Abstract
Background: Brain-derived neurotrophic factor (BDNF) levels in maternal serum and umbilical cord blood serum samples from women who underwent water immersion during labor and those who gave birth without water immersion were compared.
Objectives: This study aimed to investigate the impact of water immersion on maternal and neonatal serum BDNF levels. A total of 57 pregnant women were included in the study, 32 in the non-water immersion group and 25 in the water immersion group. Serum BDNF levels were measured by ELISA an Enzyme-Linked ImmunoSorbent Assay (ELISA). For comparisons between groups, the independent samples t-test, Mann-Whitney U-test, and Spearman rho correlation test were used.
Results: No differences were observed in age, gravidity, parity, maternal BMI, infant weight, and infant sex (p=0.97, p=0.61, p=0.71, p=0.24, p=0.14, and p=0.88, respectively). There was no difference in maternal serum BDNF levels between the two groups were compared (p=0.152). Cord blood BDNF levels were found to be significantly different in the water immersion group compared to the conventional vaginal delivery group (p=0.03).
Conclusions: The high BDNF levels in the water immersion group suggest that this method may contribute to the neurological development of infants. We believe that water immersion can have a positive effect on the psychology of mothers and their babies.
Keywords
Hydrotherapy, Brain-derived neurotrophic factor, Immersion in water, Neurological development
Introduction
Hydrotherapy and water immersion are long-standing therapeutic techniques used in medicine. Thus, the popularity of this method has increased. Water immersion has become widely used worldwide as a non-pharmacological method for reducing the stress of labor pain [1-3].
Although water birth and hydrotherapy (water immersion or immersion in water) are thought to be similar techniques, they are different. While hydrotherapy is a non-pharmacological method to cope with labor pain, water birth is the use of hydrotherapy in the second stage of labor, and as the delivery takes place in water, it can be accepted as a birth method.
Studies have underscored the drawbacks of water birth, including the risks of maternal and neonatal infections as well as potential respiratory issues for newborns [3]. Water birth performed by skilled obstetric care providers in a hospital setting is a reasonable option for low-risk women and their newborns. In a recent study, the water immersion group demonstrated lower rates of neonatal intensive care, special care nursery admission, and perineal laceration than the control group. Furthermore, this review provides additional information on immersion water [4-6].
The benefits of water immersion for pregnant women are apparent. Owing to the buoyancy of water, hydrotherapy enables pregnant women to move their legs more easily. It has been proposed that water immersion during labor enhances maternal satisfaction and a sense of control [1].
Women who sense control during childbirth tend to have enhanced emotional well-being postnatally [1]. It is also known that immersion in water significantly reduces the anxiety of pregnant women [2]. Some professional associations, such as the Royal College of Obstetricians and Gynecologists and the American College of Nurse-Midwives, support uncomplicated healthy pregnant women having water births [7].
BDNF is a protein belonging to the neurotrophin subfamily that has various effects on the central nervous system. Neurotrophins is a crucial intracellular factor that contributes to the maintenance of neuronal function. BDNF forms neurotrophins, which are very important in protecting the nervous system and neuronal structure. BDNF plays a role in the differentiation of cells into neurons in the neural root during development by preventing neuronal death in cases such as trauma or ischemia in adult brain cells. It contributes significantly to the continuation of their vitality. In addition, BDNF has a significant impact on brain development in the prenatal and postnatal periods [8-10].
BDNF has been studied in mammals, mostly during the prenatal period and neurogenesis phase [8]. This stage is important because although neurogenesis is completed a few days before birth, most neurons in the hippocampus occur after birth [11].
We aimed to investigate the relaxing and pain-reducing effects of water immersion on maternal and infant cord serum BDNF levels.
Methods
Study Design
This prospective case-control observational study was carried out at the Zekai Tahir Burak Women’s Health Education and Research Hospital with the approval of the ethics committee (ethical approval statement: 58/2018) and in accordance with the Helsinki criteria. The women were divided into two groups: the control group consisted of 32 pregnant women who did not receive water immersion during labor and gave birth vaginally, and the case group consisted of 30 women who received water immersion during labor and gave birth vaginally.
Setting
We selected our study patients among full-term pregnant women between 37-40 weeks, hospitalized in the obstetrics clinic for delivery. Our study was conducted over a period of 6 months.
