Abstract
Four studies explored the subjective responses to text generated by AI versus text generated by a single individual. Each study focused on a topic (local pizza shop; local cleaner; local dentist; local school board). Each study comprised four sets of four elements each, viz., 16 elements, the elements being answers to simple questions pertaining to the topic. Each study comprised 30-31 respondents. The evaluation showed no decided advantage for AI generated information over human generated information when the rating was assigned on a simple 5-point Likert scale. The test process provides a way of inserting human evaluation into the text generated by people or by AI, and in turn opens up the potential of a standardized way to evaluate AI text using people.
Introduction
Today’s focus on hot new technologies must, by sheer popularity, include AI, artificial intelligence. AI is high on the Gartner hype cycle (Dedehayir & Steinert, 2016), perhaps due to it romanticized connotations as much to its performance. This paper is simply a study of how well AI can help a person think, or solve a problem, when AI is used as a ‘coaching device.’ At the same time this paper in being written in a time of ferment. Two decades ago Hill et. al., (2005), reported that “people communicated with the chatbot for longer durations (but with shorter messages) than they did with another human. Additionally, human–chatbot communication lacked much of the richness of vocabulary found in conversations among people and exhibited greater profanity. These results suggest that while human language skills transfer easily to human–chatbot communication, there are notable differences in the content and quality of such conversation”. The big story of 2022 is that AI has developed so quickly and powerfully that it is being used (or really misused) by students to write their college essays (Fyfe, 2022.).
The origins of this study come from three decades of work on systematic exploration of people’s responses to ideas, when these ideas are presented in combinations, in vignettes, with these vignettes created by experimental design. The origin of the work is the emerging science of Mind Genomics (Moskowitz et. al., 2012). Mind Genomics focuses on how people make decisions in the world of ordinary experience. The underlying approach of Mind Genomics is to choose a topic, then ask a set of four questions which present the topic in a story sequence, choose four answers to each question, creating 16 elements (element=answer). Finally, the Mind Genomics program (www.bimileap.com) creates combinations of these elements according to an underlying set of recipes, a so-called experimental design (Gofman & Moskowitz, 2010), presents these combinations to the respondent, obtains ratings, and uses regression analysis to deconstruct the responses into the contributions of the different elements.
The foregoing approach has been templated and is now easy to use. One recurring observation over the decades of use is that people simply freeze when they are instructed to create a set of four questions. That is, people may know how to answer questions, but again and again it is becoming clear that people don’t know how to frame questions. In other words, it may be that people simply don’t know how to think in a critical way, at least when critical thinking is defined in part as the ability to ask a set of coherent questions.
Introducing AI into Mind Genomics
Beginning around 2010, Mind Genomics was put on a path of developing a true DIY (do it yourself) system, with automatic set-up, automated recruiting using a panel company as a partner, and automated reporting. The effort finally materialized in 2017, with the set-up screens. The objective of the DIY was to have the researcher identify a topic for the study, then provide four questions, and finally four answers for each question.
Years of experience gave the authors the preparation to provide questions and answers with a fair degree of ease. It seemed to the authors that almost anyone should be able to think of four questions about a topic, but the authors were slowly disabused of that notion when users had to be ‘coached’, brought along, and only after the coaching and talking were the users comfortable. The unhappy reality was that the reluctance, or perhaps the real inability, to come up with questions was hindering the adoption of the Mind Genomics platform. Users simply abandoned the Mind Genomics effort, often after choosing a topic, and being confronted with what had seemed to be a perfect simple task of choosing questions.
During the many years of developing Mind Genomics, author HRM was asked many times whether the questions and answers could be put in somehow ‘automatically.’ The history of those questions would make an interesting article in itself, but the main thing to emerge was that people simply did not know how to think about topics in a critical way. Answering questions was very easy for people. In contrast, framing questions about a topic was off-putting. It seemed at first that people were being lazy, but the reality began to emerge that people were simply recognizing the need for a coach, for something to help them, preferably not a person.
The opportunity to create a ‘coaching’ system emerged during the middle of the past year, in 2022. At that time the Mind Genomics approach had become virtually a DIY system, as long as the respondent knew how to create the right questions, create the answers, create the orientation page, and the rating scale. The orientation page and rating scales were easy to learn and master. Creating questions and answers remained elusive, depending as much on the person’s confidence and topic-specific knowledge as it did on the person’s attitude towards these open ended explorations.
