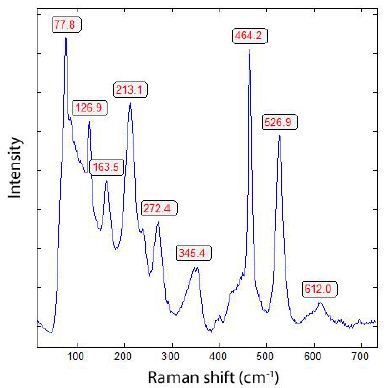
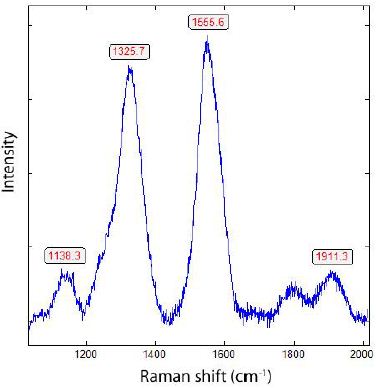
DOI: 10.31038/GEMS.2025734
Abstract
The White River today flows along much of its 270-mile length south along the Colorado Plateau as it has since the Pleistocene. During wetter times, it was a raging river flowing between high mountains and across volcanic places. It contained large side streams, and along its length were lakes and wetlands. It was in the later Pleistocene then, much as it is today, a center of Native American spiritual and ceremonial life. This analysis is based on more than a dozen ethnographic studies conducted over 40 years, compiled from field interpretations from tribally appointed representatives, and subsequently reviewed by them and approved by their tribal governments.
Keywords
Geoheritage, Cultural landscapes, Pleistocene, Cultural heritage, Colorado plateau, Native Americans, Nevada
The Landscape is Alive
Since the beginning of time, the Creator made Nuwuvi peoples at Nuvagantu and here we became attached to this place and the place to us. The land is alive, which means that there is power in all things such as rocks, water, air, plants, animals, and humans. All of these beings are interconnected; they can talk with each other and work together to balance the world (Figure 1).

Figure 1: Mountains, clouds, and desert in the study area (Stoffie, Arnold, and Van Vlack 2022).
The land has eyes and ears. It can talk and knows our thoughts. This makes it in balance and provides guidance. When treated badly, the mountains and everything within them suffers. Misuse of these areas upsets the balance and can cause great harm as well as diminish their power.
The mountains are part of us they call down the rain and make the streams flow. It’s not just a mountain to us, it’s a living thing, living spirit to us, the trees and the rocks and the air, the water, they’re all our cousins, part of us, related to us. So, it’s just not a big mountain there, it’s part of us. We’re related. It’s alive.”
Introduction
Landscapes, including the place of rock writing sites in landscape settings, are common archaeological research topics. Approaches to this large issue range from functionalist analyses, which seek to explain landscapes and site placement in terms of human adaptation to the environment; to symbolic studies seeking their religious and ideological meanings; to heritage management studies focused on better understanding their significance in scientific and/or Indigenous terms, in order to aid in their protection and preservation. In this last case ethnographic studies typically play a key role. Yet in all such studies the natural world is the connective tissue that provides the analytical context. This is recognized in the UNESCO World Heritage List which acknowledges that many such places of outstanding universal heritage value include both cultural and natural resources. One approach to the identification of significant natural landscapes uses the term geoscape to emphasize the regional geological, geomorphological and hydrological components of a landscape, with geosite designating the individual features within that larger setting. We introduce these conceptual terms in this paper and, using the results of dozens of ethnographic studies conducted over the last 40 years (cited below), show how a specific geoscape and many of its geosites formed important spiritual places for Native Americans: the Southern Paiute specifically but also their fellow Numic-speaking Shoshone and Northern Paiute who lived in adjacent areas. We demonstrate, that is, how an understanding of a natural geoscape can be greatly enhanced by attention to its cultural components.
Our region of study is the White River Geoscape, located in southern Nevada, USA, which flows south along a topographic finger of the Colorado Plateau (Figure 2) and ultimately joins the Colorado River on its journey to the Pacific Ocean. This geoscape has spiritual places used in ceremony that occur throughout its 270-mile length. Although different in origin and purpose these spiritual areas are clustered in specific geosites that respond to charismatic topography and geology. Most geosites are physically marked by rock peckings and paintings and are known through oral history to indicate their traditional purposes and meanings. The heritage geosites are functionally interrelated through cultural meanings and ceremonial purposes. Rock writing sites, accordingly, are then best understood not simply in relation to their locational context, nor alone to their specific symbolic meanings and ritual uses, but in relation to other such sites in a surrounding geoscape. We start with a description of the natural physiographic features of the White River Geoscape and how these were formed, and have changed, since the Late Pleistocene Period. The importance of this lengthy history itself reflects the great time depth of the Native American occupation of this region, including their creation of rock writings in western North America at least since the Terminal Pleistocene, if not earlier [1-3]. The cultural background is provided next, emphasizing the metaphysical beliefs that provided Native American understandings of this geoscape and thus influenced their ritual use of certain geosites within it [4]. We then provide descriptions of a series of such geosites and their significance and ceremonial functions before concluding with general observations of Numic uses such localities. Long-term continuity in occupation (cf. Whitley 2019) and ritual practices, supported by previous studies [5] as well as evidence at certain of our geosites, is a sub-text of this discussion.
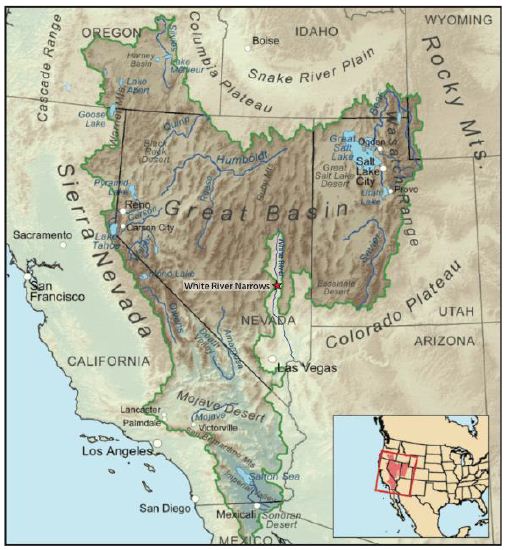
Figure 2: Great Basin Colorado Plateau Map7.
The geosites were selected for this analysis because they illustrate a range of geological and cultural places along the White River geoscape. These geosites were identified and interpreted by Native people in ethnographic studies and through ongoing archaeological studies funded by land management agencies. Potential implications of this analysis and these findings potentially contribute to the White River Geoscape being recognized as a heritage geological and cultural landscape [6] (Figure 2).
Geological and Hydrological Background
Our analysis argues that Native people understand the near surface geological basins and hydrology of the White River Geoscape and have responded culturally to this information. Some understanding of these issues is then essential for interpreting Native heritage geosites and geoscapes. This geoscape has been extensively studied by geologists and hydrologists; our analysis primarily draws on that of Rowley et al. 2016: 168-170 (Figure 3). Glaciers are key to this analysis, given the current earliest dates for the occupation of the Colorado Plateau by Native peoples is about 40,000 YBP [8-10] and that the White River hydrological system was especially impacted by glaciers during the late Pleistocene Epoch, extending into the early Holocene. Glaciers covered many mountain ranges in Nevada, including the Snake Range and Wheeler Peak. The glaciers were part of a time when the region was much wetter and cooler than it is today. The Pleistocene Epoch lasted until about 11,700 years ago. According to Laabs and Munroe [11], glaciers in the Ruby and East Humboldt Ranges had terminal moraines that were created until 22-19 ka YBP and down-valley recessional moraines representing re-advances that occurred about 18-16 ka YBP. In the South Snake and Deep Creek Ranges near the Nevada-Utah border, terminal moraines were created until 20-19 ka YBP. Numerical modeling of glacial mass balance and ice flow in the Ruby, East Humboldt, and South Snake Ranges suggests that the earlier glacial episode was accompanied by temperatures 9-11°C lower than the modern average. During the latter glacial episode, which corresponded in time to pluvial lake high stands in eastern Nevada, temperatures were likely 1-3°C warmer than during the earlier episode with precipitation rates at least 30-50% greater than modern. After down valley moraines were abandoned at 16 ka, glaciers retreated to cirques by 14-12 ka YBP and, in one valley in the East Humboldt Range, persisted until as late as 10 ka YBP. Consistency in the pattern of mountain glaciation throughout the interior Great Basin suggests regional-scale drivers of climate change during the last glaciation and early deglaciation. Native people watched this happen for up to 37,000 years and it consequently became a key feature in their understandings of and cultural response to the environment.
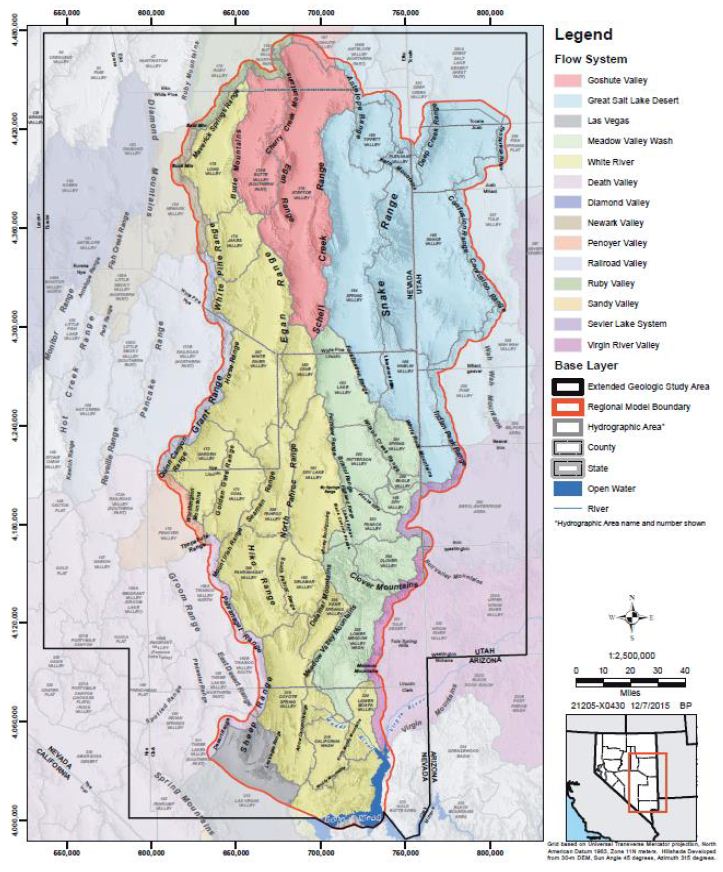
Figure 3: White River Hydrological System in Yellow and Green.
The White River study area is within the Great Basin physiographic province, characterized by north-trending basins and ranges that formed by mostly north-striking, high-angle, basin-range normal faults [12]. Most of the valleys in the Great Basin are topographically closed basins, where surface water flow is restricted to each basin. This is the case in most basins in the study area except many in the White River flow system, which were integrated during wet years of the late Pleistocene, probably largely when lakes in the basins filled and overtopped basin margins. During this time, ancestral White River and Meadow Valley Wash flowed southward to join the Colorado River at present day Lake Mead. Currently, most parts of these drainages are ephemeral. Despite the current intermittent nature of most surface water in the study area, groundwater lies throughout the area at various depths beneath the surface [12]. As elsewhere in the Great Basin, the groundwater occurs in aquifers within and between the basins, and it flows through these aquifers to topographically and hydrologically lower head areas of groundwater discharge. Depending on the regional hydraulic gradient, when one hydrographic area (basin) is hydraulically connected to an adjacent basin, with a flow path that passes beneath topographic divides and the groundwater in both flows toward a common low discharge area, a groundwater flow system is defined. When such a flow system contains many closed or integrated topographic basins, it is called a regional groundwater flow system. The White River flow system (yellow) in Figure 3, is called the Colorado Flow System. The Meadow Valley flow system (colored green) was considered a subset of the Colorado flow system and, therefore, considered part of the White River system (Rowley et al. 2016). The study area (red line in Figure 3) includes the entire White River flow system and the west part of the Great Salt Lake Desert flow system (blue).
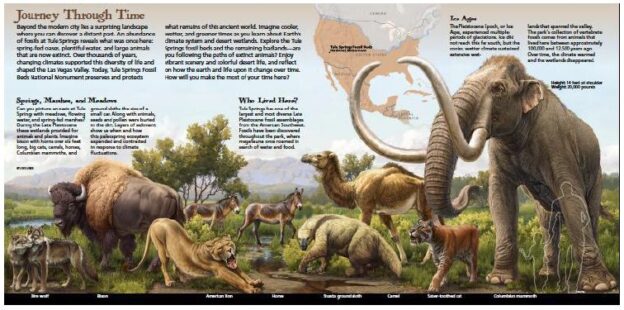
Parts of adjacent flow systems are included within the study area because their basins may be in hydraulic connection with those of the White River and Great Salt Lake Desert flow systems. In other words, the study area was defined by geological and hydrological researchers because of potential hydraulic continuity or discontinuity between basins owing to geologic influences. But this study area also corresponds to a culturally central Native American heritage geoscape. The Las Vegas River drains a relatively small but extensive hydrological system that flows into the Colorado River. The hydro system is composed of high peaks and massifs such as the Sheep Mountains to the north (labeled Las Vegas and colored grey in Figure 3) and the Spring Mountains to the south (Figure 4). The Las Vegas River supported massive wetlands and small lakes that attracted many Pleistocene and Holocene animals and was the home of Native people. Because of these wetlands, extensive fossil deposits involving many animals were created, some of which are preserved in Tule Spring Fossil Beds National Monument (TUSK). Identified fossils from the Las Vegas River hydrological system and illustrated by TUSK are in Figure 5.
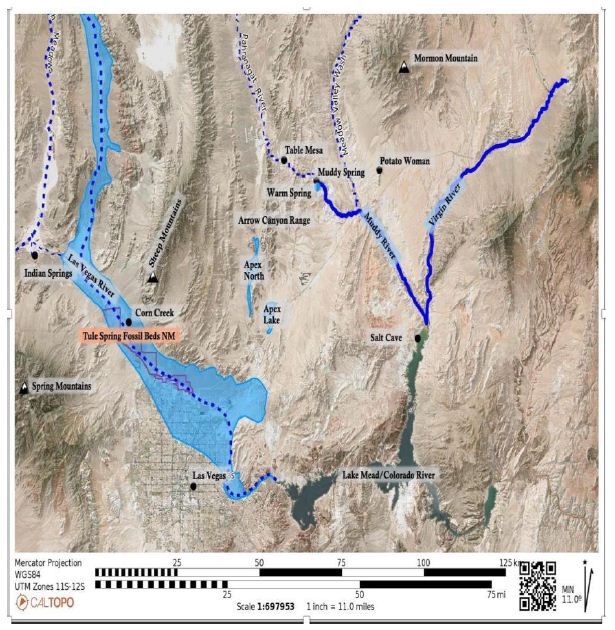
Figure 4: Lower White River and Connection With Las Vegas River Hydrological System in Dark Blue.

