Abstract
We introduce a system to rapidly explore a topic, focusing both on the direct conscious judgment of information (cognition), and on the time it takes the mind to process the same information (neuroprocessing.) The system begins with the experimental design of easily constructed mixtures of messages. With human respondents, the system measures the cognitive response to these mixtures (ratings), and at the same time, the processing rate of these same mixtures (response-time to assign a rating.) The system is affordable and scalable, working with as few as 10 respondents to as many as several thousand. The outcome data reveal what messages are important, and the response-time to process these same messages. The analysis is virtually automatic, providing a simple, readily used new tool to study decision making. All the tools are standard, easily used by professionals and novices alike, with the results immediately presented in the format of data tables and a PowerPoint® report ready for distribution.
Introduction – the conflict between ‘objective’ and ‘subjective’ in experimental psychology
During the past seventy years, since the auspicious days of the 1950’s shortly after World War II, the field of experimental psychology has been deeply involved in the measurement of subjective experience. During the previous generations it was thought that people could not be accurate instruments to assess the magnitude of external stimuli, although they could react in ways which had desired effects on their life and on their environment. Many professionals believed that people could not act as valid measuring instruments, despite the fact that people could engineer their environment to exacting tolerances. Rather than focusing on the cognitive reactions to stimuli, many experimental psychologists felt that the more appropriate measures were non-cognitive, but rather autonomic nervous system reactions. These were assumed to be more ‘truthful.’ At the very simplest level were measures such as GSR (galvanic skin response), pupil dilation, and heart rate. The feeling was that these measures were more ‘objective indicators’ of one’s reactions to external stimuli, perhaps even better than attitudinal measures. Over time, however, researchers began to recognize that they needed people to respond to the world, using scales, in order to measure the private subjective experience that could otherwise not be measured. During the period, beginning in the 1920’s but accelerating dramatically after World War II, researchers created many different standardized scales in order to measure innate feelings and proclivities. These scales range from political conservatism to fear of new foods, just to give a sense of the range.
The nature of the ‘test stimulus’ – cognitively poor vs cognitively rich
One of the ongoing issues of these experiments is the artificial nature of the stimulus, and the limits of what can be learned. In most studied focusing on what can be learned by ‘objective measures.’ The respondents are presented with test stimuli, either of a meaningless nature in terms of cognition (e.g., lights), or of a modestly meaningful nature in terms of cognitions (e.g., pictures without a context.) It is vital to do so because the typical approach of the scientific method in virtually all fields requires that the researcher isolate the variable to as pure as possible and compare the response of the organism when the variable is present versus when the variable is absent. In this manner, the difference is ascribed to the variable being studied. In such manner one begins to understand the dynamics of the so-called objective measure.
In sum, then, the reactions of the subjects in task involving those cognitively poor stimuli are analyzed to uncover patterns, which help understand how people process information. It must be emphasized here that the knowledge gleaned is from the patterns, the regularities in the response, and not from the response to the individual test stimuli, which, in the real-world, are without any real meaning. It is the opinion of the authors that a new science of the Mind is needed, one which combines the rigor of scientific interventions with test stimuli having meaning. As we will see in the study reported here, quite a bit can be learned about the way people process meaningful information, using direct judgments to understand the process of conscious judging, and using measures of response-time to understand some of the underlying neurophysiological processes.
Mind Genomics – Learning from the reactions to cognitively rich test stimuli
Author HRM was educated as a sensory psychophysicist in the middle 1960’s, with experiments involving the sense of taste. The test stimuli were aqueous mixtures of water with a taste stimulus (e.g., sugar solutions of different concentration), or aqueous mixtures of water with two taste stimuli (e.g. sugar and salt, both dissolved in the same solution.) Sensory psychophysics showed the scientific community that one could learn a great about subjective sensory perceptions. In some extensions of the sensory work, Eugene Galanter pioneered the work in scaling the utility of money [1], and Stevens himself, father of modern psychophysics inspired the use of psychophysical scaling to measure the seriousness of crimes [2].
More relevant insights into the way we think emerged when the researchers began studying responses to combinations of ideas. The combinations of ideas, i.e., mixtures of message, constitute ideal stimuli, simple and inexpensive to create and to test with people. The mixture, in the words of psychologist William James, present a ‘blooming, buzzing confusion.’ The respondent must extract the relevant information quickly from the mixture, and assign a rating to that mixture. The underlying experimental design allows the researcher to estimate the contribution of each element in the mixture. These early studies suggested responses to combinations of messages, created by experimental design, could teach us a great deal about decision-making [3].