It would be the available of AI as an interface which provided the opportunity for enhancing Mind Genomics, perhaps removing the barrier of having to think of questions for a given topic. The underlying idea was to provide a ‘coaching mechanism’, effectively a device in which researchers could elaborate on a topic, with AI returning with up to 30 questions. The elaboration could be done several times, either with the same text or with different variations, until he researcher came up with questions which seemed relevant. Some or all of these questions could be selected, and ‘dropped’ into the question boxes. The researcher was free to edit the questions, and to provide questions that she or he wished to add, as long as the number of questions came to four. The second part of the coach allowed the researcher to select the coach, receive up to 15 answers to the question, and again repeat the process, selecting the best answers. The researcher could edit the answers, as well as incorporate her or his own answers.
It was the introduction of AI in this way, viz., as a coach, which reduced some of the hesitancy, making Mind Genomics more of a cut and paste operation in which the thinking was encouraged, but not made into a stumbling block. The researcher could be a child, even one eight years old or so. The fear factor of thinking was replaced by the excitement of the new information to appear, new questions to check, new answers to discover and select. The task became fun, at least to children. And, for adults, the delight may not have been so obvious, but the hesitation appeared to have been reduced, in some occasions dramatically.
AI Generated Ideas Versus Self-generated Ideas – Do They Differ in Quality?
The genesis of this paper emerged from ongoing conversations about the use of AI in studies. The question continue to emerge regarding the ‘quality’ of the ideas emerging from AI. The consumer researcher business continues to feature advertisements about AI in consumer research, although the underlying methods, viz. ‘under the hood’ are never revealed, nor are metrics. Yet despite the opacity of AI, the pattern is clear. It may only be a matter of time before AI catches up with the human being, and actually surpasses people (Grace et al. 2018). They write in stark terms that “AI will outperform humans in many activities in the next ten years, such as translating languages (by 2024), writing high-school essays (by 2026), driving a truck (by 2027), working in retail (by 2031), writing a bestselling book (by 2049), and working as a surgeon (by 2053). Researchers believe there is a 50% chance of AI outperforming humans in all tasks in 45 years and of automating all human jobs in 120 years “
A consequence of the popularity of AI, at least in the discussions among market researchers has led to the question of how one might measure the quality of ideas emerging from AI. Would the ideas be really better, producing insights that were the equal of good ideas produced by people, and hopefully better ideas? Or, when subject to standard researchers, such as Mind Genomics, would AI produced ideas perform worse than or equal to, but definitely not better than ideas of smart people. It was this last idea, head to head comparison to the performance of ideas generated by AI versus by people which gave rise to this paper.
Mind Genomics and the Head to Head Comparison of Ideas
Mind Genomics allows the researcher to measure the quality of the ideas, without anyone except the researcher knowing the source. The research project emerged as simple to do. In a few words, the idea was to choose a simple topic, and run the study exactly the same two times. The first time the researcher would create the study with no help at all. The second time the research would select the elements, the raw material, from Idea Coach. The same number of respondents would participate in the parallel studies, and the result compared in terms of performance.
There is no direct, absolute, non-subjective way to measure the quality of ideas. Thus, the ideas which emerge from one’s unaided efforts cannot be ‘objectively’ compared to the ideas which emerge from AI. AI may produce many more ideas, but on the basis of what can we assign values to these ideas? There is the old adage, a bit judgmental, and somewhat contemptuous, namely ‘GIGO, garbage in, garbage out.’ Given the prevalence of GIGO thinking, is possible to create a system to measure the value of ideas.
Mind Genomics may provide a solution to the above-mentioned problem. Keep in mind that there are two parts of the Mind Genomics exercise. The first part comes from the selection of the elements, whether from the person or from the combination of AI as the provider of the elements and the person as the selector of the elements. The second part comes from the evaluation of the elements, albeit combinations of elements, not single elements alone. The evaluation is one by real people who do not know how the elements were generated, rating each combination on a simple Likert scale, viz. an anchored scale. With this separation of idea generation from idea evaluation, it may be possible to measure the human subjective response to the ideas, and by so doing compare the performance of ideas generated by people to ideas generated by AI.
