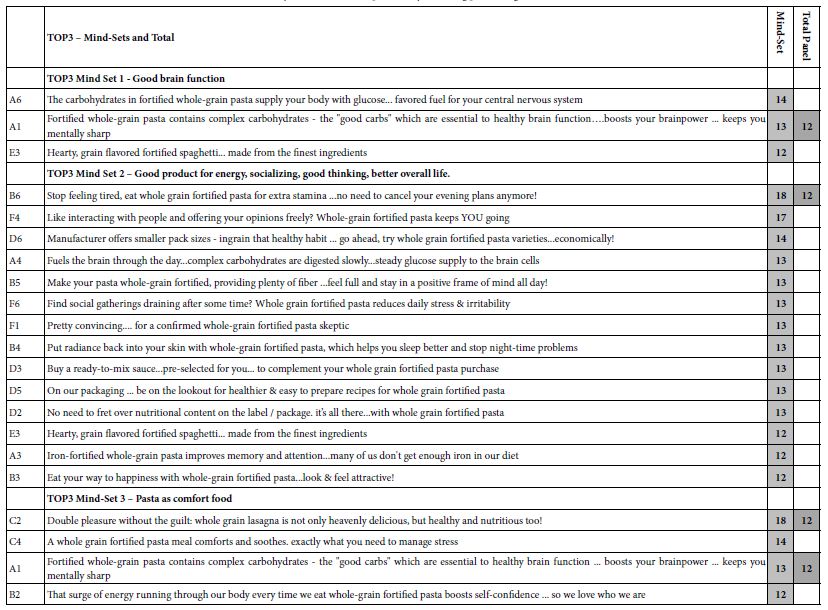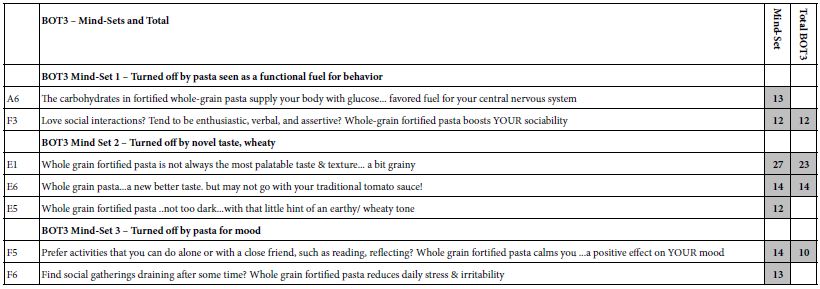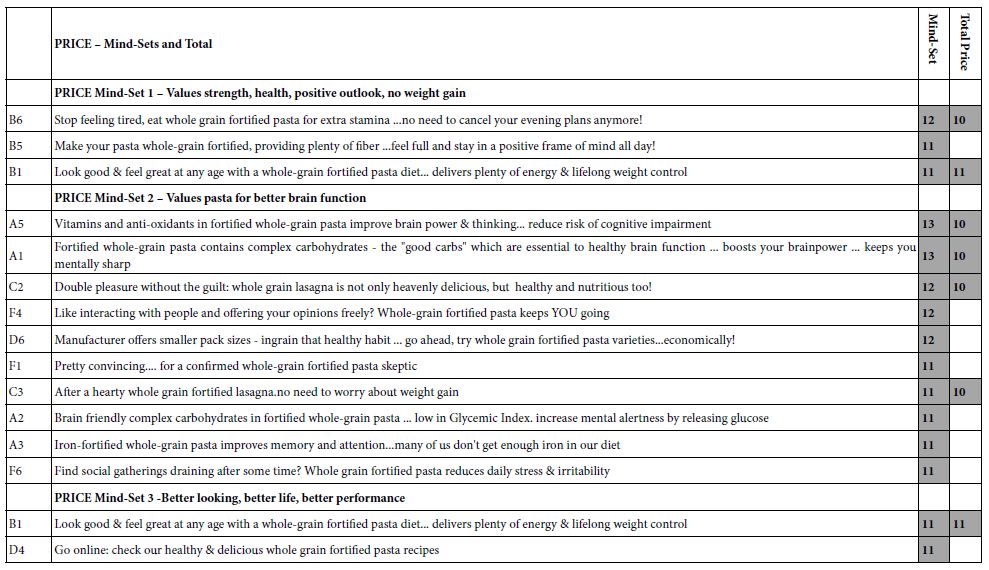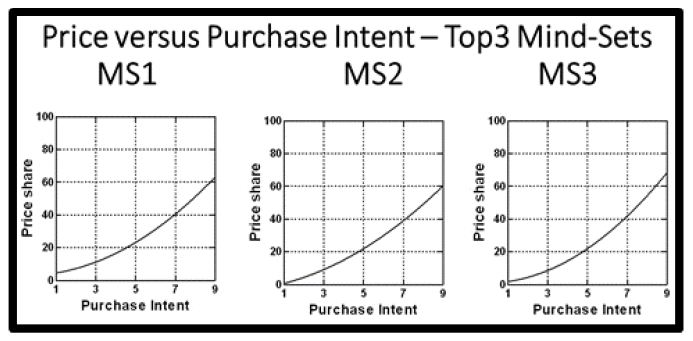
Abstract
A novel non-invasive approach for treatment of localized obesity is introduced utilizing carbopol gel containing soybean phosphatidylcholine based nanovesicular system for topical application. The tested systems are designed to combine the absence of side effects of the multi-injection system used in mesotherapy and the ease of application. Nanovesicles such as transfersomes and transethosomes were prepared using soybean phosphatidylcholine, tween 80, sodium deoxycholate, cremophor, and oleic acid in different concentrations determined according to 3D-optimal mixture experimental design. The prepared vesicles were evaluated and incorporated into carbopol gel. The stability of the prepared nanovesicles and gel was examined after storage for six months at 4˚C. In-vivo and In-vitro studies were performed using male albino rats. Performed experiments on rats showed that the three formulations of choice (F4e, F11e and Et11) succeeded to reduce body weight, percentage dorsal fat and total lipid content significantly (P<0.05) without appearance of any sign of skin irritation compared to PC marketed injections (Adipoforte®) used in mesotherapy. PC nanovesicular gel, containing transethosomes (F4e, F11e & Et11), can be significantly considered as effective noninvasive treatment for localized obesity as an alternative to multi-injections for mesotherapy.
Keywords
Phosphatidylcholine, HPLC-Determination, Experimental Design, Nanovesicles, Mesotherapy.
Introduction
Obesity is recognized as one of the most important public health problems facing the world[1]. Up to 30% of the western adults are obese[1]. In Middle East and North Africa, obesity prevalence reaches about 19% of whole population while it reaches 33% in Egypt [2]. Mesotherapy is a controversial cosmetic procedure for localized fat accumulations reduction. Subcutaneous Phosphatidylcholine(PC) injection has been performed effectively as nonsurgical treatment of localized fat deposits in abdomen, neck, arms and thighs [3]. PC has first a lipocyte-destroying effect and then a lipolytic action, which is active over 8weeks [4]. Despite being minimally invasive alternatives to liposuction, it causes localized and systemic side effects that usually appear 2-5days after application and include allergic reactions, tissue necrosis and body surface irregularities [5]. Nanotechnology-based delivery systems can protect drugs from degradation, reduce dose regimen, and enhance drug solubility. Vesicular system offers controlled drug delivery and increased drugs permeation through skin [6]. Transfersomes are metastable vesicles, sufficiently deformable to penetrate pores much smaller than their own size. They consist of phospholipids and one or more edge-activator [7]. Transethosomes are elastic ultra-deformable lipid vesicles containing high concentration of ethanol and edge-activators causing destabilization of the lipid bilayer and increases its flexibility [8]. Accordingly, this work aims to introduce non-invasive dosage form of high patient compliance for efficient, safer treatment of localized obesity instead of the applied multi-injection regimen through application of nanotechnology in drug targeting.
Materials and Methods
Materials
Soybean PC, SDC, cremophorA25, cholesterol, chloroform and methanol HPLC grade were purchased from Sigma-Aldrich (Darmstadt, Germany). Potassium hydroxide, oleic Acid, tween 80, and ethanol were purchased from El-Nasr Pharmaceutical Chemicals (Cairo, Egypt). Trichloroacetic acid was purchased from Carl-Roth Company (Karlsruhe, Germany). Carbopol 934 was purchased from Arabic laboratory equipment (Cairo, Egypt).
Animals
Male Albino rats (50±5gm) were purchased from National Research Center, Giza, Egypt. The study protocol was conducted in accordance with the ethical procedures and policies approved by the Animal Care and Use Committee of Faculty of Pharmacy-German University in Cairo. All rats were maintained in the animal facility at 25±5ºC,12hours dark and 12hours light cycle.