Immersion water was present in the special pools in the delivery room. Attention was paid to the cleaning of the pool. The bathtub was cleaned after each use as part of the precautions taken to prevent infection before immersion. First, the organic waste was removed and prewashed with running water. After preliminary cleaning with detergent and water, drainage pipes were cleaned and treated with chlorine tablets. The cleaning was completed after waiting for a certain period. Materials used in bathtubs, such as thermometers and hand dopplers, are also disinfected by surface disinfectants. After disinfection, cultures were collected from the bathtub surface, pool bottom, drain, and water flow areas. If the culture result is negative, the pregnant woman can be placed in a bathtub. All operations were performed by trained personnel.
Participants
A total of 62 pregnant women between the ages of 18 and 40 years, with pregnancies between 37 and 40 weeks, and who were in active labor during the examination, were included in our study. All pregnant women were in vertex presentation at the examination and had antenatal follow-ups in the maternity polyclinics of the same hospital. The amniotic membrane was observed to be intact during the examination. The exclusion criteria were as follows: pregnant women with a history of cesarean section, chronic disease, malpresentation, ruptured amniotic membrane, high-risk pregnancy, and medical and obstetric risks. Pregnant women with macrosomia fetuses and refugees on ultrasound who also had signs of active infection and fetal distress with bleeding were excluded from the study (Figure 1).
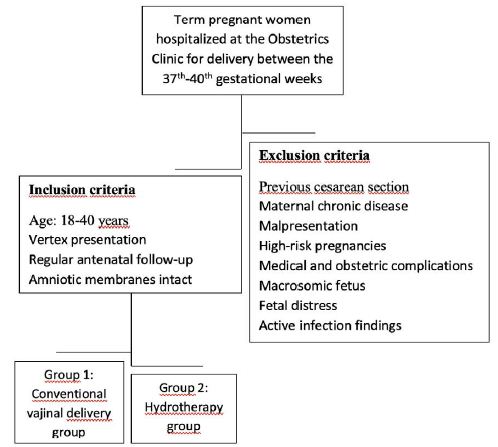
Figure 1: Inclusion and exclusion criterias.
The control group comprised of 32 patients with normal birth pain. No non-pharmacological or pharmacological pain relief methods were applied in this group. Labor was not induced.
Pregnant women in the case group (n=30) with cervical dilatation of 3 cm and 70% were taken to a pool, which had a temperature of 37–37.5⁰C and was wide enough for the woman to move freely. Fetal heart monitoring was performed at regular intervals using Doppler or non-stress tests (NST). The second stage of labor was carried out in a controlled manner outside the water. In both groups, as soon as the baby was born, it was placed on the mother’s womb, the cord was cut, and the delivery of the placenta and membranes was completed.
Venous blood samples were obtained from the mothers after birth. After the cord was clamped, blood samples were collected.
Measurements
Serum samples were separated by centrifugation at 5000 revolutions/min (2236 × g) for 10 min within 15–20 min of blood sampling. They were frozen immediately and stored at -80⁰C until the final analysis.
Serum BDNF levels were measured using an ELISA. The BDNF concentration was determined using the Elab Science Human BDNF ELISA kit (Elabscience Biotechnology Inc., Wuhan, China), which had a sensitivity of 18,75 pg/mL. The sandwich principle was used for the ELISA kit. The micro-ELISA plate provided in this kit was precoated with an antibody specific for human BDNF. Assays were performed according to the manufacturer’s instructions as follows: standards and samples were added to the micro-ELISA plate wells and combined with the specific antibody. Then, a biotinylated detection antibody specific for human BDNF and an avidin-horseradish peroxidase (HRP) conjugate were added to each microplate well and incubated. The free components were then washed away. The substrate solution was then added to each well. The enzyme-substrate reaction was terminated by the addition of a stop solution. The optical density (OD) was measured spectrophotometrically at a wavelength of 450 ± 2 nm. The OD value is proportional to the concentration of human BDNF. Maternal serum and infant cord blood BDNF levels (pg/ml) were recorded.
Bias
The case and control groups were selected from patients with the same characteristics. In contrast, only hydrotherapy was administered in the patient group. Five of the 30 patients in the case group were excluded from the study because their blood samples were damaged during transport. The number of cases had decreased to 25.
