Abstract
This contribution shows that the water for some pegmatites comes from mantle deeps via supercritical fluids. Proofs are silicate melt inclusions with high water concentration. This concentration forms with the temperature solvus curves. In addition to such solvus curves, the distributions of a row of elements display characteristic Lorentzian curves regularly related to the solvus. Along with these characteristics, untypical, mostly spherical indicator minerals from mantle deeps are present in the granites and associated pegmatites in the upper crust regions. Nanodiamonds, graphite, coesite, and reidite belong to such minerals.
Keywords
Pegmatites, Supercritical fluids, Mantle minerals, Extreme element enrichment
Introduction
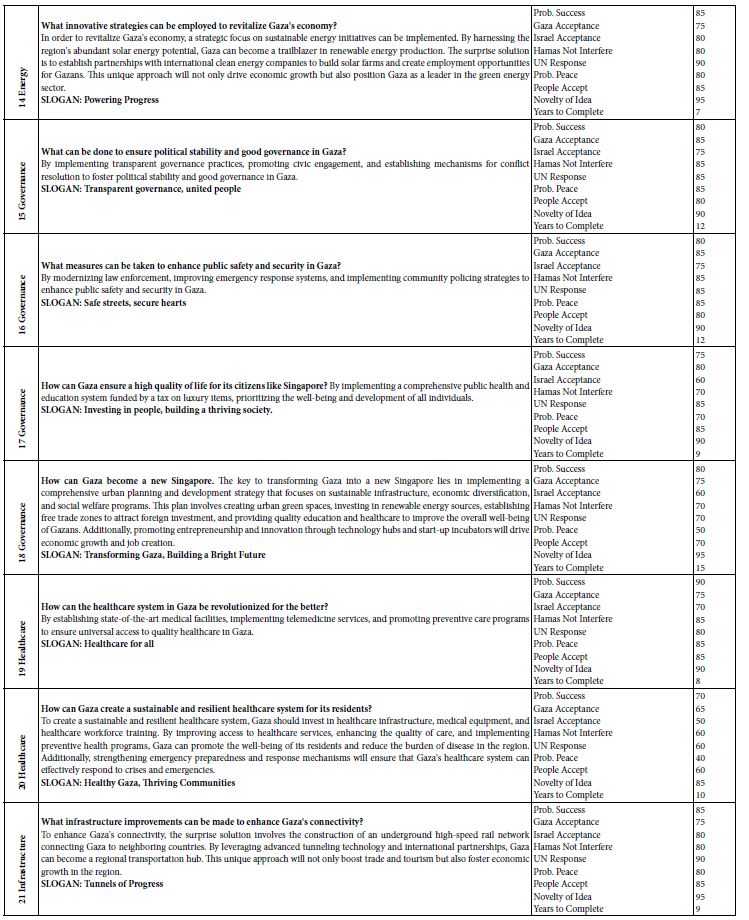
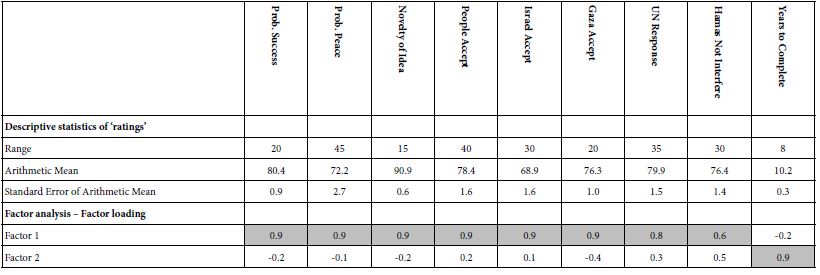
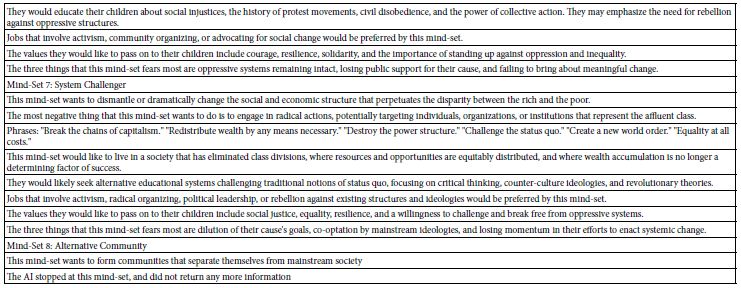
In recent years, we have seen an increasing interest in the genesis of pegmatites. The origin of this is the importance of rare elements, like Li, Be, Rb, Cs, REE, Nb, Ta, and many others, which are sometimes highly enriched in some pegmatites. That is also demonstrated by regular meetings and field trips, as well as by books [1,2] or publications on the classification of granite pegmatites [3]. Mainly in the discussion of the origin of pegmatites, those of the alkaline massifs (e.g., Lovozero Alkaline Massif/Kola peninsula; see Pekov, 2000) [4] are primarily unconsidered. In the end, the formation of miarolitic and other pegmatites is still a problem. The origin of the large Volyn chamber pegmatites (20 x 20 x 15 m [2] or the smaller miarolitic pegmatites in many granites is not entirely solved. The crucial questions are the origin of the water and the extraordinary enrichment of rare elements, which require a strong pre-enrichment. However, the origin of the water and the room-building energy is unclear, too. A typical case is the famous Sauberg tin deposit near Ehrenfriedersdorf in Saxony. Schröcke [5] has, in his notable contribution to the paragenesis of the tin deposits of the Erzgebirge, shown that the number of pegmatite veins and bodies is so large that the derivation of the necessary water cannot be the adjoining granites. The question of the origin of water for the formation of pegmatites is already unanswered. There is tacit consent that the water comes from the granite itself. Some authors ignore water as an essential component (for example, London 2008). However, water is an indispensable compound for pegmatite formation. Lindgren’s [6] model is often used to explain the formation of the different stages, starting at the liquid magmatic stage, the pegmatite stage, the pneumatolytic stage, and the hydrothermal