Methods
Quantitative analysis of PC
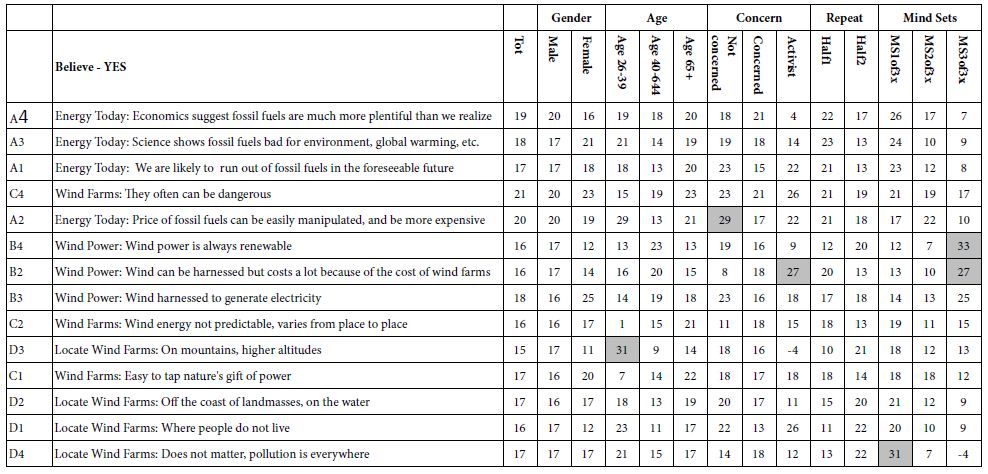
A modified method was applied for PC determination. A Spectrasystem High performance liquid chromatography (HPLC) consisting of Spectrasystem pump P2000 and detector UV-3000 connected to Thermo C8 reverse-phase analytical column (250mm lengthx4.6mm internal diameter and particle size 5μm) (Thermofisher, UK). The mobile phase consists of acidified water at pH3.5 and methanol [9]. Gradient elution was performed at a flow rate of 1.5ml/min from 80% to 100% methanol in 40min (as shown in Table1). In–vitro calibration curve was constructed using concentration range (7.5-62.5µg/ml) of PC standard solution in ultrapure water. 50µl of prepared solution was injected into the HPLC. The flow rate was adjusted at 1.5ml/min at 20˚C and detection was carried at 205nm [10]. The assay procedures were validated in terms of linearity, precision, and accuracy (R=0.9981, LOD=2.5ng/ml;LOQ=6.5ng/ml; interday and intraday assay RSD<10%, accuracy≈99%). PC concentrations in the withdrawn samples were calculated with reference to the calibration curve of area under the curve of peak corresponding to PC concentrations (Insert Table 1).
Table 1: Gradient elution of PC using methanol and acidified water
|
Time (min) |
Acidified Water (%) | Methanol (%) |
| 0 | 20 |
80 |
|
40 |
0 | 100 |
| 45 | 0 |
100 |
|
46 |
20 | 80 |
| 55 | 20 |
80 |
Preparation of Phosphatidylcholine Vesicles
Preparation of Transfersomes
Transfersomes were prepared using the thin film hydration method. PC and surfactants were solubilized in chloroform-methanol (2:1respectively) [11]. The organic solvent was evaporated leaving a dry thin film using a rotary evaporator (Buchi, Switzerland) at 55˚C, 80rpm and 471bars. The film was hydrated with 5ml ultrapure water previously heated at 55˚C. The hydrated vesicles were then rotated using rotary evaporator at 80rpm and 55˚C for 1hour at normal atmospheric pressure [12]. The prepared vesicles were left at room temperature for 2hours for swelling then kept at 4˚C [13]. The aforementioned prepared vesicles were labeled(F).
Preparation of Transethosomes Hydrated with 20%Ethanol
Transethosomes were prepared using the thin film hydration method similar to that used for preparation of transfersomes. However, the hydration step was performed with 5ml of 20%ethanol. These vesicles were labeled (Fe).
Preparation of Transethosomes
Transethosomes were prepared using the solvent dispersion method. PC and surfactants were solubilized in 1.5ml of 20%ethanol [14] under vigorous stirring in tightly covered round bottom flask in a water bath at 30˚C. An aliquot of 3.5ml ultrapure water [15] was added slowly under continuous stirring. The nanosuspension was left at room temperature for 30min under continuous stirring. The prepared formulations were left at room temperature for 2hours then kept in at 4˚C[13]. They were then labeled (Et).
D-Optimal Mixture Design Model
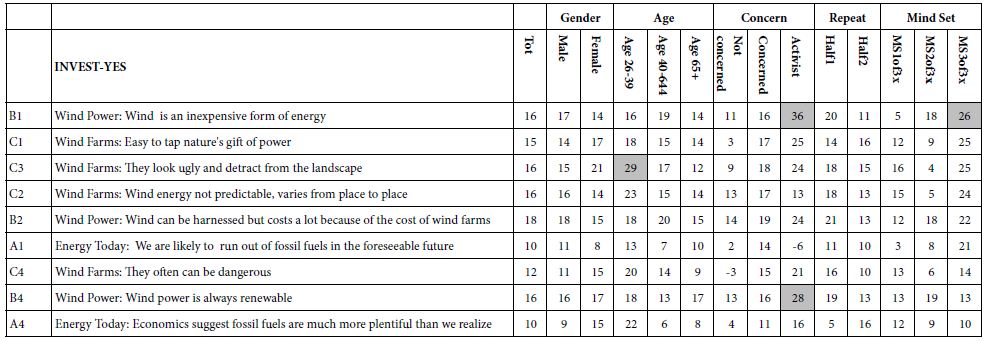
In order to investigate the different effects of the used ingredients for preparing the vesicles which are composed of PC together with a blend of surfactants, a D-optimal mixture design was conducted using the Design-Expert 7.0software [16]. The demonstrated independent variables were: the individual amounts of each of Cremophor, Sodium deoxycholate (SDC), Tween 80 and Oleic acid. The responses were: the particle size, polydispersity index and the %yield. Values of the dependent variables; particle size (P.S), polydispersity index (PDI) and yield percentage (%yield), were fed into the utilized software and equations linking the dependent and independent variables were produced. The composition of the prepared formulations for the full experimental design is shown in Table2. Three Models were conducted; P.S, PDI and %yield respectively (Insert Table 2).
Table 2: Composition of the prepared nanovesicles (mg)
|
Formula |
PC (mg) | CHOL (mg) | Tween80 (mg) | Sodium deoxycholate (mg) | Cremophor (mg) | Oleic acid (mg) | ||
| Transfersomes prepared by thin film hydration method | Transethosomes prepared by thin film hydration method |
Transethosomes prepared by solvent dispersion method |
||||||
|
F 1 |
F 1e | Et 1 | 80 | 0 | 10 | 10 | 0 | 0 |
| F 2 | F 2e | Et 2 | 80 | 0 | 0 | 10 | 0 |
10 |
|
F 3 |
F 3e | Et 3 | 80 | 0 | 0 | 0 | 20 | 0 |
| F 4 | F 4e | Et 4 | 80 | 0 | 2.5 | 12.5 | 2.5 |
2.5 |
|
F 5 |
F 5e | Et 5 | 80 | 0 | 10 | 0 | 0 | 10 |
| F 6 | F 6e | Et 6 | 80 | 0 | 0 | 20 | 0 |
0 |
|
F 7 |
F 7e | Et 7 | 80 | 0 | 0 | 20 | 0 | 0 |
| F 8 | F 8e | Et 8 | 80 | 0 | 0 | 0 | 0 |
20 |
|
F 9 |
F 9e | Et 9 | 80 | 0 | 20 | 0 | 0 | 0 |
| F 10 | F 10e | Et 10 | 80 | 0 | 10 | 0 | 10 |
0 |
|
F 11 |
F 11e | Et 11 | 80 | 0 | 12.5 | 2.5 | 2.5 | 2.5 |
| F 12 | F 12e | Et 12 | 80 | 0 | 0 | 0 | 0 |
20 |
|
F 13 |
F 13e | Et 13 | 80 | 0 | 0 | 0 | 20 | 0 |
| F 14 | F 14e | Et 14 | 80 | 0 | 0 | 10 | 10 |
0 |
|
F 15 |
F 15e | Et 15 | 80 | 0 | 5 | 5 | 5 | 5 |
| F 16 | F 16e | Et 16 | 80 | 0 | 0 | 0 | 10 |
10 |
|
F 17 |
F 17e | Et 17 | 100 | 0 | 0 | 0 | 0 | 0 |
| F 18 | F 18e | Et 18 | 80 | 20 | 0 | 0 | 0 |
0 |
|
Et 19 |
80 | 0 | 0 | 0 | 20 | 0 | ||
| Et 20 | 80 | 0 | 3 | 1 | 13 |
3 |
||
|
Et 21 |
80 | 0 | 1 | 5 | 13 | 1 | ||
| Et 22 | 80 | 0 | 2 | 2 | 14 |
2 |
||
|
Et 23 |
80 | 0 | 1 | 1 | 17 | 1 | ||
|
Et 24 |
80 | 0 | 2.5 | 0 | 15 |
2.5 |
||
|
Et 25 |
80 | 0 | 6 | 8 | 4 | 2 | ||
| Et 26 | 80 | 0 | 3 | 14 | 2 |
1 |
||
Characterizations of the Prepared Vesicles
Determination of Phosphatidylcholine %yield. PC %yield was determined using the ultracentrifugation method using cooling centrifuge (Hermle, Germany) where 1ml sample of each formulation was placed in a 1.5ml eppendorf [17] and centrifuged at 4˚C at a speed of 14000rpm for 2hours [18]. The supernatant was collected. The vesicles were washed with 0.5ml ultrapure water and recentrifuged for 2hours. The supernatant was separated and its total volume was detected. An aliquot of 50µl of the total supernatant was diluted and peak area was measured using HPLC at λmax=205nm. The concentration was calculated according to the established calibration curve. Each sample was measured in triplicates and mean value was reported. %Yield was calculated as follows:
![]()
Particle Size, Polydispersity index and Zeta Potential (ZP) Measurement
An aliquot of a 1ml sample of the prepared formulation was ultra-centrifuged at 4˚C and 14000rpm for 2hours. Consequently, the supernatant was removed. The vesicles were washed with 0.5ml ultrapure water and recentrifuged for 2hours. The supernatant was removed and the vesicles were redispersed by vortexing for 10seconds. Afterwards, 0.35ml of the vesicles was diluted to 5ml with ultrapure water. P.S and surface charges of the nanovesicles were measured using Zeta-Sizer Nano-ZEN3600. The measurements were executed in triplicates for each sample and the average values were calculated [14;19].
Transmission Electron Microscopy (TEM)
The morphology of a dilute stock of selected nanovesicles was examined using electron transmission microscope TECNAI-G2 S-Twin (Netherlands) at 80KV after being stained with phosphotungstic acid [1].
