Abstract
Using a combination of Mind Genomics thinking to structure an experiment and AI simulation of respondents, the study considered the impact of 15 different introductions of the Hamas-Israel conflict on the response to elements or messages about Hamas and Israel. Each of the studies was run with 500 synthetic respondents, created from personas, these personas in turn created from different combinations of up-front self-profiling classification questions. The results show the strategy of using ordinary least-squares (OLS) dummy variable regression model to simultaneously estimate the contribution of a basic message (element), introduction, and self-described AI-based persona.
Keywords
AI personas, Framing effects, Hamas-Israel conflict, Mind genomics, Synthetic respondents
Introduction—The Emerging Science of Mind Genomics
Mind Genomics is an experimentation-oriented, data-driven approach to understanding the way that people make decisions about the world of the ordinary. Mind Genomics treats the contents of people’s everyday thinking as a “genome” to be sequenced and analyzed, using short and concrete idea elements combined into vignettes. The experiment requires respondents to rate these vignettes on a scale. The analysis reveals which specific messages drive ratings, then uncovers potentially new-to-the-world mind-sets, defined as simple but often radically different ways people respond to these ordinary stimuli [1-3].
Rather than instructing respondents to evaluate single ideas through a questionnaire, Mind Genomics tries to emulate nature by presenting ideas in combination, with these ideas being different aspects of a topic. The respondent’s task is to react to the combination or vignette, rather than evaluate each idea in the vignette one idea at a time. The inspiration for using combinations comes from the realization that in our daily lives, we react to combinations virtually all our waking hours. The underlying rationale is that people typically spend most of their day confronting combinations of features in nature and react to them in what appears to be an automatic way. People usually have no problem navigating through many mixtures of stimuli and decisions and then moving on. Indeed, when we stop to think about our daily lives, we realize that the isolation and evaluation of single ideas or messages is the unusual, the aberrant, and the rare, if ever, experienced [4,5].
Mind Genomics evolved from the intersection of psychophysics, consumer research, and experimental design. The term Mind Genomics was borrowed from the sequencing metaphor from biological genomics, while deliberately avoiding biological reductionism.
Early instantiations of Mind Genomics used a simple experimental design in which each respondent evaluated every one of the different messages several times in various combinations of elements, these combinations called vignettes. Each respondent rated the vignettes created according to a complete experimental design, allowing the ratings from the individual respondent to be analyzed by ordinary least squares regression (OLS). OLS regression revealed the contribution of every one of the elements to the rating assigned to the vignette [6].
Mind Genomics advanced the effectiveness of OLS regression by creating many different but isomorphic experimental designs. The basic design structure was systematically modified so that each new “daughter design” comprised the same elements but in various combinations. The mathematical structure of the design was constant, so each respondent’s data could be analyzed either alone or in a subgroup of “similar respondents.” At the same time, however, the actual combinations differed from respondent to respondent. In this way, the research could cover a great deal—almost all of the possible combinations.
A key benefit of the permuted experimental design is that the researcher can cover a wide range of stimuli, which changes the research dynamic. In comparison, non-Mind Genomics researchers often spend a great deal of time discovering the most promising elements, wordsmith them, and then spend time creating the vignettes. A great deal of effort goes into polishing the final vignettes to make them “just right.” The result is a loss of time, and an increased expenditure to get to the “right answer(s).” Today’s effort spends valuable time and scarce resources to “short list” relevant ideas of a topic using judgment and afterwards spending one’s research budget for testing on a limited set of the most promising combinations. This effort could take months. In contrast, Mind Genomics tests many different combinations so quickly that the researcher gets a good idea of the strong elements, even with no prior knowledge of the topic and at the beginning of the research. The happy outcome is a process with Mind Genomics measured in hours [7].