stage at the end. However, Niggli published such a diagram (page 120) and explanation (page 122) in 1920 [7]. Fermann [8] presents his geochemical-genetic classification of granite pegmatites, which is the basis of later works in this field. In his work (1931b) [9], Fersmann suggests in Figure 5 (page 676) a direct relationship of pegmatites, pneumatolites, and hydrothermalites to the granites and has anticipated the idea of Lindgren (1937) [6]. The present authors have a contradictory opinion. At least a part of the pegmatites results from the interaction of supercritical fluids from mantle deeps with the granites at the intrusion level. Since the beginning of studies on melt inclusion in pegmatite quartz from the tin deposits, particularly on the pegmatites from the Sauberg mine in the Ehrenfriedersdorf district (Central Erzgebirge, Germany), in the years around the turn of the century, the first author often found very water-rich melt inclusions. Water content and temperature appear to be a characteristic relationship from the beginning: a typical solvus curve [10,11]. After that, such curves were also found for many other pegmatites and evolved granites (Figure 1).
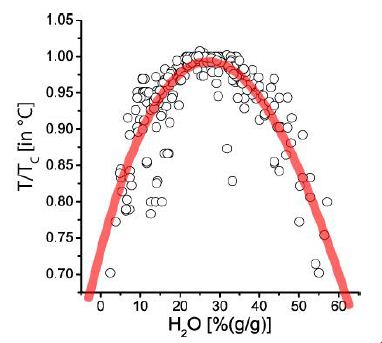
Figure 1: Pseudo-binary solvus curve for 19 different evolved granites and pegmatites worldwide. Note: each point represents the arithmetic mean of measurement on up to 100 melt inclusions [12].
Remarks to Figure 1: Values at T/TC (T in °C) = 1.0 correspond to the solvus curve’s critical point (CP). The abscissa (analytically determined water content) first approximates the melt density. Note here that the point scattering is, in a first approximation, the result of the complex interaction of volatiles (H2O, F, H3BO3), which sometimes work additively (according to Thomas and Rericha, 2023) [12]. Also, minor errors due to the inaccuracy of analytical measurements are additionally possible. For the origin of such curves, a clear answer could not given at this time. The necessary analytical technique was still in its infancy – however, the evidence of the characteristic relationship between water content and temperature increases significantly yearly. Such solvus curves were also obtained during hydrothermal diamond anvil cell (HDAC) experiments [13,14]. However, the indispensable step from experiment to nature is often missing. See to this Niggli (Figure 2a) [7].
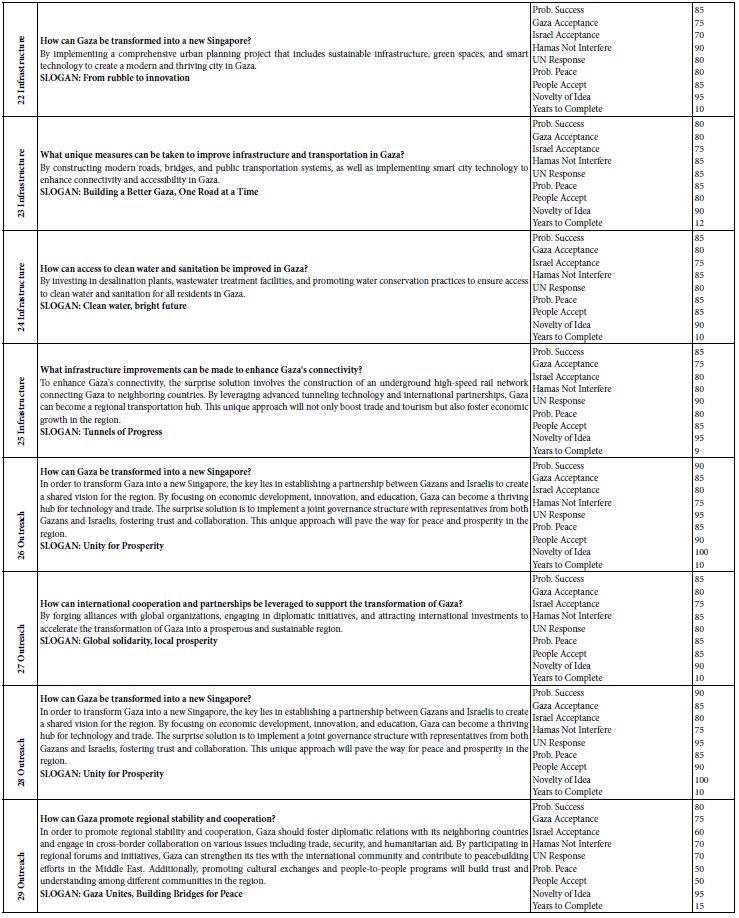
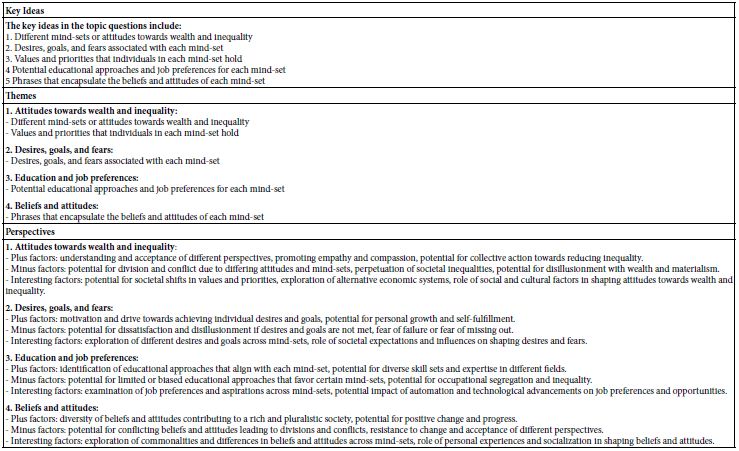
Applying critical parameters (H2Ocrit, Tcrit, and CA-crit) displays relatively good comparability for different granite and pegmatite systems (Figure 2b). Figure 2b is a combination of Figures 1 and Figure 2a schematized.
