Abstract
In a Mind Genomics experiment, 101 respondents each evaluated unique sets of 24 vignettes pertaining to interactions with a medical professional concerning the personal experience with COVID-19. The focus was to determine which messages made the respondents feel “comfortable” communicating. The results suggest two clearly different mind-sets, those responsive and comfortable with communication about the “facts” of COVID-19, versus those comfortable with communication about emotional support of the patient. These two mind-sets transcend gender, age, and previous experience with COVID-19. A simulation of the same topic by AI revealed that AI picked up these two mind-sets but suggested even deeper subgroups within each mind-set. The paper shows the value of incorporating Mind Genomics and AI into the education of medical professionals to provide deeper knowledge of how to communicate with patients.
Keywords
Artificial Intelligence, COVID-19, Empathy in healthcare, Medical education, Mind Genomics, Patient communication
Introduction
Healthcare professionals can improve their communication skills with patients by actively listening, demonstrating empathy, using clear language, and adopting a patient-centered approach. By involving patients in decision-making processes, providing comprehensive information, and collaborating on treatment decisions, healthcare providers can build trust and rapport. Measurement of communication strategies can be done through patient surveys, feedback forms, focus groups, and patient outcomes data. Common barriers to effective communication include time constraints, language barriers, cultural differences, health literacy limitations, and emotional or psychological challenges. Addressing these barriers can lead to more effective patient-provider interactions and improved health outcomes.
Mind Genomics is an emerging science that studies how people behave and respond to different messages on important topics, such as COVID. This method helps experts understand what people like or dislike about certain messages and how they react in various situations. By using AI, healthcare workers can create personalized texts about COVID in the Mind Genomics app to see how comfortable patients are with them. This approach is based on facts and aims to help healthcare workers establish deeper connections and have more effective conversations with their patients.
Mind Genomics differentiates itself from standard consumer research techniques by taking a unique approach to gathering insights on consumer preferences. Instead of asking respondents to directly rate the importance of various aspects, Mind Genomics presents them with combinations of messages and analyzes their responses to determine the impact of each message. This method avoids forcing people to intellectualize and allows for a more natural, intuitive understanding of consumer preferences. Using statistical techniques such as regression modeling, Mind Genomics identifies which messages most strongly communicate the desired messages. The pattern of strong performing messages provides insights on consumer behavior and preferences, doing so in a fashion which is robust, rapid, and designed for exploration in areas that may be as yet “terra incognita,” viz., unknown lands. This approach not only improves patient satisfaction but also makes training medical professionals more effective by giving them real-world feedback on their messaging strategies.
Mind Genomics has been used in topic areas ranging from medicine (focus of the current paper), to food, law, social issues, and matters of the everyday). The methods have been explicated in a variety of papers [1-6]. This paper adds to the corpus of knowledge created by Mind Genomics, doing so with the focus on COVID, and specifically on the communication between patient and medical professional, e.g., doctor or nurse practitioner.
Step 1: Create the Raw Materials
The Mind Genomics technique asks the user to provide four questions, each with four answers. The four questions and four answers to each question were developed using AI, as discussed in the accompanying paper. Table 1 shows the four questions and four answers to each question (elements), generated by AI, but edited by the researchers to make the answers succinct and easy to understand. For each question and each answer, the AI was instructed to make the text 15 words or less, to write in the way people talk, and to make the text understandable to a 12-year-old.
Table 1: The four questions and the four answers to each question.

Step 2: Create the Test Stimuli
The test stimuli consist of message combinations from an experimental design. The experimental design specifies the combinations as follows:
- Each element appears five times in 24 vignettes and is absent from 19 vignettes.
- A vignette must contain at most one answer to a question.
- A vignette must have a minimum of two elements and a maximum of four This requirement means that in some cases a vignette does not have an element (answer) from one of the four questions, and in some other cases a vignette does not have an element from two or the four questions. This approach ensures that vignettes do not contain contradictory information from the same question.
- The 16 elements appear independently, enabling OLS regression to assess the strength of each element in driving the response.
- Each respondent assesses a distinct set of 24 A permutation scheme ensures uniqueness while preserving the mathematical properties of the experimental design, altering only the combinations. This leads to greater coverage of potential combinations. The permutation scheme allows research to explore various ideas and combinations, rather than relying on prior knowledge of what will work best. This shift from experimental confirmation to exploration is central to the Mind Genomics perspective [7].