The now “classic” structure of a Mind Genomics experiment is to create four questions that tell a story, and for each question, create four mutually substitutable answers. The respondent’s task is to read a vignette and a collection of answers, then assign a rating to the combination. Each respondent rates a unique set of 24 vignettes in the so-called 4×4 design (four questions, four answers or elements for each question). An underlying permutation structure changes the specific combinations that a respondent will. Still, in the end, each respondent evaluates every element five times, in vignettes which comprise four, three, or two elements. Each respondent appears five times across 24 vignettes and is absent 19 times. Finally, a vignette consists of either four, three, or two elements, but each question or silo can contribute at most one element to the vignette. This structure ensures that all 16 elements are statistically independent of each other. Statistical independence will play an essential role in the subsequent analysis because it allows the regression model to collect absolute coefficients. These coefficients—measures of the degree to which the element “drives” the rating—provide a numerical measure of how the respondent thinks about a topic. The Mind Genomics set-up allows for absolute values of coefficients, which means that the coefficients can be compared across time and different conditions [8].
Analyzing the data generated by a Mind Genomics experiment follows a now-standard procedure. The ratings are assigned on a labelled category or Likert scale, from a low of 1 to a high of usually 5, but occasionally 7 or 9. A labelled 5-point scale has become the most popular scale because it is easy to understand, and because each scale point can be labelled.
If we were to summarize the process from the point of communicating to management, we might use the following summary generated by Microsoft’s AI program, Co-Pilot. AI summarizes the process as follows:
Mind Genomics begins by decomposing a complex real-world situation into a small set of meaningful, researcher-defined aspects called silos. Each silo represents a distinct question about the situation such as goals, constraints, stakeholders, or emotions. For every silo the researcher writes four concise, concrete elements that capture plausible variations of that aspect. These elements are translated into short, vivid phrases that can be recombined to form many realistic micro-scenarios. The design then constructs a balanced set of vignettes, so each element appears multiple times across respondents in controlled permutations. Presenting these vignettes to respondents forces rapid, intuitive reactions rather than deliberative rationalization. The pattern of element combinations that elicit strong responses reveals how people mentally synthesize the situation from its parts. Mind Genomics therefore generates a map of which elements drive perception, urgency, intent, or preference in the synthesized scenario. This mapping preserves causal clarity because the experimental design treats elements as independent factors. The method makes explicit the common mind-sets people bring to the same situation, showing clusters of consistent responses. From these clusters, researchers can infer people’s implicit rules to combine facts into meaning. The result is a reproducible, empirically grounded synthesis of the situation as real people mentally construct it.
Applying the Approach to National Strategy—The Case of Israel and Hamas
The 15 different introductions to the Hamas-Israel situation, all crafted in a soft and non-judgmental way, sets the scene for the adding “meaning” or at least some “tonality” to the different descriptions of the elements, which are evaluated by respondents after being combined into vignettes according to an underlying experimental design. The soft description emphasizes situational facts, competing narratives, and the range of plausible civilian experiences without clearly endorsing any party [9-11].
To ensure broad coverage, the soft description highlights key dimensions such as security concerns, humanitarian impacts, territorial claims, and international reactions. The 15 different introductions function as experimental manipulation: small changes in wording can reveal whether framing shifts downstream evaluations.
The 15 Sets of Slightly Modified Instructions, Setting up Different Expectations
The study was run 15 times. The same elements were used for each of the 15 iterations. What changed was the introductions themselves, those that would be “read by the AI” as basic introduction to the issue. The objective was to determine whether changes in the orientation used at the start of the study would have any dramatic effects on the data. The only thing which changed from iteration to iteration was the specific introduction. Table 1 shows the introductions themselves. Table 2 shows a schematic of how the study’s orientation was systematically varied.
Table 1: The 15 different orientations. The orientation began with the basic introduction at the top of the table.