The Mind Genomics Process
Mind Genomics is an emerging science, focusing on the way people make decisions (REF). Mind Genomics grew out of a combination of three different disciplines; statistics, psychophysics, and consumer research, respectively. The underlying process has been documented a number of times (REF). In summary, the process follows these steps:
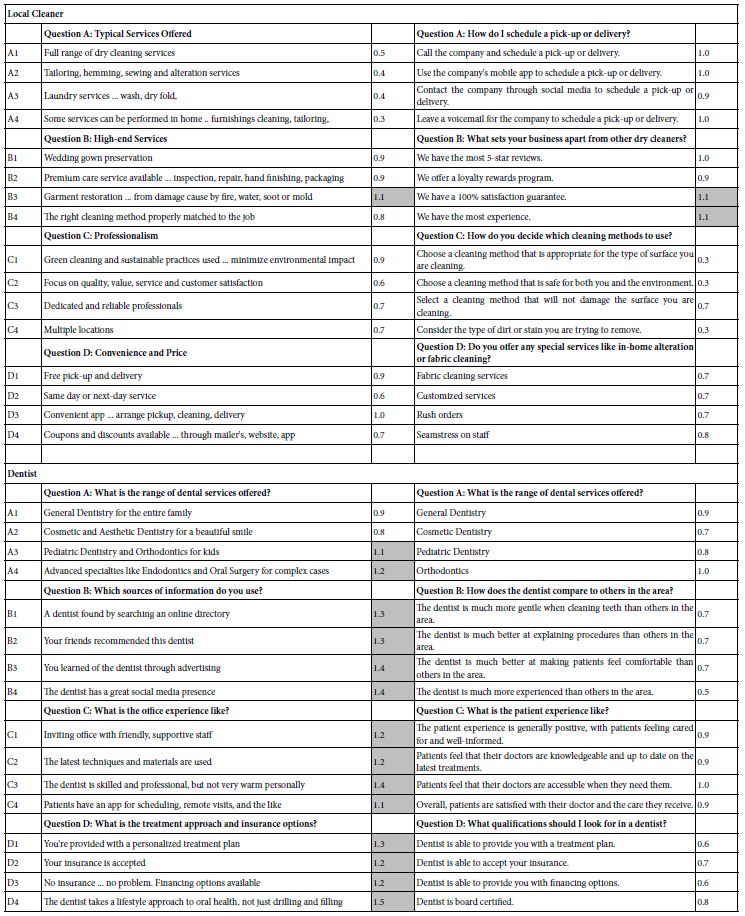
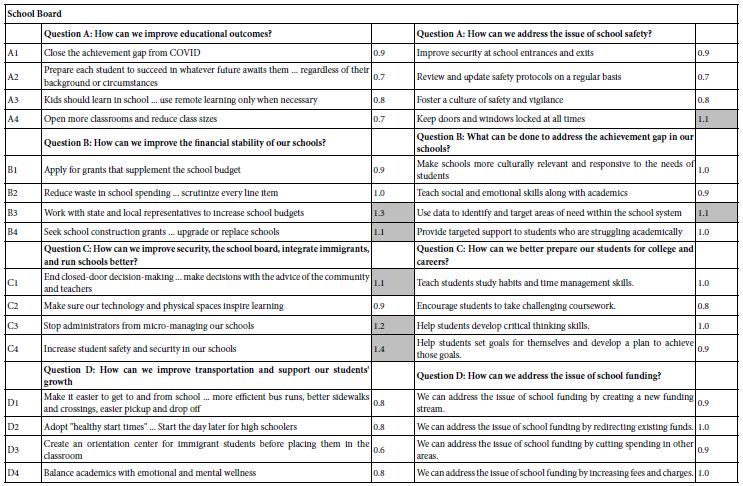
Step 1 – Define the topic, generate four questions, and for each question generate four answers. The term ‘element’ will be used instead of the term ‘answer.’ In effect, there are 16 elements in a Mind Genomics study. These questions and answers may be generated by the researcher, or may be generated using artificial intelligence. In this study, four of eight studies used questions and questions generated by the researcher, and the other four studies, with matching topics, used questions and answers generated by OpenAI’s language model “text-davinci-003” (https://beta.openai.com/docs/models/gpt-3).
The eight studies summarized in Table 1 were run with 30-31 respondents, all in the state of Connecticut, USA, with respondents aged 18-49 for the pizza studies, and 25-54 for the dry cleaner, dentist and school board candidate studies, respectively.