Such Lorentzian curves are typical for many pegmatites, evolved granites, and other mineralizations, like the Habachtal emerald deposit [15-17]. Figure 2b schematically combines the solvus curves (water versus temperature) with the Lorentzian distributions of elements or anions, like SO42- (Königshain), or CO32- (Habachtal), or Rb, Cs, Be, Sn for the Ehrenfriedersdorf pegmatites and high-temperature mineralizations.
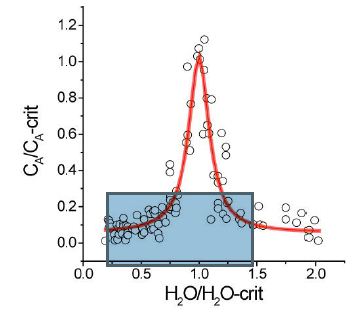
Figure 2a: Plots the normalized element concentration CA/CA-crit versus the normalized water concentration H2O/H2O-crit. This Lorentzian distribution is based on 216 data points (2-10 measurements of each point.
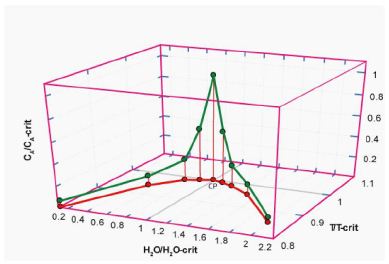
Figure 2b: Schematic three-dimensional diagram in the reduced coordinates (following Guggenheim, 1945 [18]; however, we do not use absolute temperatures here). X-axis: water concentration in a silicate melt (H2O) divided by the water concentration at the critical point (CP). Y-axis: temperature T (in °C) divided by the critical temperature (T-crit) at the point CP. Z-axis: element concentration CA divided by the concentration (CA-crit) at the critical point CP.
There is a systematic relationship between water concentration and temperature and a relationship between the concentration of various elements with water concentration and temperature, mainly in the form of Lorentzian-type curves. The critical point of the solvus curve coincides with the maximum of the Lorentzion distributed elements. The variation of elements showing such Lorentzian-type distribution shows instructive the high dynamic behavior of the supercritical fluids trapped in different melt inclusions. At this point, it is essential to emphasize that the supercritical fluid arriving at the solvus curve (especially at and immediately near the critical point) passes over in the critical and under-critical states (e.g., Ni et al., 2017 [19], Figure 1b in it). So, a more universal relationship is standing behind.
For about 20 elements, the first author and colleagues (e.g., Thomas et al., 2019) [15,16] could demonstrate the validity of such diagrams. However, revealing such curves was the first step to solving this puzzle standing behind the solvus curves, and the combined relationship to the enrichment of elements (the relationship between solvus and Lorentzian curves) has a deeper origin. Combining the two curve sets (pseudo-binary solvus and Lorentzian curves for each component (Figure 2), we see that the statement that the density of the silicate melt decreases is not continuous with the increase in the water content. At the critical point (CP), the concentration of some anions and cations increases rapidly; therefore, the density of the melt also shows a discontinuous, mostly sharp decrease. It is also noteworthy that the surface tension of a liquid decreases with increasing temperature and vanishes at the critical point (Guggenheim, 1945) [18]. If we look at the substantial increase of some elements at or near the critical point, the temperature increases to very high values of about 1000°C or more. From this, the primary temperatures and pressures represent supercritical conditions with typical properties: the viscosity of such fluid goes into the direction of zero, and the diffusivity increases in direction to infinity (as crucial properties). As already shown, the surface tension also vanishes at the critical point. An explanation for this behavior is only possible if we assume a supercritical fluid is coming directly from deep Earth’s mantle. We have found many proofs in crustal rocks, such as diamonds, moissanite, stishovite, coesite, etc. [20]. Traditionally, the miarolitic pegmatites in granites are directly related to their host granite [7,21-24]. Careful study of melt inclusions in many granites demonstrates that besides the typical melt inclusions, representing the granite crystallization (water concentrations between 1 and 12 % – see Johannes and Holtz, 1996) [25], there are also melt inclusions present, which depict a solvus curve with water concentrations between about 5 to more than 50% [26] and a critical point (CP) at the maximum of the solvus curve. A derivation of water directly from the crystallizing granite is complicated because pegmatite veins sometimes have root zones outside the granites.