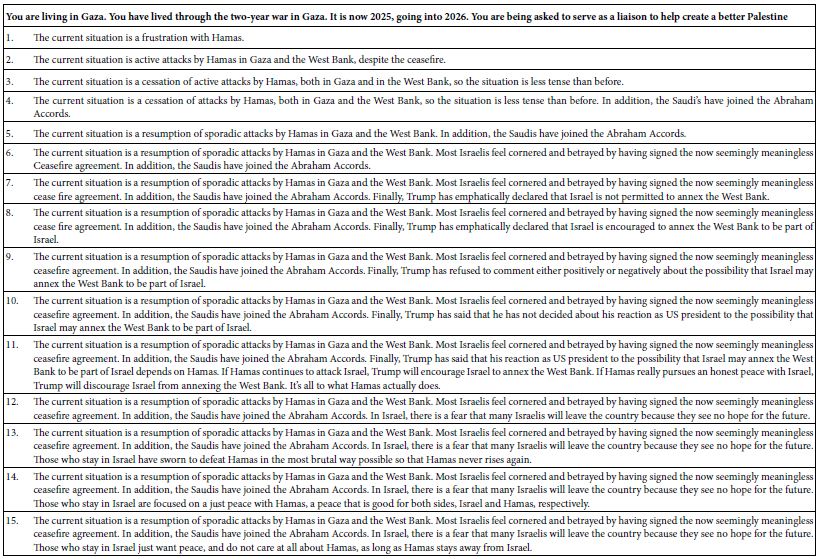
Table 3 presents the set of four questions or silos for the study, and the four answers or elements. When working with human respondents, the practice is to craft relative short answers, no more than 15 words or so. Beyond that, the respondent reports that it takes too much effort to read the vignettes. In contrast, when working with AI and synthetic respondents, preliminary efforts suggested that the data would be more precise when the answers are extensive, leaving little to interpret. Thus, the AI-generated answers or elements in Table 1 are longer than what would be the case were the respondents to be actual people. Such length provides a “tighter” specification of the information.
Table 2: Schematic of the differences in respondent orientation across the 15 “experiments.”
Creating Synthetic Respondents (Personas) by Combining Answers to Self-profiling Classification
Today’s research has taken a new turn with AI, and more specifically with synthetic respondents created by AI. These synthetic respondents are personas, generated from classification questions, the various answers to which lie at the basis of the persona. Today’s AI presumably can respond to test stimuli as if it were the persona. The study presented here used AI (ChatGPT 3.5) to create different personas, and then to have each created persona evaluate a complete set of 24 vignettes as if it were that person. The subsequent analysis is thus done on machines acting as a people, rather than as people themselves [12-14].
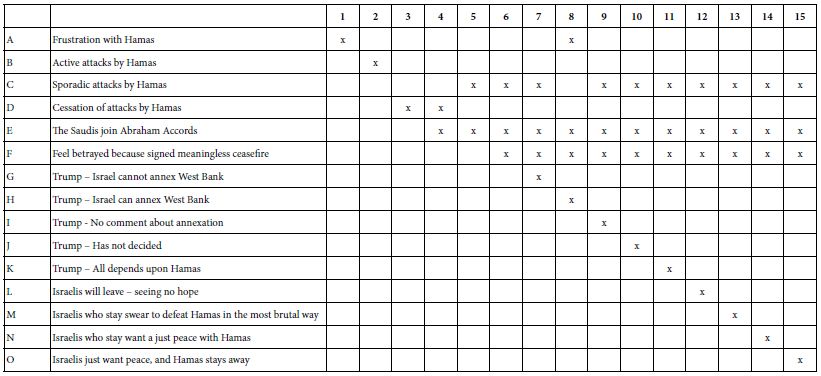
Table 3: The four questions and the four answers to each question generated by Idea Coach (ChatGPT 3.5 embedded in the Mind Genomics platform, BimiLeap.com).
Table 4 shows nine different self-profiling classification questions and answers selected by the researcher. In addition, the Mind Genomics platform automatically generates questions for age and for gender. Thus, after the analysis, the synthetic respondent—the persona—has 11 distinct statements about the respondent. It is these 11 statements of the persona used by AI to evaluate and then rate each test vignette.