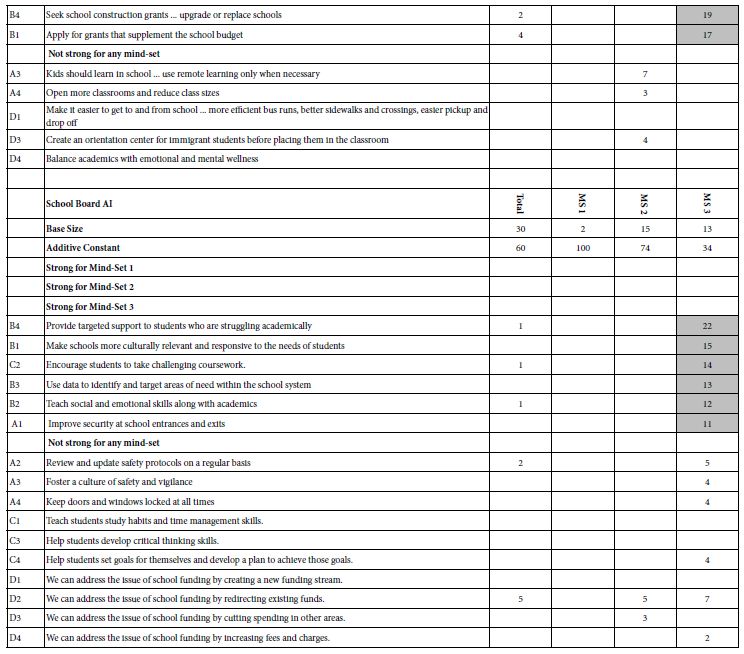
Table 1: Positive coefficients for the eight studies, showing the results for the Total panel, and for the three mind-sets extracted for each study. Strong performing elements for each study are shown in shaded cells.
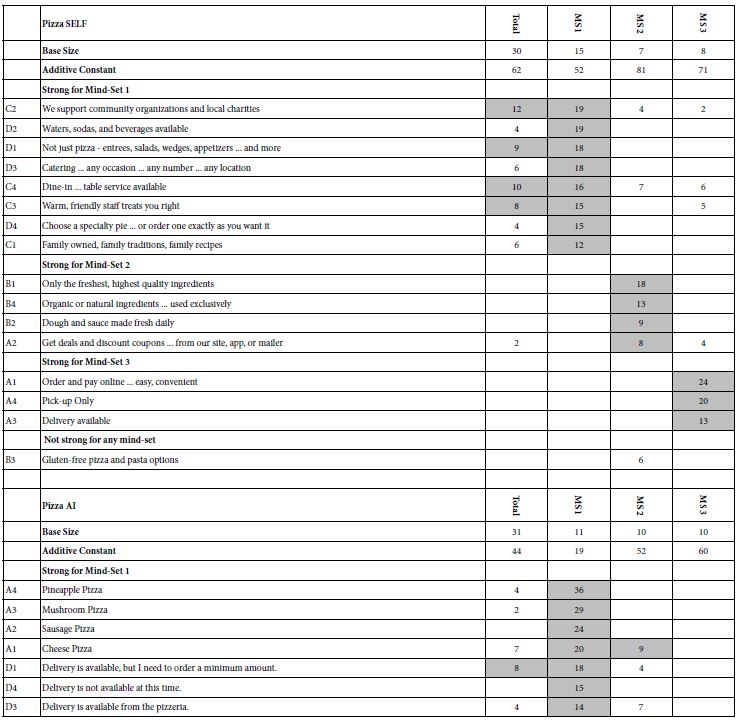
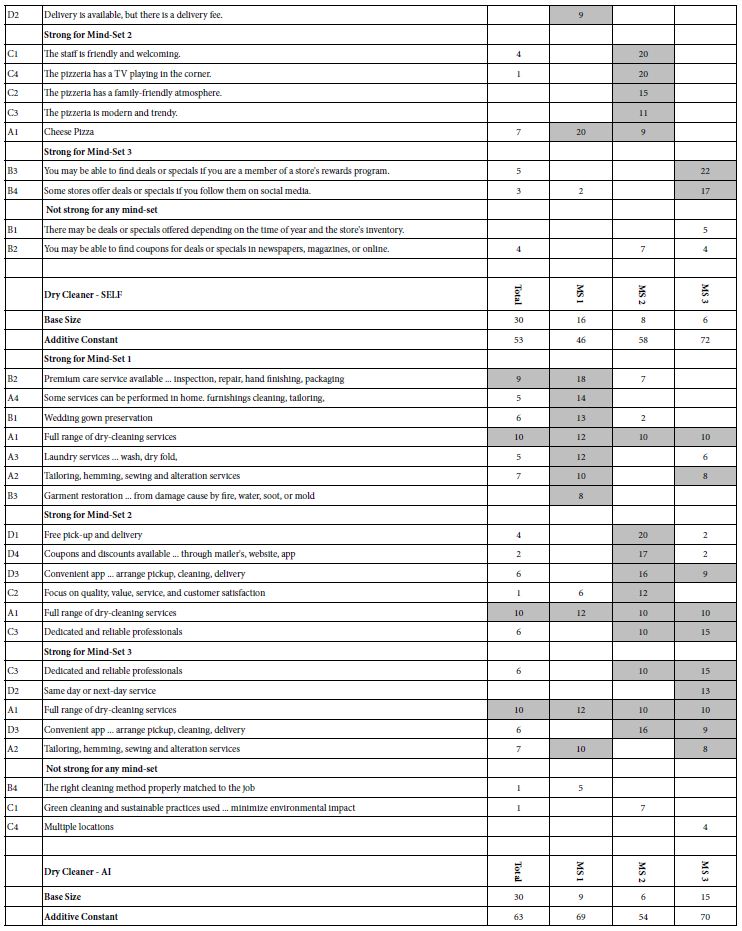
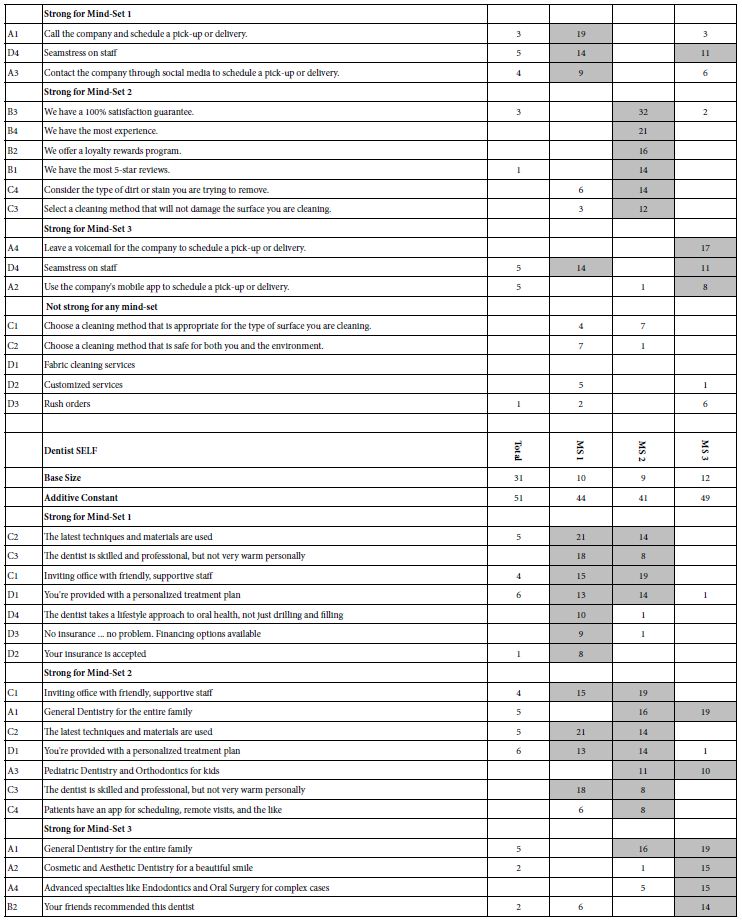
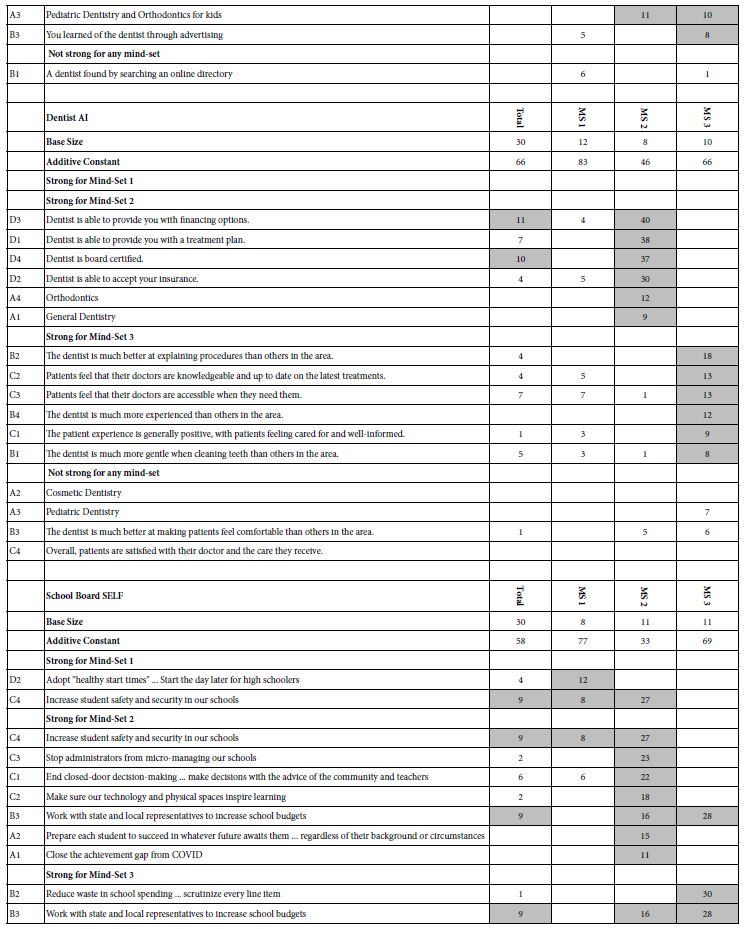
Each respondent was a member of an online panel, aggregated by Luc.id Inc. The respondents were invite to participate by an email sent only to panel members. The panels comprised more than several hundred thousand individuals for each panel company whose members were aggregated by Luc.id, making recruiting easy. Those respondents who agreed to participate read an introductory statement, completed a short self-profiling questionnaire, and evaluated a unique set of 24 vignettes, created according to an underlying experimental design (Gofman & Moskowitz, 2010). The respondents rated the vignette on an anchored 5-pooint scale, shown below.
The screen below describes a local pizzeria. Please indicate how likely you would be to patronize this pizzeria on a scale of 1-5. Although some screens may look alike, each one is different. Don’t dwell on them, just choose a number based on your gut reaction. 1=Not at all likely … 5=Extremely likely.
