8%) experienced urinary retention and required re-catheterization for one week, subsequently passing her TWOC without further issues.
Additionally, another patient (0.8%) had to be admitted for overnight observation due to significant nausea and vomiting following general anesthesia. Lastly, one patient (0.8%) faced complications with a defective catheter, necessitating them reporting to the hospital for removal. Finally, 99% of patients did not require a bladder scan, suggesting routine bladder scan post pelvic floor surgery may not be indicated.
Some common theme of feedback received is seen in Table 1.
Table 1: Patient feedback.
| Easy to remove catheter by myself | Quick and no time wasted in the hospital |
| Recovered better at home than in hospital | Easier than I expected |
| Felt better that hospital contacted me the next day, because if I had a problem, it could be solved | Nervous about taking my own catheter |
| Less risk of COVID | Did not know how to correctly remove catheter |
| Consultant and his team were efficient | Long wait from pharmacy to get discharge medications |
| Very good care and well looked after… | Need to wear loose clothing during a day case to hide the urinary catheter. |
In terms of patient feedback, ninety eight percent of enrolled patients expressed a preference not to wait for another admission date with an available bed. Additionally, ninety seven percent successfully removed the urinary catheter themselves, finding the process easy. Eighty eight percent of patients preferred not to come to the hospital or have a nurse sent to their homes for catheter removal. Furthermore, eighty nine percent would recommend this service to a friend. A significant portion (90%) would rather avoid hospital visits or nurse home visits for catheter removal due to concerns about COVID-19.
We have received largely positive feedback from our patients stating that they were pleased with the arrangements as they felt more comfortable to be at home. Although a few patients were nervous about removing their own catheters, the vast majority of patients expressed that it was straightforward, and they were reassured by a single phone calls from the team.
Discussion
The initial motivation for this study was to find an innovative, practical and efficient way to continue urogynecological surgeries during the COVID-19 pandemic.
The Covid -19 pandemic placed an enormous amount of stress and strain on the heath service resources. It has led to changes to routine practices alternative options for the patients by reducing unnecessary contact with the health service thus reducing the risk of transmitting of Covid-19. This was particularly important in our group of patients as the average age was 65, thus placing them in the vulnerable category. On the other hand, there were delays in performing surgeries during the pandemic due to increased pressure on bed space and staffing which further complicated the issue. Recent studies have proven delays in healthcare provision to be associated with adverse outcomes and poor patient satisfaction [6-8].
Seeking to achieve a balance between patient satisfaction and safety, we launched this quality improvement project to address the extended waiting times for elective pelvic floor surgeries. Our goal was to mitigate the risk of COVID exposure without compromising patient well-being.
The outcomes of this pilot prospective study were notably positive, with over 98% of participants expressing ease in self-removing their urinary catheters postoperatively. Although majority of our patients fall into an older age group, this did not pose a hindrance to the study. Reassuringly, as we have demonstrated that this is widely acceptable to the older population, this suggests that there is a strong possibility for replicating this study outcome in different age groups. The practice could also be extrapolated to other clinical and surgical disciplines faced with similar challenges [9].
The findings of this study underscore several benefits, aligning with NICE recommendations that advocate for greater patient involvement in their care. This study, in turn, places the patient at the forefront of their care, contributing to the overall improvement of healthcare practices. It is important to point out the potential cost-saving benefits observed in our study. Considering an estimated cost of £400 for a hospital bed during an overnight stay at Southend Hospital, we have saved a total of £ 49,200 ( 123 cases x£400) over the duration of our study [10-12].
Further cost savings were made by reassigning the specialist nurse who would have otherwise gone to the homes of the patients to remove the urinary catheters. Instead, they can be deployed to cover over- stretched clinical areas in the hospital as there is currently a national shortage of nurses coupled with increased staff pressures [13].
Patients filled out the feedback forms one week after the procedure, providing them with ample time to reflect on any encountered issues and to weigh the pros and cons of participating in the study. The study received positive response from the ‘family and friends’ test as 89% would recommend it to their friends. One of the common themes in the feedback was the reassurance they had knowing that there was a point of contact they could reach out to if they had any concerns.
As the study progressed, we noted that patients when given additional time, managed to pass urine without any further intervention. This prompted the team to adjust the calling times only once daily in the evening, rather than the initial three times. Also, the patients were given the number of the gynaecology ward so that they can contact the team rather than being called multiple times by the doctor.
We expanded the service to patients undergoing colpocleisis, again with positive results. In the near future, our aim is to further extend this to other gynecology procedures as it has proven to not only be cost-effective but also associated with high patient satisfaction.