Table 4: AI selected one of two genders, one of seven age groups, and one answer from each question below. The combination along with the appropriate introduction (out of 15) specified a “persona” which evaluated a vignette and assigned a rating.

Vignette Testing with Synthetic Personas
Each of the 15 experiments or studies comprised all elements and varying combinations of the groups formed from the answer in Table 3. Using an underlying experimental design, the Mind Genomics platform generated a set of 24 element combinations for each respondent. The experimental design was set up to ensure that each of the 16 elements would appear five times in 24 vignettes, that each vignette would have a minimum of two elements and a maximum of four elements, and that no vignette would ever have two elements from the same silo (viz., no vignette would ever have two different answers to the same question). Finally, each respondent would test a unique set of combinations or vignettes. The mathematical structure for each set of vignettes would be the same, but the specific combinations of elements would be different. This strategy is known as a permuted experimental design [15]. The permuted experimental design ensures that the data from each respondent can be analyzed separately using standard statistical methods, such as dummy-variable ordinary least squares (OLS) and clustering [16].
The synthetic respondent used a labelled 5-point scale to rate each vignette. Table 5 shows the scale. The scale has two sides. The first side addresses the expected response of the Gazans (do not want peace; do want peace). The second side addresses the publicly expressed desire for peace, whether from visionaries or from the public.
Table 5: The instructions for the rating scale and the 5-point rating scale.

Transforming the Ratings to Binary Dependent Variable (BDVs) to Prepare for Regression.
As it is constituted, the rating scale is an example of a nominal scale. The numbers themselves are just placeholders. To prepare for the analysis, the rating scale must be transformed. There are five key transformations shown in Table 6.
Table 6: The five key transformations to generate binary dependent variables (BDV), appropriate for analysis by ordinary least-squares (OLS) regression.

Table 7 shows the outcome from analyzing the full set of 180,000 “observations, created by AI. The numbers in the body are the coefficients for each of the four BDV’s developed by combining ratings, and then the five single BDV’s. The coefficients for the elements are “absolute” because the elements were combined by the underlying permuted experimental design. The design comprised “zero’s,” where an element would not appear, ensuring that the level of each of the 7500 synthetic respondents were statistically significant. In technical terms, the coefficients were estimated with a meaningful “zero condition.” Statistical modeling suggests that coefficients around 21 or higher are statistically significant. For these results, only two elements of the 16 approach significance (two diplomacy channels, hotline). Importantly, most of the elements do well, all with coefficients of 17 or higher. This type of result differs from what is often observed with real people, namely a longer “downwards” tail with more elements scoring in single digits and low teens. Our first conclusion is that where AI can synthesize respondents, the version used here—Chat GPT3.5—is too positive compared to what we observe with people.
Table 7: General model for 7500 simulated respondents. Strong performance is defined as a coefficient of 21 or higher for the coefficients for the 16 elements, and coefficients of 11 or higher for relative coefficients where the lowest scoring element ends up being the baseline.