For each dentist described on this screen, please rate how likely you would be to choose this dentist. 1=Not at all likely … 5=Extremely likely.
You will be shown a series of screens. Each one describes a local dry cleaner. For each dry cleaner described on a screen, please rate how likely you would be to patronize this dry cleaner.
1=Not at all likely … 5=Extremely likely.
Based on the policy positions of the school board candidate below, how likely would you be to vote for this person? 1=Unlikely … 5=Extremely likely.
The analysis converted ratings 5 and 4 to 100, ratings 1-3 to 0, added a vanishingly small random number to each transformed number, used OLS (ordinary least-squares regression), and then clustered the respondents into two and then three mind-sets using k-means clustering. The OLS regression related the presence/absence of the 16 elements to the transformed rating scale, doing so at the level of each respondent. Each respondent ended up with an additive constant and 16 coefficients. The additive constant shows the basic level of interest in the topic (e.g., voting for a person for the school board) in the absence of elements, value that ends up becoming a baseline value since all vignettes comprised 2-4 elements (viz. answers) as dictated by the underlying experimental design.
The respondents were then divided first into two non-overlapping but exhaustive groups, and then into three non-overlapping but exhaustive groups based upon K-Means Clustering. The 16 coefficients were used as the basis for clustering, with the additive constant ignored for by the clustering algorithm.
Table 1 below divides into eight sections, one section for each of four topics, done twice. The two ways are done by the researcher alone, SELF using the AI Coach, the second way, AI, done by the researcher using the AI-powered Idea Coach. Table 1 shows the results for Total Panel and for three mind-sets, for each pair of studies One can get a sense of the richness of the ideas generated by the researcher (SELF) and generated by the researcher aided by AI in the form of Idea Coach.
A cursory look at Table 1 suggests similar performances by elements chosen by a person, first without AI (SELF), and later, at a separate time, with the help of AI (AI). There are no glaring patterns which emerge to tell us that AI-augmented efforts are dramatically stronger or weaker, when selected for the same topic, and evaluated by individuals are presented with a test protocol which prevents guessing what the underlying patterns might be. Only in one of the four studies do we see clear superiority, with elements for school board chosen by a person element performing far better than elements chosen by a person selecting from offerings of AI. This means AI does not offer up any better ideas than the ideas emerging from the individual himself.