Key Observations
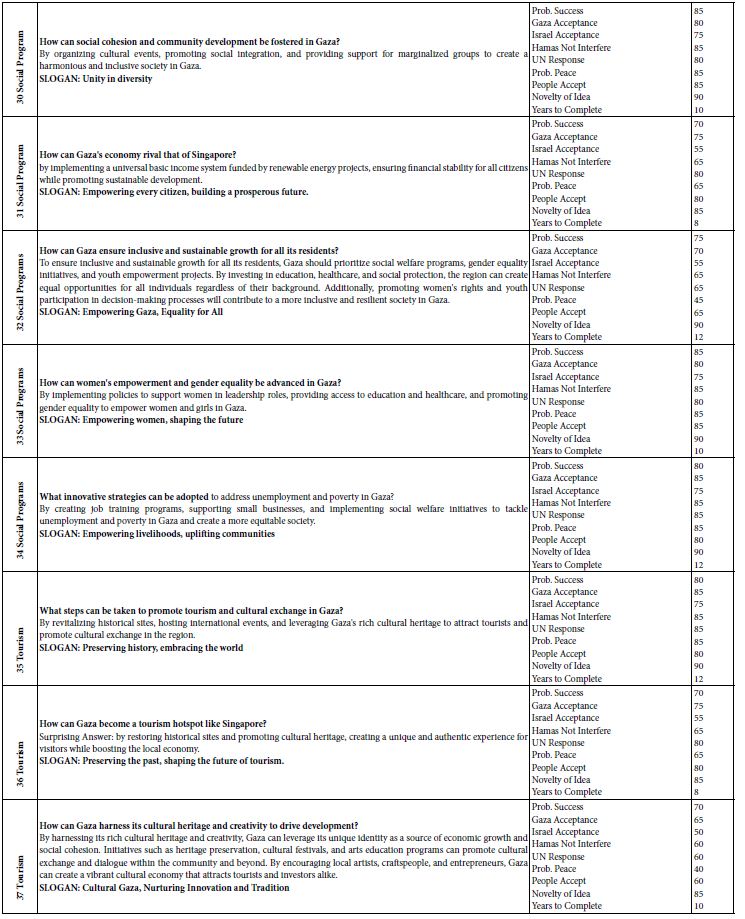
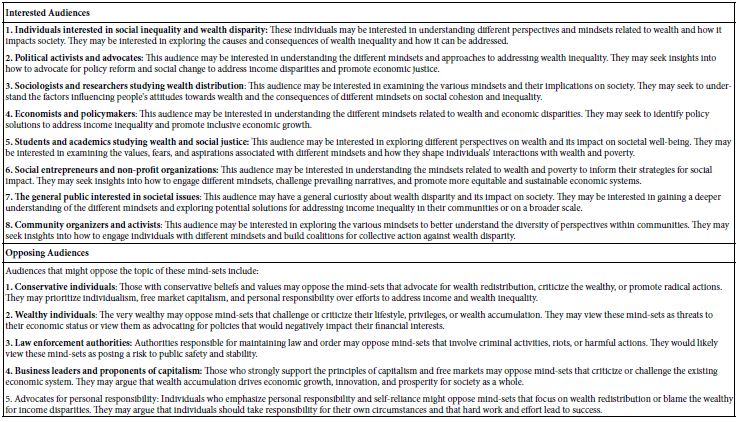
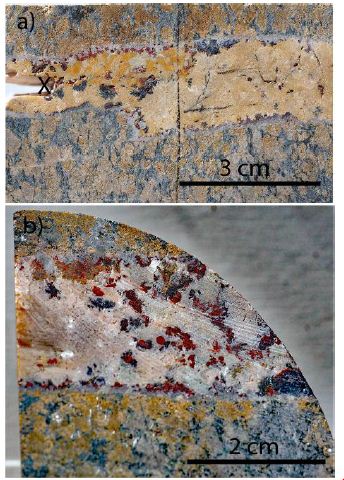
An essential observation is the striking relationship between the solvus curves and the related Lorentzian element distribution around the solvus crest (Figure 2). However, these combinations are imperative but insufficient to state that the supercritical fluids come directly from deep in the mantle. The first proof came from an untypical pegmatite case: the prismatine rock from Waldheim/Saxony. This characteristic rock, with its prismatine crystals, has been discussed till now as a classic metamorphic rock [27]. The second author has intensively studied this rock from an independent standpoint. The prismatine contains high-temperature melt inclusions, which are very water-rich (see Thomas et al., 2022; Figures 9a and 9b in there) and have nothing to do with a poor metamorphic origin – they are atypical for granulite-facial minerals. Besides such H2O-rich melt inclusions, the prismatine crystals also have trapped minerals, like coesite, reidite, and others from mantle deeps. These crystal remnants are mostly spheric with a very smooth (like polished) surface, demonstrating a very fast crystallization of the prismatine. The crystallization of the prismatine host is so fast that the natural crystal habitus of the included spherical crystals is wholly suppressed. The first author has a different view of prismatine crystallization. It is a local pegmatite crystallization initiated by rising supercritical fluids from the mantle. This mantle mineral-bearing supercritical fluid brings the necessary boron from the deep. The fast-crystallizing prismatine includes the mantle minerals (smooth spheres of diamond, coesite) unchanged in the crystal matrix. Of course, the surrounding rock is of metamorphic origin (Figure 3).