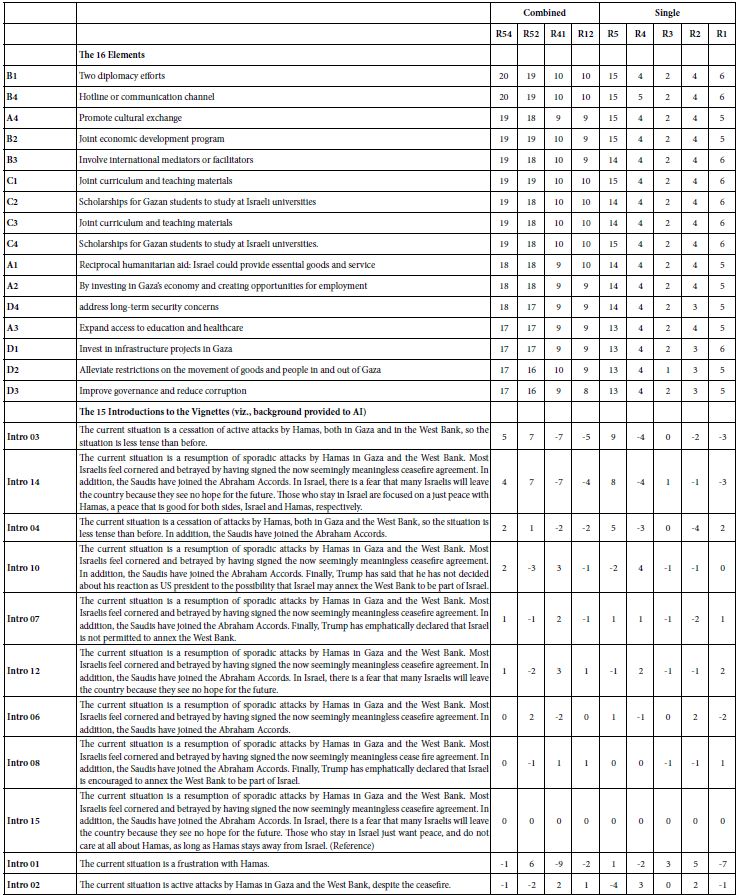
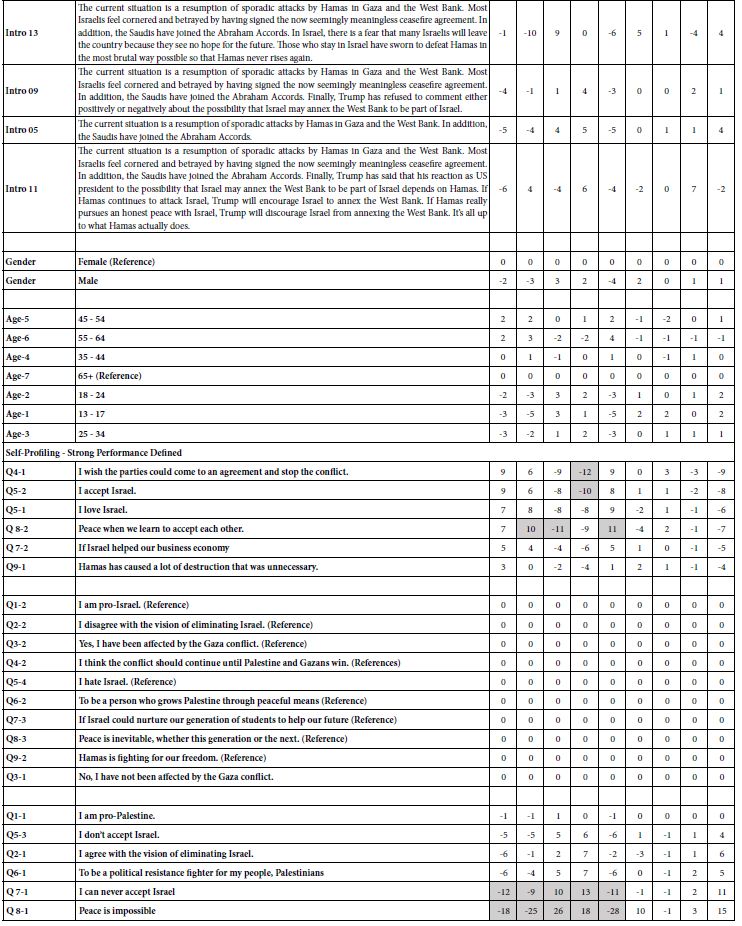
The second section of Table 7 shows the contribution of each of the 15 introductions to the coefficients. Keep in mind the AI was given the introduction. In the case of the introductions, each of the 15 studies had a different introduction. When OLS regression is used, we cannot estimate the absolute coefficient, since every study had an introduction. We must choose one of the introductions to be the baseline, with that baseline introduction removed from the regression. The researchers chose introduction 15. The data from the 15 introductions suggest that only introductions 3 and 14 drive a response from AI that the Gazans want peace.