Step 3: Execute the Study
Mind Genomics studies are conducted online through the BimiLeap.com platform. Luc.id, now Cint, supplies respondents based on user specifications. Participants were adults aged 25-54 living in the United States. Email invitations were sent to the respondents. Participants were directed to an orientation page about the study. The study was not labeled that way. The respondents were informed they would read a set of phrases and rate them as a single idea.
The orientation began with a self-profiling questionnaire that collected the respondent’s age and gender, followed by their answers to seven profile questions in Table 2. BimiLeap.com uses this information to form subgroups of respondents based on their self-identification.
Table 2: Self-profiling questions for classification questionnaire (top) and rating scale for the 24 vignettes (bottom).

The respondents did not receive extensive orientation. The goal was to show them the vignettes and capture their immediate reactions, without creating any expectations. This brief introduction is typical for most Mind Genomics studies, except those related to the law, where case background is pertinent. A brief introduction will suffice for most issues.
Step 4: Create the Database and Estimate the Regression Equation for the Total Panel
Each respondent assessed a unique set of 24 vignettes in random order. The respondent initially assessed vignette #1 as a training vignette. The rating for the first vignette was discarded. The respondent assessed all 24 vignettes. The 24th vignette was a repeat of the training vignette.
The respondent scored the vignette on a 5-point scale. The analysis focused on ratings 4 and 5, which indicate “patient feels comfortable with what the patient has heard.” They were transformed into a new binary variable, R54x. When the respondent rates a vignette a 4 or 5, R54x become 100. When the respondent rates a vignette 3, 2, or 1, R54x become 0. As a prophylactic measure to ensure some variation in the binary variable R54x (necessary for regression analysis) a tiny random number (<10-5) was added to the new binary variable.
The Mind Genomics platform recorded both the rating that the respondent assigned, then the transformed value (R54x), as well as the response time. The response time was the number of seconds (to the nearest 100th second) elapsing between the time the vignette appeared on the screen to the time that the respondent assigned a rating. Response times of 8 seconds or longer were automatically transformed to 8 seconds under the assumption that the respondent was multi-tasking.
The platform’s database included 2424 records, one for each vignette per respondent among 101 participants. Each record included a respondent ID, self-profiling data, vignette order in the 24-set, 16 columns for coding element absence, and the rating, response time, and transformed binary rating R54x.
For the OLS regression, the 16 columns for the elements were coded “1” if present in the vignette and “0” if absent. This is known as dummy coding. The coding indicates the predictor’s state: absent (0) or present (1).
The analysis occurs twice: first for groups, then for individuals. Groups are defined by the self-profiling questionnaire. All 24 vignettes from each respondent were compiled for analysis. The analysis involved the OLS regression without an additive constant, represented as: R54x = k1A1 + k2A2 … k16D4
The regression equation shows the impact of each factor. Parallel analyses showed at statistic of about 2.0 corresponding to a coefficient close to 11 in the regression model with an additive constant. The coefficient of 11 in a model or equation is equivalent to a coefficient of about 20 for a model without an additive constant, estimated on the same data. Given the foregoing argument, it appears that one could make an argument for coefficients of 21 or above as show strong performance when the model or equation is estimated without an additive constant
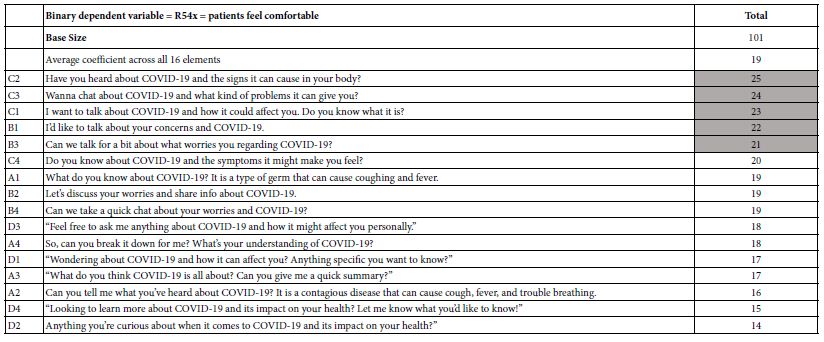
Table 3 presents the model parameters estimated for 101 respondents. Five elements are statistically significant (coefficient > 20), indicating that AI effectively generated strong, inspiring elements. These elements use informal language.