Figure 5: Pleistocene Mammals Found at Tule Spring Fossil Beds National Monument [13].
Similar wetlands existed during this period at the southern end of the Arrow Canyon Range in the Apex Playas (see Figure 4). Fossil deposits from this period also are found across the Colorado Plateau near Tuba City, Arizona, and on the Zuni Indian Reservation at Black Rock on the Little Colorado River [14]. New scientific studies document other New Mexico deposits on the Rio Puerco [10] and at White Sands National Monument, where the 22,000-year-old Native Americans and Pleistocene mammals’ relationships are officially celebrated by the National Park Service (NPS) [8] (Figure 6).

Figure 6: Megafauna and Native People [13].
The mutual co-existence of Native Americans and Pleistocene megafauna are a critical component of our understanding of the White River Geoscape. These experiences during this period established both their understanding of this complex functionally integrated river- based ecosystem and its ecology (geoscape) and ceremonial places at especially spiritual locations along the White River (geosites).
Cultural Background
To understand our cultural analysis, there are five essential points that must be discussed. These are (1) Time of Occupation, (2) Analytical Concepts, (3) the Living Universe, (4) Place, Space, and Landscape, and (5) Cultural Affiliation. The linguistic term Numic is used to refer to the aboriginal people of this area as determined by the U.S. Indian Claims Commission. The U.S. federal government specifies the term aboriginal people as referring to those Native tribes (ethnic groups) who occupied a portion of U. S. territory when it was acquired by the U. S. government. For the White River Geoscape this was in 1848 after the Treaty of Guadalupe Hidalgo with Mexico [15]. The term “Traditional Peoples” is used by the federal government for a time before that and the federal legal term “Time Immemorial” is defined by the people themselves as when they arrived in a location.
Time of Occupation
According to hundreds of ethnographic interviews (See Table 1), the White River hydrological system and its component features have been culturally important places for all of the participating Native American representatives since Time Immemorial or Creation. Both ancient Clovis and Folsom spear points have been found in the area, but they do not define the earliest occupation. Recent geoarchaeological studies have documented the presence of Native people in the even broader Colorado Plateau and Great Basin of the Southwest United States. Therefore, the broadest temporal frame for this heritage analysis is operationally defined as the late Pleistocene, which occurred between 128,000 and 11,700 YBP, and the Holocene from 11,700 YBP to modern times. Scientific studies document Native American occupation by at least 37,000 YBP with geoarchaeology dates of 23,000 to 21,000 BP at White Sands, New Mexico and 38,900 BP to 36,250 BP at the Hartley locality, a mammoth kill site situated near the Rio Puerco, New Mexico [8-10]. These geoscience dates indicate that Native Americans experienced this environment as both a massive wetland filled with lakes, rivers, and swamps and later as an arid desert with small streams and artesian springs [16]. Time keeping and celestial marking would have been adjusted to understand climate changes [17] and massive geological changes would be remembered with oral history during these periods [18-20].
Table 1: Foundation ethnographic studies.
| |
Year
|
Ethnographic Study |
Authors |
Tribes Participating
|
| 1 |
1983 |
Nuvagantu: Nevada Indians Comment on the Intermountain Power Project. (Reprinted 1983) |
Stoffie and Dobyns 1983 [36] |
5
|
| 2 |
1982 |
Puaxant Tuvip: Utah Indians Comment on the Intermountain Power Project, Utah Section of Intermountain Adelanto Bipole I Proposal |
Stoffie, Evans and Dobyns 1982 [37] |
3
|
| 3 |
1983 |
Nungwu Uakapi: Southern Paiute Indians Comment on the Intermountain Power Project. |
Stoffie, Evans Dobyns [38] |
4
|
| 4 |
1999 |
DOE Intermodal Transportation of Low-Level Radioactive Waste (Reprinted 2013) |
AITC 1999 [39] |
29
|
| 5 |
2002 |
East of Nellis: Cultural Landscapes of the Sheep and Pahranagat Mountain Ranges |
Stoffie, Toupal, and Zedeño 2002 [40] |
17
|
| 6 |
2003 |
Confronting the Angry Rock: American Indian Situated Risk from Radioactivity |
Stoffie and Arnold 2003 [41] |
26
|
| 7 |
2004 |
Landscapes of the Ghost Dance: Cartography of Numic Ritual |
Carroll, Zedeño, and Stoffie 2004 [42] |
5
|
| 8 |
2007 |
Place, Performance, and Social Memory in the 1890s Ghost Dance |
Carroll 2007 [43] |
5
|
| 9 |
2008 |
American Indians and the Old Spanish Trail |
Stoffie et al. 2008 [44] |
7
|
| 10 |
2011 |
Solar PEIS Delamar Valley |
Stoffie et al. 2011a [35] |
3
|
| 11 |
2011 |
Solar PEIS Dry Lake |
Stoffie et al. 2011b [45] |
1
|
| 12 |
2011 |
Oral Histories and Place Making of the Mormon Mountains Among the Southern Paiutes and Western Shoshone |
Ruuska et al. 2011 [33] |
11
|
| 13 |
2015 |
Social Investment in Regions of Refuge: Survival Strategies Among the Southern Paiute of Southern Nevada |
Ruuska 2015 [46] |
11
|
| 14 |
2022 |
Landscape Is Alive: Nuwuvi Pilgrimage and Power Places in Nevada |
Stoffie, Arnold, and Van Vlack 2022 [47] |
18
|
| Total Tribes in Participation |
145
|
Analytical Concepts
This heritage analysis builds on the burgeoning academic literature that has responded to the United Nations’ call for the identification of geological places and landscapes as a kind of cultural heritage deserving preservation [21,22]. Geologists have argued that certain geological and hydrological places should be preserved for the benefit of science and general understanding of the Earth. Initially such places were listed by their host nations and the United Nations. Eventually the human values attached with these places became a component of their heritage identification and preservation [6]. The ICUN and the WCPA have a Geoheritage Specialist Group that has documented the need for such new heritage preservation approaches [23]. This need is illustrated by the 20 published peer reviewed papers in the Special Issue of the journal Land entitled Geoparks, Geotrails, and Geotourism – Linking Geology, Geoheritages, and Geoeducation edited by Brocx and Semenluk. This Special Issue included studies from Europe, Australia, USA, Latin America, and Asia. Subsequently, published articles on this topic are illustrated by Geoheritage and Cultural Heritage Overview of the Toba Caldera Geosites, North Sumatra, Indonesia [24]. These studies [25] document a range of complexities involved in preserving, interpreting, and managing complex geoheritage. The Geology profession through the International Commission on Geoheritage [23] has responded by identifying significant geosites around the world using both their scientific and human significance values as criteria. The current analysis draws on these new geoheritage concepts and approaches for the identification, interpretation, and management of Earth Places because the structure and function of these cultural places significantly depends on the geology and topography of the lands involved. All Earth Places involved in this analysis are topographically and geologically special.
The Living Universe
The ways in which societies relate to their environments are grounded in their metaphysical beliefs, including their epistemologies and ontologies. In Southern Paiute society, relationships and deep connections with their environment were formed during Creation. Southern Paiutes maintain that the Creator gave them the responsibility to manage their environment to promote its growth and sustainability. They have developed numerous strategies and activities that increase biodiversity and biocomplexity throughout their homeland. The basic tenets of Southern Paiute epistemology help forge the relationship they have with their environment. To Southern Paiutes, the universe is alive, and everything is interconnected through all types of relations; this is what anthropologist Roy Rappaport [26] calls “the ultimate sacred postulate.” The universe is alive in the same way that humans are alive and it possesses most of the same anthropomorphic characteristics as well. The universe has discrete physical components such as power and elements. It is a living system. This concept of the living universe is so fundamental that any discussion of Southern Paiute culture cannot occur without it.
As explained by Liljeblad [27], power to the Numic speaking peoples is everywhere and is “a source of individual competence, mental and physical ability, health, and success.” Power is referred to as Puha and is a belief central to Paiute culture as well as many different tribes throughout the western United States [28,29]. Other Numic speaking people, such as Western Shoshone, Owens Valley Paiutes, Northern Paiutes and Utes, have similar words in their languages [1]. The concept of power is not limited to the Great Basin and Colorado Plateau peoples; it is also a core epistemological principle in the cultures of nearby Upland and Colorado River Yuman-speaking peoples such as the Mojave, Hualapai, and Havasupai. According to Numic beliefs, Puha is derived from Creation and permeates the universe, and its distribution resembles a spider web. Sometimes it is like a thin scattering; at other times, it occurs in places where there are clusters of life in definite concentrations with currents. Puha exists throughout the universe but varies in intensity from person to person, place to place, element to element, and object to object. This is similar to how strength differs among humans. Puha can also vary in what it can be used for, which determines the tasks certain elements (air, water, rocks, plants, animals) can accomplish. Puha is networked; it connects, disconnects, and reconnects elements in different ways. This connectivity occurs because of the will of the elements that have the power. Puha is present in and can move between the three levels of the universe: the upper level—where powerful anthropomorphic beings live, the middle level—where people live now, and the lower level— where extraordinary beings with reptilian or distorted humanoid appearances live [29,30].
Place, Space, and Landscape
Cultural landscapes develop from a people’s historical memory and these understandings of the land are shared and transferred over generations. Throughout traditional Southern Paiute territory, places are connected through songs, oral history, human relations, ceremony, and both physical and spiritual trails. These connections create synergistic relationships between people, places, and objects. The spaces between places, people, and objects are important components of a cultural landscape. These are the locations of trail networks that provide both physical and spiritual linkages. Trail networks provided people with the most direct links to places, resources, and communities. They facilitated the movement of people to secular places and those associated with pilgrimage. For Numic speaking peoples, trails were and continue to be closely associated with the sacred and the spiritual link that binds places together. Importantly, the spaces between also allow for the flow of Puha back and forth across the landscape.
Cultural Affiliation
All the participating tribes and pueblos consulted in our ethnographic studies have an ongoing cultural association with the White River Geoscape. They have stipulated that this is a culturally and functionally integrated area that is interlaced with pilgrimage trails and has been so since Time Immemorial. They all stipulate that they are from this region, even if they live elsewhere today, and that they continue to keep the region and their connections with it alive in their ceremonies and prayers. They maintain that this is a living ceremonial area that was established at Creation for the use of all Native peoples. Like the people themselves, these geological and topographical places remain alive, and all are committed to their original purpose of providing balance to the world.
Methods
This analysis is based on ethnographic and archaeological field research studies conducted in the White River hydrological system, which is understood based on geological and hydrological studies, outlined above. Critical to this analysis are the cultural interpretations of Native American elders who formally participated as appointed tribal representatives in the ethnographic studies and more generally informed the archaeological studies. Two archaeologists who study the White River are coauthors of this essay. Both have extensive interactions with Native peoples and heritage issues [31,32]. The ethnographic studies occurred between 1981 and 2022. All were designed with similar data collection methods, used common data review analysis protocols, and were guided by a professional applied ethnographer. This study design has been refined and approved by federal agencies and Native American tribes for each study [30,33-35]. The foundational ethnographic studies are presented in Table 1 where they are cross tabulated by a short study title, a list of senior authors, and the number of tribes participating in the study. There were 13 ethnographic studies conducted in full or part in the White River Geoscape hydrological system. A total of 145 tribes participated in the studies between 1981 and 2022. All research studies were funded and or legally managed by a federal agency such as the Department of Energy, the US Air Force at Nellis, the National Park Service, and the Bureau of Land Management. Logistical support was provided by the Desert National Wildlife Service. Table 1. This is a table. Tables should be placed in the main text near to the first time they are cited.
Agency funded research is, by definition, focused on the lands being managed by an agency or being impacted by a potential agency action. All of our ethnographic studies had such a focus, but some study areas were linear. Southern California Edison, a major public utility, for example, funded a multi-year study for a 500KV powerline that crossed 450 miles of Utah, Nevada, and California. The Intermountain Power Project (IPP) involved a narrow area of potential effect that could be widened when critical cultural resources were nearby that could be impacted. Similarly, the NPS Trails Division funded studies of impacts on Native American cultural resources along the Old Spanish Trail from New Mexico, Colorado, Utah, Nevada, and California. These studies were designed, managed, funded, and reviewed by the involved agency land managers, the project proponents, and the participating Native American tribes. Tribal participation was required by the US National Environmental Policy Act. This specified the inclusion of tribal participation in environmental impact assessments, including the independent selection of tribal cultural experts, and tribal review of and approval of study findings regarding their cultural impacts. Our White River studies involved a total of 145 Native American tribal governments and their appointed cultural representatives. Most tribes were involved in these studies multiple times. All studies were designed to improve land managers’ understanding of involved Native American cultural resources in order to enhance their preservation, in part by effective public communication of their existence and their cultural heritage importance to Native Americans [48]. As a result of decades of interactions in ethnographic studies, a relationship was established between ethnographers and the Native American peoples of these lands. Three of the many relationships are illustrated between Richard Stoffie, Dan Bulletts, and Herbert Meyers at work on the IPP in Arrow Canyon (Figure 7). A later photo from 2011 is of Herbert’s son Calvin Meyers, who worked for decades on cultural studies representing the Moapa Tribe (Figures 7 and 8). The Bulletts family, beginning in 1972, and the Meyers family, beginning in 1981, have been instrumental in studies that accurately recorded cultural areas without causing the cultural resources to be overly discussed with outsiders.