Figure 3: Pegmatitic prismatine zone in the granulite from Waldheim/Saxony
Columnar prismatine crystals (up to 3 cm long) are preferentially concentrated in zones that are more than 1 cm thick. In some rock parts, the concentration of prismatine crystals is very high [28], their Figures 1a to 1c).
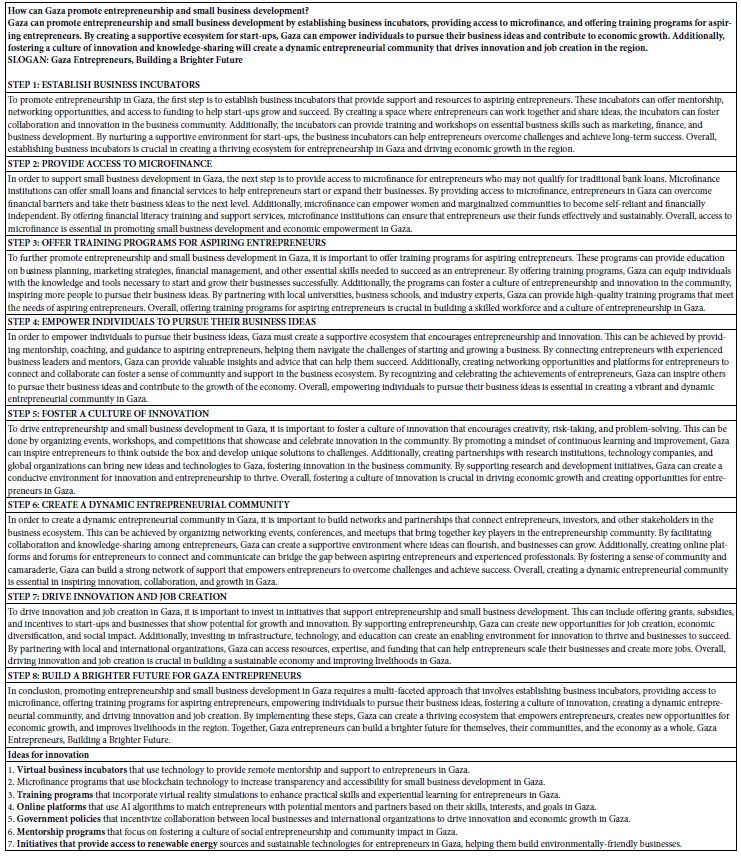
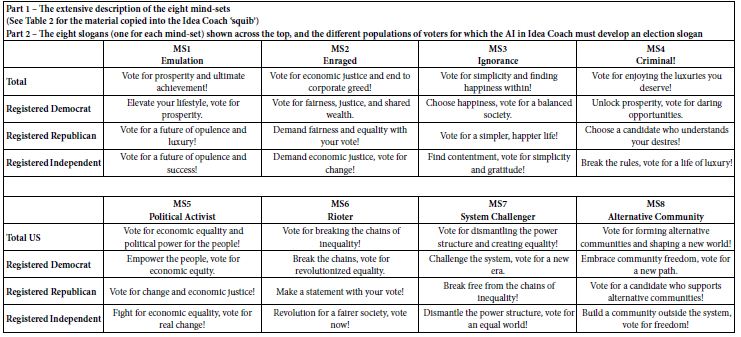
In the meantime, we have found many examples with diamond, graphite, moissanite, and others in more crustal rocks (granites and pegmatite), for which we have often also seen the combination of solvus and Lorentzian curves [29-32]. For the Variscan Königshain granite near Görlitz/Lusatia, we [32] found magmatic epidote, which indicates a speedy ascent of the granite magma (700 to 1000 m/year). With the proof of diamond in zircon of the same rock samples, Thomas (2023a) [31] could show that the flow of a supercritical fluid initiates that fast ascent. Also, many quartz veins in this region can explained by fast-rising supercritical fluids. The solvus curves, the Lorentzian element distribution of some compounds (such as sulfate), and the sporadic appearance of diamonds and graphite in the high-temperature quartz and zircon support this preceding statement. It is not simple to find the high-temperature melt inclusion in the quartz by the more or less strong overprint due to the low-temperature fluid inclusions representing a multi-stage hydrothermal activity. An example is in Thomas et al. (2019) [15,16]. Another example is the steep dipping beryl-quartz veins related to the Sauberg tin deposit near Ehrenfriedersdorf. Figure 4 shows details of such a beryl-quartz vein from the Sauberg mine, and Figure 5 depicts one beryl crystal with a moissanite whisker in the centrum of that crystal.

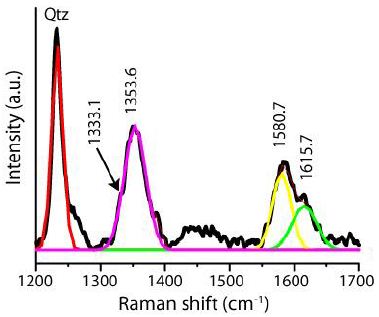
Figure 4: Detail of the studied quartz-beryl sample from the Sauberg mine near Ehrenfriedersdorf: Brl – green beryl, Mlb – molybdenite, Qtz – quartz [33].