Table 3: Coefficients for the total panel for the equation relating R54x (comfortable) to the elements.
Step 5: Estimate Regression Equations for the Self-defined Subgroups
Recall that at the start of the Mind Genomics session the respondent completed a self-defining questionnaire, shown in Table 2. The regression analysis for each group comprising 10 or more respondents generates a great deal of data. In order to make the analysis easier, Table 4 (age, gender) and Table 5 (self-defined attitudes and behavior) show only those coefficients of 25 or higher.
Table 4: Coefficients for gender and for age for the equations relating R54x (comfortable) to the elements.

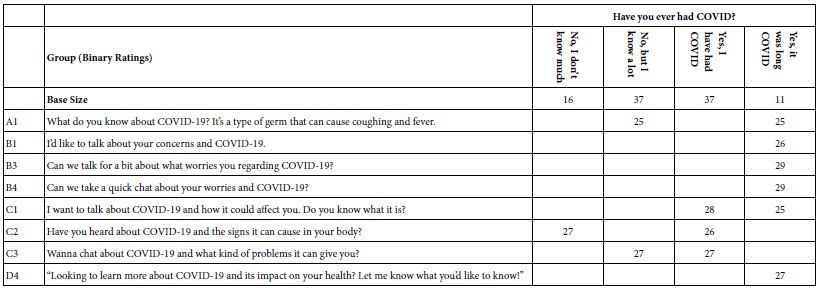
Table 4 shows only four strong performing elements, suggesting that if there are group differences, the groups are probably not defined by gender nor by age. Table 5 shows that the elements “resonate” for the 11 respondents who have defined themselves as having had Long COVID, but otherwise the pattern is once again elusive
Table 5: Coefficients for the four subsets of respondents based on COVID experience for the equation relating R54x (comfortable) to the elements.
Step 6: Create Mind-Sets by K-means Clustering
Variability among individuals derives from the “human condition,” which is the inescapable reality that people differ from each other on issues, even on the same issues of the world of everyday. Perhaps this variation is an intractable inconvenience? That would be acceptable, of course, and dealt with by oversampling people until the real average emerges out of the intractable variation. But what if this variation represents various ways of thinking about things, rather than random differences? What if there are basic distinctions in cognitive patterns that are not always related to a person’s identity or previous experiences?
A recurrent theme in Mind Genomics is that individuals vary in their daily lives but that this variation at the level of the everyday experience can be traced to mind-sets, patterns of thinking. The mind-sets emerge from the world of the granular and are descriptive rather than normative. The mind-sets “make sense” of the variation by showing that the variation can be generated by parsimonious set of groups. Furthermore, these groups are discoverable by simple studies such as the study presented here. Furthermore, one cannot always anticipate how a person would think based on their demographics, or even their actions. As of this writing (Winter 2024-2025), the mind- sets must be retrieved via an examination of reaction patterns to the vignettes. The method is simple: use the individual coefficients from a research, such as ours, to determine what individuals react to in terms of inspiration.
Reducing this tumultuous inter-person variety to well-behaved, explainable, parsimonious number of mind-sets is one way of using clustering—a well-accepted statistical procedure. Clustering reduces a seeming random cloud of different objects into a few interpretable groups, clusters, or mind-sets in the language of Mind Genomics. The processes are strictly mathematical, Mind Genomics uses k-means clustering [8]. People in a cluster think and respond similarly to the elements (viz., feel comfortable with the message as conveyed by the medical professional).
The particular strategy used by k-means clustering follows these simple steps:
- Using the data from the 24 vignettes evaluated by one respondent, compute the 16 coefficients which emerge from relating the binary dependent variable, inspire (R54x) to the 16 The equation is the same as that above, viz., R54x = k1A1 + k2A2… k16D4
- Although each respondent evaluated a different set of 24 vignettes, the original set-up ensured that each of the 101 respondents would evaluate a proper set of vignettes, permitting regression modeling at the level of the individual respondent.