Statistical Analyses
Study Size
The mean standard deviation of BDNF in women giving birth in water was predicted to be 1200 ± 290 pg/ml. Thus, the effect size was calculated to be 0.741. With an alpha of 0.05 and power of 0.80, the sample size was determined to be 60 people in total, with at least 30 people in each group.
Variables
After birth, the weight and sex of the infants were recorded. In this study, age, gravidity, parity, BMI, baby weight, baby sex, and BDNF levels were compared between the two groups.
Statistical Methods
Whether the variables with numerical results in the study were normally distributed was examined using the Shapiro–Wilk test and graphs (histogram, boxplot, etc.). Normally distributed variables, such as age, infant weight, and BMI, were compared between the two groups using an independent sample t-test. While performing the independent samples t-test, Levene’s test was used for the equality of variances. The distribution of other numerical variables that did not show a normal distribution was compared between the two independent groups using the Mann-Whitney U test, which is a nonparametric test. Descriptive statistics are given as the mean standard deviation for numerical variables compared with parametric tests and median (min-max) for nonparametric tests. Sex, which is a categorical variable, was compared between the groups using the Pearson Chi-Square test. Yates’ correction was not used, and descriptive statistics for this variable are given as numbers and percentages. The relationships between numerical variables were analyzed using Spearman’s rho correlation coefficients. Statistical significance was set at p < 0.05. Analyses were performed using SPSS IBM Statistics 23.0 Program.
Of the 62 pregnant women included in the study, 32 were in the control group and all were considered suitable until the end of the study. As the serum samples of 30 pregnant women in the case group were collected during transportation, 25 were evaluated.
Results
Descriptive Data
When the demographic data of the two groups were examined, no differences were observed in age, gravidity, parity, maternal BMI, infant weight, and infant sex (p=0.97, p=0.61, p=0.71, p=0.24, p=0.14, p=0.88, respectively) (Table 1).
Table 1: Comparison of demographic characteristics, clinical features and BDNF levels of umbilical cord, and maternal serum between the control and case groups.
|
Variables |
The control group (labor without immersion-no hydrotherapy) | The case group (labor immersion in water-hydrotherapy) |
P-value t/df/z/x² |
| Frequency |
32 |
25 | |
|
Age (years) Mean ± SD |
26 ± 5.5 | 26 ± 5.8 |
0.979 t: -0.027 df: 55 |
| Gravida Mean ± SD (Median (Min-Max) |
2.03 ± 0.7 2(1-4) |
2.16 ± 0.8
2(1-4) |
0.613
z: -0.505 |
|
Parity Mean ± SD (Median (Min-Max) |
0.94 ± 0.6
1(0-2) |
1 ± 0.6
1(0-2) |
0.711 z: -0.370 |
| BMI kg/m2 Mean ± SD |
28.76 ± 4.7 |
27.49 ± 2.9 | 0.249
t: 1.166 df: 55 |
|
Baby weight kg Mean ± SD |
3.304 ± 447 | 3.460 ± 329 |
0.149 t: -1.063 df: 55 |
| Baby gender male/female n (%) |
Male: 16 (50%) Female: 16 (50%) |
Male: 13 (52%)
Female: 12 (48%) |
0.881
x²: 0.022 df: 1 |
|
Maternal serum BDNF levels pg/ml Mean ± SD (Median (Min-Max) |
110.07 ± 79.89
85.49(39.16-359.68) |
130.83 ± 79.44
113.79(13.90-332.57) |
0.152 z: -1.431 |
| Umbilical cord serum BDNF levels pg/ml Mean ± SD
(Median (Min-Max) |
160.47 ± 82.31 137.81(66.72-415.49) |
226.48 ± 128.44
168.20(84.99-48.204) |
0.033* z: -2.127 |
P-value <0.05 is considered as statistically significant.
BMI: Body mass index; BDNF: Brain derived neurotrophic factor; SD: Standard deviation.Min-Max: Minimal and maximal value.
An independent samples t-test (with t and df) was used to compare age, baby weight, and BMI. While performing the Independent samples t test, Levene’s test was used for equality of variances.
The Mann-Whitney U test (with p and z values) was used to compare gravida, parity, and BDNF.
The Pearson Chi-Square test (with value (x²) and df) was used to compare the gender distribution of babie. Yates’s correction was not us.
Outcome Data
When the maternal serum BDNF levels were analyzed, no statistically significant difference was observed between the two groups (p=0.152). However, cord blood BDNF levels were significantly different between the case group compared with the control group (p=0.03).