Elasticity Test
The selected vesicles elasticity test was performed using the extrusion method[20] where the nanosuspension was extruded through Micropore cellulose membrane filter of 0.22µm at a constant flow of 115L/min. Deformability was reported as the deformability index (DI) calculated by following equation [21]:
DI=j×(rv/rp)2 (Equation2)
Where, j is the suspension flow rate, rv the vesicle size and rp the membrane pore size [20].
Stability testing of the prepared nanovesicles
Stability tests were performed for the selected formulae stored at 4˚C for 6months. The stability was assessed by measuring %yield, ZP, P.S and PDI. Measurements were executed in triplicates for each sample and the mean values were calculated [22].
Preparation of the nano-phosphatidylcholine vesicular gel:
The selected nanovesicles were centrifuged at 4ºC, 14000rpm for 2hours. The supernatant was removed and samples were redispersed using 0.5ml ultrapure water. Nanovesicular gel with 2%carbopol 934 was prepared using triethanolamine, methyl and propyl parabens [23]. The prepared gel was stored at 4˚C.
Characterizations of the nanovesicular gel:
Physical examination
The developed gel was tested for color, transparency, homogeneity by visual inspection [24].
pH measurement
The pH of 1%aqueous solutions of the prepared gels was measured using pH-meter (Jenway, UK) [25].
Viscosity Studies
The gel apparent viscosity was measured using Visco-star plus Viscometer (Fungilab, Barcelona) at room temperature. Readings were taken after 5min. Measurements were executed in triplicates [25].
Spreadability Test
Spreadability was assayed by pressing 0.5gm of gel between two glass slides till no more spreading occurs. Four diameters, for each of the formed circle, were measured and the average diameter was calculated. The mean of triplicates of each formulation was used as comparative values for spreadability [26].
Drug content determination
Drug content of the gel was quantified. 250mg of the prepared gel was mixed with 10ml water thoroughly. The produced solution was centrifuged for 30min at 6000rpm using Hermle centrifuge (Wehingen, Germany). The supernatant was then filtered, 0.5ml of supernatant was diluted. Drug content was determined using HPLC. The concentration was obtained using the established calibration curve at a λmax of 205nm [27].
Stability of the nanovesicular gel
Stability was studied after storage of the prepared gel at 4˚C for total periods of 3and 6months. The stability was assessed through measuring viscosity, pH and drug content. The measurements were executed in triplicate for each sample. Average values were obtained [22].
In-vivo studies on rats
Induction of obesity
Rats were randomly assigned to one of the two groups, the model group(n=42) or the control group(n=6). They were allowed free access to regular rat chow (the formula of low-fat diet) and tap water for 1week. The rats of control group were fed with rat chow. Other groups were fed with high-fat diet containing 70%lard. Meal administration continued for 4months. The criterion of successful induction of obesity was reaching 450±5gm body weight. Successful rats were divided into 4main groups (GpII to GpV). After obesity induction and during treatment period, all groups were fed with low-fat diet while model group was still fed with high-fat diet [28].
Treatment Groups
Adult male rats (50g±5) were divided into 5groups:
Group I: Control group (Allowed to low-fat diet without drug administration) and consists of 6rats
Group II: Model group (Allowed to high-fat diet without drug administration) and consists of 6rats.
Group III: Low-fat diet group (Allowed to high-fat diet and treated with low-fat diet without drug administration) and consists of 6rats.
Group IV: Market Treatment group (Allowed to high-fat diet and treated with low-fat diet & PC-market injection (Adipoforte®)) and consists of 6rats.
Group V: Introduced dosage form Treatment Group (Allowed to high-fat diet and treated with low-fat diet & PC new topical dosage form) and consists of 24rats. It was divided into 4subgroups (Group Va, Vb, Vc and Vd) for each formulation of the 4different selected formulations (F4e, F11e, Et11 and Et20) respectively. Each subgroup consists of 6rats.
Treatment and drug delivery
According to Lu,2014 [1], the abdominal hair was shaved and then intervened by drug application. Animals in the model group (GrpII) were massaged with the same amount of water on the abdomen in a clockwise direction. Animals in (GrpIII) were not treated with any massage or drug administration. The rats in the market treatment group (GrpIV) were injected subcutaneously with Adipoforte® at a dose of 0.85mg/day [29] for 8weeks. GrpV received PC new topical formulation at a dose equivalent to 0.85mgPC/day. Treatment was administered at the morning for 8weeks [30, 31]. Rats were weighed 2times/week before drug administration using electronic balance TE-612 (Sartorius AG, Germany) [1].
Skin irritation test
For skin irritation test, 36rats were divided into 3groups:
Group I: Control Group and consists of 6rats
Group IV: Market Treatment Group and consist of 6rats.
Group V: Introduced dosage form Treatment Group and consists of 24rats. It was divided into 4subgroups (Group Va, Vb, Vc and Vd) for each of the four different selected formulations (F4e, F11e, Et11 and Et20) respectively. Each subgroup consists of 6rats. Amount of gel equivalent to 0.85mg PC was applied to shaved area of group V (n=6 for each formula of prepared PC vesicular gel); same way control gel was applied to group I for the determination of irritation characteristics and hypersensitivity reaction on the skin. Group IV was injected with market PC injection (Adipoforte®). The visual observation was carried out at regular interval of 10, 24 and 48hours [24]. The erythema and edema were scored as follows: none=0, slight=1, well defined=2, moderate=3, and 4 for severe erythema, edema and scar formation [32].
Dorsal fat percentage and total lipid content analysis
At the end of treatment, rats were weighed and sacrificed. Dorsal adipose tissues were removed and weighed (wet weight of dorsal fats) after excess blood and tissue fluids were dried by filter paper. Dorsal fat percentage (PDF) was calculated[1].
![]()
The dorsal adipose tissue was digested in hot 30%KOH using homogenizer (Wiggenhauser, Germany) and then acidified. The produced homogenate was centrifuged for 2hours at 6000rpm. Total Lipid content was extracted with chloroform-methanol (2:1respectively) where organic phase was isolated and evaporated to dryness using rotary evaporator (Buchi, Switzerland). The total remaining lipid content was weighed [33].
Statistical Analysis
Data statistical analysis was performed with nonparametric one-way ANOVA test. Results were expressed as mean ±SD. All statistical tests were two-sided.
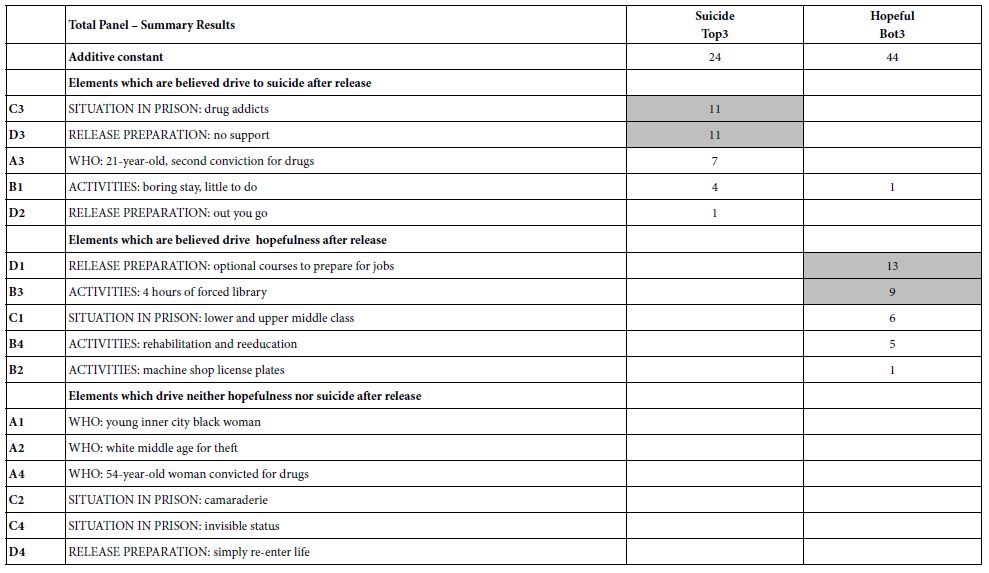
Results
%Yield Model for transfersomes (formulations code starting with F)
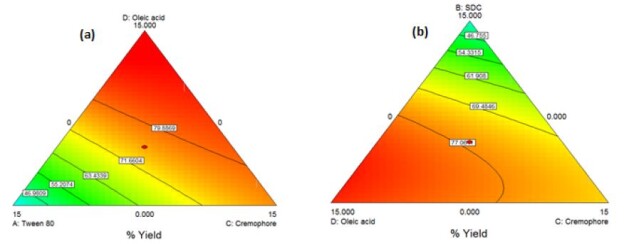
The obtained model was a quadratic one. By applying ANOVA test, it was nonsignificant(P=0.04) though with a desired nonsignificant lack of fit. All the linear mixture components: A, B and D were significant while C and other quadratic terms: AB, AC, AD, BC, BD and CD were nonsignificant. Accordingly, model reduction was carried out and ANOVA was reconducted. A significant model was obtained with a desired nonsignificant lack of fit. The results modeling showed r2 of 0.700, adjusted r2 of 0.55 and a predicted r2 of 0.44. The predicted r2 is in a reasonable agreement with the adjusted r2 (Difference between them<0.2). The Box-Cox plot for power transforms demonstrated the approximate coincident of the current lambda (1) with the best lambda (1.14) lying within the confidence intervals (-0.17to2.99) [34]. The obtained contour plots are shown in Figure1 (Insert Figure 1).