Figure 7: IPP Dan Bulletts, Rich Stoffie and Herbert Meyers [36].

Figure 8: Calvin Meyers, Moapa Tribal Representative at East Mormon Mountain Solar PEIS [45].
Tribes insisted as a condition of participation in these studies that they and their representatives only reveal enough traditional information to protect the resources and places but not so much that the resources and heritage of the areas would be harmed. All studies were reviewed and approved by the representatives involved, their cultural departments, and their tribal governments. The most dramatic example of the tribal response to the studies has been the formation of the Consolidated Group of Tribes and Organizations (CGTO) which has been involved in cultural studies with agencies since the 1980s [30,36,49]. Richard Arnold is the spokesperson for the CGTO, and he is the Chairperson of the Pahrump Paiute Tribe and a coauthor of this manuscript.
Native Heritage Geosites Along the White River Geoscape
Spiritual places, known ethnographically as Native American heritage geosites, occur from the headwaters of the White River in the Duckwater, Current Mountains and surrounding ranges to the east (Figure 9), southward along the hydrological system to the Virgin River. The headwater of the White River is primarily the large massif of peaks and highlands that includes Duckwater Peak. To the west of this massif is the reservation of the Duckwater Shoshone Tribe which is committed to heritage preservation and a regular participant in White River studies and the CGTO. A symbol of the tribe includes respect for the natural environment. According to the tribal web site [50], the Tribal Shield represents Shoshone history, “In Shoshone myths and Legends, the shield addresses the sky being the bluest ever seen. The sun rises over the mountain know as Esha Goyoi (Wolf Peak). The shield with the trade cloth and feathers trailing, honors our past, protects our heritage.”

Figure 9: One of many highland springs protected by the Shoshone people and their government [50].
The headwaters of the White River are hydrologically massive and contained glaciers during much of the Pleistocene (Figure 10). Today the waters of this area are used for extensive irrigated farming and block in places to form lakes.
Figure 10: Mountain Headwaters of the White River.
Research documents more than a thousand culturally significant geosites within the White River Geoscape. Many of these places contain rock peckings and paintings. While it is impossible to discuss all the places within this landscape, we highlight 15 geosites to convey the cultural complexity and their diversity within the White River Geoscape (Figure 11). Given that all of the geosites have been the focus of previous ethnographic and archaeological studies, fuller analysis is available in those technical reports and published articles.
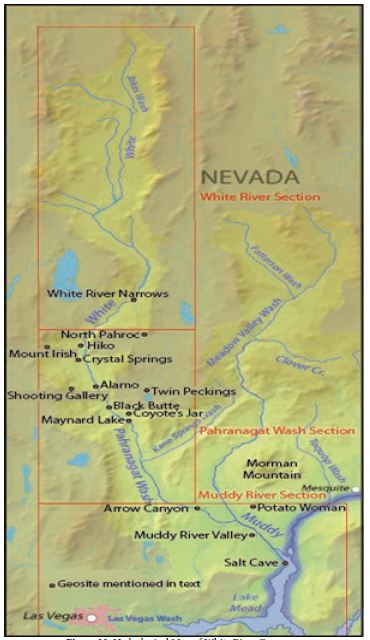
Figure 11: Hydrological Map of White River Geoscape.
It is important to understand that the hydrology of the White River Geoscape has changed dramatically in the roughly 40,000 years of presumed Native American occupation (see regional dates above). From some point in the Pleistocene the high mountains at the headwaters were covered with glaciers. Streams flowing from the mountains and glaciers supplied the major flow of the White River and the sister Meadow Valley River. Wetlands and lakes formed in low gradient areas but especially in the Maynard Lake area where a natural dam was present. During this time period Native Americans would have increasingly occupied the lower portions of the hydrological system and used the edges of wetlands for gathering and hunting. As the Pleistocene glaciers shrank and were replaced with plentiful rain and snow Native Americans would have used the abundant fauna and flora of these hydrological systems and, over thousands of years, culturally co-adapted to the increasingly dry periods of the Holocene. Our primary regional understanding of these shifts in climate, fauna, and human occupation derives from the fossil beds of the Las Vegas River at the southern end of the White River system.
Site by Site Analysis
The following is an analysis of selected geosites identified by archaeological and ethnographic investigations along the White River Geoscape. This analysis is divided by three downriver reaches, which is the appropriate term for describing a functional portion of a river.
Geosite One: White River Narrows
The White River Narrows (WRN) geosite is located on US 318, about 20 miles north of US 93 at Crystal Springs. The geosite is designated as the White River Narrows Archaeological District (Figure 12), which, together with the larger Basin and Range National Monument within which it falls, is managed by the Bureau of Land Management. US Highway 318 runs through most of the meandering WRN. The WRN is a seven-kilometer-long winding canyon where the White River has cut through resistant bands of indurated tuff, roughly between 2.5 million and 11,700 years ago. These resistant layers are part of the southeast to northeast trending Seaman Range. Except for rare flooding episodes during heavy downpours, the White River currently has no surface water within the WRN. Roughly 138 kilometers north of the WRN the headwaters of the White River include the White Pine Range near Preston and Ward Mountain between Ruth and Ely. After passing through the WRN and the Little WRN farther south, the White River changes its name into the Pahranagat Wash where it runs through the Pahranagat Valley, which includes the small communities of Hiko and Alamo. The Pahranagat Valley changes into the Muddy River Valley at Arrow Canyon, from whence it first joins the Virgin River and then ultimately empties into the Colorado River farther to the south. The WRN clearly falls within the same hydrological system as the other sites in this analysis. Located within the predominantly wide White River corridor, the WRN forms a narrow bottleneck through which people must pass through when they travel between central Nevada to the north and the Colorado River valley to the south.
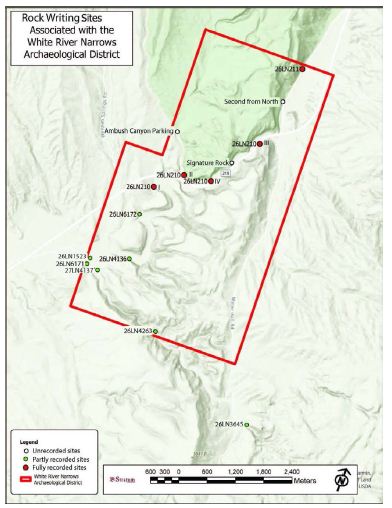
Figure 12: Map of the White River Narrows Showing the Main and Side Canyons, Map Approved by the Bureau of Land Management [31].
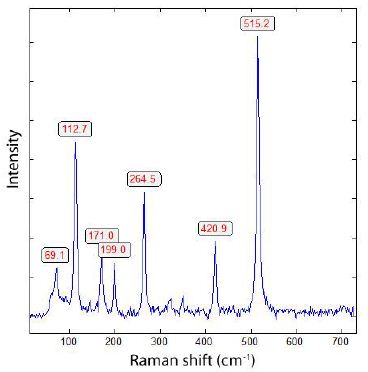
The WRN geosite contains 15 known rock writing sites, two of which contain only red pictographs and the rest comprising predominantly petroglyphs with a few red ocher smears. Of these 15 sites, two occur against east-facing cliffs immediately north of the canyon, nine against cliffs within the main canyon, and three against cliffs in the side canyons. Based on the 2,281 motifs already recorded at five of the sites [31,51], it is estimated that between 4,000 to 6,000 motifs occur at all 15 sites within the WRN geosite.
The American Indian Transportation Committee (AITC) [39] interpreted the WRN geosite as a point of comparison with two Storied Rocks sites (the AITC term for Black Butte and Red Tail Hawk geosites) in the Pahranagat Valley to the south. The red paint represents the presence of a spiritual place and the conduct of ceremonies by Indian people. The power of the place derives in part from having a river narrowed by powerful resistant rocks. Ceremonies would have been held near water. The site is reminiscent of the two Pahranagat sites in that they all are at points along a winding water course that is constricted by rock cliffs. The side canyon pecking and painted sites are places where Indian people would have prepared themselves before going into the main canyon narrows along the White River. As part of the Lincoln County Archaeological Initiative, archaeologists have conducted a series of recordings within the WRN geosite, including accurate mapping of rock markings [31,51]. This careful and thorough digital recording of individual motifs and their direct overlaps with other motifs allowed the reconstruction of a relative sequence of motif applications at the sites. Among the findings of the motif overlap study was the observation that the latest applications were done to enhance, and in a few instances obliterate, some of the earliest motifs. This shows that regardless of considerable age differences between the earliest and latest motifs, those that came later clearly acknowledged and interacted with much earlier applications. It also demonstrates continuity in site use over time, emphasizing the time-depth of this geosite. Long horizontal lines, shorter vertical lines, and knotted strings at the Northern Site, immediately outside the WRN, carefully cover and connect distant motifs, suggesting transcendent Puha connections between spatially and chronologically distant motifs (Figure 13).

Figure 13: Distant Panels and Motifs from Different Periods are Connected by Long Horizontal Lines, Shorter Vertical Lines, and Knotted Strings at the Northern Site [31].
The earliest pecked motifs within the WRN have also been observed at two Mount Irish sites. These motifs are predominantly grid shaped with occasional spirals. Human-looking feet, tracks, meanders, bighorn sheep, human-looking figures, and knotted strings comprise most of the precontact motifs at the WRN sites. The most recent motifs at the WRN sites include fine lined incisions and painted lines, stick-figure bighorn sheep, and re-engraved older motifs. The most recent motifs match the brightness of graffiti within the same mineral salt accretions, suggesting their relatively recent application, likely late nineteenth-century and even some twentieth century additions. Figure 14 below includes computer highlighted peckings mixed with natural colors. Especially important for this analysis are the two Water Babies with pecked vulvas. Water Babies are prominent spirit helpers and powerful actors throughout Numic lands, but they appear to be especially strongly associated with the White River geoscape.

Figure 14: High Resolution of Water Babies with Vulva Peckings (top right).
Also recorded were the acoustic relationships between 10 rock writing sites within the WRN geosite [52]. These acoustic studies continue Waller’s interest in the functional interrelationship of sound and rock markings [53,54]. It is a key issue documenting the interrelationship of geosites and their components. Waller documents that songs, music, or drums performed at most of these locations can be heard clearly at neighboring locations, thus documenting another kind of potential ceremonial relationship between the components of this geosite. The acoustic interaction between separate rock writing sites within the WRN is consistent with Puha, which flows between places in a connected landscape [32,55]. Native representatives talked about the enhanced acoustic properties of the location during our ethnographic interviews at the site (Figures 15 and 16).
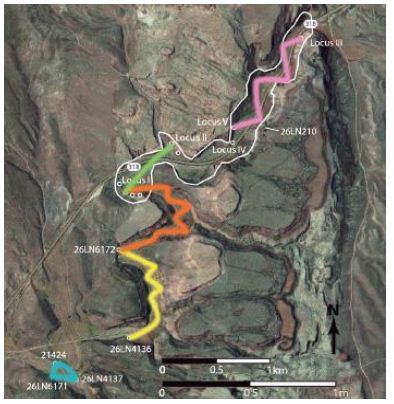
Figure 15: Map of Measured Acoustic Interactions between WRN Sites [52].

Figure 16: The Amphitheater Site Near the Center of the White River Narrows, a Locale with Enhanced Acoustic Properties and Connections with Neighboring Sites [52].
A serrated corner edge of a panel at the Northern Site, immediately north of the WRN, could have been rubbed with a straight stick to create a rasping noise (according to Columbia Plateau Native Americans, Phillip Cash Cash and Willie Selam, commenting on serrated edges along Columbia River panels, personal communication with Loubser in 2002), being additional evidence for sound production at these geosites (Figure 17).

Figure 17: Panel with serrated edge to produce rasping sound [31].
Various visual and acoustic characteristics of the rock writing sites within the WRN are suggestive of Puha. The self-similar expressions of Puha are expressed at different scales within the WRN geosite, ranging from the microcosm of individual motifs, through the macrocosms of the wider landscape to the encompassing White River Geoscape.
Geosite Two: North Pahroc Big Rock
The North Pahroc Big Rock geosite (Figure 18) includes at least two rock writing locales. The first is a single, large rock writing panel with a number of bighorns, anthropomorphs, and other motifs (Figure 19). At least two of the bighorns lack front legs and a pecked swirl surrounds a vug/gas bubble hole in the rock’s surface. A second, smaller nearby locale consists of a natural arch under a large boulder with rock paintings (Figure 20). These include a natural vug that is surrounded by a series of short red lines, creating a starburst like pattern.

