DOI: 10.31038/PSYJ.2021322
Abstract
Respondents were introduced to a hypothetical situation of an individual being released from prison. The test stimuli were vignettes comprising information about WHO the released prisoner is, WHAT the person did in prison, WHAT kind of people were in prison with the released individual, and WHAT efforts were made in prison to help the prisoner adjust after release. Respondents projected their impression of the described former prisoners, using an anchored 9-point scale, from 1=feeling hopeful to 9=feeling suicidal. When viewing the scale from the point of view of “Suicide,” two mind-sets emerged: MS1, responding to lack of preparation for release, and MS2, someone who is middle class with nothing to do in prison, surrounded by drug addicts. When viewing the scale from the point of “Hopefulness,” two other mind-sets emerge: MS3, hopeful after release and when in prison had daily schedule, and MS4, hopeful when took preparatory courses in prison. The experimental design allows the creation of a PVI, personal viewpoint identifier, to assign a person to one of each mind-set.
Background
Increasingly, we come to hear of the difficulties faced by people who, having served their sentences, are released from prison, only to find a wall of obstacles in front of them as they try to reconstruct their lives. The anguish is great, and occasionally one reads of the despair, which may lead to the use of drugs and often to suicide. The suicides are among otherwise decent people who, having served their time, are attempting to re-enter society [1-3]. We read these stories, feel saddened by them, and, at the same time, we are often fascinated by these individuals and by why they committed suicide. It is a bit of what in German might be called Schadenfreude, the interest of others in a person’s misfortune. The great sociologist, Emil Durkheim, talked about suicides, finding from his statistical analysis of the frequency of suicide, that those with a structured religious life (e.g., Catholics) showed fewer suicides than those with a less well-structured religious life (e.g., Protestants) [4].
The notion of understanding the situation which might lead to suicide prompted a discussion among the two senior authors, Ari Zoldan and Howard Moskowitz, and a separate discussion with author Arthur Kover. The issue was whether there was a “wisdom of the masses” which could inform about what details of a situation might likely be the cause for a released prisoner to commit suicide. The answers were not clear, and so the discussion led to a small Mind Genomics cartography, an attempt to understand the conditions leading to suicide (viz., despair) versus hopefulness, albeit from the ‘outside-in,’ from the response of the general population to presentation of material about released prisoners. This is called a Mind-Cart ‘cartography’.
The literature dealing with the emotions of released prisoner is extensive. Most of the literature is descriptive, dealing with the measurement of recidivism and even suicide. Issues include WHO the released prisoner is (viz., [5-7]. Other topics include the prison environment [8], the other prisoners with whom the individual socialized in prison, including violence which occurred [9,10] and the prisoner’s thoughts and preparations for release while in prison [11-16]. Finally, the literature deals with the follow-up situation and activities of the released prisoner [17], and ongoing efforts to maintain contact with the released prison to integrate the prisoner into society [18].
The literature is primarily sociological in nature, looking at the situation which exists. We propose a ‘next step,’ namely looking into how people feel about the nature of the feeling of the released prisoner, one year after release. This first paper deals with the ‘wisdom of crowds’ [19], using external respondents to read vignettes about the released prisoner, and based upon the vignette, estimate the feeling that the individual will have one year after release.
How Mind Genomics and the ‘Wisdom of the Masses’ Combine Approach the Problem?
We use the newly emerging science of Mind Genomics, a branch of experimental psychology, to understand why “suicide.” The approach, a version of “wisdom of masses,” presents the respondent with combinations of messages, descriptions of the “case,” and instructs the respondents to rate the likely outcome, adjustment to suicide. The science of Mind Genomics is appropriate to study how people think about these topics.
Mind Genomics emerged from the desire to study the experience of the “every day,” using the techniques of experimental psychology (actual experiments, conducted with the aid of computers), consumer research (focusing on the real world of experience, rather than on a situation distorted in the interests of the experiment), and experimental design (focusing on so-called within-subjects design). The topics of Mind Genomics already studied range from disease and recovery, internal war and peace, law, education, food, social distancing in time of COVID-19 , and a host of others [20,21]. The worldview of all these studies is the same: study how people make decisions with the ordinary information to which they are exposed, information known to everyone. It is the focus on the daily life, on the situations to which one pays conscious attention, the absolute ordinary, which constitutes the hallmark of Mind Genomics.
Mind Genomics follows a series of well-defined steps, starting with choice of topic, elucidation of different “granular aspects” of the topic, how people respond, and concluding with the discovery of underlying mind-sets, mental genomes, viz., fundamentally different ways that people think about the same aspects of the topic [22,23]. The later applications of Mind Genomics have been presented by [20,21].
Step 1: Select Raw Materials (Topic, Four Questions, Four Answers to Each Question)
The basis of Mind Genomics is the deconstruction of responses to mixtures of ideas, these ideas representing answers to relevant questions. Figure 1 shows the templated version. The researcher is given the form, which is structured, and comprises several screens. All the respondent must do is type in the topic at the start of the study, then type in the four questions (Figure 1, left panel), and then the four answers to each question (Figure 1, right panel).
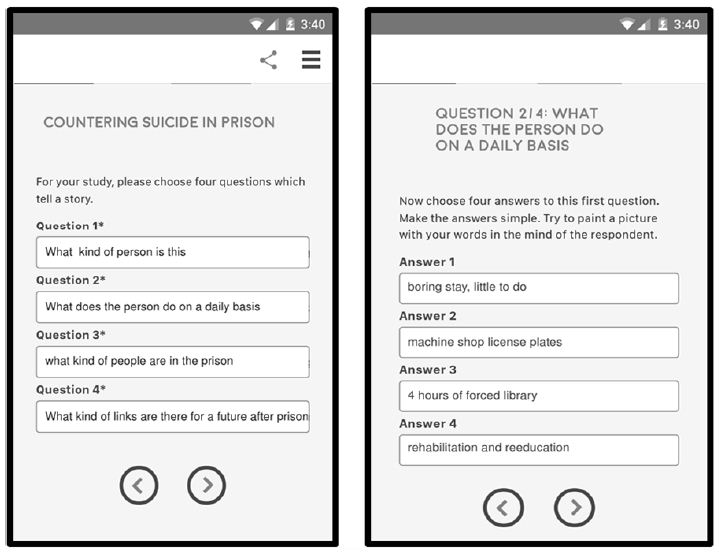
Figure 1: The set up-template for the Mind Genomics study, showing the input form for the four questions, and the input form for the four answers from question #2.
Table 1 shows the raw material created for the topic of feeling after being released from prison. The four questions are not engraved in stone. Rather, they are “first guesses,” aspects that can be fine-tuned or even discarded in subsequent easy and affordable iterations. The Mind Genomics experiment can be modified quickly, after the initial data have been collected, and executed once again, virtually immediately after the study materials have been updated.