Once researchers recognized that they could learn about the respondent’s mind from deconstructing responses to compound mixtures, it was almost a natural step to create a science of decision-making. The science of Mind Genomics was born. Mind Genomics uses the analysis of responses to mixtures of ideas in order to understand the mind of consumers to all sorts of ideas, ranging from the law to religion, to products, and so forth [4, 5] When we combine cognitive measures such as conscious judgments about these mixtures of ideas with measures that reflect neurophysiological processing of information, an easy one being response-time (RT), we may well be able to glean new insights about the way we think. When the stimuli are cognitively rich, e.g., dealing with a meaningful and possibly interesting topic, and when the measures are both conscious ratings and so-called objective physical measures, there is the greater opportunity for patterns to emerge, patterns which would never appear when the stimuli are simplistic, boring, and relatively meaningless. The world of neurophysiological studies for consumer research is beginning to grow dramatically. This paper is part of that trend [6, 7].
Comparing judgments with the time needed to make those judgments
This paper compares the content of judgments with the time needed to make the judgments. The approach uses Mind Genomics, measuring both the response to the test combinations (vignettes), and the time needed to assign the response. The experiment goes deeper, in two ways. First, the analysis separately deconstructs the response (rating), and then the response-time, into the part-worth contribution of the elements, to determine how each element or messages ‘drives’ the responses. Second, the analysis creates two Mind-Sets for the respondents based on how the elements drive the ratings (clustering on cognitive judgments), and then a separate set of two Mind-Sets for the same respondents, this time based on how the elements drive the response-time (clustering on neurophysiological data.)
We present our approach, using a small, web-based experiment with 25 respondents, set up, executed, automatically analyzed, and automatically reported in a matter of 45 minutes. We deliberately keep the study small to see how much information and insight can be extracted from a simple, cost-effective effort. Our long-term objective is to lay the foundation to easy-to-do studies, combining cognitively meaningful stimuli, judged with relevant scales by ordinary people, with the co-variate of response-time measured at the same time. We attempt to demonstrate that Mind Genomics can make researchers out of almost anyone (scalability of use), can do so inexpensively, and can investigate almost any topic where the ‘mind is king.’
The steps for the process appear in Table 1, along with the rationale for each step
Table 1. The research process combining Mind Genomics and measures of response-time.
|
Step |
Action |
Explication |
|
1 |
The three goals |
Relevance: The topic is relevant to people. The topic is the 2018 conflict between the Russians and the Ukrainians. The study does not look for patterns using essentially meaningless test stimuli. Cognitively Meaningful: The topic is structured so that the individual test stimuli, the elements, are meaningful in and of themselves. The messages are stand-alone ideas. Controls: There is one ‘ringer,’ a stimulus message which reads like an element, but has no cognitive meaning. This element is A1: Russia declares Aaron the Ukraine |
|
2 |
Choose the topic |
The Russian – Ukrainian conflict of 2018. This is an interesting topic, involving the potential of a strong emotion from the anticipation of a possible war |
|
3 |
Choose the silos (questions) |
The silos or questions should ‘tell a story.’ The silos will not be presented to the respondents, but rather used to elicit different answers, the elements. It will be the elements that will be presented in the experiment. |
|
4 |
Choose the elements (answers) |
Select elements which make sense, but which need not have happened, but could have happened in the past, or could happen in the future. Couch every element as a ‘fact’ using a simple declarative statement. |
|
5 |
Specify the combinations (vignettes) |
The elements are combined by an experimental design. The design ensures that the 16 elements are represented equally, that they are statistically independent, and that each vignette comprises at most one element or answer from each silo. Each respondent evaluates a unique set of 24 vignettes, different from the 24 vignettes evaluated by other respondent. The uniqueness of each experimental design is guaranteed by a permutation strategy, which maintains the underlying mathematical structure, but changes the actual combinations. |
|
6 |
Choose an orientation page |
The orientation page tells the respondents relatively little. It presents the topic in one sentence, tells the respondents they will evaluate a set of vignettes, and instructs them to consider all the elements in a vignette as part of one idea. |
|
7 |
Choose the rating scale |
The rating scale is typically bipolar, comprising nine points, with the lowest and highest scale points anchored with descriptor terms. |
|
8 |
Invite the respondents |
Use a small, affordable base of respondents, obtained from a commercial company (e.g., Luc.id, Inc.), specializing in so-called e-panels. Use a sufficient number to obtain meaningful results, but a small enough number to afford many studies. The study here involves 25 respondents, sufficient to reveal patterns, both in direct judgment of what is read, and in response-time to make the judgment. |
|
9 |
Orient the respondents |
Respondents do not know what to do. The orientation page presents the name of the project, and instructions to read the entire vignette or combination as a single idea. |
|
10 |
Present 24 vignettes in a form easy to read |
The layout of the vignette is such that no effort is made to connect the different ideas. The design enables the respondent to ‘graze’ comfortably, rather than be encumbered by a set of connectives to be disentangled during the course of reading and comprehending. We are interested in presenting the respondent with a set of ideas which must battle among themselves to drive the respondent’s rating. We are not interested in adding an additional complexity to the already compound stimulus. |