- The result of the analysis is a matrix of 101 rows, one row per respondent, and 16 columns one column for each of the 16 The number in the cell is the coefficient for that respondent for the specific element.
- The k-means process computes the “distance,” D, between every pair of respondents, by the expression (1-R). The “R” is the Pearson linear correlation between two sets of When R is 1, the two sets of numbers are perfectly related to each other. In our case, this means that the two respondents react identically to the elements. The distance is 1-1 or 0. In contrast, when the two respondents are opposites, R = -1. The distance is (1- -1) or 2.
- The k-means algorithm puts the 101 respondents first into two groups, so that the distances of people in each group are small, but the distances of the two group centroids are large. Then the k-means algorithm does the same thing for three groups, and so forth.
- The process is entirely objective.
- Once the k means algorithm finishes, we end up with two and then with three We can create the equations for the two groups and then create the equations for the three groups. In each case, we look at the strong performing elements.
- The remaining effort moves from objective mathematics to subjective We want to make sure that we have easy- to-interpret clusters (interpretability) and as few clusters as possibility (parsimony)
- For this study, two clusters ended up providing the better Three clusters ended up having many of the same elements in common.
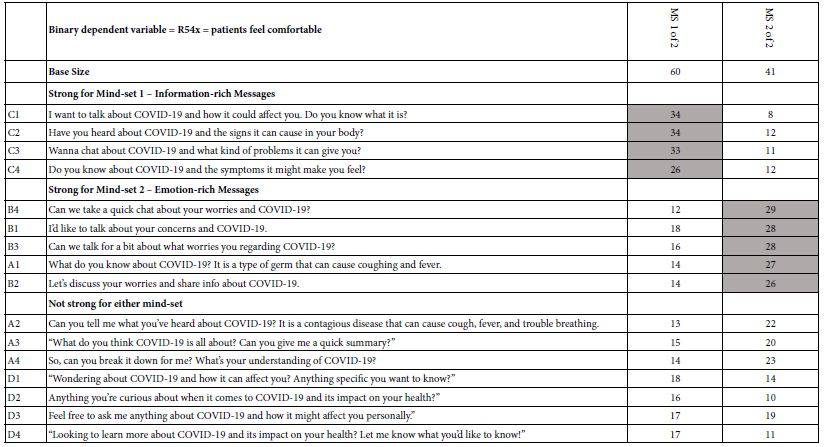
Table 6 compares the two mind-sets emerging from the k-means clustering. To make the patterns easier to distinguish, the tables show the very strong performing coefficients (25 and higher) in shade. The choice of a cut-off of 25 was made subjectively, to provide a way to distinguish between these two mind-sets. When we use this cut-off, we end up with Mind-Set 1 feeling comfortable by “information-rich messages,” and Mind-Set 2 feeling comfortable with “emotion-rich messages.”
Table 6: Coefficients of two mind-sets (MS1 of 2, MS 2 of 2) emerging from k-means clustering.
It is important to keep in mind that it would be impossible for the respondents to “game” the system. Each respondent saw 24 vignettes in rapid order, and essentially ended up judging each vignette intuitively. Yet, it is striking how clear the mind-sets are. The results of this study support the “insight productivity” emerging from the seemingly “impossible” Mind Genomics task of judging so many vignettes so rapidly.
Step 7: Estimate the Regression Models Using Response Time as the Dependent Variable
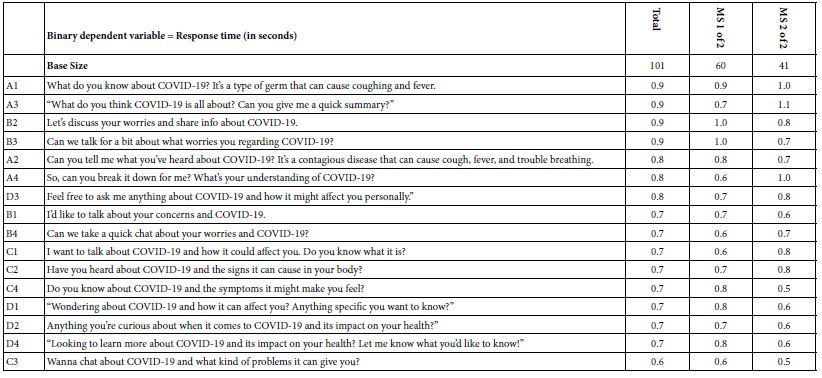
Table 7 shows the estimated number of seconds in the response time attributed to each element. The table shows three columns, one column for Total Panel, and then the two remaining columns for the two mind- sets. Long response times are operationally defined as 1.3 seconds or longer. Short response times are operationally defined as 0.3 seconds or shorter. The data suggests no response times meeting the criteria for “long response times.” The absence of long or short response times suggests a lack of deep interest in the topic of COVID-19 [9,10].