Figure 5: An about 600 μm long moissanite (SiC) whisker in the center of a beryl (Brl) crystal (crossed Nicols). Qtz – quartz [33].
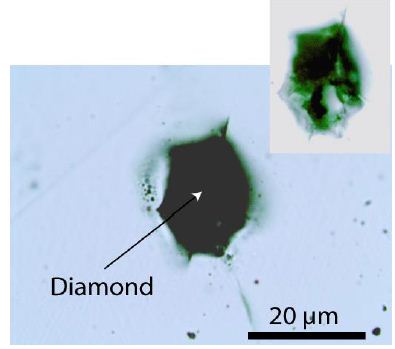
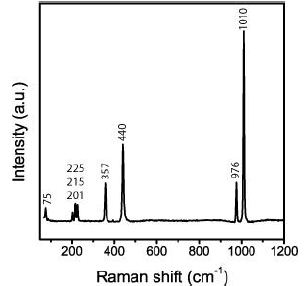
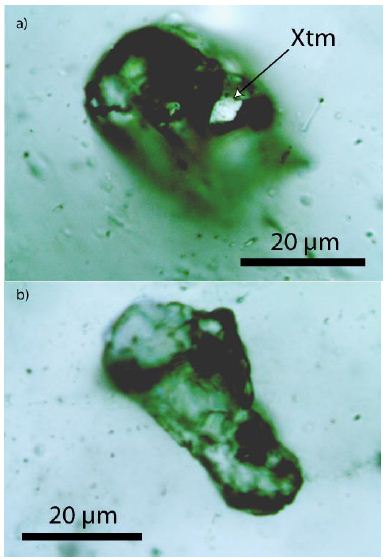
This sample’s beryl and, more sporadically, quartz also contains many nanodiamonds and moissanite crystals, including and partly grown at a crustal level untypical for those crystals. This example clearly shows that unpredictable processes can work at changing the supercritical fluid into a critical/undercritical one. Nanocrystals of diamond and moissanite are germs of larger crystals. Recently, Thomas (2024a) [34] showed that in small (~2 cm) steeply inclined pegmatite veins in gneiss from drill cores near Annaberg/Erzgebirge, many nanodiamonds and graphite are present, which demonstrates that supercritical fluids rising from mantle regions are also present far away from the classic tin deposits in the Ehrenfriedersdorf region. Notably, there is a high concentration of distributed submicroscopic diamond and graphite crystallites (Thomas, 2024) in a small vertical pegmatite vein. From all observations, it follows that the composition of the supercritical fluids is highly variable from place to place. Sometimes, the typic relicts are a combination of diamond and graphite only, and sometimes, we have observed very complex parageneses (diamond, graphite, moissanite, coesite, cristobalite-X-I (high-pressure phase of cristobalite; see Černok et al., 2017) [35], and others. Careful observations of very different pegmatites and other mineralizations (Habachtal emerald deposit) have shown that nanodiamonds, graphite, and other high-pressure minerals are testimony of the supercritical fluids. Regarding the Habachtal emerald, its melt inclusions contradict the regional geology. The thesis of the involvement of supercritical fluid solves this dilemma elegantly (see Thomas et al., 2020) [17]. Also, the first author found nanodiamonds, besides graphite, in eudialyte-bearing [Na4(Ca, Ce)2(Fe2+, Mn2+)ZrSi8O22(OH, Cl)2] pegmatites in the Lovozero Massif [4] (Figure 6).
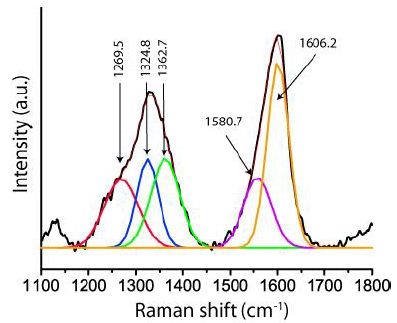
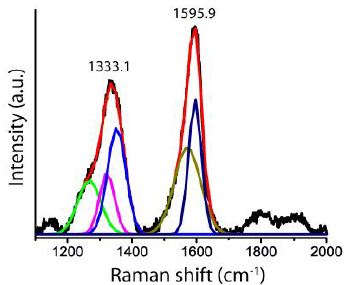
Figure 6: Raman spectrum of graphite-diamond aggregate in nepheline in the eudialyte rock. The diamond line at 1324.8 cm-1 has a FWHM of 45.7 cm-1. The graphite main band at 1606.2 cm-1 is remarkably high.
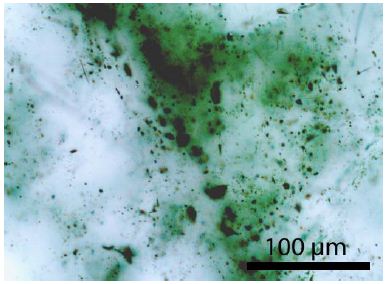
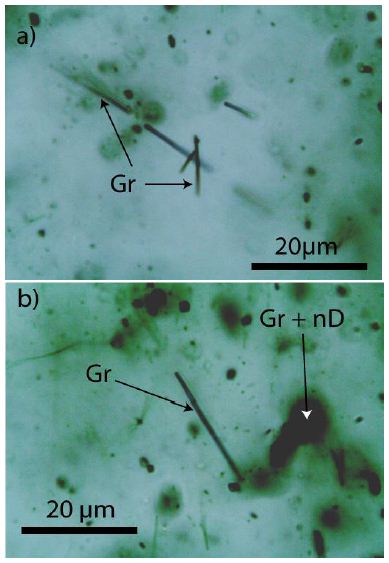
As a rule, the diamonds are tiny, about 4 µm in diameter. Larger spherical graphite crystals are widespread (Figure 7 and Table 1).