|
11 |
Acquire ratings, measure response-time |
Rating scale: 1=Tension goes away … 9= War likely to break out |
|
12 |
Convert the ratings to binary |
Managers don’t understand the Likert rating scale. They respond to binary (no/yes). The scale is bifurcated. Ratings of 1–6 are converted to 0 to denote ‘no war likely’. Rates of 7–9 are converted to 100 to denote ‘war likely.’ A small random number (<10–5) is added to every binary value to ensure that the regression model can be estimated, even when a respondent confines the ratings, respectively, either to 1–6 (all transformed to 0), or to 7–9 (all transformed to 100.) |
|
13 |
Truncate the RT |
All response-times greater than 30 are brought to 30. These represent response-times which signal that the respondent interrupted the experiment to do something else. |
|
14 |
Build models (equations) using regression analysis |
Use OLS (ordinary least squares) regression to relate the presence/absence of the 16 elements to either the binary transformed ratings, or to the response-time, respectively. |
|
15 |
Segment respondents into two groups, Mind-Sets, doing so twice. |
On an individual-by-individual basis, relate the presence/absence of the elements to the binary transformed ratings or response-time, respectively. The modeling creates 16 coefficients for the binary transformed ratings, and another 16 coefficients for the response-time, respectively. Then, either for the binary transformed models or for the response-time models, cluster the respondents into two, complementary, non-overlapping groups, or mind-sets. The foregoing represents two clustering efforts, based first on the coefficients for the ratings, then based second on the coefficients for response-time. |
|
16 |
Assess the Mind-Sets |
Do the Mind-Sets ‘make sense’ |
|
17 |
Plot response-time versus rating |
Using the 16 coefficients, plot the coefficient for response-time (ordinate) against the coefficient for rating (binary, on the abscissa). Look for a relation between ‘meaning’ and response-time |
The study
The Russian- Ukrainian conflict of 2018, began some years back [8, 9]. The topic, a geo-political conflict, is meaningful in terms of everyday life, but not widely understood. Even when the respondents are not familiar with the topic, the test stimulus (vignette) presents sufficient information for the respondent to make judgments based upon what is presented, and based upon their own understanding of current events, whether deep or only superficial. Thus, the messages can talk about peace and war, as realistic, but rather ‘remote’ topics. Our comparison of cognitive measures (ratings) and neurophysiological measures, will make sense in terms of dealing with ‘real world’ issues.
Table 2 shows the set of four questions, and the four answers to each question. (Table 2) also shows the number of ‘key words’ (information) in each element.
Table 2. The four questions and the four answers to each question. The topic is the Russian Ukrainian conflict in 2018.
|
Questions and Answers |
|
|
Question A: What does Russia do? |
|
|
A1 |
Russia declares Aaron the Ukraine |
|
A2 |
Russia block the strait between Crimea and rest of Ukraine |
|
A3 |
Russia imposes economic sanctions on Ukraine |
|
A4 |
Russia show muscle in surrounding areas |
|
Question B: What do the Ukraine do? |
|
|
B1 |
Ukraine seeks help from NATO |
|
B2 |
Ukraine seeks help from the United States |
|
B3 |
Ukraine confiscates Russian property |
|
B4 |
Ukraine seeks military help from NATO |
|
Question C: What does the US do? |
|
|
C1 |
United States provides military help to Ukraine |
|
C2 |
United States block access of Russia to money |
|
C3 |
United States militarizes countries surrounding Russia |
|
C4 |
United States through President Trump makes its displeasure public |
|
Question D: What does NATO do? |
|
|
D1 |
NATO provides military forces |
|
D2 |
United Nations provides military force |
|
D3 |
United Nations brings Russia to the international court |
|
D4 |
NATO grants membership to countries surrounding Russia |
One of the key features of Mind Genomics is that it enables the researcher to use relatively few respondents for exploratory studies, such as the one reported here, or many respondents to define a topic area with a large, representative sample of respondents. The power of Mind Genomics, and its ability to work with few respondents, comes from the use of ‘permutable’ experimental designs, with each respondent presented with a full experimental design, different in combinations from the experimental design of the same material presented to another respondent [10] Thus, even with as few as 25 respondents, one can cover a wide space of 600 alternative combinations of messages, far more than most conjoint studies ever attempt to explore [11].
The respondent’s experience
The respondent reads each of the 24 vignettes, rating each vignette as a totality. The Mind Genomics APP (BimiLeap) records the rating and the response-time. (Figure 1) shows an example of the layout of the study on smartphone. The respondent can also participate with a personal computer or a tablet. There are biases in surveys. One of these biases is the desire of the respondent to please the researcher or the interviewer, by giving politically appropriate, non-confrontational answers to questions. This tendency to please the interviewer is promoted both by a personal interview, and by having questions on the interview which allow a person to slant her or his answers in the appropriate way. In contrast to the foregoing, Mind Genomics experiments are virtually impossible to ‘game.’ Mind Genomics experiments are done in the privacy of one’s home, on a computer, away from other people, so there is no interviewer bias. More importantly, however, Mind Genomics studies are impervious to the desire to be ‘politically correct.’ Test stimuli continually change, with ever-changing combinations appearing one after another.