Creating a Metric for Comparison – IDT (Index of Divergent Thinking)
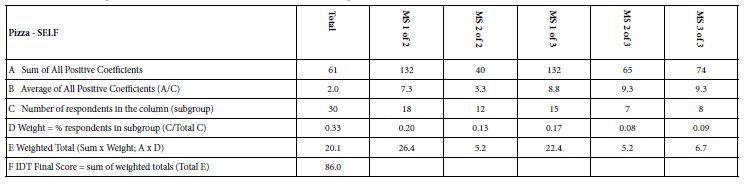
A different metric is called for, to compare the performance of the study. This metric has been used for Mind Genomics studies. Table 2 presents the computation for the IDT, index of divergent thinking. In simple terms, the IDT looks at the weighted sum of positive coefficients generated by the combination of the three major groups: total panel, both mind-sets in the two-mindset solution, all three mind-sets in the three mind-set solution. Each of these three components contributes an equal proportion to the final IDT. The approach makes sense because it is very difficult to generate a high coefficient for the total panel because the different people in the total panel cancel each other out. Thus, the total panel gets a weight of 33%. When it comes to two mind-sets, they also share a weight of 33%, so the two mind-sets compete for the 33%. Finally, when I come to three mind-sets, they also share a weight of 33%, so the three mind-sets compare for their 33%. Table 2 shows the computation.
Table 2: Computation of the IDT, the ‘Index of Divergent Thought’. The IDT provides a metric for the strength of the ideas using subjective judgments of the vignettes.
When the IDT is computed for the eight studies, the results give a sense of the subjective ‘strength’ of the elements, when ‘strength’ is operationally defined as strong performance on the rating attribute (viz., a preponderance of assigned ratings of 5 and 4 to the vignettes by a defined subgroup of respondents). Table 3 presents a comparison among the eight studies, the sum of positive coefficients for each of the key groups (total, two mind-sets, three mind-sets, respectively), then the IDT for the study.
Table 3: Key statistics from the eight studies
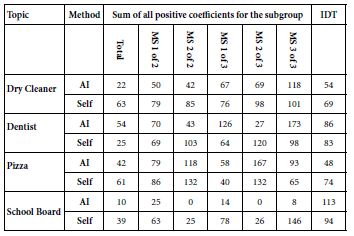
The important number in Table 3 is the IDT for virtually the same number of respondents across four pairs of matched studies, one study with four questions and four sets of four elements chosen completely by the researcher without any help from AI, and then afterwards the same selection, this time using only the questions and answers provided by the selected OpenAI language model and based only on a simple statement about the topic.
At this stage, we can say that the results are inconclusive. AI generates a much higher IDT value for school board (113 vs. 94, AI vs. Self), similar value for dentist (86 vs. 83), lower for dry cleaner (54 vs. 69) and much lower for pizza shop (48 vs. 74).
These initial results suggest that AI may perform better than Self generates messages for topics which are not ordinary, not daily (viz., dentist, and school board), but will probably perform more poorly for the more common topics (viz., dry cleaner, pizza shop). The respondents were matched in each study in terms of market and age, and the study was not identified as to origin of the elements. It may be that the differences could emerge from discrepancies in the base sizes of the two groups of emergent mind-sets (MS1 of 2 and MS2 of 2 vs. MS1 of 3, MS2 of 3, and MS3 of 3). If we just look at the Total Panel, using the Total of the positive coefficients, we find that only dentist data shows a stronger performance of AI generated elements versus self-generated elements.
Are AI Generated Elements More or Less ‘Engaging’ than Self-generated Elements?
Up to now the data strongly suggest that the current AI generated elements do not perform quite as well as the self-generated elements, although they do not perform poorly, at least when the judgment is cognitive. What happens, however when the metric comparing the two is non-cognitive, and often used by consumer researcher as well as experimenters in psychology and other disciplines’ course, we refer here to response time, a time-honored method in psychology and more recently in consumer research (Bassili & Fletcher, 1991).
The Mind Genomics program, BimiLeap, measures the time between the presentation of the test stimulus, the vignette, and the response to the stimulus, viz., the rating assigned by the respondent. The respondent need not do anything but read and respond. The time between the presentation of the vignette and the respondent, response time, become the dependent variable in a simple regression equation:
RT=k1A1 + k2A2… k16D4
The response time model does not have an additive constant, simply because the additive constant does not have any real meaning. The dependent variable, response time, is used in place of the 5-poont scale, either at the level of the group, or for other studies, at the level of the individual respondent.