Table 1: The four questions and the four answers for each question.
|
Question A: What kind of person is this? |
| A1 |
WHO: young inner city black woman |
| A2 |
WHO: white middle age for theft |
| A3 |
WHO: 21-year-old, second conviction for drugs |
| A4 |
WHO: 54-year-old woman convicted for drugs |
|
Question B: What does the person do on a daily basis? |
| B1 |
ACTIVITIES: boring stay, little to do |
| B2 |
ACTIVITIES: machine shop license plates |
| B3 |
ACTIVITIES: 4 hours of forced library |
| B4 |
ACTIVITIES: rehabilitation and reeducation |
|
Question C: what kind of people are in the prison? |
| C1 |
SITUATION IN PRISON: lower and upper middle class |
| C2 |
SITUATION: camaraderie |
| C3 |
SITUATION IN PRISON: drug addicts |
| C4 |
SITUATION IN PRISON: invisible status |
|
Question D: What kind of links are there for a future after prison? |
| D1 |
RELEASE PREPARATION: optional courses to prepare for jobs |
| D2 |
RELEASE PREPARATION: out you go |
| D3 |
RELEASE PREPARATION: no support |
| D4 |
RELEASE PREPARATION: simply re-enter life |
Step 2: Select a Rating Scale
The rating scale dictates the nature of the experiment. The rating scale is shown below. The scale deals with the likelihood of what will happen 12 months after the person is discharged from prison.
Rating question: What will happen in 12 months?
Low Anchor: Rating question 1=hopeful
High Anchor: Rating question 9=suicidal
Figure 2 two other tempates. The left panel in Figure 2 shows the orientation page. The right panel show the rating scale, including number of scale points (9), and the anchors for each scale point.
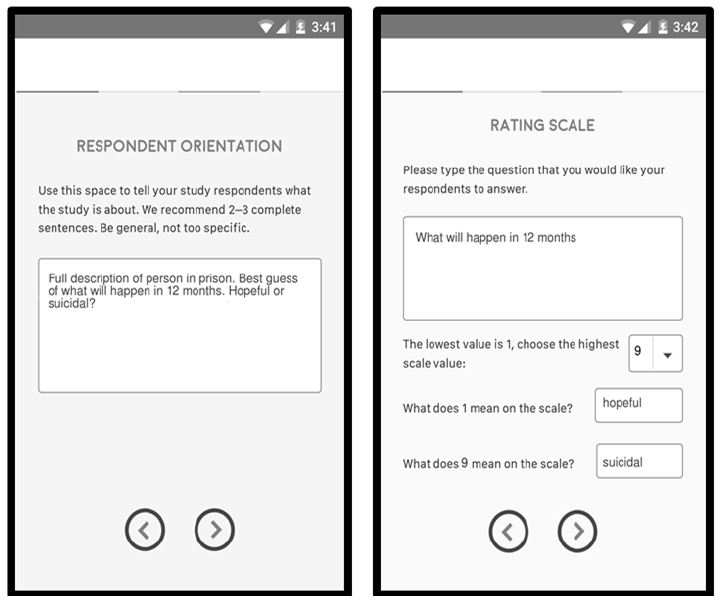
Figure 2: The templates, for respondent instructions (left panel), and for rating scale (right panel).
Step 3: Create the Vignettes, Combinations of Elements to be Tested
The vignette, a combination of 24 elements, becomes the “stimulus” that the researcher presents, and the respondent responds by following a rating scale introduced in Step 2. The vignettes are created according to a systematically designed set of combinations, “the experimental design” [24]. The underlying experimental design for this so-called 4×4 design of Mind Genomics (4 questions, 4 answers/question) prescribes exactly 24 combinations. The combinations are of three types: combinations with one element from two questions (2-element vignette), one element from three questions (3-question vignette), or one element from four questions (4-question vignette). By design each question can contribute at most one element, but often no elements. Furthermore, each respondent evaluates a different set of combinations, permutations of the main design [25].
The rationales for the design and the permutations follow:
a. The experimental design ensures that each respondent evaluates the appropriate vignettes, designed for OLS (ordinary least squares) regression. OLS regression builds a model or an equation, of the form: Dependent Variable = k0 + k1(A1) + k2(A2) … k16(D4)
b. The systematic permutation of the design ensures that the structure of the combinations is the same for all respondents, but each respondent tests different combinations. In effect, the permuted design ensures that the Mind Genomics experiment covers many of the possible combinations. The approach of testing many combinations, each with “noise,” rather than testing a limited number of combinations with the noise averaged out through replication, represents a dramatic departure from conventional statistics and design. Conventional design suppresses noise or averages out the noise. Permuted designs accept the noise at each point but cover most of the design space, thereby allowing the underlying pattern to emerge. The best metaphor is the difference between a high resolution X- ray of a single area, with a single X- ray impression, versus the MRI, magnetic resonance imaging, which takes many pictures of the tissue from different angles, and combines the different pictures later on. Metaphorically speaking, Mind Genomics is an “MRI of the mind.”
c. In order for the rating scale to work, it must be applied to the description of a person. Only with combinations of elements is there a real, albeit sparse, description of a person and situation. The rating scale will not be meaningful when applied to each of the 16 elements, in a one-by-one fashion. There is no context in the format which presents one element at a time, despite the attractiveness of doing so. By presenting the test elements in a one-by-one fashion, one allows the respondent to alter the criterion for judgment to fit the nature of the test element being evaluated. The experimental design combines elements, forcing the respondent to maintain one criterion, and preventing “gaming” the interview.
Step 4: Define the Dependent Variables
The raw data from Mind Genomics are the ratings on the anchored 9-point scale (see Step 2), and the response time. The response time is defined as the number of seconds between the presentation of the test vignette and the rating assigned by the respondent. The response time is easily measured by the underlying computer program.
The original ratings on the 9-point scale are hard for managers to understand, despite their seeming simplicity. The typical question encountered is: “What does <rating X> mean?” “Rating X” could be a 3, a 7, or any of the numbers on the scale. As simple as the scale is, the reality in practice is that the scale has no intrinsic meaning to the manager, except at the very top or bottom.
The convention in traditional consumer research has been to divide the scale into two points, to denote NO versus YES. For these data we divide the scale two ways:
Top3: The scale is divided so that ratings of 7-9 are transformed to 100 to denote “suicide YES” (whether thoughts or expected action), and ratings of 1-6 are transformed to 0 to denote “hopefulness YES”). A small random number is added to the transformed ratings to introduce minute variability, a statistical requirement for OLS (ordinary least-squares) regression analysis. The small random number, assigned to each transformed number, ensures the necessary but vanishingly low variability in the dependent variable.
Bot3: The scale is divided so that ratings of 1-3 are transformed to 100 to denote “hopefulness YES,” and ratings of 4-9 are transformed to 0 to denote “hopefulness NO.” A random number is once again added to each transformed rating.