Figure 1. Example of the respondent experience. The figure shows the presentation of a vignette on a respondent’s smartphone. The Mind Genomics study can be done using any device which can show websites, such as smartphones, personal computers, and tablets, respectively.
Results
A very simple first analysis computes the average rating, and the average response-time, respectively, for each of the 24 positions. Every respondent evaluated 24 unique vignettes. It is not the vignette itself which interests us, but rather whether there is a position effect. Figures 2A-2C show that there is no clear position effect for the average 9-point rating by position (Figure 2, left panel), nor for the average binary-transformed value by position (Figure 2, middle panel.) There is a clear position effect for the response-time, RT. The first position shows a higher average response-time, perhaps because the respondent is discovering what to do (Figure 2, right panel.) The strong position effect means that it will be more judicious to consider, where appropriate, the data without taking into account the first test vignette, i.e., the vignette in position #1.
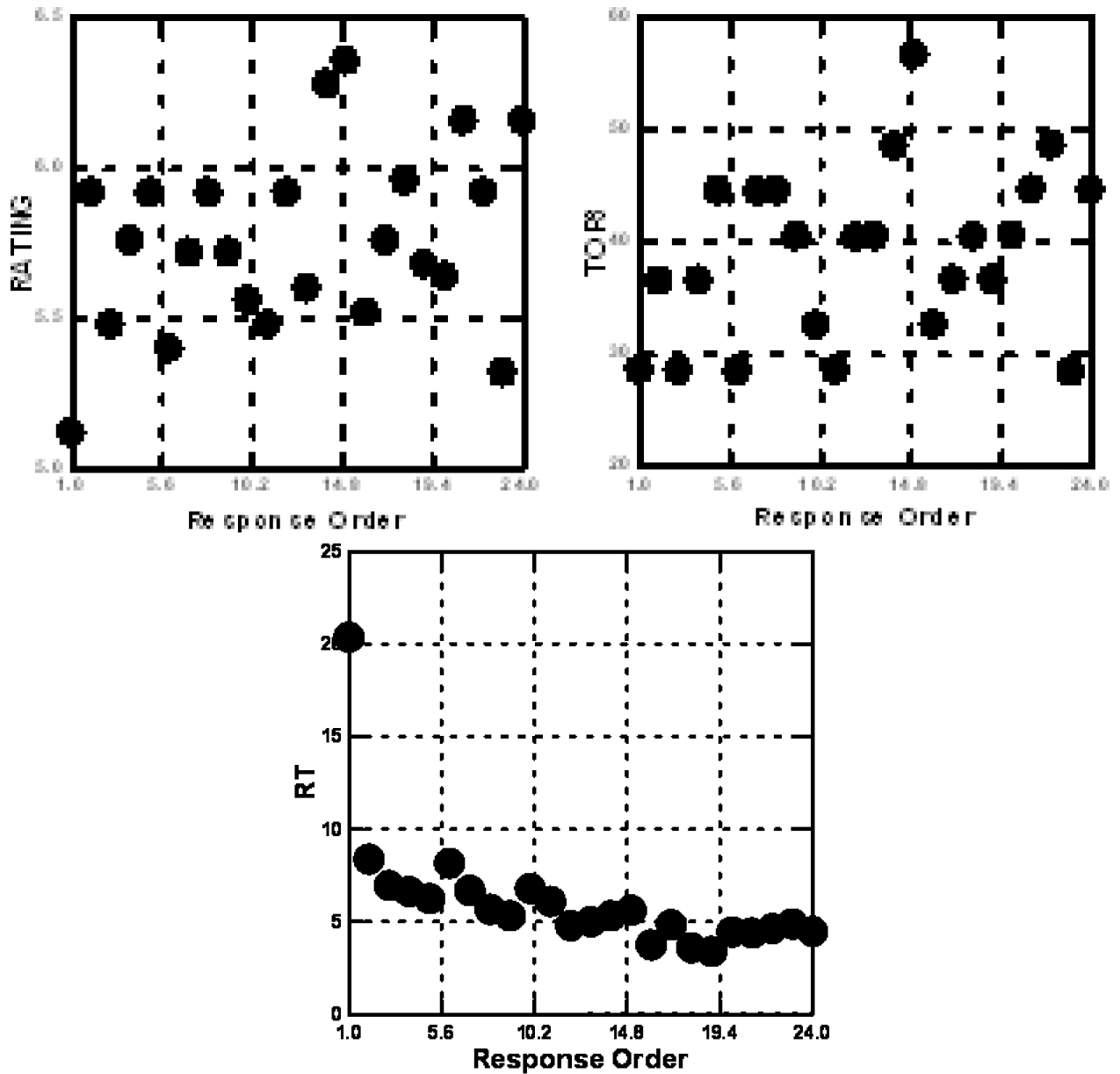
Figure 2. The covariation with response order of ratings of the 9-point scale (left panel), the binary transformed scale (middle panel), and the response-time (right panel.)