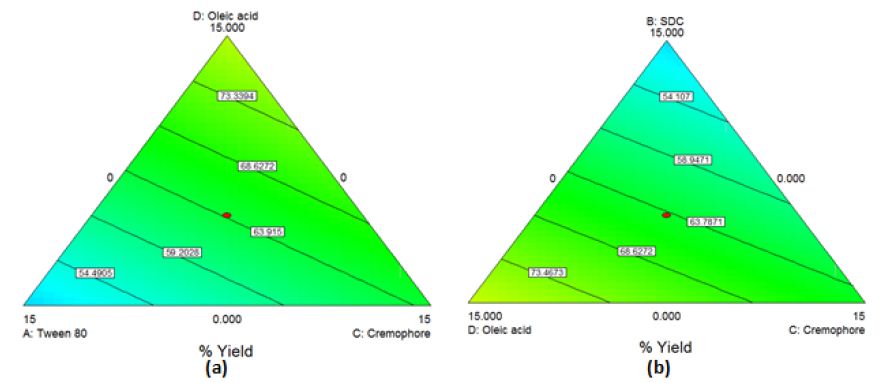
Figure 1: Contour Plot demonstrating the effect of (a)Oleic acid, cremophor and Tween 80 (b)Oleic acid, cremophor and SDC on the %yield of PC-transfersomes
The obtained Model Equation obtained was:
%Yield=2.502*Tween80+2.451*SDC+3.486*Cremophor+4.387*Oleicacid (Equation4)
%Yield Model for transethosomes (formulations code starting with Fe)
The obtained model was a quadratic one. By applying ANOVA test, it was significant(P<0.0001) with a desired nonsignificant lack of fit. All the linear mixture components: A, B, C and D besides the terms AB, AC, AD, BC and BD were significant. The CD quadratic term was nonsignificant. Accordingly, model reduction was carried out and ANOVA was reconducted. A significant model was obtained with a desired nonsignificant lack of fit. The results modeling was successful as demonstrated by the values of r2 (0.98), adjusted r2 (0.96) and predicted r2 (0.76). The predicted r2 is in a reasonable agreement with the adjusted r2. The Box-Cox plot for power transforms demonstrated the approximate coincident of the current lambda (1) with the best lambda (1.32) lying within the confidence intervals (0.41to2.61). The obtained contour plots are shown in Figure2 (Insert Fig 2).
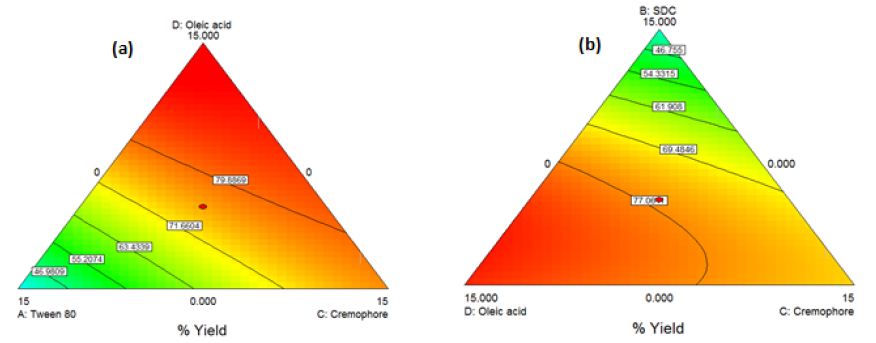
Figure 2: Contour Plot demonstrating the effect of (a)Oleic acid, cremophor and Tween 80 (b)Oleic acid, cremophor and SDC on the %yield of PC-transethosomes prepared by thin film hydration
The obtained Model Equation obtained was:
![]()
%Yield Model for transethosomes (formulations code starting with Et)
The obtained model was a quadratic one. By applying ANOVA test, it was significant(P=0.0056) but with a non-desired significant lack of fit. All the linear mixture components: A, B, C and D besides the term AC were significant. The other quadratic terms: AB, AD, BC, BD and CD were nonsignificant. Accordingly, model reduction was performed. This time a significant model was obtained with a higher p-value for lack of fit but still significant. The modeling of the results was successful as demonstrated by the values of r2 (0.81), adjusted r2 (0.74) though the predicted r2 was low (0.31). The Box-Cox plot for power transforms demonstrated the approximate coincident of the current lambda (1) with the best lambda (1.33) lying within the confidence intervals (-0.15to2.96). The obtained contour plots are shown in Figure3.
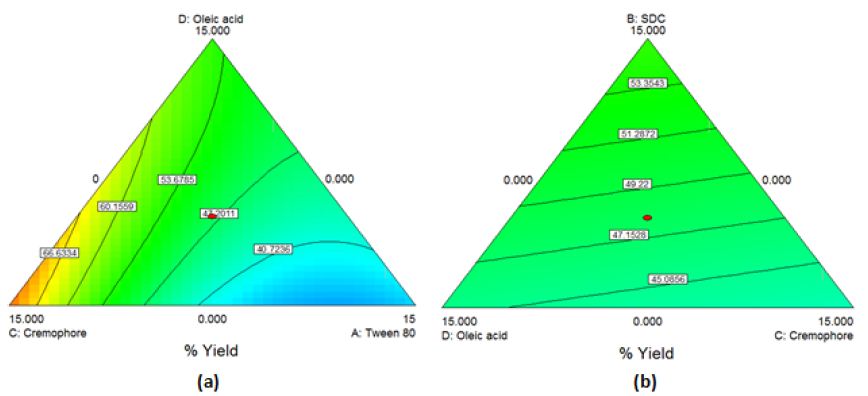
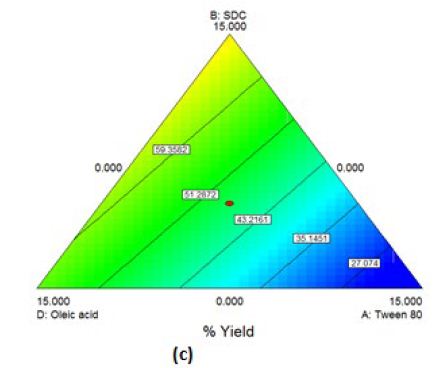
Figure 3: Contour Plot demonstrating the effect of (a)Oleic acid, cremophor and Tween 80 (b)Oleic acid, cremophor and SDC (c)Oleic acid, Tween 80 and SDC on the % yield of PC-transethosomes prepared by solvent dispersion
The model equation obtained was:
%Yield=1.396*Tween80+3.229*SDC+3.798*Cremophore+2.567*Oleicacid0.279*Tween80*Cremophore (Equation6)
Validation of experimental design
Eight new formulations (Et19-Et26) were chosen. The actual %yield, P.S and PDI were compared with the predicted values. For %yield model, the obtained values were comparable to the predicted counterparts, these results ensured the validity of the %yield model with a mean %bias of 7.4%. For P.S and PDI models, the overall mean was considered a better predictor of the response than the obtained models due to the obtained negative predicted r2. Thus, these models are not reliable [35] and were considered as reported values.
Zeta Potential
ZP give indication about surface charge type and magnitude [36] which can affect both vesicular stability and skin-vesicle interactions[8;37]. Vesicles showed highly negative charges ranging from -31 to -72.5mV for the prepared transfersomes (F), -24.8 to -53mV for the prepared transethosomes (Et) and ranging from -23.2 to -64.2mV for the prepared transethosomes (Fe). For the transethosomal formulations (Et21 to Et26), no significance difference was observed in their ZP(P>0.05).
Selection of the formula of choice
From the data shown in Table3, it was found that transethosomes (F4e, F11e, Et11 & Et20) showed SD<10% of the mean of the evaluated parameters indicating their reproducibility. Their P.S ranged from 200 to 480nm, so they can reach the skin subcutaneous layer and become entrapped. Besides, their ZP range is between -41.8mV and -53.2mV ensuring particle stability with reduced mutual aggregation. Moreover, they have PDI around 0.3 ensuring low variability. Their %yield ranged between 31.3% to 63.89%, on which the dose will be calculated. Consequently, F4e, F11e, Et11 & Et20 were selected as formulations of choice on which further studies were done.
Elasticity Test
The elasticity results are shown in Table4. The chosen formulations showed a high deformability index ranging from 70.8976±4.29 to 137.1707±6.14 (Insert Table 3 & 4).
Table 3: Characteristics of the selected vesicles
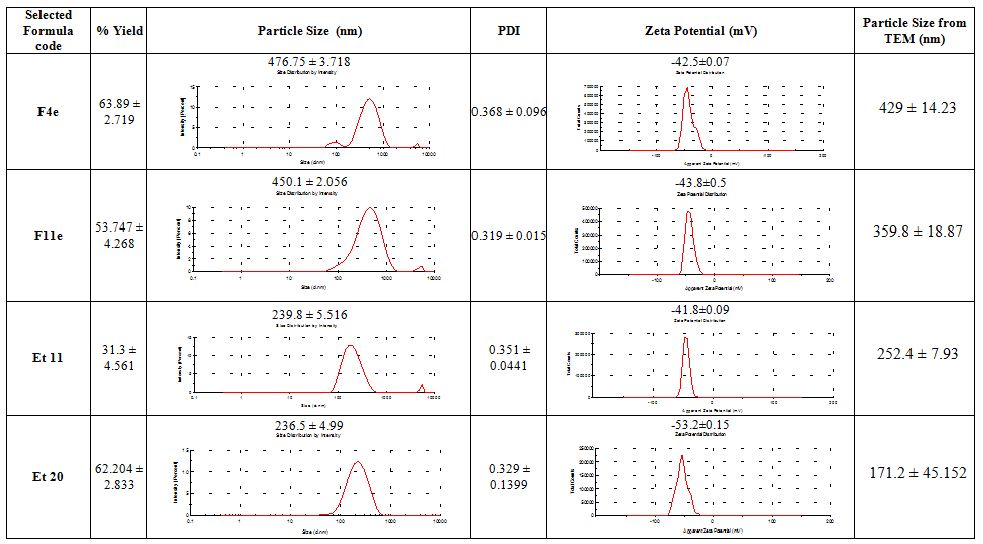
Table 4: Particle size and Deformability Index of the selected vesicles before and after extrusion
| Formula Code |
Particle Size (nm) |
Deformability Index (DI) | Average DI ± SD | |
| Before Extrusion |
After Extrusion |
|||
| F4e |
476.8 ± 3.72 |
176.73 | 74.2118 | 70.8976 ± 4.29 |
| 174.6 |
72.43 |
|||
| 166.73 |
66.051 |
|||
| F11e |
450.1 ± 2.06 |
235.6 | 131.887 | 137.1707 ± 6.14 |
| 239 |
135.72 |
|||
|
246.13 |
143.905 |
|||
| Et11 |
239.8 ± 5.52 |
188.3 |
84.25 |
88.4467 ± 4.26 |
|
197.6 |
92.77 |
|||
| 192.8 |
88.32 |
|||
| Et20 |
236.5 ± 4.99 |
189.6 | 85.41 |
84.26133± 2.72 |
Transmission Electron Microscopy
The morphology of the four selected formulations is shown in Figure4. The imaging analysis showed unilamellar vesicles possessing a thin lipid layer that is hydrated forming enclosed vesicular structure whose shape ranges from spherical to oval with some irregular shapes and black precipitates (Insert Fig 4).