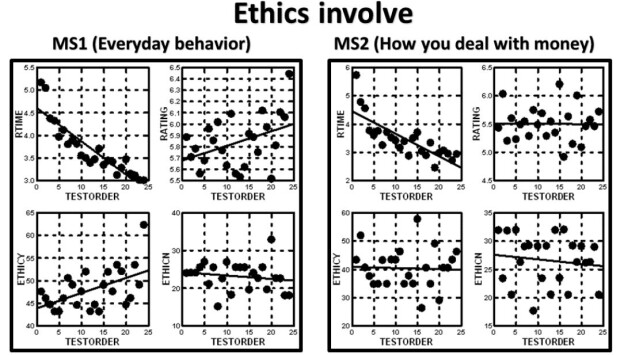
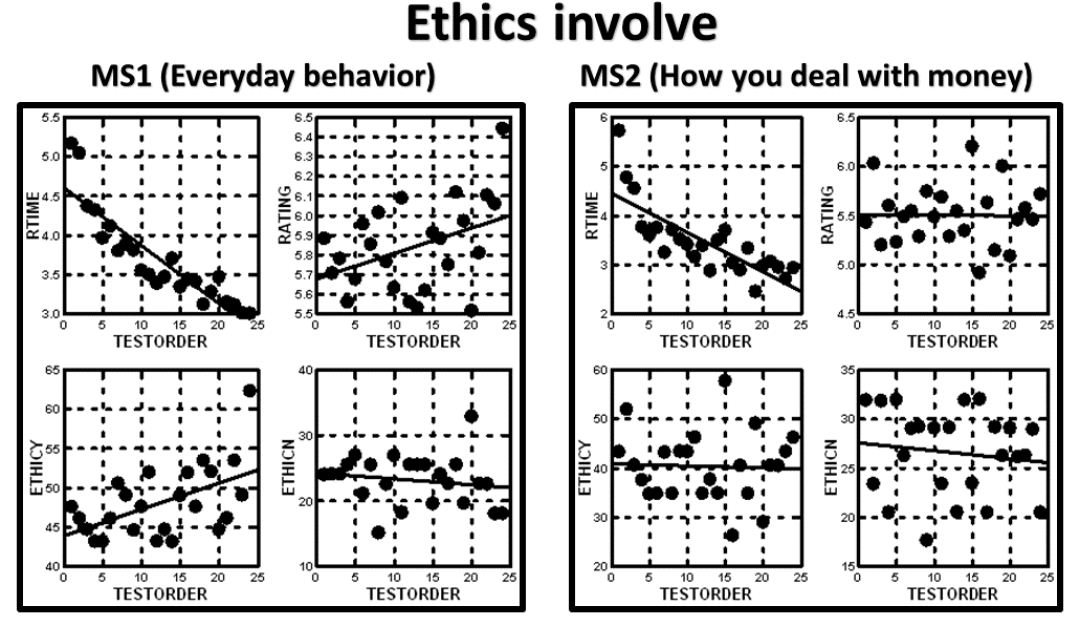
The Mind Genomics program, BimiLeap, measures the response time, defined as the time between the appearance of the vignette and the time that the rating is assigned. The response time is also treated as a dependent variable, but not transformed. For the analysis, the response times from vignettes 13-24 will be the only ones used for analysis. The use of data from the second half of the vignettes for response time, but the use of data from all 24 vignettes for the binary transformed variables (Top3 and Bot3), comes from the striking observation in Figure 3. The average response time drops as the respondent becomes more acquainted with the task, and more practiced. In contrast, the average rating on the 9-point scale does not change. Figure 3 shows the average values by each of the 24 positions in the experiment for the four prospective dependent variables, respectively. It is clear that there is no order dependency for the average rating, a clear decreasing function for response time, and a very “noisy,” but possibly decreasing function for both Top3 and Bot3.
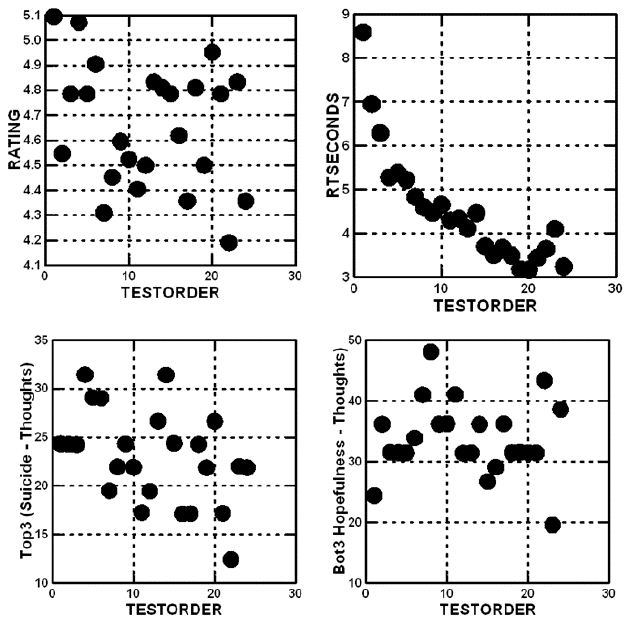
Figure 3: Average value of the four dependent variables for each of the 24 positions (test order) in the Mind Genomics experiment. Position 1 is the vignette tested in the first position, position 10, for example, is the vignette tested in the 10th position.
Step 5: Build the Model (Equation) Relating the Presence/Absence of Elements
It is the contribution of the elements to the response which constitutes the key information afforded by the Mind Genomics experiment. That contribution is provided by the coefficient of the model, relating the presence/absence of the 16 elements to the dependent variable.
The equation is estimated using the well accepted method of OLS (ordinary least-squares) regression, or so-called “curve fitting.” The analysis focused on three equations, relating to Top3, Bot3, and response time. The equation for the rating was not calculated because it is contained within the analysis of Top3 (Suicide) and Bot3 (Hopeful).
The basic equation is expressed as an additive constant (k0) and 16 coefficients (k1-k16), respectively.
Top3 = k0 + k1(A1) + k2(A2) … k16(D4)
Bot3 = k0 + k1(A1) + k2(A2) … k16(D4)
RT (Response Time ) = k1(A1) + k2(A2) … k16(D4)
The additive constant is the estimated value of the dependent variable (e.g., Top3 or Bot3) in the absence of elements. The experimental design ensured that each vignette would be comprised of 2-4 elements, meaning that the additive constant is a purely estimated parameter. The additive constant can be thought of as the baseline value of Top3 or Bot3. If the metaphor is a statue, then the additive constant is the base, viz., not part of the statue itself, but a basic, fixed contribution to the height.
Above the baseline or additive constant will be the separate contributions of the elements, given by the coefficients. The coefficients are positive (the element contributes to the the value of Top3 or Bot3), zero (no effect), or negative (the element takes away from the value of Top3 or Bot3). For the sake of clarity and to allow the patterns emerge, we will estimate the coefficients, but only show the positive or non-zero coefficients. It is the pattern of these positive coefficients which tell the “story.”