Figure 18: North Pahroc Big Rock Geosite.

Figure 19: Large Boulder with Peckings.

Figure 20: Big Rock Geosite with Activity Area Underneath and Red Paint Around Portal Hole.
Bighorns commonly served as the spirit helper for rain shamans (Whitley 1994). There are also several bighorns without legs at the White River Narrows geosite, while a few bighorn motif eyes are centered on vugs, and certain lines start or terminate at cracks. As documented by Van Vlack [56], ritual pilgrims sometimes inserted their fingers into vugs incorporated into rock writing motifs to transition into the sacred realm. At the Amphitheater site in the center of the WRN, diagnostic bighorn horn racks are pecked along the top edges of long horizontal knotted strings, creating the impression that the rest of the bighorns are hidden behind the knotted strings and the rock surface. Knotted strings were used by messengers, sent to outlying villages, to document the number of days until a communal ritual gathering [47]. At Mount Irish (Geosite 5) a few of the larger bighorns had their legs added to their torsos later. Certain Water Baby figures have arms, legs, and penises that were added later too. Water Baby was an important spirit helper that was especially associated with the Pahranagat Valley area and is depicted in a specific, identifiable fashion [20,32,57]. Isolated vugs at Mount Irish are framed by tightly pecked circles. All of these rock writing motifs and depictive conventions illustrate the belief that the rock face is the permeable veil between the natural and sacred realms and that spirits and shamans move back and forth, through this rock face, often through cracks or vugs [58]. That certain of the bighorns lack front legs suggests that they were in the process of transitioning into the sacred realm. Because the actions of a shaman and their spirit helper were indistinguishable, bighorn and other animal motifs themselves can be understood as shamans transformed into their supernatural power form.
While not all gatherer-hunter beliefs and ritual practices, let alone religions, were universal [4], some beliefs were widely shared. The San (Bushmen) who are gatherers and hunters in southern Africa similarly painted certain eland (the largest and most docile antelope in Africa, a spirit helper among many medicine people and/or a transformed medicine person) without legs or as if they emerge from cracks in the rock. Long painted serpentine lines disappear into tiny holes in the rock surface only to re-appear from tiny holes or cracks a few meters along. The landscape/inter site level of these lines can be seen where they extend to the edge of a rock surface only to re-appear on another surface at a site miles away (perhaps indicating a long-distance connection between geosites). These lines are !num, the San Bushmen equivalent of the concept of Puha among the Numic speaking peoples [59]. It can be argued that Native Americans did the same as the San, depicting spirit beings as hovering betwixt-and-between the spirit world behind the rock surface and the physical world on the physical observer’s side of the rock.
Geosite Three: Traditional farming villages from Hiko to Alamo
Hiko is a historic massacre site located near the contemporary town of Hiko, Nevada, along US 318 and about 5 miles north of Crystal Springs on US 93 [60]. The town of Hiko, the surrounding ranches, and the massacre site are defined as the geosite identified in this study. The massacre site itself is located where the western Native American trail out of Hiko enters a pass through the mountains towards Mount Irish. The Hiko geosite is defined as where two local communities of Indian people experienced hostile relationships with newcomer Euro- American settlers [61]. One farming community was at Alamo and the other was at Hiko, which is used as the point of reference for this discussion [62]. These hostilities resulted in the killing of many members of both Native American farming communities in one incident while later both Shoshone and Paiutes killed at Quinn Canyon [61,63]. The Indian farming communities were surrounded by the EuroAmerican newcomers and then massacred. The massacre was documented at the time by a local newspaper in Pioche, Nevada, and more recently by oral history with the families of longtime residents recorded by McCracken. These oral histories document the event itself from a EuoAmerican point of view; specifically, that the Indians had to be killed because they were stealing horses. Native oral histories suggest the massacre were due to EuroAmericans wanting their irrigated farms.
These Native American oral history interviews conducted with both Shoshone and Paiute elders documented that people who escaped ran up the trail to Mt. Irish and sought spiritual protection in the area of rock peckings [39,41]. Later the local ranchers attacked them again and the survivors went west to the Quinn Canyon Range where they again sought refuge but this time in a community of Shoshone people. Soon a force of ranchers and U.S. military calvery who were called to put down the Indian uprising attacked this community. Only a few survived. A cradle board with the skeletal remains of a child was found in later years stuck into a rock crevasse on Mt. Irish along the trail from the massacre site. The cradle board was subsequently removed by unknown persons. The area contains unsettled spirits [39,41]. These can potentially be further disturbed by truck accidents, parking, and traffic. The area is extremely sensitive to Native Americans today. It is like driving through a place that has ongoing spiritual turmoil. The massacre left the Paiute victims without a burial, so they never made their passage to the other side. Native Americans know that the local ranchers have collected some of the artifacts and bones from the massacre site. These artifacts and bones will have to be buried with a proper funeral to begin to restore balance to the area.
A local business owner recounted to an author of this paper that his dad visited a remnant Paiute community near Crystal Springs in Crystal Wash. Paiute elders told his dad of a time when Paiutes could still paddle down the White River and Pahranagat Wash to the Colorado River, all the way from north of Lund. Among other occupations, the business owner’s dad was a silver and gold prospector in the Mount Irish area around the abandoned Logan City and a descendant of the first Mormon settlers in the valley. The business owner was glad to hear that the archaeology team removed his dad’s 1940 initials from a petroglyph boulder at Paiute Rock, Mount Irish. After 1920 two Native American settlements existed in the area, living on fish caught in a local lake, rabbit hunting, and some corn farming. Their former irrigated agriculture fields were, by this time, controlled and used by EuroAmerican settlers (McCracken ed. 1991). These oral accounts document the return of Paiutes to Crystal Springs/Alamo/ Hiko area in the early 1900s despite having been forcibly relocated by the US government to the Moapa Reservation a generation earlier. This return to a homeland is common among relocated Native Americans, reflecting a strong heritage attachment to the geoscape.
Geosite Four: Artesian Springs
The Crystal Springs Geosite Four is located on US 93, at the junction with US 318. The site consists of a series of major (slightly) warm springs. At this site, there are many trees and Indian foods like watercress. A red tail hawk was observed at the site as well as a number of other types of birds. Water babies, noted as important spirit helpers above, are in the springs and in the water system. Hot springs were said to be created by their fires [64]. They can travel up and down throughout the hydrological system [20]. The water babies in this area have been influenced by the Hiko massacre. As a result, there are more water babies in the local hydrological system, and they are angry because of the Indian massacre. It is possible that the water babies are now holding some of the spirits from the massacred people, especially the children. The parking areas near the springs are especially dangerous at night and should not be used (see Figures 21 and 22).

Figure 21: Sacred Artesian Ash and Crystal Springs.

Figure 22: Crystal Spring.
Geosite Five: Mount Irish
The Mount Irish geosite is on a slope southeast of Mount Irish where a dip in the topography creates a natural location for a trail from the White River below to the upper reaches of Mount Irish (Figure 23). The surface of the land in this geosite is covered with exposed but largely small boulders and rock outcrops. There are hundreds, probably thousands, of Native American rock markings on these stone features. Viewed from the prominent trail through the mountain pass, the Mount Irish rock pecking area is in the foreground (Figure 23).

Figure 23: Mount Irish in the Background as seen from Rock Writings in the Foreground [31].
Whitley’s 2015 analysis [32] of this area and its cultural features maintains that the glyphs (Figure 24) have a variety of ritual functions, and the rock markings reflect places where these rituals occurred.

Figure 24: Shooting Gallery Possible Vision Quest Image [32].
Other images are similar to ones identified as spirit helpers (Figure 25). Bighorn sheep images instead played an important spiritual role in Numic society as the spirit helpers specifically of rain shamans [32,65]. A series of accounts amplify the association between the rain shaman and the bighorn. According to Kelly’s [66] ethnographic data, a mountain-sheep singer, that is a shaman, always dreamed of rain, a bull-roarer, and a quail tufted cap of mountain-sheep hide. Wooden bullroarers were sometimes toys, but those of mountain sheep horns were for rainmaking.

Figure 25: Bighorn Sheep Motif Possible Spirit Helpers [32].
Geosite Six Shooting Gallery
The Geosite Six is called the Shooting Gallery (Figure 26). It appears to be a massive archaeological complex, possibly bigger than that of Mount Irish to the north, and arguably the largest known geosite in the White River catchment. There are small surface scatters of lithics, ceramics, and dark organic soils, which occur next to and among boulders with petroglyphs.
Figure 26: Map of Badger Mountain and the Shooting Gallery.
There is a diversity of places and pecking in the area. Figure 26 shows rock walls or cairns constructed along the trail to the mountains, probably Badger Mountain. Based on ethnographic interviews, these walls were likely constructed to mark the locations where supplicants received spirit helpers, which were then depicted in the nearby rock writings [32] (See Figures 27-29). These rock walls are on the edge of a ridge that overlooks the Shooting Gallery geosite.

Figure 27: Rock Wall in Shooting Gallery Area [31].

Figure 28: Puha Naax Mountain Sheep (“electric bighorn”) with Multiple Lines Radiating from its Head [51].

Figure 29: Transformed Mountain Sheep Along the Primary Trail [32].
The rock walls are southeast of the geosite. Similar but much smaller and U-shaped walls overlook at least three rock writing geosites in the WRN. The primary Shooting Gallery Wall has tiny upright stones implanted at more-or- less regular intervals along its course. One small U-shaped stone walled enclosure above the Northern Site at WRN also has a small upright stone in it. These are not hunting blinds but more likely places for vision questing, where the questers sit in a crouched/ fetal position. Studies of the Mount Irish area have not documented such walls but instead there are big natural hollows in the boulders above rock writings that may have served the sane purpose. Shooting Gallery is in a basin shaped hollow that is physically and visually separated from the White River Valley to the east by a series of ridges (Figure 27). In a sense its current remoteness reminds one of a “pristine” Shangri La- like location. The Puha Naax (Power Mountain Sheep) (Figure 27) is within the first concentration of petroglyphs and small lithic, ceramic, ground bedrock, and dark midden features and encampments as you walk northwest from the vehicle parking spot. The map in Figure 27 is the estimated locations of the wall in relation to the Puha Naax at the Shooting Gallery Geosite. The wall is on a ridge line above and southwest of a 4-wheel drive vehicle parking spot, overlooking a boulder field with habitation sites and rock writings in the basin shaped valley below, to the northwest. Farther in the background to the northwest is the looming Badger Mountain, while to the northeast is a narrow valley linking the basin with the White River Valley near Alamo.
Note that the Puha Naax that have been identified as when the mountain sheep transforms through a portal [57]. To the right is another mountain sheep with similar transformed feet and below is a buffalo with transformed feet. Petroglyphs with these transformed feet have been described by tribal representatives as these spirit helpers have moved through a portal into the supernatural world. Figures 29 and 30 show more spirit helpers that have transformed by passing through a portal into the supernatural.
Figure 30 has three transformed spirit helpers as indicated by their feet. Additionally, the panel has almost a dozen pecked knotted strings which indicate ceremonial activity and portals. The pecking in the lower left-hand corner of Figure 30 that looks like a series of upside-down arches/rainbows represents the mirrored landscape on the other side of the portal. Mirrored landscapes are inverted and thus the colors move from positive to negative, the poles are reversed, day is night, night is day.

Figure 30: Panel with U-shaped Semi Circles and Knotted Strings (Trail).
Geosite Seven: Black Butte Ceremonial Area
Rock peckings have been placed by Indian people on many of the boulders and cliff faces in this volcanic formation [40,60] (Figures 31 and 32), located in the Pahranagat National Wildlife Refuge. These petroglyphs range from complex panels that are covered with interrelated figures and shapes to peckings on isolated boulders. On top of one prominent butte are a number of high-walled, circular structures (Figure 33). In the original riverbed below are marshes filled with seed grasses. At any given time, according to the ranger, there are 250 bird species in the refuge. The site is on the Pacific Flyway for migratory birds, but it is also the permanent home for many species. A red tail hawk nest is located in a large cottonwood (Populus spp.) just below the butte. Mammals in the area include coyotes (Canis latrans), bobcats (Felis rufus), mountain lions (Felis concolor), muskrats (Ondatra zibethicus), and deer (Odocoileus hemionus), some of whom sleep at night on a grassy area just below one of the large cliff-face panels high on the butte. Indian tobacco grows out of the cliff face below many of the panels. Pahranagat Valley is the place where the Pahranagat/Moapa people were created. The Native American representatives in multiple studies interpreted the site as a place to seek knowledge and power, conduct ceremony, and communicate with spiritual beings (Figure 34). The site contains medicines, food, and drink, but its power caused it to be exclusively used for ceremony. Living, farming, hunting, plant collecting, and social gathering areas were located elsewhere in the valley.

Figure 31: Extensive Wetland Surrounding Black Butte.

Figure 32: Many Peckings Cover Black Butte.

Figure 33: Stone structures for visiting spiritual people on top of Black Butte.
Native representatives confirm in multiple studies that Black Butte is a place where shamans acquire spirit helpers. These are mostly rain making helpers given that most spirit helper peckings are of water babies (Figure 34).