Figure 4: TEM micrographs of formulation (a)F4e, (b)F11e, (c)Et11, (d)Et20
Stability test
The stability of the selected formulae was evaluated by macroscopic inspection and by measuring their P.S, PDI and %yield monthly and ZP every 3months for 6months storage at 4˚C. At room temperature, fungal growth appeared after the first month. An adequate stability of the selected transethosomes (F4e, F11e, and Et11) was observed with nonsignificant change regarding their P.S, PDI, %yield and ZP through the 6months of storage at 4˚C(P-value>0.05). Transethosome formula (Et20) showed nonsignificant differences regarding PDI, %yield and ZP throughout the 6months (P-value=0.4279, 0.4344, 0.4291, 0.4225, 0.4287 & 0.4247) but showed a highly significant change in P.S compared to P.S of original samples throughout the 6months (P-value=0.0009, 0.0002, 0.0091, 0.0077, 0.0068 & 0.0091).
Characterizations of nanovesicular gel
All prepared gels were translucent, smooth, and consistent in appearance with pleasant acceptable odor and without appearance of any clumps nor phase separation.
pH Measurement
The pH of all prepared gels was found to range from 8.24±0.36 to 8.78±0.14.
Viscosity Studies
The prepared gel viscosity ranged from 71254±4cps to 77183±3cps ensuring the successful preparation of the gel structure.
Spreadability Test
The prepared gel spreadability was measured in terms of average diameter of the spread circle. The longer the diameter, the better the spreadability [26]. Measurements lie between 3.43±0.14cm and 3.75±0.13cm indicating good spreadability properties.
Drug content determination
Drug content of PC was found to be 94.53±0.02%, 95.476±0.1%, 95.43±0.35%, and 96.875±0.1% for F4e, F11e, Et11 and Et20 gels respectively.
Stability Studies of gel
Nanovesicular gel color, consistency, pH, drug content and viscosity were evaluated after 3and 6months of storage at 4˚C [24]. The prepared gels were consistent with no signs of phase separation or deterioration.
In-vivo studies on rats
In–vivo studies of PC-vesicular gel formulations containing F4e, F11e, Et11 and Et20 were performed and results are presented in Table (5,6) and Figure (5–8).
Induction of obesity
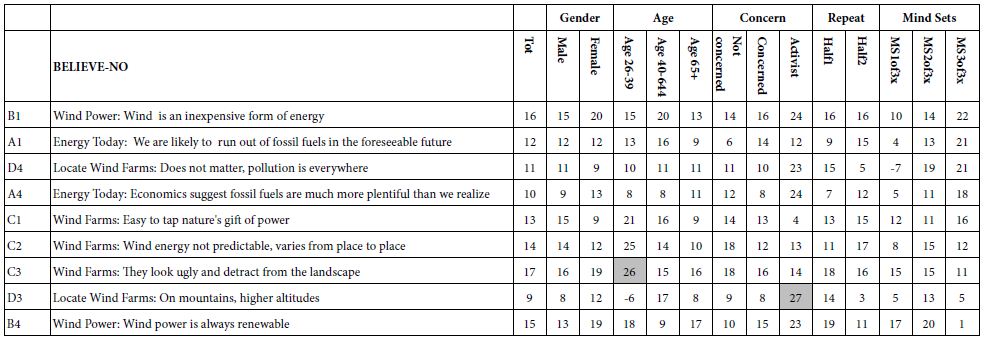
As shown in Table5 & Figure 6(a), the body weights were similar among all groups before initiation of high-fat diet(P>0.05). At the end of 4months on high-fat diet, the body weight of obese rats (GpII-V) significantly increased compared to control group (GpI)(P<0.0001).
Table 5: Rats body weight changes before and after treatment
|
Rat Group |
Initial body weight | Body weight before high fat diet | Body weight after high fat diet | Body weight after treatment | %weight loss |
| Control | 51.3 ± 2.43 | 74.1233 ± 5.437 | 227.016 ± 5.937 |
297.08 ± 27.648 |
|
|
Model |
50.92 ± 3.64 | 76.0775 ± 7.0175 | 451.865 ± 3.4027 | 462.917 ± 24.076 | |
| Diet only | 451.95 ± 2.3036 | 418.833 ± 51.219 |
7.328 |
||
|
Injected |
449.417 ± 3.11 |
397.33 ± 38.867 |
11.59 |
||
|
F4e |
452.03 ± 3.1123 | 356.667 ± 62.67 |
21.097 |
||
|
F11e |
451.383 ± 3.517 | 394.33 ± 23.157 | 12.64 | ||
| Et 11 | 450.433 ± 4.9066 | 379.833 ± 34.649 |
15.6 |
||
|
Et 20 |
450.817 ± 3.414 | 394.5 ± 29.751 |
12.4 |
Skin irritation test
In the control (GpI) and treated (GpVa to Vd) groups, the erythema score was 0 and no irritation signs appear through the total examination period (Figure5(a) and (b) respectively). In grpIV, that was injected with Adipoforte®, slight erythema with score 1 appear after 24hours in 50% of the group (Figure5(c)). After 48hours, a hard scar appeared with erythema score of 4 ((Figure5(d), (e) and (f)) forming hard nodules or lesion that disappeared after 3days (Insert Figure 5).
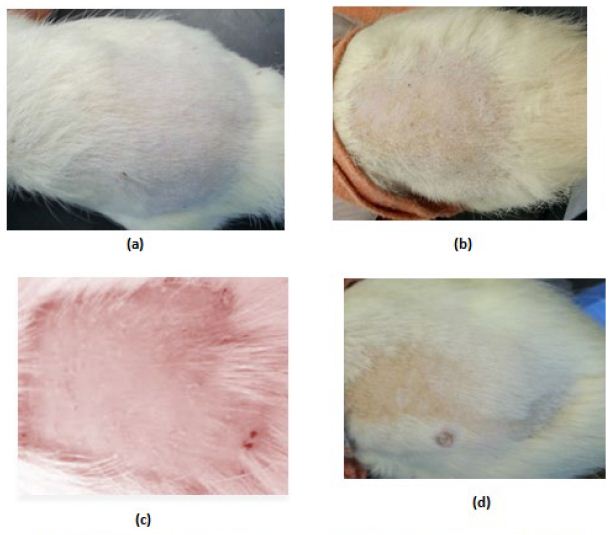
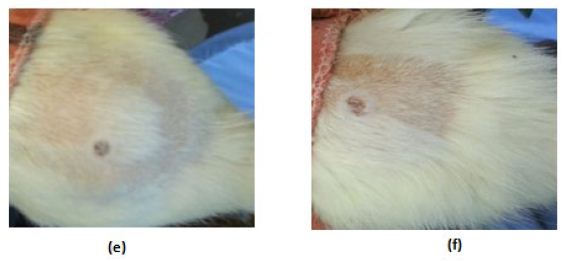
Figure 5: Irritation score zero in (a)control group (Gp I), (b)treated groups (GpVa-Vd), (c)Irritation score 1 in injected group (Gp IV) after 24hours, (d,e,f)Irritation score 4 in injected group (Gp IV) after 48hours
Treatment and drug delivery
As shown in Table5 & Figure6, the body weight of obese rats (GpVa) after obesity treatment showed nonsignificant difference compared to the control group (P=0.1647). In comparison to the model group (GpII), the body weight of the treated groups (i.e. GpVa and Vc) was reduced significantly (P<0.05) with %weight loss of 21.097% and 15.6% respectively. On the other hand, there was nonsignificant difference in weight reduction between the model group (GpII) and the group treated with diet only (GpIII)(P=0.5142) whose body weight decreases by 7.328%. There was nonsignificant difference in weight reduction between the model group (GpII) and the group treated with injection (GpIV)(P=0.0932). There was nonsignificant difference in weight reduction between the model group (GpII) and the group treated with prepared topical formulations containing F11e, Et20 (GpVb and Vd) (P=0.0686 & P=0.0698 respectively) whose body weight decreases by 12.64% and 12.4% respectively. There was nonsignificant difference between the diet group (GpIII) and treated groups (GpV)(P>0.05) (Insert Table 5& Fig 6).