Step 6 – Results from the Total Panel
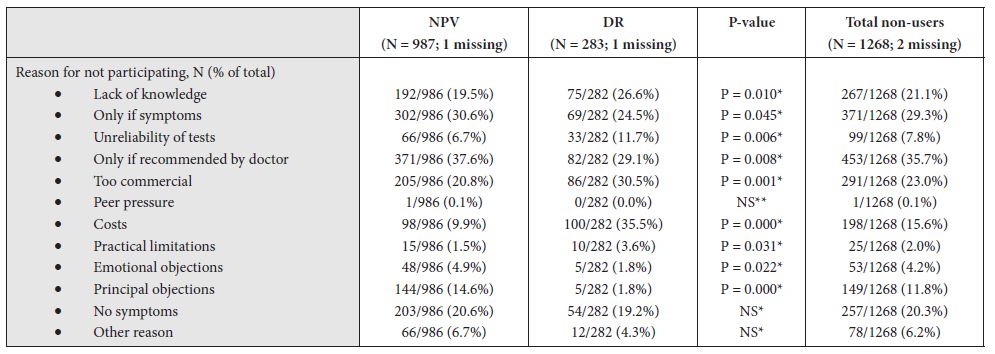
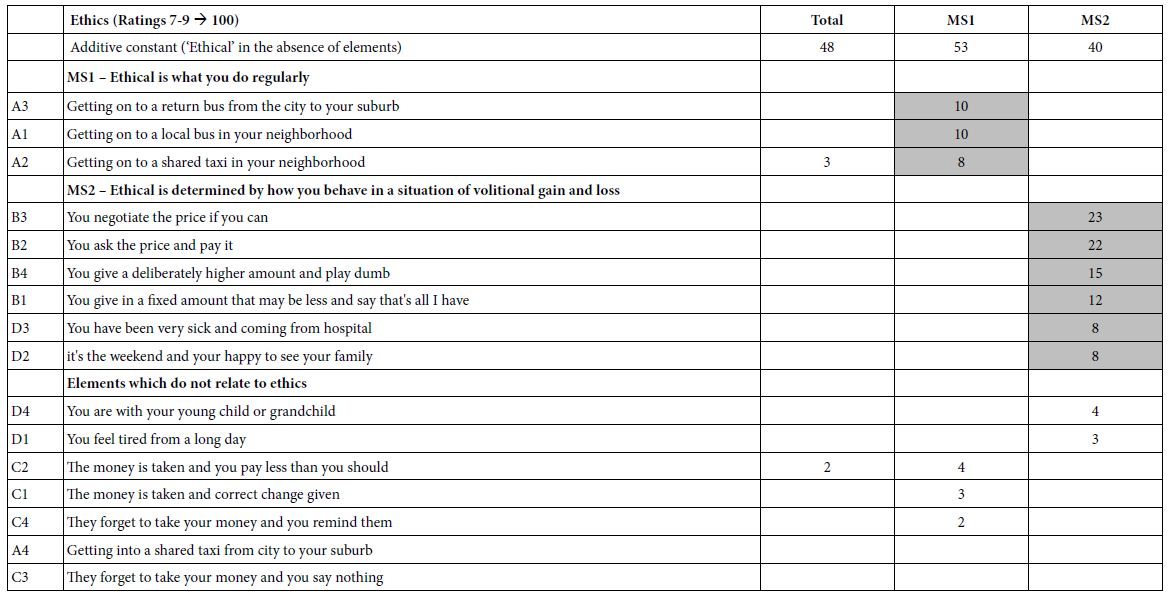
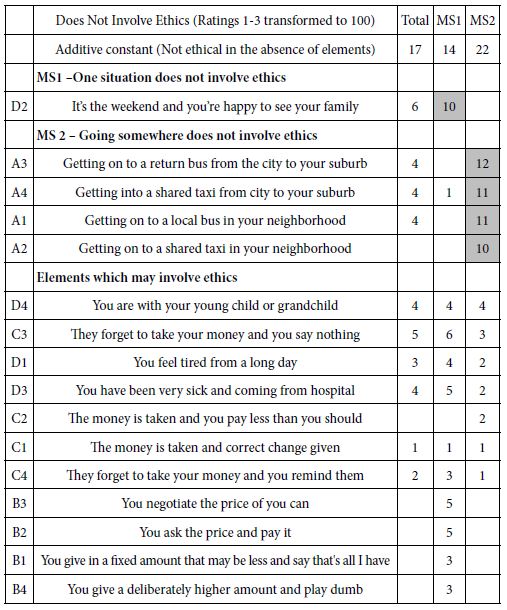
The total panel comprises all the vignettes from all the respondents. Keep in mind that the analysis generated two models, one looking at suicide (not further defined; Top3), the other looking at hopefulness (not further defined; Bot3). Again, keep in mind that we are dealing with the wisdom of the masses, viz, a guess about the behavior based upon the vignette. Yet, we surmise that an average judgment, given by many people, may provide a good sense of what people believe regarding how a recently released prisoner might feel after 12 months. Table 2 shows the positive coefficients driving either suicide/despair (Top3) or hopefulness (Bot3).
The additive constant represents the expected feeling of the person described, in the absence of any additional information. The expected proportion of responses “suicide”(ratings 7-9) in the absence of information is 24. Of course, all vignettes by design comprised 2-4 elements, so the addiive constant is a purely estimated parameter. Nonetheless, we get a sense that about a quarter of the responses will be that the person described will contemplate suicide. In contrast, for feelings of hopefulness, Table 2 suggests that 44% of the time, i.e., almost half of the responses, the person described will feel hopeful.
Table 2: Parameters of the models relating the presence/absence of the 16 elements to the thought of suicide (Top3) or hopefulness(Bot3). Strong performing elements (8 or higher) are shown in shaded cells. Only positive coefficients are shown, to reveal the patterns.
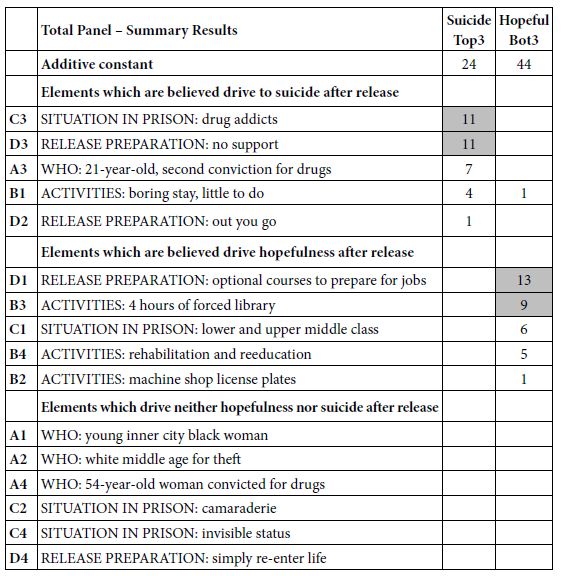
It is in the elements that we see some situations which drive the feeling of suicide. The only elements we show are positive ones because we are interested in what drives the feelings of suicide, rather than what does not drive the feeling of suicide. The two strongest elements are having been in prison with SITUATION IN PRISON: drug addicts, and an element described as RELEASE PREPARATION: no support in prison. Both of these elements have high coefficients of 11, meaning that when they are included in the description of the released person, an additional 11% of responses are that the person will fee “suicidal” (ratings 9, 8, 7). If the person leaving is a 21-year old, with a second conviction for drugs, an additional 7% feel there could be suicide behavior.