The deconstruction of the responses is done by OLS, ordinary least-squares. The independent variables are the presence/absence of the 16 elements or answers to the four questions. They take on the value ‘1’ when present in a vignette, or ‘0’ when absent. The dependent variables are either the binary values (0/100) after transformation of the original 9-point ratings, or the response-time in seconds, from the time the vignette appeared to the time that the respondent assigned a rating.
Clustering respondents on the basis of ratings of the elements
Clustering is a well-accepted method in statistics to divide objects by their patterns. The software is readily available [12]. The r clustering method is a matter of choice. The clustering used here computes a measure of ‘distance’ between each pair of respondents based upon the Pearson correlation between their corresponding 16 coefficients, one per element. The distance is expressed as (1-Pearson R.) When two respondents show a perfect linear relation, the Pearson R is +1 and the distance is 0. When two respondents show a perfect inverse relation, the Pearson R is -1 and the distance is 2.
Table 3 shows the results for the deconstruction of the binary values, for the total panel and for three mind-set segments emerging from clustering the respondents based on the set of 16 coefficients generated from the individual models. The dependent variable was always the respondent’s rating, either 0/100.
Table 3. Parameters of models relating the presence/absence of the 16 elements in vignettes to both the binary-transformed ratings (also called Top3), and to the response-time (RT). The table shows the results from the total panel and from two Mind-Sets (segments) emerging from clustering. The clustering was done based upon the coefficients for the ratings (binary transformed, Top3) of the 16 elements, from the 25 respondents.
|
|
Segment by Cognitive Response (Binary Transformed =Top3 Rating for ‘War’)
From Grand Model w/o Test Order #1 |
Top 3 – Total |
Top 3 – MS1 |
Top 3 – MS2 |
RT – Total |
RT – MS1 |
RT – MS2 |
|
|
Additive Constant |
25 |
27 |
21 |
|||
|
Top3Mind-Set 1: War if direct military action |
|||||||
|
C2 |
United States blocks access of Russia to money |
9 |
19 |
0 |
1.2 |
1.8 |
0.7 |
|
B1 |
Ukraine seeks help from NATO |
8 |
17 |
2 |
1.4 |
1.0 |
1.8 |
|
A4 |
Russia show muscle in surrounding areas |
3 |
11 |
-5 |
1.5 |
1.3 |
1.5 |
|
B3 |
Ukraine confiscates Russian property |
-2 |
9 |
-11 |
2.1 |
1.1 |
3.0 |
|
A2 |
Russia block the strait between Crimea and rest of Ukraine |
2 |
9 |
-5 |
2.2 |
1.8 |
2.6 |
|
Top3 Mind-Set 2: War if military build-up |
|||||||
|
C3 |
United States militarizes countries surround Russia |
8 |
1 |
15 |
1.1 |
1.8 |
0.6 |
|
C1 |
United States provides military help to Ukraine |
8 |
3 |
14 |
0.9 |
1.4 |
0.5 |
|
D1 |
NATO provides military forces |
8 |
4 |
13 |
1.1 |
1.1 |
1.0 |
|
D4 |
NATO grants membership to countries surrounding Russia |
7 |
3 |
13 |
1.3 |
1.0 |
1.5 |
|
D2 |
United Nations provides military force |
7 |
0 |
12 |
2.0 |
2.0 |
2.1 |
|
C4 |
United States through President Trump makes its displeasure public |
3 |
0 |
9 |
1.0 |
2.1 |
0.2 |
|
No clear perception of potential war |
|||||||
|
D3 |
United Nations brings Russia to the international court |
5 |
5 |
5 |
1.4 |
1.5 |
1.3 |
|
B2 |
Ukraine seeks help from the United States |
3 |
6 |
-1 |
2.3 |
1.7 |
2.7 |
|
A3 |
Russia imposes economic sanctions on Ukraine |
-1 |
-1 |
-1 |
1.8 |
1.6 |
1.8 |
|
A1 |
Russia declares Aaron the Ukraine |
-3 |
-4 |
-1 |
2.7 |
1.4 |
3.6 |
|
B4 |
Ukraine seeks military help from NATO |
2 |
8 |
-2 |
1.8 |
1.0 |
2.5 |
After clustering to reveal the two pairs of Mind-Sets, each respondent was assigned to the appropriate Mind-Set for the binary rating, and the appropriate Mind-Set for Response Time. For all models, the data from the first vignette (Response Order 1) was discarded. Then, the first vignette tested by each respondent was eliminated from the data set, and OLS regression was run on all the data from all the respondents in the particular Mind-Set. This is the so-called Grand Model. The analysis thus generated four Grand Models.