When looking at the coefficients for the self-profiling questions, the strongest (most positive coefficients) and the weakest performers (most negative) make a great deal of sense. Different coefficients would have emerged had we chosen different elements to be the reference but the differences among pairs of products would have been the same. As a result, the conclusions would end up being the same, but the size of the coefficients would have differed. Self-profiling statements which accept Israel end up generating higher coefficients for R54 and for R5 than self-profiling statements which reject Israel.
An important consideration in this analysis concerns the nature of the coefficients for the self-profiling classification. In this study, the self-profiling options were not statistically independent. Thus, one of the classification options must be the reference. It does not matter which of the options serves as the reference. The reference ends up being omitted from the large linear regression, with the unhappy consequence that the coefficients for the self-profiling question are relative values. Differences of 11 or higher approach statistical significance.
How the Orientation to AI Affects the Distribution of Ratings
Table 8 shows a summary of the 15 “experiments” run with synthetic respondents. The rows correspond to the 15 different introductions. Table 8 shows two sets of data columns. The first set (R1-R5) shows the distribution of the five ratings (R1-R5), as well as the four binary combinations of ratings (R54, R21, R52, R41).
Table 8: Distribution of rating points by each introduction.
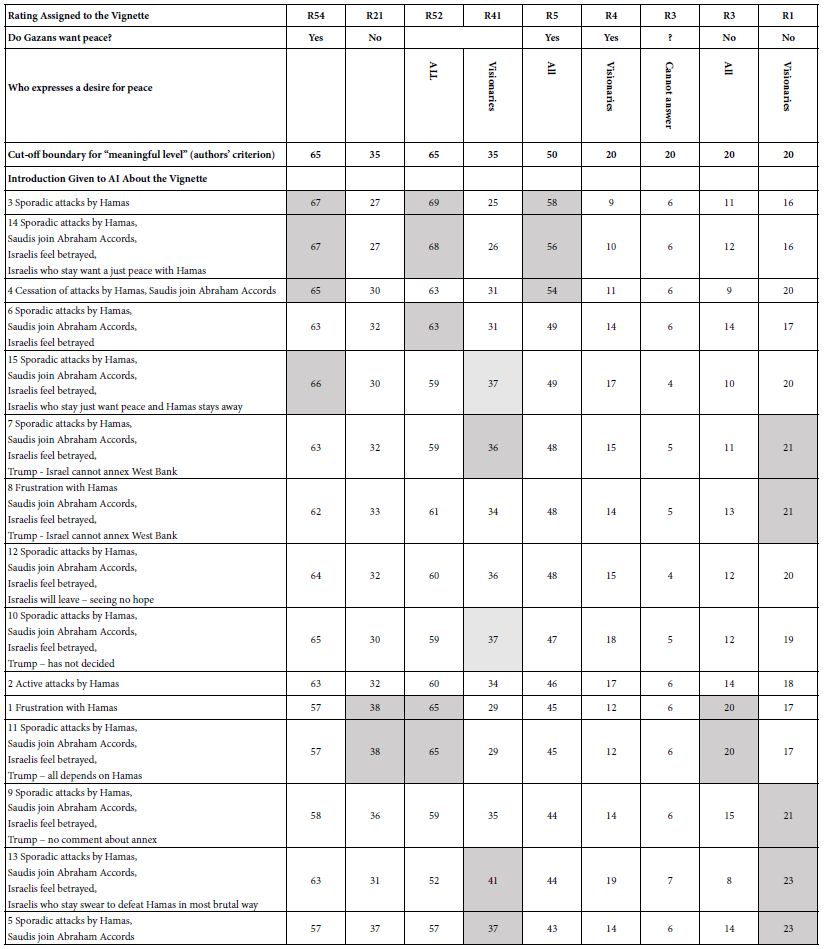
One important observation from Table 8 is the preponderance of positive responses, especially ratings of 5 but also ratings of 4. With human respondents, the percent of “5” on a similar 5-point labelled scale is much lower. Table 8 shows that R5, the most positive response, is selected more frequently than one might assume, given a negative introduction.