The data suggest that two strong elements are thought to drive a feel of hopefulness: RELEASE PREPARATION: optional courses to prepare for jobs, and ACTIVITIES: 4 hours of forced library. There is a sense that forcing the prisoner to do things to improve the mind should help.
Step 7: Response Time (Reflection of Degree of Engagement of Responder) as a Dependent Variable
The response time, defined as the time between the presentation of the vignette and the rating, may represent time needed to process the information. Response time is not directly under the cognitive control of an individual, who is simply reading the vignette (if that), and assigning a rating.
Figure 3 above shows the systematic decrease in the average response time. The average response time in the aggregate, by test position (postion 1 to position 24), shows a dramatic pattern which makes sense. As respondents get increasingly experienced with the task, even without feedback, their average time to read and rate the vignette decreases, at first dramatically. The response time eventually stabilizes near the end of the experiment.
Graphs similar to these appear in virtually any study, leading to the introduction of a “practice first vignette,” the response to which is discarded. In this study we discard that first vignette, which is not part of the design, measure the response times for the 24 vignettes, and build models for the total set of 24 vignettes, followed by models for the first half of th vignettes vs the second half (vignette 1-12 vs 13-24).
The deconstruction of the response time for the total vignette into the component response times is done using the same type of regression equation , but without the additive constant. The rationale for this analysis, called “forcing the model through the origin” comes from the recognition that in the absence of elements there is no response at all.
Response Time = k1(A1) + k(A2) … k16(D4) (Note: no additive constant)
Table 3 shows the coefficients for response time, first for the total set of vignettes (Vig 1-24), then for the first 12 vignettes (Vig 1-12) and finally for the last 12 vignettes (Vig. 13-24). The final column (Sec-First) shows the change in estimated response time (seconds) by element, for the total panel. The important thing to notice is the changes are not the same. There is a dramatic range.
Table 3: Response times for the 16 elements, showing the response time for the total panel over 8 second for all 24.
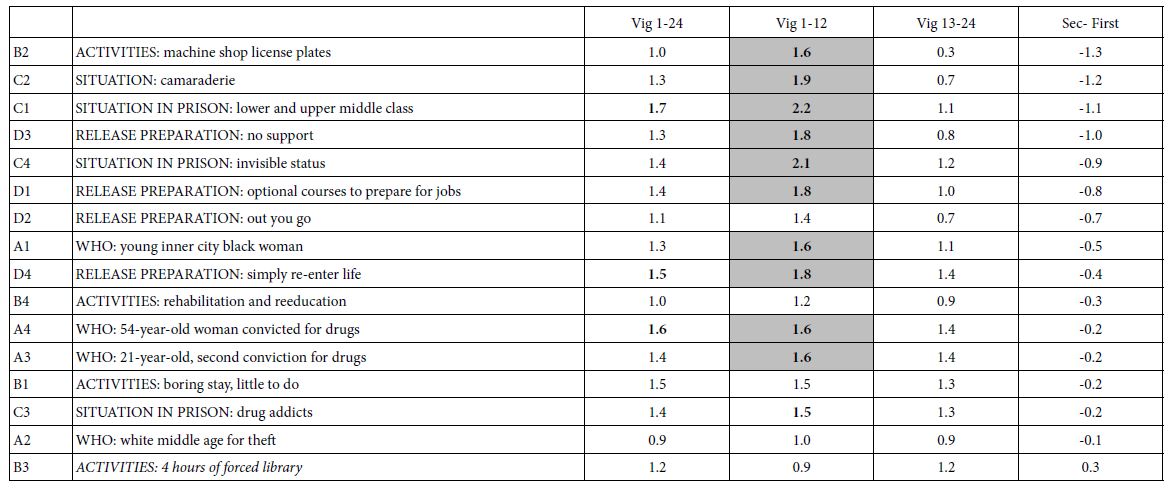
The response times are not highly correlated, but they are positively correlated, all except one being shorter for the second half of the 24 vignettes, and being longer for the first half of the vignettes. That element, B3, ‘ACTIVITIES: 4 hours of forced library’ is important because it becomes more engaging as the respondents are exposed to it. It may be that the message becomes increasingly meaningful with repeat exposures. It may be these types of elements which are most important to recognize. Their meaning may “sink in” over time, rather than become diluted (Figure 4).
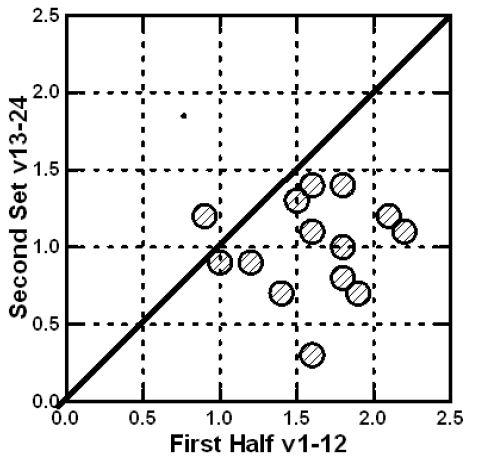
Figure 4: Relation between the coefficients for response time for the first vs the second half of the set.
Step 8: Create New Groups of Respondents (Mind-sets), based Upon the Patterns of Their Coefficients
A continuing hallmark finding of Mind Genomics is that people differ in the way they think. The finding is not surprising and often glossed over as a characteristic of “subjective data,” such as ratings of opinions, and certainly ratings of opinions of the Mind Genomics vignettes.
Mind Genomics studies often reveal that what seems to be a “flat” data set with few strong elements is stronger than one might believe at first glance. The mind-sets can be thought of as different patterns of interesting elements. When one group of people is interested in a set of elements, but another group is not, often the result is flat and noisy when the coefficients of the elements are plotted against each other. The plot is “noisy,” with the coefficients darting about with no pattern emerging. Such is the general problem in research when one deals with groups of people with radically different points of view towards the same topic. What could be rich veins of information, rich patterns of “color” are discarded because at first glance the general impression is a boring monochrome. Only when one looks more closely do the intricate patterns reveal themselves, patterns which otherwise intertwine, interdigitate, and produce a dull gray.