Figure 34: Transformed Shaman and Water Baby.
The Black Butte geosite is connected spiritually, physically, and via common ceremonial activities to other places in the southern portion of the valley such as Maynard Lake, Lower Pahranagat pecking panels, and Arrow Canyon, as well as connected to the north to Crystal Springs and to the traditional farming communities that were located there. It is a ceremonial center or hub of ritual activities.
Geosite Eight: Beginning of Pilgrimage Trail to Spring Mountains
During the US Air Force funded EIA study of a proposed expansion of their lands, an assessment team appointed by the CGTO consulting group and representing 18 tribes studied the proposed land withdrawal area. During that study, a traditional pilgrimage trail was identified as having one beginning/ending point in Pahranagat Valley that extends south to another beginning/ending point at Corn Creek and the Spring Mountains (Figure 35). A longer technical report of findings is available online at the US Congressionally mandated public project EIA site. These findings were reviewed and approved by the 18 tribes and their participating representatives. A summary article based on those findings is referenced here [40].
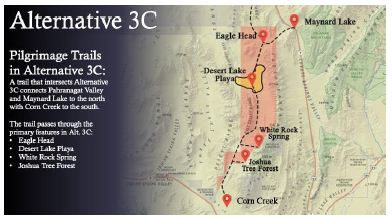
Figure 35: Diagram of Pahranagat Valley to Spring Mountains [47].
One geosite from along this pilgrimage trail is illustrated in Figure 36 [47]. In the upper left is a view from Eagle Head looking to the south along the pilgrimage trail as it headed towards the massive Desert Lake Playa. Archaeological studies document that Native Americans occupied this wetland as long as 9,000 YBP. The Joshua Tree, top right, is a food and ceremonial plant that occurs in abundance to the south where ceremonies were held during the multi-community harvests of its fruit. Next to the right are peckings at the narrows of Eagle Head. Figure 37 shows details of the peckings in the narrows.

Figure 36: Images from along the Pilgrimage trail to the Spring Mountains. Note the knotted strings, top right of the middle photo, which is a marker of ceremonial trails.
The Eagle Head Narrows on the pilgrimage trail has peckings on both sides of the constriction. In Figure 37 left, Richard Arnold is viewed interpreting a panel of peckings, including many Mountain Sheep which, as discussed above, are depictions of spirit helpers.

Figure 37: Peckings Along Pilgrimage Trail at Eagle Head Narrows 47.
It is useful for this analysis to note that the Native American representatives view this trail and others in the region as potentially interconnected as well as being destination-only trails. Black Butte is a ceremonial hub, but the Spring Mountains are the origin location of all humanity, with the trail to this geoscape composed of many sacred sites thatA mark portals to other dimensions [57].
Geosite Nine: Red Hawk Origin Lake – Maynard Lake
Stoffie and Arnold [41] record that, on the southern end of Pahranagat Valley, a Pleistocene lake left a 15-foot tall, continuous white ring around the edge of a once plugged up canyon, and here is the origin place for Kwinat’sits, the red tail hawk (Buteo jamaicensis) [33,41,46] (Figure 38). Known today as Maynard Lake, this site is located inside of the Pahranagat National Wildlife Refuge. Although a natural dam has been breached in modern times, various past lake levels are indicated by white bands that ring the red cliffs of the valley. The site is where the Kwinat’sits received the white band on his tail feathers.

Figure 38: Red Tail Hawk Origin Site, aka Maynard Lake.
This white band occurred because the Kwinat’sits used the canyon walls as his perch from which he protected the area. When the natural weather conditions became more arid and the lake water level lowered it left a white band across the bottom of the tail feathers, just as it left its mark on the walls of the canyon. The existence of Kwinat’sits is spiritually tied to Maynard Lake, much like the Arrow Canyon Range mountain sheep are tied to a place known as Potato Woman [46]. Kwinat’sits is one of the animals that appears when a human reaches the afterlife. The appearance of the red tail hawk shows that the person is now whole and strong again. The hawk also helps the person go across to the afterlife at the end of the journey. The red tail hawk feathers are used in medicine fans because of the puha of that animal. Red tail hawks are a good omen [41].
Geosite Ten: Pecking of Twins, Pilgrimage Trail Connecting Red Tail Hawk with Delamar Lake
In Southern Paiute society, only a select group of shamans called Puha’gants made pilgrimages, which they conducted on behalf of the entire community, as well as for themselves. Those who went on these journeys were medicine men or medicine men in training. These spiritual journeys were not to be taken by everyone because there were great physical and spiritual risks involved. While ceremonial activities such as ritual cleansing and daily prayers occurred in a pilgrim’s home community, most of the rituals associated with pilgrimage took place far from daily living space in controlled settings along the trails [29].
The pilgrimage trail into and out of Delamar Valley (Figure 39) is marked by two rare peckings known as the Twins (Figure 40). They occur at two locations where they mark the ends and beginnings of a pilgrimage trail [35]. The Twins and the figure to their left appear clearly downstream in lower Pahranagat Valley at the outlet of the Pleistocene Lake known as the Red Hawk origin spot. They appear again in the center of the portal peckings in Delamar Lake. Native interpretation is that the twins mark a place for prayer for pilgrims thus making the journey to and from the two destination locations.
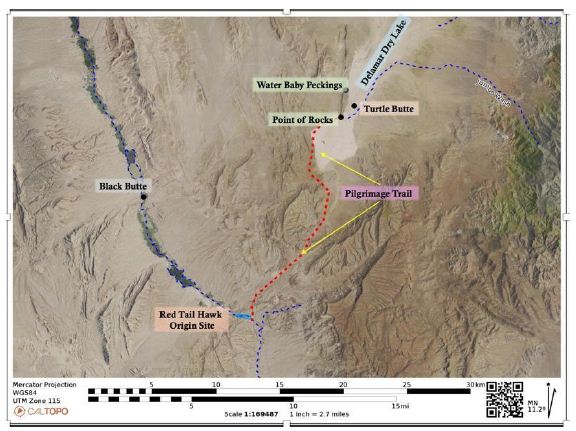
Figure 39: Pilgrimage Trail With Twins Marking Each End.

Figure 40: Twins Peckings: Left, Red Tail Hawk; right, Delamar Lake [35].
The twins in these peckings resemble those often represented from the northern-sky constellation Gemini. The twins exist in other cultures throughout the world. For example, in ancient Greece, one twin is named Pollux and the other is called Castor. They are the most northern of the pair and its twin status is mythologically understood in a number of cultures. Other Native American interpretations of twins include (1) Hopi stories associating the Gemini stars with the twin war gods, Poqanghoya and Pookonghoya, and (2) in Navajo cosmology, representing the Gemini stars as the Hero Twins, central figures in creation stories, and (3) the Lakota stories in which the Star Twins are associated with the Thunder Beings. The Twins also are seen in a painted panel in a culturally important cave in upper Kanab Creek in the Grand Canyon region of northern Arizona. Another Native interpretation was that the Twins represent the Salt Song sisters who participated in the formation of the trail to the afterlife that is traveled through a thousand miles of spiritual and physical paths and places [35,57,67].
Geosite Eleven: Coyote’s Jar Emergence Site
Most Native cultural groups have an Origin or Creation location describing where all humans were made. In addition, most cultural groups have a second or multiple creation sites where a local component or district of people were created. For Southern Paiutes, all humanity was created in the Spring Mountains and, for the Southern Paiutes of the Moapa and Pahranagat district, they were created at their secondary creation site, Coyote’s Jaw [20,46,48].
Geosite Twelve: Reach Three – Lower Reach of White River and Muddy River
This reach of the White River begins at the end of the Pahranagat Valley at the Red Tail Hawk geosite, previously described. The hydrological system is termed White River until its waters reach the Virgin River, but maps shift the name from White River to Muddy River just after Arrow Canyon near Warm Springs. Figure 41 shows the location of two large Pleistocene lakes which are now largely playas termed Apex North and Apex Lake. These wetlands were within 15 miles of the Las Vegas River hydrological system, and plants and animals likely have moved over time between the two systems at this location.
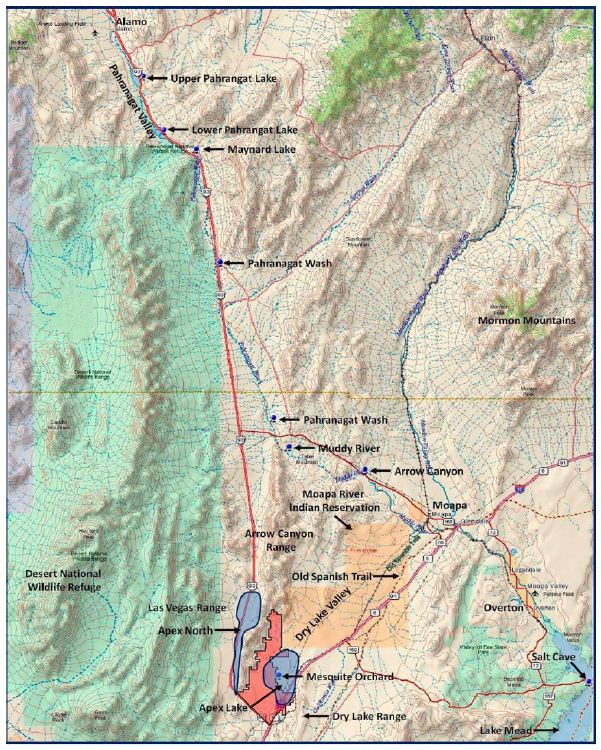
Figure 41: Lower Reach of White River, Muddy River [45].
Geosite Thirteen: Arrow Canyon Range
Ethnographic studies involving the interpretation of Arrow Canyon uniformly document it as a ceremonial area with its deep canyon constricting the White River as it moves to join the Muddy River a few miles south. While the canyon is lined with elaborate peckings, as expected for a geosite of this spiritual nature, Tribal representatives have asked that our study teams neither take photos nor publish any in our reports. This analysis honors that request; hundreds of Arrow Canyon photos, however, are publicly available online posted by hikers and students of geology field trips. The Arrow Canyon Range (Figure 42) is associated with Southern Paiute songs, stories, and ceremonies. One story describes how Shin-au-av (Coyote) formed the area with a shot of his arrow [45]. Another story links the Arrow Canyon Range to a Creation Being, Potato Woman. Potato Woman is responsible for the creation of a variety of Nah’gah (Mountain Sheep, Ovis spp.) that live exclusively in the Arrow Canyon Range (Ruuska et al. 2011). The Nah’gah, in turn, have and continue to bring songs, stories, and medicine to Indian people. Impacts to the Arrow Canyon Range directly impact the health of Potato Woman and the creation of the Nah’gah. Potato Woman is also related to two other Creator beings – the Po-ni (skunk) and the Un-nam-but (badger). Areas within the Arrow Canyon Range were used for round dances and balancing ceremonies. In 1890, Southern Paiute people went to the Arrow Canyon Range to perform the Ghost Dance in order to restore balance to the world [43]. Great events occurred in the Arrow Canyon Range area [36,40]. Between the 17th and 28th of September 1872, John Wesley Powell traveled to upper Kanab Creek with Stephen Vandiver Jones and two Kaibab Paiutes, Chuarunpeak (Frank) and George. During this time, Powell recorded a Southern Paiute story about the creation of the Arrow Canyon Range:

Figure 42: Deeply Carved Arrow Canyon on the now surface of the dry White River [70].
Originally the surface of the Earth was a smooth plain, but one day Shin-au-av told Kusav to place the latter’s quiver at a short distance from where they stood that it might be used as a mark, at which he would shoot. Then Shin-au-av sent an arrow from his bow which struck the quiver but glanced and plowed its way about the face of the earth in every conceivable direction, digging deep gorges and canons, making valleys, plowing up mountains, hills, and rocks. In this way the water courses were determined and the hills and mountains made, and huge broken rocks were scattered about the country [69]. According to these early interviews, previous to this time the nation of people had lived in one community, “they were all brothers and sisters,” but the scattering of the nations commenced with the origin of surface relief, for there was now a great diversity of country and each one chose for himself a special habitat. The eagle admired the crags and peaks and mountain summits and delighted in the fierce wind and roaring storm, and he said to his brethren, “My home shall be in the cliffs.” The hawk (Ku-sav) loved the wild rocks, and he said, “There will be my home.” And the badger said, “I will make me a warm burrow in the ground.” And the wolf said, “I will roam over the plains.” And the swallow said, “I will build my nest on the face of the rocks that overhang the waters.” And the grizzly bear said, “I will live in caves.”
According to Powell [69], a great many species of animals are described, each of whom selects his home. When the people had thus separated, they ceased to speak their ancient language, each one adopting a new one which has been handed down to their own descendants. From this time, they also lost their wisdom because of their disagreements, and slowly degenerated, changed to the forms in which they now appear. By some, this change is said to have been gradual, and very slow, but others have said that it was instantaneous and that there was great wonder among the people, each seeing the changes of the other but not seeing their own transformation, and each one supposing that they spoke the original language and that the rest had lost it, and that this transformation was the cause of their separation; while others attribute the change to quarrels and separation. Sometimes, the story is told as if it was a quarrel for the best homes on the new earth, but by others this element of contention is not introduced. At least once this story has been referred to as a point of moral argument for harmony in council [69]. The presence of animals in an area contributes to the overall cultural importance of a place to Native Americans. In Southern Paiute culture, animals factor significantly in songs, stories, and ceremonies. Animals were also important food sources, and their fur, bones, and feathers were used as components in ceremonial objects.
Geosite Fourteen: Arrow Canyon
Arrow Canyon proper was created by the White River, probably during the late Pleistocene, as this glacier-fed, roaring river carved this deep canyon through relatively soft marine sediments that often contain visible corals fossils [19]. The White River continues to move through the canyon on its path to become the Muddy River. The Arrow Canyon images below have been provided to us by the author of the Adventure Taco [70] website, which includes many more high- quality images of the canyon and surrounding areas north along the White River. The images included here represent best the information that we have obtained from ethnographic interviews in the canyon and the archaeological study of other petroglyphs in the White River Geoscape. Only a few panels are presented here but these illustrate the spiritual and ceremonial nature of Arrow Canyon as described by tribal elders since first shared by Dan Bulletts and Herbert Meyers in 1982. The Canyon has been deeply carved by the White River and there are hundreds of peckings in Arrow Canyon. Figures 43-45 represent the diversity and abundance of peckings. Ocean Woman’s Net is presented multiple times. She is the primary original Creator Being for Paiute people. The panel in Figure 44 includes an image of Ocean Woman’s Net, motifs interpreted by tribal representatives as a Bear Paw and wavy lines which indicate spiritual transformations through a portal into the supernatural.