Our first observation from this detailed analysis of the effect of introduction is that AI is not as discerning as a human respondent. Simply stated, AI generates ratings that are more positive than the responses that would be obtained from actual people.
Additional insights regarding the contribution of the introductions emerge when we consider the coefficients of the 16 elements. Recall that the elements were created to follow an experimental design. This design allows the estimation of absolute coefficients for each respondent. The equation is a simple linear model: BDV = R54 = k1A1 +k2A2 … k16D4. This regression model can be done for each respondent, or for any defined subgroup of respondents. The analysis was run 15 times, once for each of the 15 introductions. Each regression analysis thus involved 16 independent variables, one for each element, and 12,000 rows of data, 24 rows for each of 500 respondents.
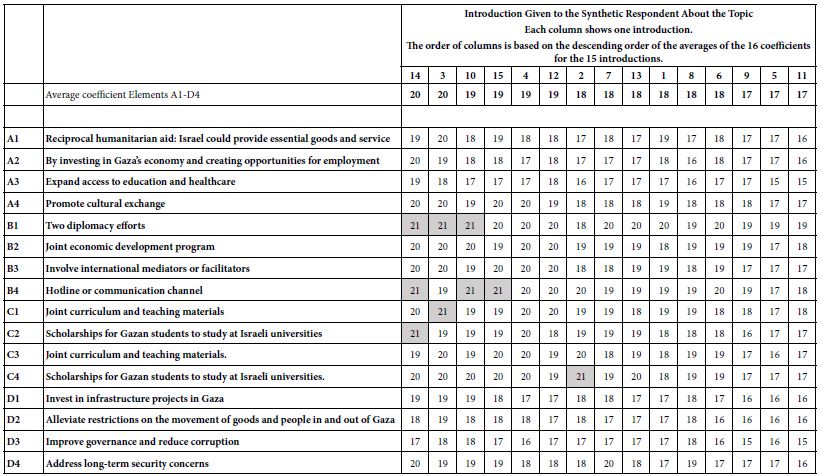
Table 9 shows the coefficients for each of the 16 elements for each of the 15 introductions. The study generates a total of 240 comparable coefficients. The coefficient gives a sense of how much of the BDV can be traced to the contribution of the element. Parallel analysis of modeling with an additive coefficient suggests statistical significance when the coefficient is 10. The element value of 10 estimated without an additive constant corresponds to a coefficient of 20-21 when the equation is 1estimated without an additive constant, viz. regression through the origin. The strong, statistically significant elements are shown in shaded cells.
Table 9: Performance of the 16 elements for each of the 15 introductions to the problem. The dependent variable is R54 (Gazans want peace).
Discussion and Conclusions
This approach provides practical and ethical benefits for the examination of contentious conflicts within a structured framework. This approach enables researchers to analyze the ways in which framing and message components interact to generate varying levels of support, opposition, or ambivalence, all while minimizing dependence on the often-chaotic nature of field debates. The approach allows organized comparisons among segments defined by specific personas, including a general panel, pro-Israel groups, pro-Palestinian groups, and those with mixed attitudes.
Using Mind Genomics coupled with AI simulation through synthetic respondents permits swift iterations. The happy outcome is that teams can explore many soft descriptions, adjust vignette components, and re-execute simulations. This process enables them to assess the robustness of their findings prior to engaging in expensive research involving human subjects.