Conclusion
The majority of our patients who underwent elective vaginal wall surgeries expressed high satisfaction with the procedure being conducted as day cases and with the subsequent self-removal of their catheters.
This project allowed improvement in capacity to provide elective surgeries with better efficiency and high patient satisfaction without compromising patient safety.
With over 1250 NHS hospitals, this could lead to a potential saving of 20 million pounds, if 40 repairs are done per year which equates to over 50,000 repairs being performed multiplied by only the estimated cost of an inpatient bed (1250×40 repairs /year x £400). Furthermore, additional cost savings will be made by re-deploying nursing staff who were initially assigned to care for these patients.
We conclude that this is a sustainable service that can be continued, and we hope to extend this to other elective gynecological procedures. The inpatient beds can be redistributed for other elective surgeries.
Finally, our study demonstrated that removal of patient’s own catheter following pelvic floor surgeries is not only cost-saving, but also safe and highly acceptable to this cohort of patients.
Future Considerations
With the effective vaccination program, COVID-19 is no longer causing as much strain to our hospitals compared to three years ago, when our project was launched. However, the demand for hospital beds and waiting list for elective surgery are constant struggles within the NHS, our study outcomes should reassure other hospitals that self-TWOC post operatively with uncomplicated pelvic floor surgeries is a safe and cost-effective way of reducing the pressure on the ever- increasing demand of the NHS system.
Patient’s consent: Only anonymous data are included in the study and therefore no individual patient’s consent was required.
Disclosure of Interests
There no conflict of interests declared for this study.
Ethical Approval
Also, no ethical permission was required as it was registered as a Quality improvement project at Southend University Hospital.
Funding
This study was a quality improvement project no external funding was obtained.
Roles of Authors
Dr Papa Yaw Opoku-Ansah (trainee doctor in Obstetrics and Gynaecology ) – Lead author, I used to see the patients pre and post operatively, assist in the surgery, call the patients post operatively, did the write up of the paper.
Dr Candice Cheung – Senior Registrar – saw the patients pre and post operatively, assisted and performed the surgery, called the patients post operatively, made input to the write up of the paper.
Mr Lee – Consultant Urogynecologist, the patients were under his care, he consented the patients, operated on the patients, followed them up, made numerous changes and edits to the paper
References
- Uimonen M, et (2021) The impact of the COVID-19 pandemic on waiting times for elective surgery patients: A multicenter study. PLoS One 16(7).
- Surgeons, RCo (2020) RCS Managing elective surgery guidance 16 Dec pdf.
- Belayneh T, et (2021) Pelvic organ prolapse surgery and health-related quality of life: a follow-up study. BMC Womens Health 21(1). [crossref]
- Felder L, et (2022) How does colpocleisis for pelvic organ prolapse in older women affect quality of life, body image, and sexuality? A critical review of the literature. Womens Health (Lond) 18: [crossref]
- Weemhoff, et (2011) Postoperative catheterization after anterior colporrhaphy: 2 versus 5 days. A multicentre randomized controlled trial.BMC Women Health.22(4). [crossref]
- Moynihan R, et al. (2021) Impact of COVID-19 pandemic on utilisation of healthcare services: a systematic review. BMJ open 11(3). [crossref]
- Romero Starke K, et al. (2021) The isolated effect of age on the risk of COVID-19 severe outcomes: a systematic review with meta-analysis. BMJ Global Health 6(12). [crossref]
- Sud A, et (2020) Effect of delays in the 2-week-wait cancer referral pathway during the COVID-19 pandemic on cancer survival in the UK: a modelling study. The Lancet Oncology 21(8).
- Apramian T, et al. (2016) They Have to Adapt to Learn: Surgeons’ Perspectives on the Role of Procedural Variation in Surgical J Surg Educ 73(2). [crossref]
- NICE (2016) Patients should be more involved in decisions about their care, says NICE.
- Krist AH, et (2017) Engaging Patients in Decision-Making and Behavior Change to Promote Prevention. Stud Health Technol Inform 240: 284-302. [crossref]
- Fund, K. (2022) Key factsnabd figures. Retrieved 03-10-22, 2022, Available from: https://www.kingsfund.org.uk/audio-video/key-facts-figures-nhs.
- Melissa Macdonald, CB (2020) Nursing workforce shortage in England. Available From: https://researchbriefings.files.parliament.uk/documents/CDP-2020-0037/ CDP-2020-0037.pdf