Figure 7: Small diamond (D) crystal with graphite (Gr) in nepheline (Ne). The crystal is 30 µm under the sample surface.
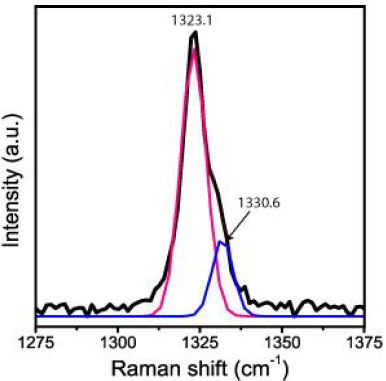
Table 1: Raman data of spherical diamond and graphite inclusions in pegmatite nepheline in eudialyte-dominant rock from Lovozero Massif (15 spherical crystals).
|
Phase |
Position (cm-1) | FWHM (cm-1) | Position (cm-1) |
FWHM (cm-1) |
| Diamond |
1333.0 ± 8.6 |
81.0 ± 16.2 |
||
| Graphite G |
1578.6 ± 9.5 |
80.9 ± 10.8 |
||
| Graphite D2 |
1604.3 ± 3.0 |
42.5 ± 8.0 |
FWHM – full width at half maximum
Interpretation
Based on innumerable results from natural samples, we could demonstrate that supercritical fluids significantly affect many mineralizations in water and energy delivery. Niggli [36] already emphasized the outstanding significance of H2O for forming pegmatites. He wrote (page 423): “Melt solutions in which water is plentiful as an essential volatile component besides large amounts of non-volatile components are called pegmatitic solutions.” However, over the origin, the reader remains in the obscure. Ni [37] gives in his introduction to advances in the study of supercritical fluids essential hints to the effects of supercritical fluids, which covers a broad spectrum between hydrous melts and aqueous solutions with an emphasis on the enrichment of large ion lithophile elements (LILE), U-Th-Sr and REE. Sun et al. [38] show that supercritical fluids’ speciation and transport properties are essential for understanding their behavior in the Earth’s interior. According to our studies, supercritical fluids connect the deep mantle and the crust by delivery of energy, water, and various elements, e.g., coming from subducted zones. Our studies answer those open questions regarding the origin of water. There is already a lot to solve all problems related to the origin of water and the processes connected with the transition from the supercritical to the under-critical stage of water. The enrichment processes in this state, indicated by the Lorentzian type of element distribution, are a further open problem. Element enrichment in a relatively small room by the factors of 104 to 105 is not seldom. Is there communication between the particles, like the quantum entanglement in the supercritical state?. We have seen that mantle minerals like nanodiamonds are already present in the old Volyn pegmatites (1760 Ma) [39], the pegmatites from the Lovozero Massif of Devonian age and the younger ones like the Variscan Erzgebirge and the Königshain Massif [20], Furthermore, it follows the question of the time and intensity of the ascending supercritical fluid: sporadic or continuous?
Acknowledgment
We thank many coworkers and other scientists in the past who have contributed to the supercritical fluids and their proof in natural samples. A special thanks go to Huaiwei Ni (Hefei, China), Yicheng Sun (Nanjing), and Jim Webster (New York).
References
- London D (2008) Pegmatites. The Canadian Mineralogist, Special Publication 10.
- Pavlishin VI, Dovgyi SA (2007) Mineralogy of the Volynian Chamber Pegmatites, Ukraine. Volodarsk- Mineralogical Almanac 12.
- Müller A, Simmons W, Beurlen H, Thomas R, Ihlen PM, et al. (2018) A proposed new mineralogical classification system for granitic pegmatites – Part I: History and the need for a new classification. The Canadian Mineralogist 56: 1-25.
- Pekov IV (2000) Lovozero Massif: History, Pegmatites, Minerals. Moscow.
- Schröcke H (1954) Zur Paragenese erzgebirgischer Zinnerzlagerstätten. Neues Jb. Abh 87: 33-109.
- Lindgren W (1937) Succession of minerals and temperatures of formation in ore deposits of magmatic affiliation. American Institute of Mining, Metallurgical, and Petroleum Engineers. Technical Publication 126.
- Niggli P (1920) Die Leichtflüchtigen Bestandteile im Magma. B.G. Teubner Verlag Leipzig.
- Fersmann A (1931a) Über die geochemische-genetische Klassifikation der Granitpegmatite. Zeitschrift für Kristallographie, Mineralogie und Petrographie, Abteilung B Mineralogische und Petrographische Mitteilungen 41: 64-83.
- Fersmann A (1931b) Geochemische Diagramme. Neues Jb. Mineral. Etc. Abh.
- Thomas R, Webster JD, Heinrich W (2000) Melt inclusions in pegmatite quartz: complete miscibility between silicate melts and hydrous fluids at low pressure. Mineral, Petrol. 139: 394-401.