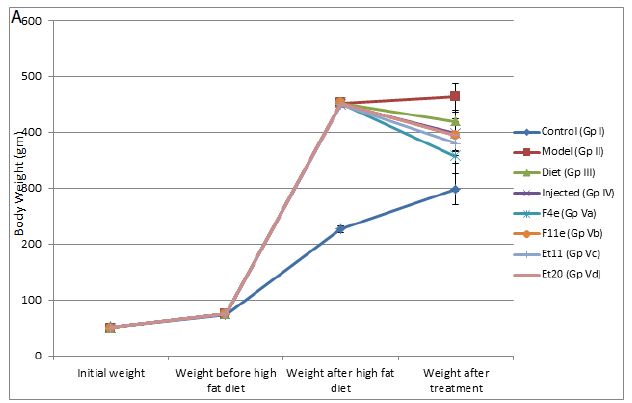
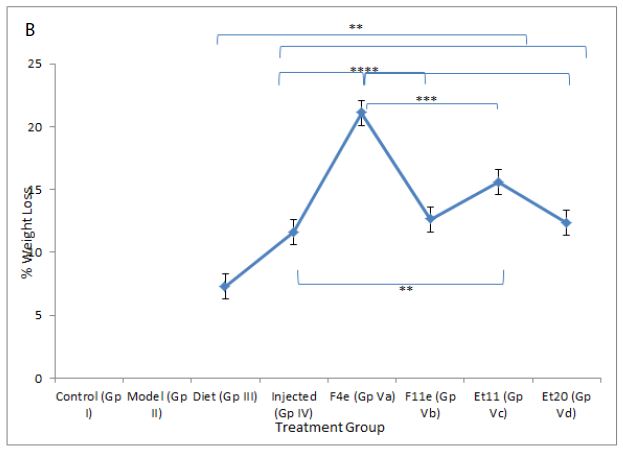
Figure 6: ** P value ≤ 0.01 indicating significant difference
*** P value ≤ 0.001 indicating highly significant difference
**** P value ≤ 0.0001 indicating an extremely significant difference
(a)Body weight changes among treatment groups, (b)%weight loss changes among different treatment groups after end of treatment
Dorsal Fat Percentage and total lipid content
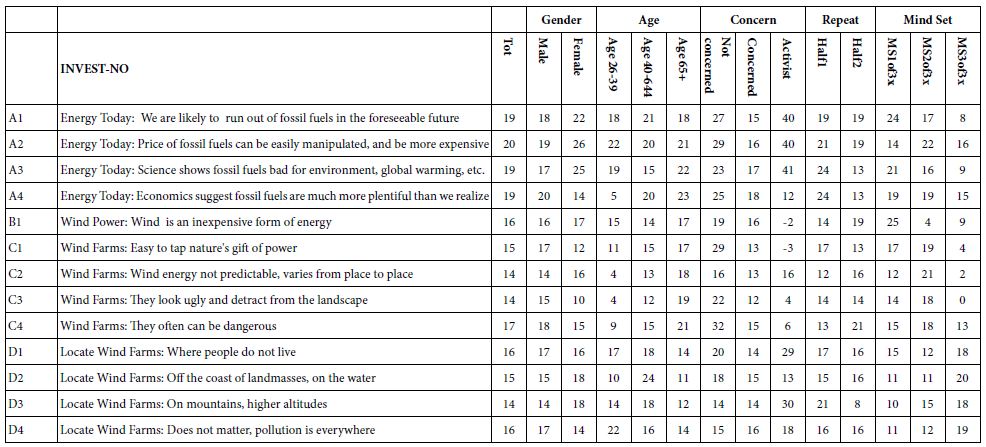
According to %PDF, a highly significant difference between the control group and other groups (P<0.0001) appeared as shown in Table6, and Figure7. The %PDF of the injected obese rats (GpIV) was nearly equal to that of the control group by the end of treatment (P>0.9999). On comparing model group (GpII) with the treated groups, the %PDF of the treated groups (GpIV and V) reduced significantly(P<0.0001). As shown in Table6 and Figure8, the total Lipid content of the treated groups (GpIII, IV and V) reduced significantly (P<0.0001) compared to model group. Meanwhile, there was a highly significant difference between the control group (GpI) and the model, diet and injected groups (GpII, III, and IV) (P<0.0001). Interestingly, the total lipid content of the control group (GpI) compared to the treated group with PC vesicular gel (GpV) showed nonsignificant difference (P>0.05). Total lipid content in rat group treated with diet only (GpIII)(4.834±0.403g) decreased to half that of the model group (GpII)(9.05±0.7319g). On comparing model group (GpII) with injected group (GpIV) and invented new dosage form group (GpV), total lipid content decreased in group IV and group V by 67.96% and 88.398% respectively reaching in the latter group a comparable value as that of control group (GpI) (Insert Table 6& Fig 7-8).
Table 6: Comparison of obesity parameters among groups
|
Rat Group |
Rat weight (gm) | Fat tissue wet weight (gm) | Total Lipid content weight (gm) | |
| Control | 297.08 ± 27.648 | 2.286 ± 0.2034 | 0.7754 ± 0.1029 |
1.552 ± 0.266 |
|
Model |
462.917 ± 24.076 | 9.366 ± 0.6992 | 2.0218 ± 0.074 | 9.05 ± 0.7319 |
| Diet only | 418.833 ± 51.219 | 5.387 ± 0.707 | 1.3098 ± 0.2772 |
4.834 ± 0.403 |
|
Injected |
397.33 ± 38.867 | 3.1 ± 0.4406 | 0.781 ± 0.0893 | 2.9 ± 0.5168 |
| F4e | 356.667 ± 62.67 | 1.218 ± 0.604 | 0.3305 ± 0.1151 |
1.103 ± 0.488 |
|
F11e |
394.33 ± 23.157 | 1.294 ± 0.486 | 0.3245 ± 0.1104 | 1.102 ± 0.4028 |
| Et 11 | 379.833 ± 34.649 | 1.099 ± 0.346 | 0.2845 ± 0.0693 |
1.019 ± 0.3044 |
|
Et 20 |
394.5 ± 29.751 | 1.169 ± 0.3592 | 0.292 ± 0.0708 |
1.094 ± 0.307 |
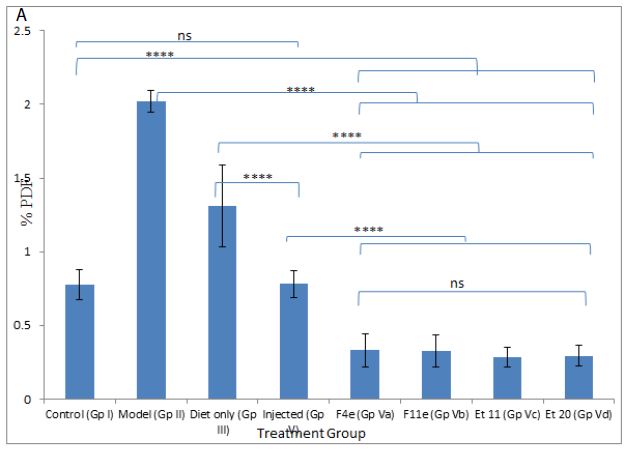
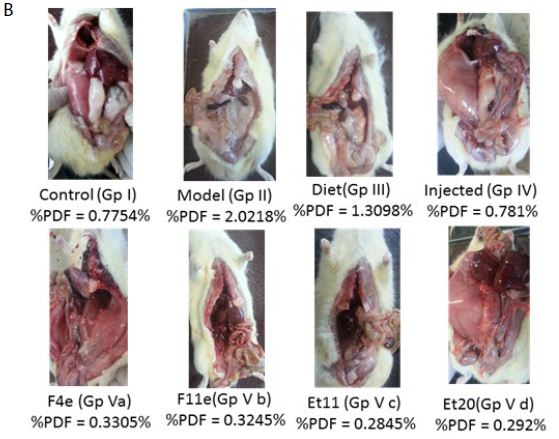
Figure 7: ns P value > 0.05 indicating no significant difference
**** P value ≤ 0.0001 indicating an extremely significant difference
(a) Changes in %PDF among different groups, (b)%PDF obtained for all treatment groups
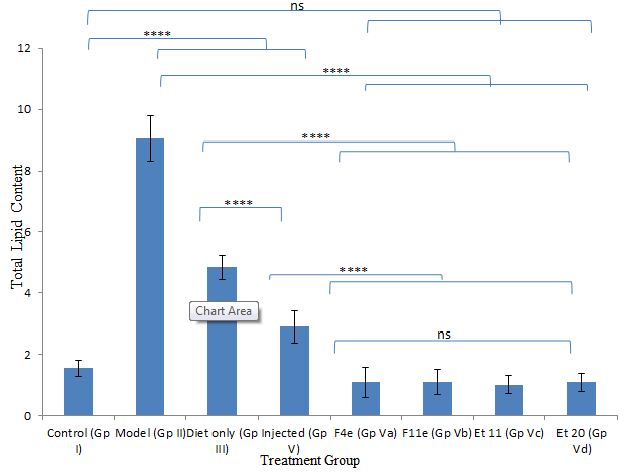
Figure 8: ns P value > 0.05 indicating no significant difference
**** P value ≤ 0.0001 indicating an extremely significant difference
Changes in total lipid content among different treatment groups
Discussion
The contour plots obtained confirm the interaction effects of the used oils and edge-activators in increasing the %yield of the prepared transfersomes and transethosomes. For the three types of prepared vesicles, the area of high %yield lies between oleic acid and cremophor which indicates that by increasing their percentage, the %yield increases. Increasing the percentage of Tween 80 decreases the %yield demonstrated by the blue area close to its apex. For transfersomes and transethosomes prepared by thin film hydration method, increasing SDC decreases %yield demonstrated by the blue area close to its apex where increasing tween 80 and SDC causes lipid layer destabilization leading to reduced %yield [22, 38]. Also, increasing the concentration of some edge-activators beyond certain threshold leads to formation of micelles instead of vesicles causing solubilization of the phospholipids [19, 39]. This can be attributed to cremophor bulky structure which provides rigidity to the vesicles leading to higher P.S increasing %yield [40]. According to literature, increasing HLB value as in the case of cremophor [41] increases the P.S which can in turn increase %yield by increasing hydrophilicity, enhancing surface free energy[39]. Increasing SDC, in transethosomes prepared by solvent dispersion method, increases %yield demonstrated by the yellow area close to its apex where SDC increases the whole lipid bilayer volume increasing P.S causing increase in %yield [42]. For good physical stability [43], ZP should not be less than -30 or +30mV [37] and on approaching -60mV [44], vesicles obtain an excellent physical stability through shelf life preventing aggregation [45]. This means that all formulations are stable except (F1e, F10e, F13e, Et3, Et10, Et13 and Et14). This can be attributed to the presence of edge-activators [8]; tween 80 was reported to cause decrease in ZP, although it is a nonionic surfactant [46] due to its oxyethylene part[47]. Oleic acid was reported to produce negative ZP [6;48]. Using SDC produces high negatively charged vesicles due to the presence of cholate anions [47]. Although PC is zwitterionic compound with an isoelectric point (6-7), PC carried a net negative charge under experimental conditions of pH7.4 [12;39] due to the negatively charged phosphate group[43;49]. For transethosomes, ethanol produces negative charges on vesicles [14;45]. These negatively charged vesicles enhances skin permeation of drugs [12]. Lipid bilayer elasticity affects permeation enhancing skin penetration[47]. The edge-activator chemical structure affects vesicles deformability where flexible non-bulky carbon chain gives more fluidity to the membrane bilayer compared to bulky cyclic edge-activators [39]. Transethosomal formula (F11e) show the highest DI followed by Et11 then Et20 and finally F4e showing the least DI. This can be attributed to the high concentration (12.5%) of tween 80 with its highly flexible and non-bulky hydrocarbon chains [20] which aid in their squeezing along the stratum corneum and localization at high concentration in the deepest skin layers [47, 50]. Although Et11 and F11e have the same percentage of Tween 80, F11e has a higher ethanol volume (5ml) than Et11 (1.5ml) where increasing ethanol content increases lipid bilayer elasticity [8, 51]. Et20 showed lower DI compared to F11e due to high concentration of cremophor (12.5%) with its bulkier structure compared to Tween 80[40]. F4e showed the lowest DI with the highest percentage of P.S change comparing P.S before (476.75±3.718nm) and after extrusion (172.69±5.27nm) whereas %P.S change increases, DI decreases. This can also be due to high concentration of SDC (12.5%) with its steroid-like structure [52]. The use of oleic acid and ethanol provides high elasticity [51]. The TEM micrographs show a highly recognized vesicles in the nanometer range which agreed with the size data obtained using dynamic light scattering (DLS) and ensures vesicle formation at the used concentrations of ethanol and edge-activators [8]. Deviation of particle shape from spherical form is due to lipid modification during sample drying for imaging [45] and being highly deformable [43, 47]. The slight change in size can be attributed to the samples drying prior imaging [53]. The appearance of black precipitates may be due to precipitation