Neither maternal serum nor cord serum BDNF values differed according to sex (p=0.861 and p=0.718, respectively). A statistically weak but significant correlation was found between infant weight and maternal serum BDNF level (p=0.004; r=0.371). There was also no relationship between baby weight and cord BDNF level (p=0.642; r=0.063) (Table 2).
Table 2: Maternal and umbilical cord serum BDNF levels acccording to baby gender.
|
Variables |
Female n=28 | Male n=29 | P-value |
|
Maternal serum BDNF levels pg/ml Mean ± SD (Median (Min-Max) |
126.77 ± 92.05
87.03(39.16-359.68) |
111.85 ± 66.38
96.95(13.90-312.64 |
0.861 z: -0.176 |
| Umbilical cord serum BDNF levels pg/ml Mean ± SD
(Median (Min-Max) |
189.94 ± 117.05 |
191.84 ± 104.02 |
0.718 z: -0.361 |
BDNF: Brain Derived Neurotrophic Factor; SD: Standard deviation; Min-Max: Minimal and maximal value.
The Mann-Whitney U test (with p and z values) was used to compare BDNF.
Discussion
Immersion in the waterbirth method provides many benefits in the form of maternal satisfaction, pain control, and easy movement in water. In this method, pain is reduced by hydrotherapy by taking pregnant women into the pool during labor, but birth takes place outside the pool. On the other hand, during a water birth, the pregnant woman is taken into the water during labor, and the birth takes place in the water. Both methods have been found to be beneficial for the emotional comfort of postpartum mothers [1]. However, studies on the neonatal benefits of these methods are limited. There are selected studies on immersion in water and the absence of fetal side effects during birth [4,12].
This study was designed to investigate the potential benefits of water immersion. The advantages of water immersion during labor or birth encompass reduced pain, expanded functional diameter of the true pelvis, improved quality of contractions, heightened release of endorphins, diminished reliance on opiates, increased mobility for the mother, and enhanced positioning during various stages of labor [13]. We aimed to investigate whether hydrotherapy has an increasing effect on maternal and infant cord BDNF values, and whether hydrotherapy has a positive neurohormonal effect. We compared BDNF, a neurotrophic factor in the serum of maternal and infant cord blood, in hydrotherapy and conventional vaginal delivery and found that maternal serum BDNF levels were not different. Although there was no statistical difference between maternal serum BDNFs levels, the mean values in the hydrotherapy group were significantly higher. This may be because of the small sample size. Despite this, cord serum BDNF levels were significantly higher in the hydrotherapy group.
Neurotrophins are important regulators of neural cell survival, development, function and plasticity. Mammals have four neurotrophins that are derived from the same ancestral gene [26]. Neurotrophins support neuron survival and prevent neuron apoptosis [14].
Neurotrophins play an important role in axon growth during development, higher neuronal function, morphologic differentiation, and neurotransmitter expression [15]. Thus, neurotrophins can play an important role in the development of the brain before and after birth. However, data on the presence and effects of neurotrophins in preterm infants are insufficient. BDNF and NT-3 are highly expressed in the cortical and hippocampal structures and have been linked to the survival and function of multiple neuronal populations [16].
BDNF was found to be related to hypoxic-ischemic encephalopathy, mental retardation, and autism in newborns. The importance of BDNF and NT3 in neurodevelopment in the intrauterine period has been emphasized. There is evidence that prenatal or maternal traumatic stress has a significant impact on neurodevelopment. In general, the earlier and more severe the trauma, the more impaired the neurodevelopment [17]. The better the mother’s comfort during delivery, the easier the mother’s adaptation to the mother’s puerperium, and the lower the rate of postpartum depression. Therefore, we believe that immersion in water may be beneficial to neurological development.
BDNF is important in neuronal plasticity [18]. BDNF has mostly been studied in mammals during the prenatal and neurogenesis stages, but relatively less in the postnatal period [8]. This phase is important because, although neurogenesis is completed several days before birth, most neurons in the hippocampus appear after birth [11]. In addition, since BDNF is very important in mammalian adults, our research goal was to investigate whether BDNF changes depending on the mode of delivery.