Table 3 shows the parameters of the Grand Models created from the group data (Total Panel, Respondents in MS1, and Respondents in MS2). The first three columns of data show the coefficients from the binary models (called Top3). The second three columns of data show the coefficients from the response-time (RT) models for the same respondents, segmented using their ratings of the vignettes.
It is clear that there are two Mind-Sets, based on clustering respondents according to their ratings of perceived likelihood of war. Mind-Set 1 feels that war will break out if there is direct military action. Mind-Set 2 feels that war will break out if there is an arms build-up.
Associated with each of these elements is also a response-time measure. Those response times of two seconds or longer are shown in bold and shaded. These are elements which ‘stop’ the respondent, engaging the respondent. We do not know whether the respondent could verbalize that these particular elements are engaging, but the regression analysis deconstructs the response time into the contribution of these elements (Table 3).
The response-time data become more interesting when the response-time coefficient is plotted against the binary-transformed or Top3 coefficient, either for the total panel, or for the Mind-Sets. (Figure 3) shows a clear pattern for total panel, as well as for the two Mind-Sets. As the perception of ‘likelihood of war’ increases (abscissa) the response-time of the element diminishes. For this cognitively relevant task, evaluation of the likelihood of war, we see a definite pattern relating a neurophysiological-based measure, response-time, to a judgment criterion, likelihood of war. The more likely the sense of ‘war’ breaking out, the faster the response time, when the plot is at the level of the 16 individual elements. In other experiments by author HRM, dealing not with critical events but with ordinary products, like yogurt, this straightforward pattern does not emerge (see appendix to this paper).
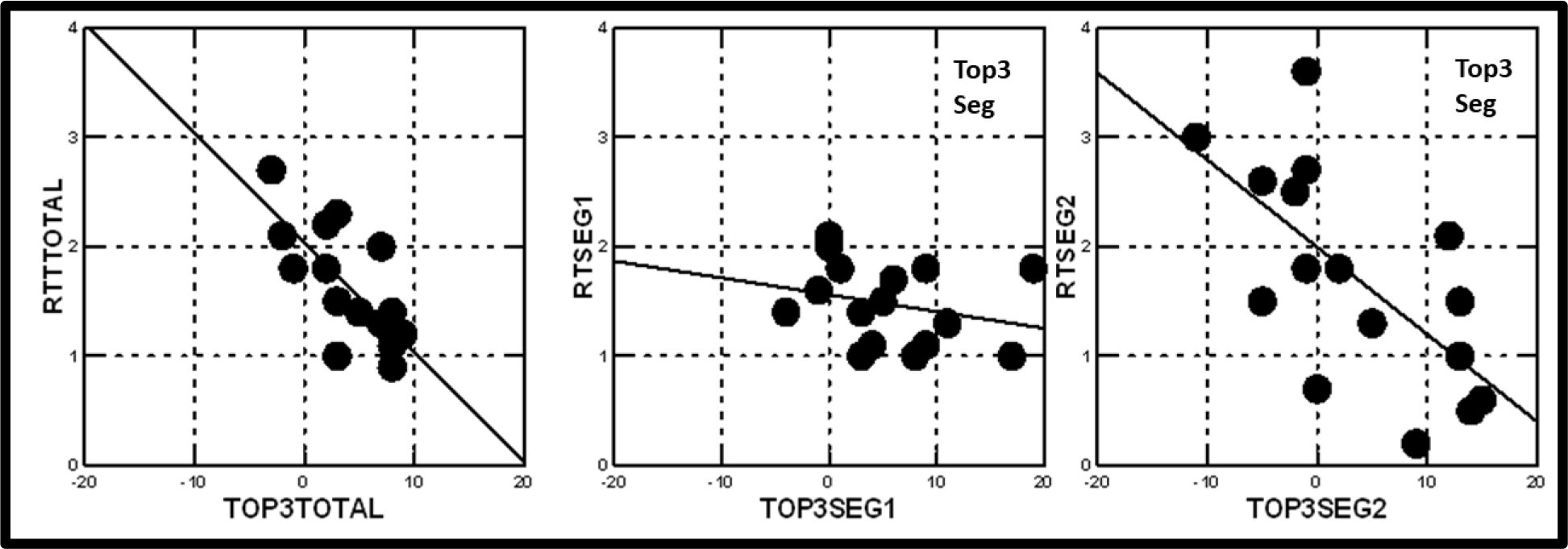
Figure 3. The relation between the coefficient for response-time (RT) for the element (ordinate) and the coefficient of the same element from the model for ‘likelihood of war’ (abscissa.) The Mind-Set segments, MS1 and MS2 were obtained by segmenting the 25 respondents based upon the coefficient for Top3, the binary-transformed response of the rating scale.