of phosphotungstic acid in hydrophilic core [53, 54]. The selected transethosomes (F4e, F11e, and Et11) adequate stability can be due to their high ZP [44, 45]. Transethosome formula (Et20) shows a highly significant change in P.S compared to freshly prepared samples throughout the 6months (P-value=0.0009, 0.0002, 0.0091, 0.0077, 0.0068 & 0.0091), however, it is still in the size range targeting skin subcutaneous layer (185-460nm) [1]. It was reported that high cremophor concentration causes physical instability [55] due to enhanced water penetration into vesicle increasing P.S upon storage [56]. The pH of the prepared gel lies in the physiologically accepted range of 5-9 [57, 58]. Gel viscosity affects the extrudability, drug release [27] and vesicles delivery onto or across the skin [45]. The prepared gel high viscosity, due to the presence of lipid vesicles [39], facilitates the retention of gel on the skin for better skin penetration. The prepared gel spreadability indicates that the gel is easily spread by low shear[24] with uniform spreadability [26, 32]. Drug content results show homogenous dispersion of vesicles in gel[39] indicating the suitability of method used for gel preparation [27, 59]. On comparing the original results and those obtained after storing gel for 3and 6months, nonsignificant change was observed in the above mentioned parameters (P-value>0.05) ensuring stability over 6months [59]. Average body weights after high-fat diet, shown in Table5 column4, shows about 50% increase compared to the normal control group (GpI) indicating the successful establishment of obesity model by feeding the animals with high-fat chow containing 70%lard [1]. In comparison to the model group (GpII), the body weight of the treated groups (GpVa and Vc) was reduced significantly (P<0.05) with %weight loss of 21.097% and 15.6% respectively indicating their ability to reduce body weight. On the other hand, there was nonsignificant difference in weight reduction between the model group (GpII) and the group treated with diet only (GpIII)(P=0.5142) whose body weight was decreased by 7.328% which is in coordinance with previous studies which stated that diet regimens failed to act on localized obesity [5]. Skin irritation test was conducted to assess the potential irritant effect of PC vesicular gel formulations [22]. The appearance of hard scar in rats injected with PC-market injection, confirms lack of patient compliance of injection lipolysis for treatment of localized obesity which is in accordance with previous experiments which reported that localized adverse effects were described as “very mild’(18.4%) or “mild”(39.2%) [60]. According to observed changes in body weight, %PDF and total lipid content observed, the topical application of PC vesicular gel, revealed the ability of newly prepared gel containing transethosomes (F4e, F11e, Et11 & Et20) to significantly decrease localized fat. This confirms the successful penetration of vesicles into the skin subcutaneous layer that can be attributed to the solvent action of ethanol, used in preparation of transethosomes on stratum corneum, in addition to the high deformability and malleability of these vesicles. This aids in their squeezing along the stratum corneum and localizing at high concentrations in subcutaneous layer producing their lipolysis effect[15].
Conclusion
PC nanovesicular gel, containing transethosomes (F4e, F11e & Et11), can be used as effective non-invasive treatment for localized obesity as an alternative to multi-injections for mesotherapy.
Conflict of Interest
No conflict of interest associated with this publication and there has been no significant financial support for this work that could have influenced its outcome.
References
- Lu K, Xie S, Han S, Zhang J, Chang X, et al. (2014) Preparation of a nano emodin transfersome and study on its anti-obesity mechanism in adipose tissue of diet-induced obese rats. Journal of translational medicine 12 : 1-14. [crossref]
- Nikoloski Z, Williams G (2016) Obesity in Middle East. In Metabolic Syndrome. Switzerlands: Springer.
- Rittes PG, Rittes JNC, Amary MFC (2006) Injection of phosphatidylcholine in fat tissue: experimental study of local action in rabbits. Aesthetic plastic surgery 30 : 474-478. [crossref]
- Hasengschwandtner F (2005) Phosphatidylcholine treatment to induce lipolysis. Journal of Cosmetic Dermatology 4 : 308-313. [crossref]
- Abel MR (2012) Evaluation of the Efficacy of Injection Lipolysis using Phosphatidylcholine/Deoxycholate Versus Deoxycholate Alone in Treatment of Localized Fat Deposits. Journal of Clinical & Experimental Dermatology Research 3 : 1-9.
- Shilakari G, Singh D, Asthana A (2013) Novel vesicular carriers for topical drug delivery and their applications. International Journal of Pharmaceutical Sciences Review and Research 21 : 77-86.
- Uchechi O, Ogbonna JD, Attama AA (2014) Nanoparticles for dermal and transdermal drug delivery. Sezer, AD eds; pg : 193-235.
- Shaji J, Garude S (2014) Transethosomes and Ethosomes for Enhanced Transdermal Delivery of Ketorolac Tromethamine: A Comparative Assessment. International Journal of Current Pharmaceutical Research 6 : 88-93.
- Descalzo AM, Insani EM, Pensel NA (2003) Light-scattering detection of phospholipids resolved by HPLC. Lipids 38 : 999-1003. [crossref]
- Jangle RD, Galge RV, Patil VV, Thorat BN (2013) Selective HPLC method development for soy phosphatidylcholine fatty acids and its mass spectrometry. Indian journal of pharmaceutical sciences 75 : 339-345. [crossref]
- Abdel-Hafez SM, Hathout RM, Sammour OA (2018) Curcumin-loaded ultradeformable nanovesicles as a potential delivery system for breast cancer therapy. Colloids and Surfaces B: Biointerfaces 167 : 63-72. [crossref]
- Shaji J, Lai Maria (2014) Preparation, Optimization and evaluation of transferosomal formulation for enhanced transdermal delivery of a COX-2 Inhibitor. Int J Pharm Pharm Sci 6 : 467-477.
- Pal R, Pandey M (2015) Transferosomes: A Novel Carrier For Enhanced Dermal Delivery of Drug. World Journal oof Pharmacy and Pharmaceutical Sciences 4 : 1816-1832.
- Kaur A, Jain SK, Pandey RS (2012) Aceclofenac Encapsulated Ethanolic Nano-Vesicles for Effective Treatment of Osteoarthritis. International Journal of Pharmaceutical Sciences and Research 3 : 2562-2567.
- Bragagni M, Mennini N, Maestrelli F, Cirri M, Mura P (2012) Comparative study of liposomes, transfersomes and ethosomes as carriers for improving topical delivery of celecoxib. Drug delivery 19 : 354-361. [crossref]
- Safwat S, Hathout RM, Ishak R, Mortada N (2016) Augmented simvastatin cytotoxicity using optimized lipid nanocapsules: a potential for breast cancer treatment. Journal of liposome research 27 : 1-10. [crossref]
- Abdallah MH (2013) Transfersomes as a Transdermal Drug Delivery System for Enhancement the Antifungal Activity of Nystatin. Int J Pharm Pharm Sci 5 : 560-567.
- Argan N, Harikumar SL (2012) Topical Liposomal Gel: A Novel Drug Delivery System. International Journal of Research in Pharmacy and Chemistry 2 : 383-400.
- Chaudhary H, Kohli K, Kumar V (2013) Nano-transfersomes as a novel carrier for transdermal delivery. International journal of pharmaceutics 454 : 367-380. [crossref]
- Elazreg R, Soliman M, Mansour S, El Shamy A (2015) Preparation and evaluation of mucoadhesive gellan gum in-situ gels for the ocular delivery of carbonic anhydrase inhibitor nanovesicles. International Journal of Pharmaceutical Sciences and Research 6.