In the water immersion group, high BDNF levels in the cord blood, but not in the mother’s blood, may contribute positively to the neurological development of the newborn. Moreover, Kodomori et al. showed in their animal study that maternal BDNF contributes to the neurological development of the fetus through uteroplacental passage. In our study, high BDNF levels were detected in the cord blood of rats in the water immersion group. In the perinatal period, the blood-brain barrier is immature because circulating BDNF may reflect the level of BDNF in the central nervous system, and circulating cortical BDNF levels are correlated, as has been reported. Again, in previous studies, conditions such as surgery, stress, birth, and hypotension that cause stress in the central nervous system have been found to cause changes in BDNF release. Accordingly, since hydrotherapy is a less painful and emotional form of delivery, higher BDNF values were obtained in our study group [18-20].
We also investigated the relationship between infant weight and BDNF levels and found only a weak link between maternal serum BDNF levels and infant weight. All the infants included in this study were term. In a recent animal experimental study [21], the relationship between infant sex and BDNF was investigated, and it was shown that BDNF content increased in the brains of both male and female rat pups 0 h after hypoxia and 4 h in serum; however, only males had increased brain BDNF levels 4 h after hypoxia. When we investigated the relationship between baby sex and BDNF levels, we did not find any difference in BDNF levels between the sexes. This may be due to the small number of patients. As this subject has been extensively researched and the importance of BDNF and other neurohormones is increasing, more long-term studies are needed.
Recent studies have investigated the use of serum BDNF levels in Alzheimer’s disease and as a biomarker of schizophrenia and depression. We aimed to examine serum BDNF levels because we believe that hydrotherapy has positive effects on maternal psychology and protects against the development of postpartum depression. As hydrotherapy has positive effects on maternal psychology and postpartum depression, we examined serum values [21-23].
Neurotrophic factors play crucial roles in neuroprotection. Neurotrophins promote survival and reduce apoptosis in many populations of neurons [14].
Limitations of the Study
The small number of participants in our study and the fact that we did not follow mothers and babies in the long term may be a limitation of our study.
Conclusions
In light of these studies, the neuroprotective effects of neurotrophins, especially BDNF, including anti-apoptotic axonal development of neurons, neurodevelopmental effects that have healing effects in some neurodegenerative diseases, and their positive effects in diseases such as autism and mental retardation, have increased the importance of BDNF in recent years. The relationship between BDNF, other delivery modes, and hydrotherapy has not been previously studied. Although we have shown in our study that hydrotherapy delivery may have a positive effect on BDNF levels, we believe that immersion in water contributes to the development of neurons in newborns by increasing BDNF levels. We hope that our study will encourage future research on this very important subject and will shed light on future studies on this very important subject.
Declarations
- Conflict of interest: Not applicable
- Funding: This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
- Ethical approval: Ethical approval was received from the Zekai Tahir Burak Women’s Health Education and Research Hospital with the approval of the ethics committee (ethical approval statement: 58/2018).
- Consent to Participate: All participants provided written informed consent prior to their participation in the study in accordance with the tenets of the Declaration of Helsinki.
- Authors’ Contributions:
Conceptualization: Rahime Bedir Findik
Investigation: Rahime Bedir Findik, Ozlem Uzunlar, Esin Merve Erol Koc
Methodology: Rahime Bedir Findik, Ozlem Uzunlar
Resources: Rahime Bedik Findik, Ozlem Uzunlar, Esin Merve Erol Koc
Validation: Rahime Bedir Findik, Ozlem Uzunlar
Supervision: Yaprak Ustun
Writing – original draft: Rahime Bedir Findik, Ozlem Uzunlar
Writing – review & editing: Rahime Bedir Findik, Ozlem Uzunlar
Formal analysis: Jale Karakaya, Gulsen Yilmaz, Fatma Meric Yilmaz Mert
All authors have read and agreed to the submitted version of the manuscript. - Data availability: Data are however available from the authors upon reasonable request and with permission from [third party name].
- Czech I, Fuchs P, Fuchs A, Lorek M, Tobolska-Lorek D, et al. (2018) Pharmacological and Non-Pharmacological Methods of Labour Pain Relief-Establishment of Effectiveness and Int J Environ Res Public Health. 2018 Dec 9;15(12). [crossref]
- Benfield RD, Hortobágyi T, et al. (2010) The Effects of Hydrotherapy on Anxiety, Pain, Neuroendocrine Responses, and Contraction Dynamics During Labor. Biol Res Nurs 12(1). [crossref]
- Poder TG, Larivière M (2014) Bénéfices et risques de l’accouchement dans l’eau: Une revue systématique. Gynécol. Obs. Fertil. 42(10): 706-713.