Does segmentation on the basis of response-time produce meaningful patterns?
Just as one may cluster the respondents based on their judgments of what they perceived to drive the likelihood of war, so one may cluster the same respondents on the pattern of what drives response-times. The mechanics of clustering remain the same. The only differences are the nature of the models, and the interpretation of the meaning of the segmentation.
The clustering process begins by building a model for each respondent, using all 24 vignettes, despite the bias encountered with the first vignette. There is no other option. Each respondent generates a pattern of 16 coefficients, which can be divided into two (or more) clusters. Table 4 shows the parameters of the models for the 16 elements, for models using as the dependent measure response-time (first three data columns), and the binary transformed rating (Top 3, second three data columns.)
Table 4. Parameters of models relating the presence/absence of the 16 elements in vignettes to both the binary-transformed ratings (also called Top3), and to the response-time (RT). The table shows the results from the total panel and from two Mind-Sets (segments) emerging from clustering. The clustering was done based upon the coefficients for response-time of the 16 elements, from the 25 respondents.
|
Segmented by Response-time
From Grand Model w/o Vignettes in Test Order #1 |
RT Total |
RT MS1 |
RT MS1 |
Top3 Total |
Top3 MS1 |
Top3 MS2 |
|
|
|
Additive constant – |
NA |
NA |
NA |
25 |
35 |
15 |
|
RT Mind Set 1 – Engaged the image of third forces coming into the fray |
|||||||
|
D2 |
United Nations provides military force |
4.1 |
7.7 |
1.2 |
7 |
0 |
13 |
|
A1 |
Russia declares Aaron the Ukraine |
5.0 |
6.9 |
2.6 |
-3 |
-16 |
8 |
|
B2 |
Ukraine seeks help from the United States |
4.6 |
6.3 |
3.3 |
3 |
-8 |
14 |
|
RT Mind Set 2 – Engaged by reading about description of actions |
|||||||
|
A2 |
Russia block the strait between Crimea and rest of Ukraine |
3.0 |
2.2 |
3.5 |
2 |
-14 |
14 |
|
B3 |
Ukraine confiscates Russian property |
2.3 |
2.0 |
2.6 |
-2 |
-14 |
9 |
|
C2 |
United States block access of Russia to money |
-0.7 |
-4.4 |
2.6 |
9 |
14 |
6 |
|
C4 |
United States through President Trump makes its displeasure public |
-0.9 |
-4.9 |
2.5 |
3 |
-3 |
5 |
|
C3 |
United States militarizes countries surround Russia |
-0.6 |
-3.8 |
2.4 |
8 |
3 |
11 |
|
B4 |
Ukraine seeks military help from NATO |
1.9 |
1.5 |
2.2 |
2 |
-7 |
10 |
|
A4 |
Russia show muscle in surrounding areas |
1.9 |
1.7 |
2.0 |
3 |
-11 |
15 |
|
Not strongly engaging |
|||||||
|
A3 |
Russia imposes economic sanctions on Ukraine |
2.2 |
2.3 |
1.9 |
-1 |
-11 |
10 |
|
B1 |
Ukraine seeks help from NATO |
1.5 |
1.1 |
1.5 |
8 |
1 |
15 |
|
D4 |
NATO grants membership to countries surrounding Russia |
1.4 |
1.8 |
1.4 |
7 |
2 |
14 |
|
D1 |
NATO provides military forces |
1.4 |
1.7 |
1.3 |
8 |
5 |
12 |
|
D3 |
United Nations brings Russia to the international court |
1.5 |
1.4 |
1.2 |
5 |
-5 |
12 |
|
C1 |
United States provides military help to Ukraine |
-1.1 |
-3.7 |
1.2 |
8 |
14 |
1 |
In order to assess the ‘meaningfulness’ of the segmentation based on response-time, it is necessary to look at the nature of the clusters in terms of what is responded to most rapidly. It appears that the words ‘United States’ drive the fastest response for Mind-Set1, and the words’ United Nations’ and ‘NATO;’ drive the fastest response for Mind-Set2.
It might well be that the segmentation and clustering on the basis of cognitive responses identify group differences due to ‘ideas’, whereas segmentation and clustering on the basis of response-time identify group differences due to specific ‘words.’ Finally, Figure 4 shows the relation between the coefficient for response-time for the element (ordinate) and the coefficient from the model for ‘likelihood of war.’ This time the Mind-Set segments MS1 and MS2 come from the segmentation by response-time. Mind-Set 1 in (Figure 4), focusing on the search for words, shows a clear relation between response-time and belief that war will break out. Mind-Set 2 in Figure 2 shows no such relation (Table 4).