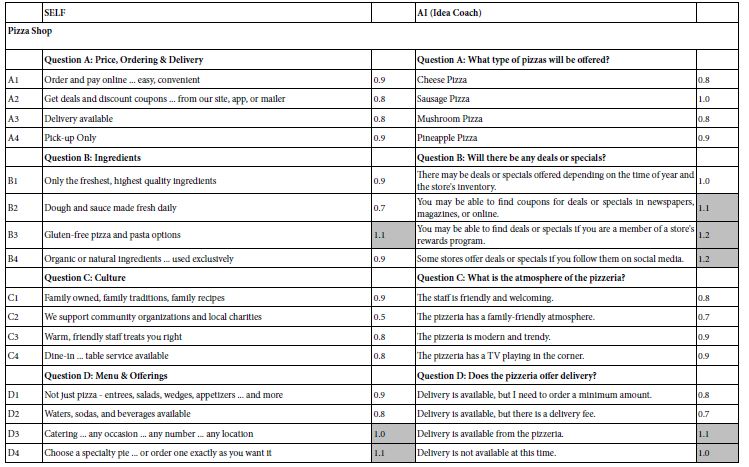
Table 4 shows the response time estimate for each element for all eight studies. The table shows the longer response times in shade. This paper does not evaluate the response time, but two opposite arguments can be made about the response time. The first argument is that the longer response times ‘engage’ the respondent to pay attention. The second argument is that the longer response times due to the fact that the message may take longer to read because the message is confusing, poorly written, or simply has mor words.
Table 4: Estimated response time for each element, estimated by Mind-Genomics
Discussions and Conclusions
The rapid emergence of ‘cognitively rich’ AI cannot be ignored. Newspaper articles discussing trends of AI point to the ability of widely available AI tools to create prose in a way which mimics that prose written by people who are capable writers, producing what could be called felicitous prose. Indeed, the topic of the growing potential of students to write college essays using AI is forcing a reevaluation of what it means for a student to learn to write, or indeed to get a liberal arts education. When the language generated by AI is sufficiently close to the language ‘ordinary people’ use, a new paradigm in called for in education.
The contribution of this paper is to introduce the human judge into the evaluation of snippets of information, viz., the elements produced either by people or by artificial intelligence. The Mind Genomics study does not focus on the coherence of the composition, viz., the ‘fitting together’ of the elements into a coordinated paragraph. Rather, the Mind Genomics effort in this paper is to understand the degree to which respondents feel about the individual texts, and to determine whether the elements generated by AI produces the same evaluation score of feeling as does the text of the same topic produced by a person.
If one were to summarize the findings of this paper, one would have to conclude that in terms of human judgment, the elements generated by AI may approach the quality of the elements generated by one’s mind alone, but only in one study out of four (school board) do we see AI performing better, presumably because people do not know about school boards in the way they know about pizza shops, dry cleaners, and dentists. Furthermore, the response time for elements are higher for elements created by the person, rather than by AI. This might be because the text elements created by the highly regarded AI used for the study (Zuccarelli 2020) were sensible, but bland and simply not as engaging yet as those written by a person.
References
- Bassili JN, Fletcher JF (1991) Response-time measurement in survey research a method for CATI and a new look at nonattitudes. Public Opinion Quarterly 55: 331-346. [crossref]
- Dedehayir O, Steinert M (2016) The hype cycle model: A review and future directions. Technological Forecasting and Social Change 108: 28-41. [crossref]
- Fyfe P (2022) How to cheat on your final paper: Assigning AI for student writing. AI & SOCIETY, pp.1-11. [crossref]
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145. [crossref]
- Grace K, Salvatier J, Dafoe A, Zhang B, Evans O (2018) When will AI exceed human performance? Evidence from AI experts. Journal of Artificial Intelligence Research 62: 729-754. [crossref]
- Hill J, Ford WR, Farreras IG (2015) Real conversations with artificial intelligence: A comparison between human–human online conversations and human–chatbot conversations. Computers in Human Behavior 49: 245-250. [crossref]
- Moskowitz HR (2012) ‘Mind genomics’: The experimental, inductive science of the ordinary, and its application to aspects of food and feeding. Physiology & Behavior 107: 606-613. [crossref]
- Zuccarelli, Eugenio (2020) GPT-3, OpenAI’s Revolution: Looking into the most powerful language model ever created, Towards Data Science, GPT-3, OpenAI’s Revolution. Looking into the implications of the… | by Eugenio Zuccarelli | Towards Data Science, accessed 20 December 2022. [crossref]