- Neiman, E, Austin E, Tan A, et (2020) Outcomes of waterbirth in a US hospital‐ based midwifery practice: a retrospective cohort study of water immersion during labor and birth. Journal of Midwifery & Women’s Health 65(2). [crossref]
- Sidebottom AC, Vacquier M, Simon K, et al. (2020) Maternal and Neonatal Outcomes in Hospital-Based Deliveries With Water Obstet Gynecol 136(4). [crossref]
- Cluett ER, Burns E, Cuthbert A (2018) Immersion in water during labour and Cochrane Database Syst Rev 2018(5). [crossref]
- American College of Obstetricians and Gynecologists’Committee on Obstetric Practice.
- Committee Opinion No: 679 (2016) Immersion in Water During Labor and Obstet Gynecol 128(5): e231-e236.
- Colucci-D’Amato L, Speranza L, Volpicelli F (2020) Neurotrophic Factor BDNF, Physiological Functions and Therapeutic Potential in Depression, Neurodegeneration and Brain Cancer. Int J Mol Sci 21(20):7777. [crossref]
- Chao MV, Rajagopal R, Lee FS (2006) Neurotrophin signalling in health and Clin Sci (Lond) 110(2): 167-173. [crossref]
- Chouthai NS, Sampers J, Desai N, et al. (2003) Changes in neurotrophin levels in umbilicalcord blood from infants with different gestational ages and clinical Pediatr Res 53(6): 965–969. [crossref]
- Miguel PM, Pereira LO, Silveira PP, Meaney MJ (2019) Early environmental influences on the development of children’s brain structure and Dev Med Child Neurol. 61(10): 1127-1133. [crossref]
- Mollamahmutoğlu L, Moraloğlu Ö, Özyer Ş, et (2012) The effects of immersion in water on labor, birth and newborn and comparison with epidural analgesia and conventional vaginal delivery. J Turkish-German Gynecol Assoc 13(1): 45-49. [crossref]
- Chaichian S, Akhlaghi A, Rousta F. et al. (2009) Experience of waterbirth delivery in Arch Iran Med 12(5): 468-471. [crossref]
- Hetman M, Xia Z (2000) Signaling pathways mediating anti-apoptotic action of Acta Neurobiol Exp. (Wars)60(4): 531–545. [crossref]
- Carvalho IM, Coelho PB, Costa PC, Marques CS, Oliveira RS, et (2015) Current Neurogenic and Neuroprotective Strategies to Prevent and Treat Neurodegenerative and Neuropsychiatric Disorders. Neuromolecular Med 17(4): 404-22. [crossref]
- Moses VC, Rithwick R, Francis SL (2006) Neurotrophin signalling in health and Clinical Sci(lond) 110(2);167–17.[crossref].
- Nelson KB, Grether JK, Croen LA, et (2001) Neuropeptides and neurotrophins in neonatal blood of children with autism or mental retardation. Ann Neurol 49(5): 597–606. [crossref]
- Von Bohlen Und Halbach O, Von Bohlen Und Halbach V (2018) BDNF effects on dendritic spine morphology and hippocampal function. Cell Tissue Res 373(3): 729-741. [crossref]
- Karege F, Schwald M, Cisse M (2002) Postnatal developmental profile of brain- derived neurotrophic factor in rat brain and platelets. Neurosci Lett 328(3): 261-264. [crossref]
- Kodomari I, Wada E, Nakamura S, et (2009) Maternal supply of BDNF to mouse fetal brain through the placenta. Neurochem Int 54(2): 95-98. [crossref]
- Sukhanova Iu A, Sebentsova EA, Khukhareva DD, et (2028) Gender-dependent changes in physical development, BDNF content and GSH redox system in a model of acute neonatal hypoxia in rats. Behav Brain Res 350: 87-98. [crossref]
- Shiyong P, Wenqiang L, Luxian L, et al. (2018) BDNF as a biomarker in diagnosis and evaluation of treatment for schizophrenia and depression. Discov Med 26(143): 127-136. [crossref]
Abbreviations
BDNF: Brain-Derived Neurotrophic Factor; ELISA: Enzyme- Linked ImmunoSorbent Assay; OD: The Optical Density
References