Table 7: Response times attributable to individual elements for the Total Panel and for the two mind-sets.
How AI Summarizes the Two Mind-Sets
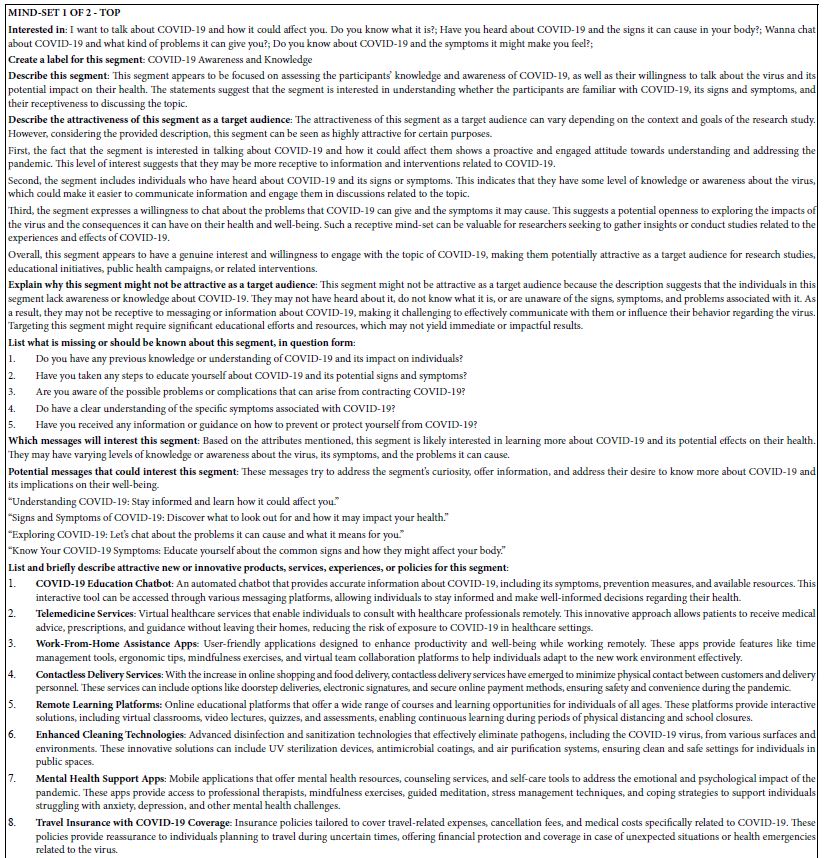
After the analysis is completed by the Mind Genomics platform, BimiLeap.com, the program is instructed to review the coefficients for each subgroup and answer a variety of prompts. Those prompts are based on the elements 21 or higher for the subgroup. Table 8 shows how the AI “summarizes” these subgroups.
Table 8: AI summarization of the two mind-sets.

What Would AI Have Uncovered Had It Been Prompted to Look for Mind-Sets?
Our final analysis returns to AI, to determine whether or not AI would have uncovered these mind-sets [11-13]. Table 9 (top) shows the instructions given to the AI. Table 9 (bottom) shows the five different mind-sets emerging from the AI, AI-generated Mind-Sets A and B are similar to the empirical Mind-Set 1, AI-generated Mind-Sets D and E are similar to the empirical Mind-Set 2, and AI-generated Mind-Set C is similar to both empirical mind-sets.
Table 9: Using AI to simulate possible mind-sets in the populations regarding communicating with the patient about COVID-19.

Discussion and Conclusions
Mind Genomics experiments improve medical communication by understanding patient mind-sets and preferences. By analyzing patterns in patient responses to different types of communication, healthcare professionals can tailor their approach to better meet individual needs. This personalized approach can lead to improved patient satisfaction, adherence to treatment plans, and overall health outcomes.