Figure 43: Arrow Canyon Pecking Panel [70].

Figure 44: Arrow Canyon Panel with Ocean Woman’s Net on top left and wavy lines indicating a portal to the supernatural towards lower right [70].
The third pecking panel displays multiple images of feet that are generally interpreted here and elsewhere as representing physical and spiritual travel. To the left of the panel is a mountain sheep that is moving into a shaman [57] (Figure 45).

Figure 45: Arrow Canyon Panel with multiple and different kinds of feet, interpreted by tribal informants as indicating spiritual and physical movement, and (bottom left) a sheep transforming into a shaman [70].
Arrow Canyon has this name due to the historical presence of numerous arrows lodged in cracks in the canyon walls. According to a newspaper article from 1904:
Thousands of arrows shot by bands of Indians for possibly centuries protrude from a fissure several hundred feet long in the rocky walls of Arrow Canon…The arrows are so thick that little room is left for more…Already relic hunters are visiting the place and despoiling it of its treasures by shooting the arrows out with revolvers and rifles… It is believed that Indians visited this site in connection with some rite. Crude, strange figures have been cut by them in the face of the rock wall [71]. A number of Native American tribes, stretching from California to the Great Lakes, are known to have shot arrows into cracks at rock writing sites as an offering to the living rock and spirits that live within it. Archaeological evidence indicates that this ritual action was practiced for a minimum of 2,000 years [72].
Geosite Fifteen: Traditional Trails through Arrow Canyon
The Arrow Canyon Range was the center of a large traditional district prior to colonial disruption, then composed of what are now the Moapa and Pahranagat Southern Paiutes [38]. Full-time agricultural settlements were located within the large hydrological system beginning northeast of Pahranagat Valley and continuing down along the Muddy, Virgin, and Colorado Rivers. Arrow Canyon Valley was used for hunting, gathering, and traveling between these agricultural settlements. These continual use patterns account for scattered archaeological remains in the Arrow Canyon Range area. The site of the trail from Moapa through the Sheep Range to the Spring Mountains is located near the junction of US 93 and SR 168, near the junction of the Muddy River and US 93 (Figure 46). This special trail connects the traditional Indian villages, located to the east in the Virgin Mountains, the Moapa villages along the Muddy River, and the Pahrump villages on both sides of the Spring Mountains. This trail also connects special natural and cultural places, such as the waters of the Virgin River and the Colorado River to the east. The important Salt Cave, at Saint Thomas, is currently inundated under Lake Mead, but there were Ghost Dance ceremonies conducted there and near Arrow Canyon.

Figure 46: Towards Arrow Canyon Range Looking Northeast from US 93 where the Indian Trails Cross to and from the Sheep and Spring Mountains.
The Muddy River trail was interpreted by the AITC [39] as traditionally used. One of these was for the exchange of wives. Men from Pahrump Valley came to Moapa to acquire wives. In fact, the Pahrump Paiutes interpret the term Moapa to be a shortened form of “Muh-ma’-pah” which may be a play on words designed to mean “Woman Water.” In Native American culture, trails are sacred because they lead to places of power or spirits. Indigenous people physically travel trails, but they also travel through the medium of song, prayer, and in their spiritual thoughts (Henningson, Durham and Richardson 1980). The academic literature recognizes the importance of Native American trails, describing them as the most enduring evidence of Indigenous land use [73]. Norris and Carrico [73] specifically discuss the Mojave, the Cocopa-Maricopa, the Yuma-Needles Trails, and other shorter and less significant trails. Landforms along these trails possess significance to Native Americans, reflecting their land use methods and knowledge of the landscape. The Salt Song Trial, for instance, was and still is a functionally integrated series of landmarks and sacred areas for both the Southern Paiute and the Hualapai people. Trails are not then just physical entities, but they are additionally repositories of prayers, songs, and thoughts [46]. Native American representatives identified 15 traditional use plants and 34 traditional use animals within Arrow Canyon area. Identified plants include those used for ceremony, medicine, food, and utilitarian purposes including the construction of various cultural items and tools. One animal that had special meaning for the Arrow Canyon area is the mountain sheep. These are understood as spiritual animals that are spirit helpers for rain shamans [39].
Geosite Sixteen: Ghost Dance Site
According to interviews with Moapa Paiute tribal representatives [43,44,46], there was a dance site on the western end of Mormon Mesa on Table Mountain that was also used for a Ghost Dance, a late nineteenth century revitalization movement. The Ghost Dance is considered by most to be a form of traditional Round Dance. The physical characteristics of this geosite confirm its use as a Ghost Dance site and traditional Round Dance site. Because of contemporary cultural sensitivity, the tribal members requested that the exact location not be placed in our reports [43,46]. After the establishment of the Moapa Reservation in 1873, Southern Paiutes struggled to cope with changing lifeways as they became increasingly incorporated into the Euro-American wage labor economy. The Ghost Dance was a culturally significant event that, when manifested in a particular place and space, reaffirmed the identity of a people [74,75]. Southern Paiute people were able to become a part of a pan-Indian movement by transcending aboriginal boundaries defined by language, society, and politics. The Ghost Dance performance provided a foundation for identifying sacred places in a contemporary setting. The Ghost Dance movements of 1870 and 1889-1890 sought to restore dead animals, destroyed botanical landscapes, and dead ancestors to their aboriginal condition and to shift power from Euro-Americans (who were expected to not survive the event) back to Indian peoples [75]. This ceremony was conducted in response to Euro-American encroachment on Indian holy lands, the resulting stress from diseases that caused depopulation, the disruption of animal and native plant areas, their forced removal from springs, rivers, and farming areas, social disruptions of various kinds, and the inability of traditional religions to explain or deal with ailments resulting from this encroachment. Arrow Canyon is in a location that allows views of the 1890 Ghost Dancers from Moapa. Participants from Paiute communities located along the Virgin and Santa Clara Rivers and the Cottonwood Island on the Colorado River attended this event [45].
Carroll [43] explains that, even though the late nineteenth century Ghost Dance ceremony was performed in Arrow Canyon area during 1890, it remains a vital cultural heritage geosite today [45,46]. A Southern Paiute representative from Carroll’s study of the 1890s Ghost Dance said that:
I came to Arrow Canyon at night with some friends. We were just out driving around and having a good time. Once we got to Table Mountain, I felt something. Things felt different. I could hear people singing. When I looked up on top of Table Mountain, I could see the Ghost Dancers moving around in a circle. I had not been told anything about this place but knew what it was about once I was here. It was a good experience to come to Arrow Canyon. It cleared my mind. I know those Ghost Dances were here before. I could hear a drum beating and I hear people talking in Indian. I tried to listen hard. It was so peaceful. I didn’t think about anything but that place. The animals were chasing each other, and the lizard was running after something. It brought peace to mind, and it also made me mournful, so I prayed. You hear things when you are in tune. This place is alive with spirits there. They communicate that to you. There is also a quietness of the canyon that is very special [43].
Geosite Seventeen: Potato Women Creation Being
Potato Woman (Figure 47) is located along the southern flank of Mormon Mountains, the western edge of Mormon Mesa, just north of Weiser Wash. Potato Woman’s hair touches Interstate Highway 15. Potato Woman is a Creator Being [46]. According to a Paiute elder interviewed in 1982 during the IPP study [36], Potato Woman is especially powerful because she is related to two other Creator Beings — the Po-ni (skunk, Spilogale putorius) and the Un-nam-but (badger, Taxidea taxus). As a Creator being, Potato Woman has a permanent responsibility for creating a small variety of Nah’-gah (Mountain Sheep, Ovis spp.) which predominates in the Arrow Canyon Mountain Range. This Nah’gah, in turn, has brought, does bring, and will bring songs, stories, and medicine to Indian people.

Figure 47: Potato Women West from US 15 (AITC 1999).
Potato Woman is known as a powerful place, so powerful that traditionally Indian people would not camp near her. In 1982 during the IPP studies, a Paiute elder provided a detailed story of a medicine man who spent the night near her. He became sick and only because of his personal power was he able to heal himself. Some of the power of the place comes from unburied spirits caused by an epidemic that killed lots of people in Moapa Valley. This story was provided to illustrate the power of Potato Woman. The epidemic was probably malaria introduced by Spanish explorers. It spread up the Colorado River to the White River Muddy Valley in the late 1700s. The epidemic caused many people to die and thus they often refer to the Moapa Valley as the Valley of Death. The name Moapa derives from the term moa or mosquito and pah or water.
Geosite Eighteen: Traditional Farming Villages in Muddy River Valley
The entire length of the Muddy River from approximately Arrow Canyon to the Virgin River contained traditional Native farming communities. The river valley was always occupied but farming communities were most common for the past 2,000 years.
Geosite Nineteen: Warm Springs
Warm Springs is one of a number of naturally occurring artesian springs that create a series of riverine oases. There is a diverse flora and fauna at these locations. During the IPP studies, a Moapa elder pointed out that food from the plants at this spring become available each month of the year. Of special importance are the native palm trees which are seen as traditional use plants by the Moapa elders. Hot springs are places of mixed power. They supply water for healing, and they represent a place that has its own spirits (Stoffie, et al. 1998). At this time, the drinking water of all towns and the Moapa Indian reservation come from this hydrological system (see photos of Warm Springs- Figure 48). Ethnographic interviews at this site occurred during the AITC 1999 study [39] and in other studies. Native American quotes identified by the speakers’ names are used uniquely in this analysis because the spring managers wanted to remove the indigenous palms which they incorrectly maintained were recent additions; the tribal representatives involved in the AITC study wanted to have their memories recorded.

Figure 48: Warm Springs [77].
Other Moapa Paiute elders have shared information about Paiute uses of native palm trees during the early 1920s [76]. Some of his quotes are reported here and they are consistent with others shared during the ethnographic study.
- I remember Palm parts being used to make The baskets made in this way (from palms) were not the really fine sort which were made from other materials. I never learned to make baskets. I remember my grandmother making them. I have also seen my grandparents making shelters out of palm leaves from the springs. My grandfather had a place that he took a sweat bath in. It wasn’t right by the springs but near where he lived. But he would go to the headwater of the Muddy River at the Warm springs because there was something sacred in the water. He would then talk to the water and bring it back to his sweat hut. No one lived in the springs themselves… We drank water out of the ditch and there were many Palms over there. Over at the springs was a very sacred place and as children we had to act a certain way whenever we went over there.
- I also know where the deep stone holes are where grandma used to work the Palm I was very little. The stones they used to grind the screwbeans, and the mesquite were called Maddah and were different than the deep holes they used for Palm seeds.
My Elders used to say that the whole area of the springs west of here was a designated spiritual area and very sacred. We know that the Palms have always been there. We Moapas have always known this.” Quote by Evelyn Samalar, Moapa Paiute, age: 76 years (1996).
- …they used Palms for small I remember my grandparents using Palm leaves for shelters and small huts. I don’t remember any other uses; I was very young. My grandfather said that the Palms are always here.” Quote by Irene Benn, Moapa Paiute, age: 73 years (1996)
- I remember seeing shelter built with Palm thatching and I remember my grandparents using Palms to build small huts and such. I also remember seeing my grandmother crush the black seeds from the Palms in a deep stone hole in the ground, but I was very young, and I don’t remember how it was used. My father used to say that the Palms were always here. My grandparents always used to say that too…that the Palms have always been here. There are deep grinding holes in the rocks near my house. About four of them…I’ll show you. (spoken to Kaye Herron) …where my grandmother used to grind the seeds of the Palms.” Quote by Maureen Frank, Moapa Paiute, age: 63 years (1996).
- My grandparents said that the palms have always been I also saw my grandmother grind the seeds from the palms using some special holes in the rocks by my house I think they made a gravy. She used to crush them in the deep stone holes by my house. There used to be a Paiute word for the gravy they made with the seeds, but I don’t remember what it was. Irene might remember. We have always known that white men did not bring the palms with them. Among ourselves we’ve always known that the palms were here before any white man came.” Quote by Juanita Kinlichinie, Moapa Paiute, age: 64 years (1996).
During the IPP, Herbert Meyer interviewed at this oasis spring with Dr. Pamela Bunte and Richard Stoffie about this spring’s ethnobotany and its cultural importance. As we walked around its perimeter Meyers noted the medicine and food plants then present. He maintained that the edge of the spring always provided different food and medicine plants at different seasons making it a culturally central place for the Moapa people. Spiritually he maintained that the plants appear annually because Coyote planted them, thus adding another dimension to this geosite.
Geosite Twenty: Crossing of the Salt Song Trail
The Salt Song Trail, followed by a deceased spirit to the afterlife, crosses through the hair of Potato Woman about where Highway 15 passes. The Salt Song Trail emerges from the Mormon Mountain sacred sites, allowing the deceased spirit to pause for some time before continuing their journal to the afterlife. The spirit enjoys the view of the Muddy River Valley and surrounding mountains. It then continues to the Salt Cave on the Salt Song journey. The thousand- mile-long Salt Song Trail is traveled by deceased Numic People and the Hualapai People to the afterlife [78]. The deceased is sung along the trail to specific places by sequential songs [32,44,46,79].
Geosite Twenty-one: Salt Cave
The Salt Cave is the final geosite discussed here [44] (Figures 49- 51). It has been studied since the 1930s by archaeologists such as M.R. Harrington [80. 81] and ethnographers so is only briefly discussed here. Ethnographic interviews were conducted at this location during the Old Spanish Trail study [44].
Figure 49: Map of the Salt Cave Area.
Figure 50: Diagram of Traditional Salt Cave [44].