The process to uncover the mind-sets comprises simple steps, described elsewhere [26]. Here is a list of the steps:
a. Create a model for each respondent. This is possible because of the underlying experimental design, used to create the vignettes for each respondent.
b. Cluster the respondents based upon the pattern of their coefficients.
c. For clustering, use the metric (1-Pearson Correlation) as the measure of “distance” or “dissimilarity” between pairs of respondents.
d. Extract two and then three clusters, the mind-sets.
e. Create the models for all respondents in a specific cluster or mind-set. Thus the analysis creates two new models for the two-mind set solution, three new modesl for the three mind-set solution.
f. Inspect the models for interpretability, viz., do the data “tell a coherent story?”
The clustering program was run twice, first for the models for Top3 (suicide), and second for the individual models for Bot3 (hopefulness). The analysis, run twice, allows us to look at these two feelings separately, viz. treating the data anew, once from the viewpoint of feelings about suicide and once, and entirely separately, from the point of view of feelings about hopefulness.
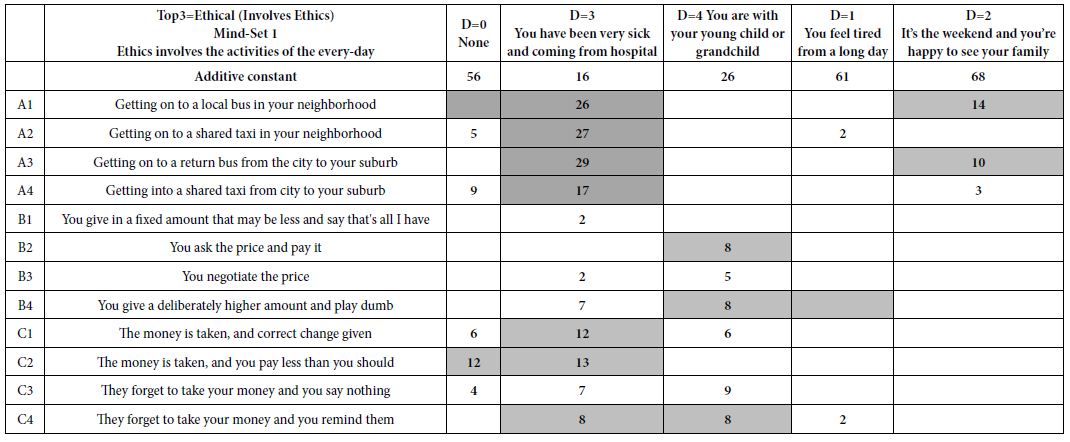
Table 4 shows the results of two sets of cluster analyses: MS1 and MS2, based on suicide (Top3); MS3 and MS4, based on hopefulness (Bot3). Table 4 shows only the positive coefficients for each, in the interests of readability and to detect the underlying patterns. The strongest performing elements are shown in shaded cells. The “names” for the mind-sets are shown in the second row. These names were assigned by the researchers based upon the “story” which the strong performing elements appeared to provide.
Table 4: The two pairs of mind-sets, based upon clustering coefficients for suicide (Top3, left two columns) and coefficients for hopefulness (Bot3, right two columns).
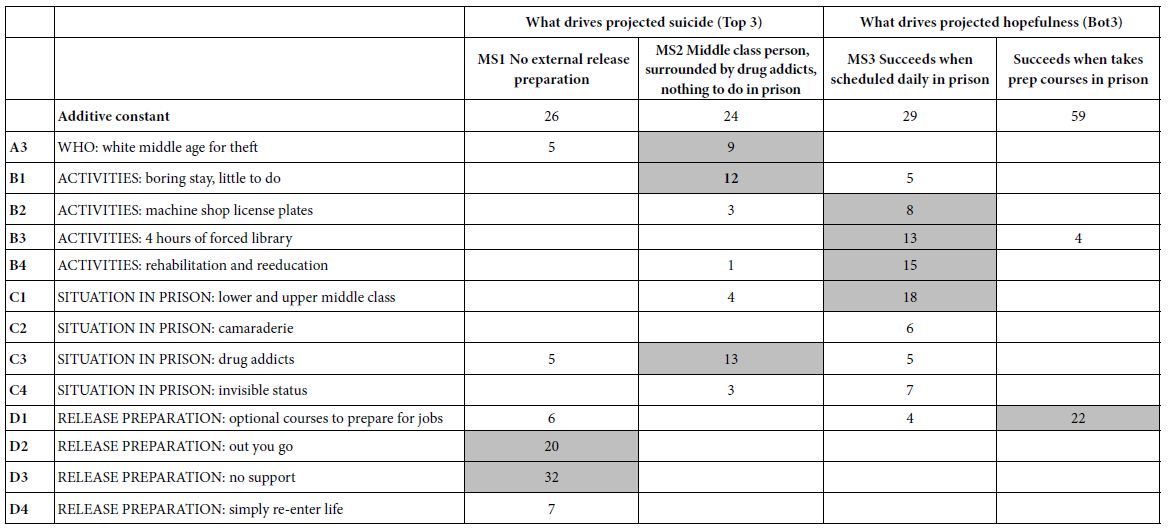
Pairwise Interactions – What Situation Drives a Rating of “Suicide”
The underlying exoerimental design using Mind Genomics ensures that all of the elements are statistically independent of each other. Yet, despite that, some combinations naturally “enhance each other,” when they appear together, despite being statistically independent. The permuted design used here (Gofman & Moskowitz, 2010) allows us to discover these synergistic combinations, or more correctly, to discover how a set of elements performs when one of the elements is held constant with different options. This analysis shows the change in the performance of a set of elements when we systematically “cycle through” the elements in one question.
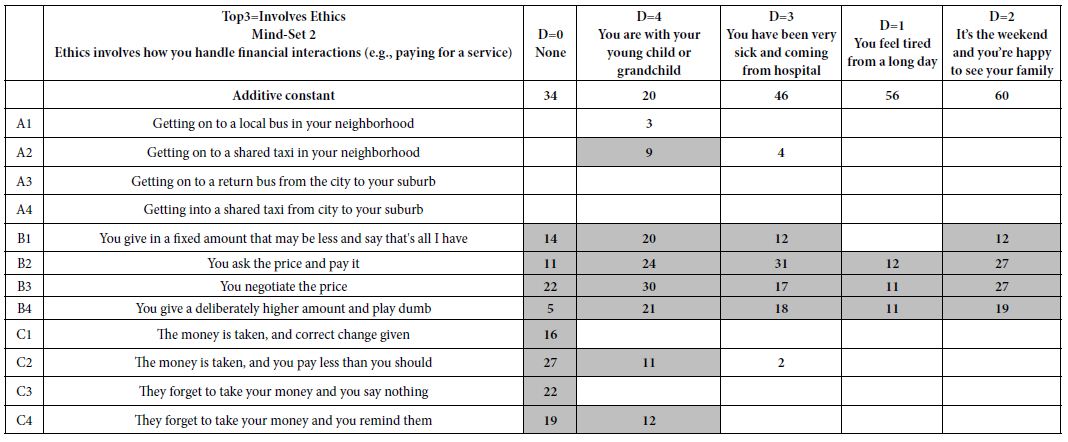
In order to discover these synergistic combinations we simpy divide the data for any question (e.g, WHO the person is, question A) into the five levels or strata (A=0 viz., A does not appear in the vignette; A=1 in the vignette, A=2 in the vignette, A=3 in the vignette, and A=4 in the vignette, respectively). The vignettes in each strata comprise an experimental design that can be analyzed. The value of A is held constant in the stratum. Thus, A no longer acts as a source of four independent variables (A1-A4). We are now left with 12 independent variables, B1-B4, C1-C4, and D1-D4, respectively.