- Thomas R, Förster HJ, Heinrich W (2003) The behaviour of boron in a peraluminous granite-pegmatite system and associated hydrothermal solutions: a melt and fluid-inclusion study. Mineral, Petrol. 144: 457-472.
- Thomas R, Rericha A (2023) The function of supercritical fluids for the solvus formation and enrichment of critical elements. Geology, Earth and Marine Sciences (GEMS) 5: 1-4.
- Shen AH, Keppler H (1997) Direct observation of complete miscibility in the albite-H2O system. Nature 385: 710-712.
- Bureau H, Keppler H (1999) Complete miscibility between silicate melts and hydrous fluids in the upper mantle: experimental evidence and geochemical implications. Earth and Planetary Letters 165: 187-196.
- Thomas R, Davidson P, Appel K (2019) The enhanced element enrichment in the supercritical states of granite-pegmatite systems. Acta Geochim 38: 335-349.
- Thomas R, Davidson P, Rericha A, Tietz O (2019) Eine außergewöhnliche Einschlussparagenese im Quarz von Steinigwolmsdorf/Oberlausitz. Berichte der Naturforschenden Gesellschaft der Oberlausitz 27: 161-172.
- Thomas R, Davidson P, Rericha A (2020) Emerald from the Habachtal: new observations. Mineralogy and Petrology 114: 161-173.
- Guggenheim EA (1945) The principle of corresponding states. The Journal of Chemical Physics 13: 253-261.
- Ni H, Zang L, Xiong X, Mao Z, Wang J (2017) Supercritical fluids at subduction zones: Evidence, formation condition, and physicochemical properties. Earth-Science Reviews 167: 62-71.
- Thomas R (2023) The Königshain Granite: Diamond inclusion in zircon. Earth Mar. Sci. 5: 1-4.
- Niggli P (1937) Das Magma und seine Produkte. Akademische Verlagsgesellschaft M.B.H. Leipzig.
- Fersman AE (1934) Geochemistry Vol. II, Leningrad, 1-354 (in Russian).
- Fersman AE (1937), Geochemistry Vol. III, Leningrad, 1-503 (in Russian).
- Fersman AE (1961) Les Pegmatites. Librairie Universitaire Uystpruyst, Louvain. Tome I, 163 p.; Tome II, 164-437 p.; Tome III, 438-739.
- Johannes W, Holtz F (1996) Petrogenesis and Experimental Petrology of Granitic rocks. Springer Verlag.
- Thomas R, Förster HJ, Rickers K, Webster JD (2005) Formation of extremely F-rich hydrous melt fractions and hydrothermal fluids during differentiation of highly evolved tin-granite magmas: a melt/fluid-inclusion study. Mineral. Petrol. 148: 582-601.
- Grew ES, Thomas R (2021) Coesite and relict diamond in prismatine and pyrope from Waldheim, Germany: New evidence for deep burial of the Saxony Granulitgebirge and its implications for the Bohemian Massif of central Europa. Research Seminar at the University of Maine-Orono, September 15.
- Thomas R, Davidson P, Rericha A, Recknagel U (2022c) Water-rich coesite in prismatine-granulite from Waldheim/Saxony. Veröffentlichungen Museum für Naturkunde Chemnitz. 45: 67-80.
- Thomas R, Davidson P, Rericha A, Recknagel U (2022a) Discovery of stishovite in the prismatine-bearing granulite from Waldheim, Germany: A possible role of supercritical fluids of ultra-high-pressure origin. Geosciences 12: 196, 1-13.
- Thomas R, Davidson P, Rericha A, Recknagel U (2022b) Supercritical fluids conserved as fluid and melt inclusions in quartz from the Sheba-Gold Mine, Barberton, South Africa. Aspects in Mining & Mineral Science 10: 1193-1196.
- Thomas R, Davidson P, Rericha A, Recknagel U (2023a) Ultrahigh-pressure mineral inclusions in a crustal granite: Evidence for a novel transcrustal transport mechanism. Geosciences 94: 1-13.
- Thomas R, Davidson P (2016) Origin of miarolitic pegmatites in the Königshain granite/Lusatia. Lithos 260: 225-241.
- Thomas R, Recknagel U, Rericha A (2023b) A moissanite-diamond-graphite paragenesis in a small beryl-quartz vein related to the Ehrenfriedersdorf deposit, Germany. Aspects in Mining & Mineral Sience 11: 1310-1319.
- Thomas R (2024a) Graphite and diamond-rich pegmatite as a small vein in a gneiss drill core from the Annaberg region Erzgebirge, Germany. Geology, Earth and Marine Sciences (GEMS) 6: 1-4.
- Černok A, Marquardt K, Caracas R, Bykova E, Habler G, et al. (2017) Compressional pathways of -cristobalite, structure of cristobalite X-I, and towards the understanding of seifertite formation. Nature Communications 8: 1-12.
- Niggli P (1954) Rock and Mineral Deposits. W.H. Freeman and Company, San Francisco.
- Ni H (2023) Introduction to advances in the study of supercritical geofluids. Science China Earth Sciences 66: 2391-2394.
- Sun Y, Liu X, Lu X (2023) Structures and transport properties of supercritical SiO2-H2O and NaAlSi3O8-H2O-fluids. American Mineralogist 108: 1871-1880.
- Thomas R (2024b) Another fluid inclusion type in pegmatite quartz: Complex organic compounds. Geology, Earth and Marine Sciences (GEMS) 6: 1-5.