Figure 51: Entrance to Traditional Salt Cave, by Harrington [44,46,81].
According to Southern Paiute epistemology, caves are places with high amounts of Puha. People would travel into caves to seek songs, spirit helpers, knowledge, and medicines. Caves are places only used by religious specialists and shamans; non-initiated people would not enter them. Items taken from caves were used to help individuals, communities, and the surrounding environment. Songs could be used in round dance ceremonies to bring the world back into balance. Medicines such as ompi (red paint) and salt could be used in doctoring ceremonies.
During the Southern Paiute Funeral Ceremony, also known as the Cry, the spirit of the deceased visits the Salt Cave. During the Cry, Salt Songs are sung to help move the spirit to the afterlife. The songs are known as the Salt Songs because they were created by the Salt Song twins, and they describe various places along the trail. After the deceased person’s spirit crosses the Colorado River at its junction of the Virgin, the spirit visits the Salt Cave. A tribal representative said that:
The Salt Cave was and is sacred. Avi-Na-Va in Arizona is similar. The Salt Song Trail went through here. The songs pass through here to meet the other trails around. ‘Tu-winna gat’ is a sacred story told by Coyote by sacred tongue. Nobody talked of sacred things – only the shaman or wise men could have the authority. ‘Na-win-na-gat’ are like this: one is the story land which Coyote lives in and he carries the sacred story by the sacred talk. A lot of people say that this is the place where the Salt Song got its name. I feel that it works with other caves like there’s one down near Prescott that’s powerful, there’s one…Pintwater that’s powerful, Gypsum–that’s powerful, and the ones in the Spring Mountains are powerful as well. Even the ones in the Providence Mountains. I think all together yeah that they somehow, they were together, and the traditional people could see that [44].
Another tribal representative said that:
The person who was given the position to be the one to go in and get the salt for the people had his own songs. There were songs associated with the cave for coming and going. You could probably get songs from the cave if you needed them [44].
The Salt Cave is at the junction of the Virgin and Muddy Rivers. In the Paiute worldview, powerful places also exist at the convergence of hydrological systems. For people who live in the desert, water is the most important component of life. With its affinity for life, water is seen as a powerful element. Miller [28] describes all types of water as sacred and its power adheres to its reservoirs as clouds, rain, snow, springs, seeps, lakes, streams or the occasional river in the desert. The Puha that is concentrated at places where two water sources meet creates special ceremonial areas.
Religious specialists responsible for collecting salt from the cave had to prepare themselves for this activity. The preparation process would start in the specialists’ home communities and then continue along a pilgrimage trail to the Salt Cave. The home communities were major Paiute settlements located at permanent water sources. The pilgrimage trail, more aptly named Puha Path, has various stopping points where the specialists would visit shrines to say prayers and leave offerings of water, pottery, arrowheads, or rare stones. Once they arrived at the cave, they performed a ceremony that would allow them to enter the cave and harvest the salt.
Summary of Geosites: Not Just Places
The geosites analyzed here are culturally important; however, taken as components of a functionally integrated landscape they define the special role of the heritage geoscape and why it is culturally central in the lives of Native people. Early ethnographic studies focused narrowly on study areas as these were established by land managers for use by federal and state agencies. The resulting studies provided data on a small and topically focused area. As a consequence, the larger heritage geoscape interpretation awaited an integrated approach such as presented here.
Based on this and other studies [82], geosites illustrate that, among other features of the geoscape:
- Medicine places focused on massive stones
- Portals were used to transform spiritual Native leaders and acquiring spirit helpers
- Hight points were for vision questing
- There are geosites where pilgrimage trails and the journeys began and ended
- Hot springs were used for purification and healing
- Rock outcrops that constrain a flowing river concentrate Puha or energy
- Canyons were carved by White River runoff from Pleistocene glaciers, snow and heavy
- Native communities expanded in size in the past 2,000 years due to irrigated
- Concentrations of spiritual energy and heritage ceremonies, such as Round Dances, occur at
- A geoscape has mutual heritage functions whose interactions constitute an ancient and persistent cultural landscape with critical geology and topographical
The geosites were selected for this analysis because they illustrate a range of geological and cultural places along the White River geoscape. These geosites were identified and interpreted by Native Americans in ethnographic studies and through ongoing archaeological studies funded by land management agencies. This analysis and these findings potentially contribute to the White River Geoscape being recognized as a heritage geological and cultural landscape [22].
Discussion
The White River flows through the Pahranagat Valley; thus, it is central to an extensive hydrological system that feeds into the Virgin River and subsequently into the Colorado River to the southeast. The area is topographically a part of the Colorado Plateau, but it is adjacent to the Great Basin. The hydrological system has permanent and abundant water because it is fed by snow and rain that falls on much higher surrounding mountains, especially near its headwaters to the north. While the mountains are covered with dense forests, the river valley itself is arid. Together, these produce a fertile riverine oasis, which has supported Native American life since Time Immemorial. Importantly, this geoscape contains one of the largest concentrations of rock writing geosites and s/b petroglyph motifs in Numic territory, potentially only second to the Coso Range, eastern California, which has the largest concentration of rock writing in the Americas, if not one of the largest in the world. An early Native American environmental perspective was recorded in 1864 when William Nye and his mine explorers lived for a winter in the mountains along the river valley. In his essay entitled “A Winter Among the Paiutes,” Nye [83] noted that Pah-ranagat is purely a Native American name, and one which in the Southern Paiute language signifies “shining water”—the Valley of the Shining Water—a name which, at least, reflects no little poetic faculty of the Indian dwellers in this valley of the mountains. After all, it is a pleasant thought that, in the past, this little strip of fertile land with its grass-bordered streams has been a Native American paradise. Nye’s mining camp was located on a mountainside within view of Lower Pahranagat Lake. Below the camp was an Indigenous village whose inhabitants grew corn and melons. The Fowler and Sharrock [84] and Madsen studies of this valley, based on field archaeology and documents, indicated that from the protohistoric period until at least 1865, the “Southern Paiutes were farming with the use of irrigation ditches in the valley.” This village probably was the location of a High Chief [85]. Although Nye [83] noted the common belief of his fellow Americans that Native Americans and the White Man are natural born enemies and that we are here only to fight and kill each other, it was Nye’s experience that:
Ours was an honest struggle to live in peace with our Indian neighbors; and we found them, in many respects, not very unlike what any community of two hundred white men would have been under the same circumstances…Their chief (Pah-Wichit) saw fit, at the outset, to remind us that the region was his domain. He said: “Me one great captain,” and with impressive gesture, he pointed down the valley [83]. Despite the early efforts of Nye to forge a peaceful coexistence with the Indian villages of the valley, the State of Nevada was to establish the first county seat just upstream at a community called Hiko. Before that could happen, however, there had to be growth in the local population, so new settlers were encouraged to mine and farm. As a matter of Nevada Territorial policy and of image, the Indians had to be controlled. In the late 1860s, the members of two of the three Indian villages were surrounded by local settlers, and most of the Native American people were either killed or removed [39]. In 1873, Powell and Ingalls recorded a Native population [69] in their official U.S. government survey. At that time, there were Pahran-i-gats residents in the valley headed by a chief called An-ti-av.
The cultural significance of places such as Black Butte in Pahranagat Valley to Native people is well understood from Powell and Ingalls[85] who interviewed the Native American farmers in the valley [69]. During that ethnographic visit, they recorded a poem that they had composed regarding Native feelings about the beauty of the area. It was a Paiute song about this valley, which they called:
The Beautiful Valley [MS 831-c][56].
Pa-ran’-i-gi yu-av’-i The Paranagat Valley Yu-av’-in-in The Valley
Pa-ran’-i’gi yu-avai-I The Paranagat Valley Yu-av’-in-in The Valley
U-ai’-in-in yu-av’-I Is a Beautiful Valley Yu-av’-in-in The Valley
While this song and poem reflect the traditional views of the Native people about this valley, Powell and Ingalls recorded but a small portion of this tradition song. Many songs lasted for hours. This song was composed for and traditionally sung to the valley. According to the Powell and Ingalls report, the Pahran-i-gats were formerly three separate tribes (probably local irrigated farming communities), but their lands had been taken from them by white men and so they have united in one tribe under An-ti-av. Two years later, in 1875, all local Paiute Indians, including the Pahran-i-gats, were relocated from their valley to the new Moapa Indian Reservation on the Muddy River which is the continuation of the White River that flows into the Virgin River and is the contemporary home of the White River people [39]. The Moapa Paiutes, and all Southern Paiutes and Western Shoshone are the relatives of the ancestorial people of the White River Geoscape. These Native people have a Creation-based stewardship responsibility to protect and honor the places, plants, animals, rock markings, and the history of their ancestors. In a Living Universe, relationships involve all Earth elements and mutual responsibilities are shared.
References
- Benson LV, Hattori EM, Southon J, Aleck B (2013) Dating North America’s Oldest Petroglyphs, Winnemucca Lake Subbasin, Journal of Archaeological Science 40: 4466-4476.
- Middleton ES, Smith GM, Cannon WJ, Ricks MF (2014) Paleoindian Rock Art: Establishing the Antiquity of Great Basin Carved Abstract Petroglyphs in the Northern Great Journal of Archaeological Science 43: 21-30.
- Whitley DS (2013) Rock Art Dating and the Peopling of the Journal of Archaeology 2013 (713159) : 1-15.
- Whitley D (2014) Future Directions in Hunter-Gatherer Research: Hunter-Gatherer Religion and Ritual. In Oxford Handbook of the Archaeology and Anthropology of Hunter-Gatherers. (Eds) Cummings V, Jordan P, Zvelebil M. Oxford University Press: Oxford, Pg: 1121-1242.
- Whitley DS, Dorn RI, Simon JM, Rechtman R, Whitley TK (1999) Rockshelter and the Archaeology of the Vision Quest. Cambridge Archaeological Journal 9: 221-247.
- Brocx M, Semeniuk V (2007) Geoheritage and Geoconservation – History, Definition, Scope and Scale. Journal of the Royal Society of Western Australia 90: 53-87.
- Musser Map of the Great Basin. Map of the Great Basin.
- Bennett M, Bustos D, Pigati J, Springer K, Urban T, et (2021) Evidence of Humans in North America during the Last Glacial Maximum. Science 373: 1528-1531. [crossref]
- Pigati, J. S.; Springer, K. B.; Honke, J. S.; Wahl, D.; Champagne, M. R, et al. (2023) Independent Age Estimates Resolve the Controversy of Ancient Human Footprints at White Science 382: 73-75. [crossref]
- Rowe T, Stafford TW, Fisher D, Enghild J, Quigg JM, et (2022) Human Occupation of the North American Colorado Plateau ∼37,000 Years Ago. Frontiers in Ecology and Evolution 10.
- Laabs B, Munroe J (2016) The Relative Timing of Late Pleistocene Glacier and Pluvial Lake Maxima in The Northern Great Basin, Nevada and Utah, U.S.A.
- Rowley J, Fan M (2016) Middle Cenozoic Diachronous Shift to Eolian Deposition in the Central Rocky Mountains: Timing, Provenance, and Significance for Paleoclimate, Tectonics, and Paleogeography. Geosphere 12: 1795-1812.