This approach mitigates potential harm by situating potentially distressing content within a controlled synthetic testing environment, all the while ensuring that the personas remain anchored in empirical response patterns. This approach enhances interpretability by generating parameter estimates for each individual element and their interactions. Such estimates can be utilized by policy communicators and researchers to predict potential public responses effectively. Additionally, it aids in identifying which framings inadvertently enhance polarization, as opposed to those that promote thoughtful reconsideration and discussion.
This approach does not substitute for meticulous field validation using human samples; rather, it serves as a robust tool for triage and the generation of hypotheses. This approach serves as a responsible and evidence-based strategy aimed at exploring the ways in which contextual descriptions and individual orientations collaboratively influence responses to conflict narratives. In other words, the approach provides a new way to explain topics at “scale.”
References
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2006) Founding a new science: Mind genomics. Journal of Sensory Studies 21(3): 266-307. [crossref]
- Papajorgji P, Moskowitz H (2024) Mind Genomics: Origins, Evolution, Inner-Workings. In: The Mind of Everyday: Combining Individual and Artificial Intelligence. Dec 29 (pp. 91-143) Cham: Springer Nature Switzerland.
- Porretta S, Gere A, Radványi D, Moskowitz H (2019) Mind Genomics (Conjoint Analysis): The new concept research in the analysis of consumer behaviour and choice. Trends in Food Science & Technology 84: 29-33. [crossref]
- Ludtke A, editor (1995) The history of everyday life: Reconstructing historical experiences and ways of life. Princeton University Press; May 21. [crossref]
- Naukkarinen O, Vasquez R (2017) Creating and Experiencing the Everyday Through Daily Life. Experiencing the Everyday. May: 166-85.
- Moskowitz HR (2012) ‘Mind genomics’: The experimental, inductive science of the ordinary, and its application to aspects of food and feeding Physiology & Behavior 107(4): 606-13. [crossref]
- Papajorgji P, Moskowitz H (2024) Mind Genomics: Origins, Evolution, Inner-Workings. In: The Mind of Everyday: Combining Individual and Artificial Intelligence. Dec 29 (pp. 91-143) Cham: Springer Nature Switzerland.
- Kover A, Papajorgji P, Moskowitz H, editors (2022) Applying mind genomics to social sciences. IGI Global. May 13. [crossref]
- Atran S, Rodriguez-Gómez L, Yilmaz K, Gómez Á (2025) How Gaza Sees the 2023-2025 War and the Future of the Israel-Palestine Conflict. New England Journal of Public Policy 37(1): 11. [crossref]
- Segell G. Israel vs (2025) Hamas expands to eight fronts. InExploring the Implications of Local and Regional Conflicts. (pp. 1-26) IGI Global Scientific Publishing.
- Vitman Schorr A, Sasson Shoshan T, Govrin Y, Tokatly L, Kahlon D, Ghanem L, Dremer S, Plantonov V, Davidovich S, Lev-Wiesel R (2025) Is the Future Ours to See? Israelis’ Future Perception Following Hamas Massacre. Journal of Loss and Trauma. Apr 2: 1-27. [crossref]
- Bisbee J, Clinton JD, Dorff C, Kenkel B, Larson JM (2024) Synthetic replacements for human survey data? the perils of large language models. Political Analysis. Oct;32(4): 401-16. [crossref]
- Davidson T, Karell D (2025) Integrating Generative Artificial Intelligence into Social Science Research: Measurement, Prompting, and Simulation. Sociological Methods & Research. May 7: 00491241251339184. [crossref]
- Shrestha P, Krpan D, Koaik F, Schnider R, Sayess D, Binbaz MS (2024) Beyond WEIRD: Can synthetic survey participants substitute for humans in global policy research? Behavioral Science & Policy. Oct;10(2): 26-45.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies. Feb;25(1): 127-45. [crossref]
- Gofman A, Moskowitz HR, Bevolo M, Mets T (2010) Decoding consumer perceptions of premium products with rule‐developing experimentation. Journal of Consumer Marketing 27(5): 425-36. [crossref]