AI can further enhance the understanding of patient communication preferences by analyzing large amounts of data and identifying patterns that may not be immediately apparent to human researchers. By developing a corpus of knowledge based on Mind Genomics experiments, medical students and nurse practitioners can learn about the diverse mind-sets of patients and how to effectively communicate with them. This knowledge can help healthcare professionals provide more personalized care and support ongoing professional development.
The value of Mind Genomics experiments goes beyond improving patient satisfaction; it can also lead to better health outcomes. When patients feel heard, understood, and cared for, they are more likely to follow treatment plans and adhere to medical advice. By analyzing patterns in patient responses to different types of communication, healthcare providers can tailor their communication style to better connect with and engage their patients.
Incorporating the findings of Mind Genomics experiments into training can help young medical professionals develop the communication skills needed to excel in their clinical practice and provide more personalized care to their patients. Empathy plays a crucial role in effective communication between doctors and patients, as it allows them to understand and connect with their emotions, concerns, and perspectives.
Mind Genomics experiments can be used to enhance the communication skills and patient-centered care of organizations. By incorporating these findings into training and practice, healthcare providers can better understand patient communication preferences and tailor their communication strategies to meet their unique needs. This can lead to better patient understanding, adherence to treatment plans, and overall satisfaction with care.
Acknowledgment
The authors gratefully acknowledge the ongoing support and encouragement of Dr. Rizwan Hamid of the Global Healthcare Management Forum in Brooklyn. Dr. Hamid is a continuing source of encouragement for young medical professionals to create a more patient-focused, knowledge-driven healthcare system. The authors are grateful to Vanessa A. and Angela A. for their ongoing help in preparing these and other manuscripts for publication.
References
- Moskowitz HR, Porretta S, Silcher M (2008) Concept research in food product design and John Wiley & Sons. [crossref]
- Moskowitz HR, Reisner M, Lawlor JB, Deliza R (2009) Packaging research in food product design and development. John Wiley & Sons. [crossref]
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2012) Mind Genomics®: A Systematic Consumer Research. InRule Developing Experimentation: A Systematic Approach to Understand & Engineer the Consumer Mind. Bentham Science Publishers. [crossref]
- Moskowitz HR, Wren J, Papajorgji P (2020) Mind genomics and the Mauritius: LAP Lambert Academic Publishing. [crossref]
- Kornstein B, Rappaport S, Moskowitz H (2023) Communication styles regarding child obesity: investigation of a health and communication issue by a high school student researcher, using mind genomics and artificial intelligence. Mind Genom Stud Psychol Exp. [crossref]
- Mendoza CL, Mendoza CI, Braun M, Deitel Y, Rappaport S, et (2023) Empowering Young Researchers: Searching for What to Say to Young People to Avoid Becoming Obese. Endocrinol Diabetes Metab J. [crossref]
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint Journal of sensory studies. [crossref]
- Dubey A, Choubey AP (2017) A systematic review on k-means clustering Int J Sci Res Eng Technol (IJSRET, ISSN 2278–0882). [crossref]
- Azuma T, Van Orden GC (1997) Why SAFE is better than FAST: The relatedness of a word’s meanings affects lexical decision Journal of memory and language. [crossref]
- Chumbley JI, Balota DA (1984) A word’s meaning affects the decision in lexical Memory & Cognition. [crossref]
- Moskowitz HR, Rappaport SD, Saharan S, Wingert S, Anderson T, Mulvey T, Mulvey M (2024) Mind-Sets for Prescription Weight Loss Products That Are Advertised Directly to Consumers: Using Mind Genomics Thinking with AI for Synthesis and Acta Scientific Pharmaceutical Sciences (ISSN: 2581-5423). [crossref]
- Viswanathan S, Omidvar-Tehrani B, Renders JM (2022) What is Your Current Mindset?: Categories for a satisficing exploration of mobile point-of-interest InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. [crossref]
- Moskowitz HR, Rappaport SD, Saharan S, Mulvey T. Envisioning the World STEM Teaching Organisation: Combining AI with Mind Genomics to Map a Sustainable InNon-Profit Organisations, Volume III: Society, Sustainability and Accountability 2024 Aug 13 (pp. 151-175) Cham: Springer Nature Switzerland. [crossref]