- National Park Fossilized Footprints. White Sands National Park.
- Lucas S, Semken S, Berglof W, Ulmer-Scholle D (2003) Geology of the Zuni Plateau, New Mexico Geological Society, Guidebook, 54th Annual Field New Mexico Geology Society: Socorro NM.
- Treaty of Guadalupe-Hidalgo, 1848.
- Grayson D (1993) The Desert’s Past: A Natural Prehistory of the Great ; Smithsonian Institution Press: Washington DC, USA.
- Romero Villanueva G, Sepúlveda M, Cárcamo-Vega J, Cherkinsky A, de Porras ME, et (2024) Earliest Directly Dated Rock Art from Patagonia Reveals Socioecological Resilience to Mid-Holocene Climate. Science Advances 10. [crossref]
- Angelbeck B, Springer C, Jones J, Williams-Jones G, Wilson MC (2024) Líĺwat Climbers Could See the Ocean from the Peak of Qẃelqẃelústen: Evaluating Oral Traditions with Viewshed Analyses from the Mount Meager Volcanic Complex Prior to Its 2360 BP American Antiquity 89: 378-398.
- Wilson EC, Langenheim RL (1993) Early Permian Corals from Arrow Canyon, Clark County, Nevada. Journal of Paleontology 67: 935-945.
- Ruuska A (2025) When the Earth Was New: Memory, Materiality, and the Numic Ritual Life University of Utah Press: Salt Lake City.
- Brocx M, Semeniuk V (2017) Towards a Convention on Geological Heritage (CGH) for the Protection of Geological Geophysical Research Abstracts 19.
- Brocx M, Semeniuk V (2011) Assessing Geoheritage Values: A Case Study Using the Leschenault Peninsula and Its Leeward Estuarine Lagoon, South-Western Proceedings of the Linnean Society of New South Wales 132: 115-130.
- World Commission on Protected Areas 2021-2025. World Commission on Protected Areas 2021-2025.
- Muzambiq S, Sibarani R, Perdana Nasution Z, Gustanto (2024) Geoheritage and Cultural Heritage Overview of the Toba Caldera Geosite, North Sumatra, Indonesia 5.
- Moretti R, Moune S, Jessop D, Glynn C, Robert V, et (2021) The Basse-Terre Island of Guadeloupe (Eastern Caribbean, France) and Its Volcanic-Hydrothermal Geodiversity: A Case Study of Challenges, Perspectives, and New Paradigms for Resilience and Sustainability on Volcanic Islands. Geosciences 11.
- Rappaport Ritual and Religion in the Making of Humanity, Cambridge University Press: New York.
- Liljeblad S (1986) Oral Tradition: Content and Style of Verbal Arts. In Handbook of the American Great Basin. (Eds) D’Azevedo W. Smithsonian Institution Press: Washington D.C, USA. 11.
- Cap & c (1983) Basin Religion and Theology: A Comparative Study of Power (Puha). Journal of California and Great Basin Anthropology 5: 66-86.
- Van Vlack, K (2012) Southern Paiute Pilgrimage and Relationship. Journal of Ethnology 51: 129-140.
- Stoffie R, Zedeño M, Halmo D (2001) American Indians and the Nevada Test Site: A Model of Research and ; U.S. Government Printing Office: Washington D.C.
- Loubser JHN (2024) LCAI Round 13 – Graffiti Mitigation and Rock Art Recording at Site 26LN211; Straum Unlimited LLC: New York, NY, USA.
- Whitley D (2015) Ethnographic Interpretation of the Shooting Gallery, Mount Irish and Pahroc Rock Art; Manuscript Posted on edu.
- Ruuska A, Keifer L, Mallo A (2011) Oral Histories and Place-Making Practices of the Mormon Mountains Among the Southern Paiute and Western Shoshone. Bureau of Applied Research in Anthropology, University of Arizona: Tucson AZ.
- Stoffie R (2007) Cultural Heritage and Resources. In The Heritage Reader; (Eds) Fairclough G, Harrison R, Schofield Routledge: London, England. Pg: 363-372.
- Stoffie R, Van Vlack K, Johnson H, Dukes P, De Sola S, et (2011) Tribally Approved American Indian Ethnographic Analysis of the Proposed Delamar Valley Solar Energy Zone. Bureau of Land Management Solar Programmatic EIS.; Bureau of Applied Research in Anthropology, University of Arizona: Tucson, AZ, USA.
- Stoffie R, Dobyns H, Nuvagantu (1983) Nevada Indians Comment on the Intermountain Power Project.; Cultural Resources Series 7. Bureau of Land Management Nevada: Reno, NV.
- Stoffie R, Evans M, Dobyns H (1981) Puaxant Tuvip: Utah Indians Comment on the Intermountain Power Project, Utah Section of Intermountain Adelanto Bipole I University of Wisconsin-Parkside, Applied Urban Field School.: Kenosha, WI.
- Stoffie R, Evans M, Dobyns H (1983) Nungwu Uakapi: Southern Paiute Indians Comment on the Intermountain Power Revised Intermountain-Adelanto Bipole I Proposal. University of Wisconsin-Parkside, Applied Urban Field School.: Kenosha, WI.
- Arnold R, Booth E, Cloquet D, Cornelius B, Eddy L, et (1999) American Indian Transportation Committee Field Assessment of Cultural Sites Regarding the U.S. Department of Energy: Preapproval Draft Environmental Assessment of Intermodal Transportation of Low-Level Radioactive Waste to the Nevada Test Site. Bureau of Applied Research in Anthropology, University of Arizona: Tucson, AZ.
- Stoffie R, Toupal R, Zedeño M (2002) East of Nellis: Cultural Landscapes of the Sheep and Pahranagat Mountain Ranges, An Ethnographic Assessment of American Indian Places and Resources in the Desert National Wildlife Range and the Pahranagat National Wildlife Refuge of Nevada; Bureau of Applied Research in Anthropology, University of Arizona: Tucson, AZ, U.S.A.
- Stoffie R (2003) Arnold, Confronting the Angry Rock. Ethnos 68: 230-248.
- Carroll AK, Zedeño MN, Stoffie RW (2004) Landscapes of the Ghost Dance: A Cartography of Numic Journal of Archaeological Method and Theory 11: 127-156.
- Carroll A (2007) Place, Performance, and Social Memory in the 1890s Ghost Dance. Dissertation, University of Arizona, Tucson, AZ, USA.
- Stoffie R, Van Vlack K, Toupal R, O’Meara S, Arnold R (2008) American Indians and the Old Spanish Trail.; Bureau of Applied Research in Anthropology, University of Arizona: Tucson, AZ.
- Stoffie R, Van Vlack K, Johnson H, Dukes P, De Sola S (2011) Tribally Approved American Indian Ethnographic Analysis of the Proposed Dry Lake Solar Energy Zone; Bureau of Land Management Solar Programmatic EIS. Bureau of Applied Research in Anthropology, University of Arizona: Tucson, AZ, U.S.A.
- Ruuska A (2015) Social Investment in Regions of Refuge: Survival Strategies Among The Southern Paiute of Southern In Engineering Mountain Landscapes. (Eds) Sheiber L, Zedeño M. University of Utah Press: Salt Lake City, Utah, USA. Pg: 75-98.
- Stoffie R, Arnold R, Van Vlack K (2022) Landscape Is Alive: Nuwuvi Pilgrimage and Power Places in Land 11.
- Stoffie R (2000) Culture Heritage and In Social Impact Analysis: An Applied Anthropology (Eds) Manual; Goodman L. BERG: New York, NY, USA. Pg: 191-232.
- Halmo D (2001) Culture, Corporation and Collective Action: The Department of Energy’s American Indian Consultation Program on the Nevada Test Site in Political Ecological Dissertation, University of Arizona, Tucson, AZ, USA.
- Duckwater Shoshone Heritage. https://duckwatertribe.org; accessed 6/30/205.
- Loubser JHN (2020) LCAI Round 11 – Graffiti Mitigation and Rock Art Recording at Site 26LN210; Straum Unlimited LLC: New York, NY, USA.
- Waller SJ, Gilreath A, Hedges K, McConnell A (2023) Near-Field Far-Field Acoustic Study of White River Narrows Rock Art. In American Indian Rock Art; American Rock Art Research Association: Salt Lake City, Utah, USA 49: 151-158.
- Waller SJ (1993) Sound Reflection as an Explanation for the Content and Context of Rock Art. Rock Art Research 10: 91-101.
- Waller SJ (2010) Voices Carry: Whisper Galleries and X-Rated Echo Myths of In Utah Rock Art; (Eds) McConnell A, Holmes E. Utah Rock Art Research Association: Salt Lake City, Utah, USA. 29: 31-55.
- Liwosz CR (2017) Petroglyphs and Puha: How Multisensory Experiences Evidence Landscape Time and Mind 10: 175-210.
- Van Vlack K (2012) Puaxant Tuvip: Powerlands Southern Paiute Cultural Landscapes and Pilgrimage Trails, PhD Dissertation, University of Arizona, Tucson, AZ.
- Van Vlack K, Arnold R, Bell A (2025) Shamans, Portals, and Water Babies: Southern Paiute Mirrored Landscapes in Southern Nevada. 14: 56. https://doi.org/10.3390/ arts14030056
- Whitley D (1992) Shamanism and Rock Art in Far Western North Cambridge Archaeological Journal 2: 89-113.
- Lewis-Williams JD (1981) The Thin Red Line: Southern Sand Notions and Rock Paintings of Supernatural Potency. The South African Archaeological Bulletin 36: 5-13.
- Stoffie R, Toupal R, Ilahiane H (1999) Environmental Assessment of the Intermodal Transportation of Low-Level Radioactive Waste: Field Assessments of Cultural Bureau of Applied Research in Anthropology, University of Arizona: Tucson, AZ, USA.
- Giambastiani M (2020) Research Context for Late Nineteenth-Early Twentieth Century Native American Settlement and Land-Use in Lincoln County, Nevada. Bureau of Land Management, Ely District Caliente Field Office: Ely, NV.
- Henningson D, Richardson INC (1980) M-X Environmental Technical Report (ETR 21). Native Americans-Nevada/Utah.; Henningson, Durham & Richardson, Inc: Santa Barbara, CA.
- McCracken R, Howerton J (1996) A History of Railroad Valley, Nevada; Central Nevada Historical Society: Tonopah, NV.
- Van Vlack K (2018) Puha Po to Kavaicuwac: A Southern Paiute Pilgrimage in Southern International Journal of Intangible Heritage 13: 129-141.
- Whitley DS (1994) By the Hunter, for the Gatherer: Art, Social Relations and Subsistence Change in the Prehistoric Great Basin. World Archaeology 25: 356-373.
- Fowler C, Garey-Sage D, Isabel T (2016) Kelly’s Southern Paiute Ethnographic Field Notes, 1932-1934, Las ; University of Utah Press: Salt Lake City.
- Stoffie R, Carroll A, Eisenberg A, Amato J (2004) Ethnographic Assessment of Kaibab Paiute Cultural Resources: The Grand Staircase-Escalante National Monument, Utah; Bureau of Applied Research in Anthropology, University of Arizona: Tucson, AZ.
- Stoffie R, Arnold R, Van Vlack K, Eddy L, Cornelius B, et al. (2009) “Where Snow Sits”: Origin Mountain of the Southern In Landscapes of Origin. In Landscapes of Origin; (Ed) Christie J. University of Alabama: Tucsaloosa, Alabama, USA. Pg: 32-44.
- Fowler D, Fowler C (1971) Anthropology of the Numa; John Wesley Powell’s Manuscripts on the Numic Peoples of Western North America, Smithsonian Contributions to Anthropology. Smithsonian Institution Press: Washington D.C, USA.
- Adventure Taco. The Narrows of Arrow Canyon. Adventure Taco Escape the Ordinary.
- Arrows from Long Ago (2007). Journal of California and Great Basin Anthropology 27.
- Whitley D (2021) Symbolic and Ritual Significance of Weapons in Western North American Rock Art. In Weapons and Tools in Rock Art: A World Perspective (Eds) Bettencourt AMS, Santos-Estevez M, Sampaio HA. Oxbow Books: London. Pg: 143-150.
- Norris F, Carrico R (1978) A History of Land Use in the California Desert Conservation Area.; Bureau of Land Management, California Desert District Office. Palm Springs.
- Hittman M (1996) Corbett Mack: The Life of a Northern Paiute; University of Nebraska Lincoln, Nebraska.
- Stoffie RW, Loendorf L, Austin DE, Halmo DB, Bulletts A (2000) Ghost Dancing the Grand Canyon: Southern Paiute Rock Art, Ceremony, and Cultural Landscapes. Current Anthropology 41: 11-38. [crossref]
- Spencer Washingtonia filifera: Nevada’s rejected ancient Palm. A 10 page Introduction to the problem of Palms in Moapa Nevada. Washingtonia filifera: Nevada’s rejected ancient Palm. A 10 page Introduction to the problem of Palms in Moapa Nevada.
- Sedenquist M (2024) An Astounding Oasis in the Desert: Warm Springs Natural Living Las Vegas.
- Laird C (1976) The Chemehuevis; Malki Museum Press: Banning, CA, USA.
- Spoon J, Arnold R (2014) Nuwuvi Working Nuwu-Vots (Our Footprints): Nuwuvi and the Pahranagat Valley. The Mountain Institute and Portland State University: Portland, OR.
- Harrington MR (1931) Lights and Shadows in Gypsum Cave. The Final Phases. The Masterkey 4: 233-235.
- Harrington MR (1933) Gypsum Cave, Nevada 8; Southwest Museum Papers: Los Angeles, CA.
- Stoffie R, Arnold R, Van Vlack K (2024) Native American Science in a Living Universe: A Paiute Perspective. In Natural Science and Indigenous Knowledge: the Americas Experience (Eds) Johnson EA, Aldridge SM. Cambridge University Press: In Press.
- Nye W (1886) Winter Among the Overland Monthly 7: 293-298.
- Fowler D, Sharrock FW (1973) Survey and Test In Prehistory of Southeastern Nevada. In Prehistory of southeastern Nevada (Eds) Fowler D, Madsen DB, Hattori EM. Desert Research Institute: Reno, NV, USA.
- United States Bureau of Indian Affairs. Report of Special Commissioners J. W. Powell and G. W. Ingalls on the Condition of the Ute Indians of Utah; the Pai-Utes of Utah, Northern Arizona, Southern Nevada, and Southeastern California; the Go-Si Utes of Utah and Nevada; the Northwestern Shoshones of Idaho and Utah; and the Western Shoshones of Nevada; and Report Concerning Claims of Settlers in the Mo-a-Pa Valley Southeastern Nevada.; Library of Congress: Washington DC. 1874.