Table 5 shows the coefficients which are very strong for independnt variables B1-D4, when A is “cycled through,” viz., A0 (A absent), A1, A2, A3 and A4, respectively. Only the very strong performing coefficients appear in Table 5. The analysis was done for suicide (Top3) as the dependent variable. It is clear that there are synergies between WHO the person is and the situation in prison. Of course, these are inferred by the respondent. We are relying on the ‘‘wisdom of the masses” to give us a sense of the pattern Nonetheless, the data suggest some patterns, such as the perceived synergy between a middle class released prisoner and an experience with drug addicts in prison.
Table 5: Synergistic combinations in which the coefficient for the situation is very strong. The dependent variable is Top3 (suicide).
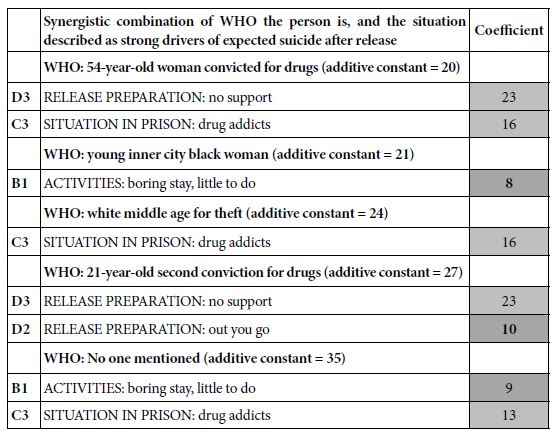
Finding these Individuals in the Population
A key output of most Mind Genomics studies is the continuing discovery that the mind-sets do not vary in a straightforward way with the typical geo-demographics that fill the databases of people. We know a lot about the behavior of people. However, despite being able to measure their behaviors at many touchpoints and in many situations, we cannot say that we know the attitude of a person in a granular way for any topic which arises. Everyday experience suggests that people differ. Although we might hazard a guess about the way people make decisions regarding issues in a specific topic, these are guesses, not facts. Indeed, just a bit of thinking will reveal that people dramatically differ, often to the surprise of those who question them and believe they know the answer before it is given. The reason for the surprise is that how a person thinks is not related to, except in the most obvious cases, who the person is.
Table 6 below shows the distribution of mind-sets for both Top3 (suicidal) and Bot3 (hopeful). There were two mind-sets extracted for each. There is no clear relation between mind-sets in either case analysis to gender or age. Indeed, there is no clear relation between membership in segments created for suicidal vs segments created for hopeful, even though the people were the same, the ingoing data were the same, and all that differed was the way the data in the scale were treated.
Table 6: Distribution of mind-sets for Suicidal (Top3) and for Hopeful (Bot3).
| |
|
MS1 (Top3) Feel worst when just sent out after finishing sentence with no contact after release |
MS2 (Top3) Feel worst when recalling time in prison was spent being bored, surrounded by addicts, etc.
|
| Total |
42
|
19 |
23
|
|
Male
|
19 |
9 |
10
|
| Female |
23
|
10 |
13
|
| Age 18-29 |
13
|
7 |
6
|
| Age30-Plus |
29
|
12 |
17
|
| |
|
|
|
| |
Total
|
MS3: (Bot) Feel hopeful when recall that prison experience was ok, fellow prisoners were middle class, time was boring but did some work |
MS4 (Bot) Feel hopeful when recalling prison prepared for exit, and provided something to do to keep busy
|
| Total |
42
|
22 |
20
|
| Male |
19
|
9 |
10
|
| Female |
23
|
13
|
10
|
| Age18-29 |
13
|
6 |
7
|
| Age30-Plus |
29
|
16 |
13
|
| |
|
|
|
| |
Total
|
Bot 3 MS Seg3 |
Bot 3 MS Seg4
|
| Total |
42
|
22 |
20
|
| Top 3 MS1 |
19
|
12 |
7
|
| Top 3 MS2 |
23
|
10 |
13
|
Unable to generalize the discoveries of Mind Genomics, our ability to understand what the mind-sets mean in terms of behavior and how they relate to mind-sets of other studies is limited. The mind-sets here can be used to understand how one thinks of the feelings of released prisoners. The results would be far stronger if the study could be administered to prisoners a year after their release or to prisoners from different socio-economic classes with the objective to assign a new individual (ex-prisoner) to one of the two mind-sets.
Recently, authors Gere and Moskowitz developed an approach to assign new people to the mind-sets discovered through Mind Genomics. The approach, called the PVI (Personal Viewpoint Identifier), uses a combination of Monte Carlo Simulation with added variability, and Decision Tree analysis. The PVI creates a set of six questions, using the elements and coefficients shown in the left part of Table 4 (mind-sets created from Top3, viz., Suicide). The table, comprising both positive and negative coefficients, is “perturbed” by added, random variability. The PVI then identifies the optimal set of six elements, taken directly from the study, the patterns of response which best reproduce the original mind-sets. The elements are presented to the new person on a 2-point scale. The pattern of responses to these six questions, based on the elements, assigns the new person to one of the two (or three) mind-sets, empirically uncovered by the study.
It should be kept in mind that the PVI works with granular data, with data used to create the vignettes in the first place. Thus, the PVI does not need to be “interpreted” by experts, who take macro segmentation of an entire topic and change the focus to a micro-topic. The PVI works automatically, without training, and is set up in minutes based upon the proper input from the study.
Figure 5 shows the PVI. The first part of the PVI (left side) contains a section to obtain demographics, allowing the researcher to understand who the respondent IS, when the PVI is completed, and so forth. Many of these questions can be suppressed for a shorter interview. The second part comprises two PVI’s, one for Suicide, and the other for Hopefulness. The respondent simply answers the 12 questions. The data are stored in a database, showing the demographics, the mind-set for each PVI (suicide, hopefulness), and the original ratings. The PVI is set up for rapid, easy deployment, and for fast answers.