- Naguib SS, Hathout RM, Mansour S (2017) Optimizing novel penetration enhancing hybridized vesicles for augmenting the in-vivo effect of an anti-glaucoma drug. Drug delivery 24 : 99-108. [crossref]
- Tsai MJ, Huang YB, Fang JW, Fu YS, Wu PC (2015) Preparation and Characterization of Naringenin-Loaded Elastic Liposomes for Topical Application. PloS one 10 : 1-12.
- RAJESH B, Saumya D, Dharmajit P, PAVANI M (2014) Formulation Design and Optimization of Herbal Gel containing Albizia Lebbeck Bark Extract. International Journal of Pharmacy and Pharmaceutical Sciences 6 :111-114.
- SINGH A, Vengurlekar P, Rathod S (2014) Design, Development and Characterization of Liposomal Neem Gel. International Journal of Pharma Sciences and Research 5 : 140-148.
- Shankar NB, Kumar RP, Kumar NU, Brata BB (2010) Development and characterization of bioadhesive gel of microencapsulated metronidazole for vaginal use. Iranian journal of pharmaceutical research: IJPR 9 : 209-219. [crossref]
- Soliman SM, Malak NA, El-Gazayerly ON, Rehim AA (2010) Formulation of microemulsion gel systems for transdermal delivery of celecoxib: In vitro permeation, anti-inflammatory activity and skin irritation tests. Drug Discov Ther 4 : 459-471. [crossref]
- Rajan R, Vasudevan DT (2012) Effect of permeation enhancers on the penetration mechanism of transfersomal gel of ketoconazole. Journal of advanced pharmaceutical technology & research 3 : 112-116. [crossref]
- Wilkes JJ, Bonen A, Bell RC (1998) A modified high-fat diet induces insulin resistance in rat skeletal muscle but not adipocytes. American Journal of Physiology-Endocrinology And Metabolism 275 : E679-E686. [crossref]
- Rittes P (2001) The use of phosphatidylcholine for correction of lower lid bulging due to prominent fat pads. Dermatologic surgery 27 : 391-392. [crossref]
- Co A, Abad-Casintahan M, Espinoza-Thaebtharm A (2007) Submental fat reduction by mesotherapy using phosphatidylcholine alone vs. phosphatidylcholine and organic silicium: a pilot study. Journal of Cosmetic Dermatology 6 : 250-257. [crossref]
- Karl G (2005) Efficacy of injections of phosphatidylcholine into fat deposits-a non-surgical alternative to liposuction in body-contouring. Indian Journal of Plastic Surgery 38.
- Shetty PK, Venuvanka V, Jagani HV, Chethan GH, Ligade VS, et al. (2015) Development and evaluation of sunscreen creams containing morin-encapsulated nanoparticles for enhanced UV radiation protection and antioxidant activity. International journal of nanomedicine 10 : 6477-6491. [crossref]
- Couturier K, Servais S, Koubi H, Sempore B, Sornay-Mayet M, et al. (2002) Metabolic Characteristics and Body Composition in a Model of Anti-Obese Rats (Lou/C). Obesity Research 10 :188-194. [crossref]
- Abdel-Hafez SM, Hathout RM, Sammour OA (2014) Towards better modeling of chitosan nanoparticles production: screening different factors and comparing two experimental designs. International journal of biological macromolecules 64 : 334-340. [crossref]
- Rai A, Mohanty B, Bhargava R (2015) Modeling and response surface analysis of supercritical extraction of watermelon seed oil using carbon dioxide. Separation and Purification Technology 141 : 354-365.
- Honary S, Zahir F (2013) Effect of zeta potential on the properties of nano-drug delivery systems-a review (Part 1). Tropical Journal of Pharmaceutical Research 12 : 255-264.
- Neves A, Lucio M, Martins S, Lima J, Reis S (2013) Novel resveratrol nanodelivery systems based on lipid nanoparticles to enhance its oral bioavailability. International journal of nanomedicine 8 : 177-187. [crossref]
- Al-mahallawi AM, Khowessah OM, Shoukri RA (2014) Nano-transfersomal ciprofloxacin loaded vesicles for non-invasive trans-tympanic ototopical delivery: In-vitro optimization, ex-vivo permeation studies, and in-vivo assessment. International journal of pharmaceutics 472 : 304-314. [crossref]
- Yusuf M, Sharma V, Pathak K (2014) Nanovesicles for transdermal delivery of felodipine: Development, characterization, and pharmacokinetics. International journal of pharmaceutical investigation 4 : 119-130. [crossref]
- Patel K, Sarma V, Vavia P (2013) Design and evaluation of Lumefantrine – Oleic acid self nanoemulsifying ionic complex for enhanced dissolution. DARU Journal of Pharmaceutical Sciences 21. [crossref]
- Matsaridou I, Barmpalexis P, Salis A, Nikolakakis I (2012) The influence of surfactant HLB and oil/surfactant ratio on the formation and properties of self-emulsifying pellets and microemulsion reconstitution. AAPS PharmSciTech 13 : 1319-1330. [crossref]
- Liu D, Hu H, Lin Z, Chen D, Zhu Y, et al. (2013) Quercetin deformable liposome: preparation and efficacy against ultraviolet B induced skin damages in vitro and in vivo. Journal of Photochemistry and Photobiology B: Biology 127 : 8-17. [crossref]
- Ascenso A, Raoso S, Batista C, Cardoso P, Mendes T, et al. (2015) Development, characterization, and skin delivery studies of related ultradeformable vesicles: transfersomes, ethosomes, and transethosomes. International journal of nanomedicine 10 : 5837-5851. [crossref]
- Caddeo C, Sales O, Valenti D, Sauri A, Fadda A, et al. (2013) Inhibition of skin inflammation in mice by diclofenac in vesicular carriers: liposomes, ethosomes and PEVs. International journal of pharmaceutics 443 : 128-136. [crossref]
- Uprit S, Sahu RK, Roy A, Pare A (2013) Preparation and characterization of minoxidil loaded nanostructured lipid carrier gel for effective treatment of alopecia. Saudi Pharmaceutical Journal 21 : 379-385. [crossref]
- Uchino T, Lefeber F, Gooris G, Bouwstra J (2014) Characterization and skin permeation of ketoprofen-loaded vesicular systems. European Journal of Pharmaceutics and Biopharmaceutics 86 : 156-166. [crossref]
- Alomrani A, Shazly G, Amara A, Badran M (2014) Itraconazole-hydroxypropyl-cyclodextrin loaded deformable liposomes: In vitro skin penetration studies and antifungal efficacyusing Candida albicans as model . Colloids and Surfaces B: Biointerfaces 121:74-81. [crossref]
- Caddeo C, Manconi M, Fadda AM, Lai F, Lampis S, et al. (2013) Nanocarriers for antioxidant resveratrol: formulation approach, vesicle self-assembly and stability evaluation. Colloids and Surfaces B: Biointerfaces 111:327-332. [crossref]
- Manca M, Castangia I, Zaru M, Nacher A, Valenti D, et al. (2015) Development of curcumin loaded sodium hyaluronate immobilized vesicles (hyalurosomes) and their potential on skin inflammation and wound restoring. Biomaterials 71:100-109. [crossref]
- Kakkar S, Kaur I (2011) Spanlastics – A novel nanovesicular carrier system for ocular delivery. International journal of pharmaceutics 413 : 202-210.
- Song CK, Balakrishnan P, Shim CK, Chung SJ, Chong S, et al. (2012) A novel vesicular carrier, transethosome, for enhanced skin delivery of voriconazole: characterization and in vitro/in vivo evaluation. Colloids and Surfaces B: Biointerfaces 92 : 299-304. [crossref]
- Salama HA, Mahmoud AA, Kamel AO, Abdel Hady M, Awad GA (2012) Brain delivery of olanzapine by intranasal administration of transfersomal vesicles. Journal of liposome research 22 : 336-345. [crossref]
- Zhu Z, Li Y, Li X, Li R, Jia Z, et al. (2010) Paclitaxel-loaded poly(N-vinylpyrrolidone)-b-poly(epsilon-caprolactone) nanoparticles: preparation and antitumor activity in vivo. Journal of Controlled Release 142 : 438-446. [crossref]
- Hathout RM, Mansour S, Mortada ND, Guinedi AS (2007) Liposomes as an ocular delivery system for acetazolamide: in vitro and in vivo studies. AAPS PharmSciTech 8 : E1-E12. [crossref]
- Mognetti B, Barberis A, Marino S, Berta G, De Francia S, et al. (2012) In vitro enhancement of anticancer activity of paclitaxel by a Cremophor free cyclodextrin-based nanosponge formulation. Journal of Inclusion Phenomena and Macrocyclic Chemistry; 74 : 201-210.
- Dixit AR, Rajput SJ, Patel SG (2010) Preparation and bioavailability assessment of SMEDDS containing valsartan. AAPS PharmSciTech 11 : 314-321. [crossref]
- Jana S, Manna S, Nayak AK, Sen KK, Basu SK (2014) Carbopol gel containing chitosan-egg albumin nanoparticles for transdermal aceclofenac delivery. Colloids and Surfaces B: Biointerfaces 114 : 36-44. [crossref]
- Mahajan Suvarnalata S, Chaudhari R (2016) Transdermal gel: As a novel drug delivery system. International Journal of Pharmacy and Life Sciences 1 : 4864-4871.
- Rai VK, Yadav NP, Sinha P, Mishra N, Luqman S, et al. (2014) Development of cellulosic polymer based gel of novel ternary mixture of miconazole nitrate for buccal delivery. Carbohydrate polymers 103 : 126-133. [crossref]
- Palmer M, Curran J, Bowler P (2006) Clinical experience and safety using phosphatidylcholine injections for the localized reduction of subcutaneous fat: a multicentre, retrospective UK study. Journal of Cosmetic Dermatology 5 : 218-226. [crossref]