The PVI for the study, the left panel shows the demographics section. The right panel shows the two PVIs comprising six questions each, one for suicide (study 1), the other for hopefulness (study 2). The PVI structure allows the researcher to randomize the order of the studies, and within a study randomize the order of the questions. There is a third option to randomize all 12 questions so that questions of hopefulness may be mixed with questions of suicide (Figure 5).
The PVI showing two panels, the left panel obtains the demographics. The right panel presents two sets of six questions each, designed to assign a person separately to the one mind-set from the first pair of mind-sets (regarding suicide), and at the same time assign a person to one mind-set from the second pair of mindsets (regarding hopefulness) (Figure 5).
Discussion and Conclusion

Figure 5: The PVI. The left panel shows the first part, which acquires the demographics. The right panel shows the two PVI questionnaires, for the two pairs of mind-sets.
With increased experience in applying the methods of Mind Genomics, the researcher can gain valuable insights into the minds of people. In contrast to the typical approach of science, which addresses “holes” in the literature, the Mind Genomics approach proceeds in a purely inductive, exploratory way. With a Mind Genomics experiment, there is no hypothesis to be tested and either corroborated or falsified in the classical manner of science as described by Karl Popper [27]. Rather, the science here is simply observing a situation and formalizing a way to understand the different aspects of that situation [28].
What is important in this paper is the discovery of the two mind-sets for suicide thoughts and the two mind-sets for hopeful thoughts. It should be noted that rather than interviewing recently released prisoners (viz., after a year), we began this project in the spirit of “wisdom of the masses” and engaged in a gedanken or “thought” experiment.
If the approach presented here is acceptable to the scientific community as a way of understanding our perception of others, then the Mind Genomics approach provides an interesting way to introduce new topics into the world of research, topics which are appropriate for specific groups but must be first explored with the world at large. Mind Genomics offers many benefits. The results can be directly integrated into a larger database. The data is self-evident. Patterns emerge from the data. Some are meaningful and some are not. By following many iterations and fine-tuning the questions and answers that received the most responses in an earlier iteration, the researcher arrives at the truth. This is the science of psychology in its most basic form: looking at all possibilities, sorting out the emerging patterns, searching for differing mind-sets, and predicting which mind-set someone new will belong to. By repeating this methodology for dealing with questions of economics or feelings or everyday occasions, the researcher will gather the data to formulate a “wiki of the mind” and understand how mind type and behavior are related.
Acknowledgement
Attila Gere thanks the support of Premium Postdoctoral Research Program of the Hungarian Academy of Sciences.
References
- Kariminia A, Law MG, Butler TG, Levy MH, Corben SP, et al. (2007) Suicide risk among recently released prisoners in New South Wales, Australia. Medical journal of Australia 187: 387-390. [crossref]
- Pratt D, Piper M, Appleby L, Webb R, Shaw J (2006) Suicide in recently released prisoners: a population-based cohort study. The Lancet 368: 119-123. [crossref]
- Pratt D, Appleby L, Piper M, Webb R, Shaw J (2010) Suicide in recently released prisoners: a case-control study. Psychological medicine 40: 827-835. [crossref]
- Stark R, Doyle DP, Rushing JL (1983) Beyond Durkheim: religion and suicide. Journal for the Scientific Study of Religion 120-131.
- Harizi A, Trebicka B, Tartaraj A (2020) A Mind Genomics Cartography of Shopping Behavior for Food Products During the Covid-19 Pandemic. European Journal of Medicine and Natural Sciences 4: 25-33.
- Opsal T (2012) ‘Livin’on the Straights’: Identity, Desistance, and Work among Women Post‐ Sociological Inquiry 82: 378-403.
- Steiner B, Wooldredge J (2008) Inmate versus environmental effects on prison rule violations. Criminal Justice and Behavior 35: 438-456.
- Camp SD, Gaes GG (2005) Criminogenic effects of the prison environment on inmate behavior: Some experimental evidence. Crime & Delinquency 51: 425-442.
- Hochstetler A, Murphy DS, Simons RL (2004) Damaged goods: Exploring predictors of distress in prison inmates. Crime & Delinquency 50: 436-457.
- Lahm KF (2008) Inmate-on-inmate assault: A multilevel examination of prison violence. Criminal justice and behavior 35: 120-137.
- Dhami MK, Mandel DR, Loewenstein G, Ayton P (2006) Prisoners’ positive illusions of their post-release success. Law and Human Behavior 30: 631-647. [crossref]
- Craig DE, Rogers RD (1993) Vocational training in prison: A case study of maximum feasible misunderstanding. Journal of offender rehabilitation 20: 1-20.
- Holbrook MI (1997) Anger management training in prison inmates. Psychological Reports, 81: 623-626. [crossref]
- Suarez A, Lee DY, Rowe C, Gomez AA, Murowchick E, et al. (2014) Freedom project: Nonviolent communication and mindfulness training in prison. Sage Open 4: 2158244013516154.
- Visher CA, O’Connell DJ (2012) Incarceration and inmates’ self-perceptions about returning home. Journal of Criminal Justice 40: 386-393.
- Winnick TA, Bodkin M (2008) Anticipated stigma and stigma management among those to be labeled “ex-con”. Deviant Behavior 29: 295-333.
- Baldry, Eileen, Desmond McDonnell, Peter Maplestone, Manuel Peeters. (2002) “Ex-prisoners and accommodation: What bearing do different forms of housing have on social reintegration for ex-prisoners.” In Housing, Crime and Stronger Communities Conference convened by the Australian Institute of Criminology and the Australian Housing and Urban Research Institute, Melbourne 6-7.
- Johnson Listwan S, Colvin M, Hanley D, Flannery D (2010) Victimization, social support, and psychological well-being: A study of recently released prisoners. Criminal justice and behavior 37: 1140-1159.
- Surowiecki J, (2005) The wisdom of crowds. Anchor.
- Milutinovic V, Salom J (2016) Mind Genomics: A Guide to Data-Driven Marketing Strategy. Springer.
- Moskowitz HR, Wren J, Papajorgji P (2020) Mind Genomics and the Law, LAP LAMBERT Academic Publishing 13: 17-21.
- Moskowitz HR, (2012) ‘Mind genomics’: The experimental, inductive science of the ordinary, and its application to aspects of food and feeding. Physiology & behavior 107: 606-613. [crossref]
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2006) Founding a new science: Mind genomics. Journal of sensory studies 21: 266-307.
- Box GE, Hunter WH, Hunter S (1978) Statistics for experimenters. New York: John Wiley and sons.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of sensory studies 25: 127-145.
- Dubes R, Jain AK (1980) Clustering methodologies in exploratory data analysis. Advances in computers 19: 113-228.
- Popper K (2005) The logic of scientific discovery. Routledge.
- Kell DB, Oliver SG (2004) Here is the evidence, now what is the hypothesis? The complementary roles of inductive and hypothesis‐driven science in the post‐genomic era. Bioessays 26: 99-105. [crossref]