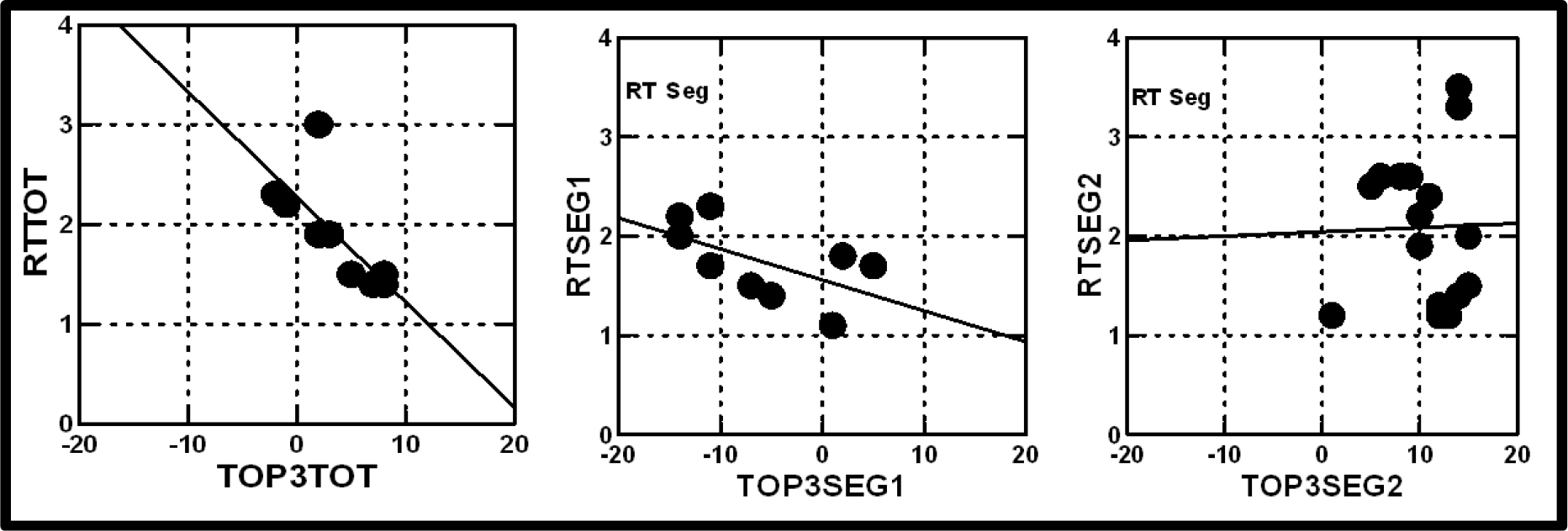
Figure 4. The relation between the coefficient for response-time (RT) for the element (ordinate) and the coefficient of the same element from the model for ‘likelihood of war’ (ordinate.) The Mind-Set segments, MS1 and MS2 were obtained by segmenting the 25 respondents based upon the coefficients for Response-Time.
Applying the approach – assigning a new person to a mind-set
Our small study here identified a potential pair of mind-sets in the population, those who believe that the path to war occurs by direct action (Mind-Set 1) versus occurs by military build-up (Mind-Set 2.) We used only 25 respondents, but we were able to uncover two mind-sets when we clustered on the basis the coefficients derived from the ratings. The analogy here is the discovery of basic colors, the red, yellow and blue, with a small set of test stimuli. Mind Genomics allows us to identify these basic mind-sets even with a small group of respondents.
The next level of effort is to use this discovery of two mind-sets to understand the world. Examples of such understanding and fundamental problems to be addressed in light of our small discovery are:
How do these two mind-sets distribute around the world, by age, by gender, by government, by personal history?
Over time, does a person remain in the same mind-set? Are these two mind-sets fixed, or can a person first be a member of one mind-set, but through life experience change into the other mind-set?
Is there a relation between membership in a mind-set and education?
If one can do many of these studies on the political world, then can one extract other mind-sets for other topics, such as negotiation, and study the membership pattern of a single individual across many mind-sets?
Does membership in the mind-set co-vary with any exogenous, measured behavior, such as political activism?
And perhaps, most controversial, is there a relation between the genetics of an individual (e.g., revealed by chromosomal mapping) and membership in a mind-set?
One approach to predicting mind-set membership looks at the pattern of coefficients for the mind-sets (Table 3), and selects elements showing the greatest differentiating power, i.e., the biggest difference for the average panelist. Each selected element is then edited to become a question, to be answered NO or YES, or some other appropriate pair of responses for the same type of binary decision. The questions are incorporated into a short questionnaire (Figure 5, left panel.) The pattern of responses shows which mind-set is the likely mind-set of the respondent (Figure 5, right panel.) The approach is simple, quick, and works on summary data. The important thing to keep in mind is that the objective is to have the respondent rate single elements that are most discriminating between two mind-sets or among three mind-sets. It will be the pattern of ratings which will end up being most appropriate for a person in a specific mind-set. The algorithm will then assign the new person to the mind-set segment most likely to generate the pattern just obtained from the new respondent, the person waiting to be assigned.
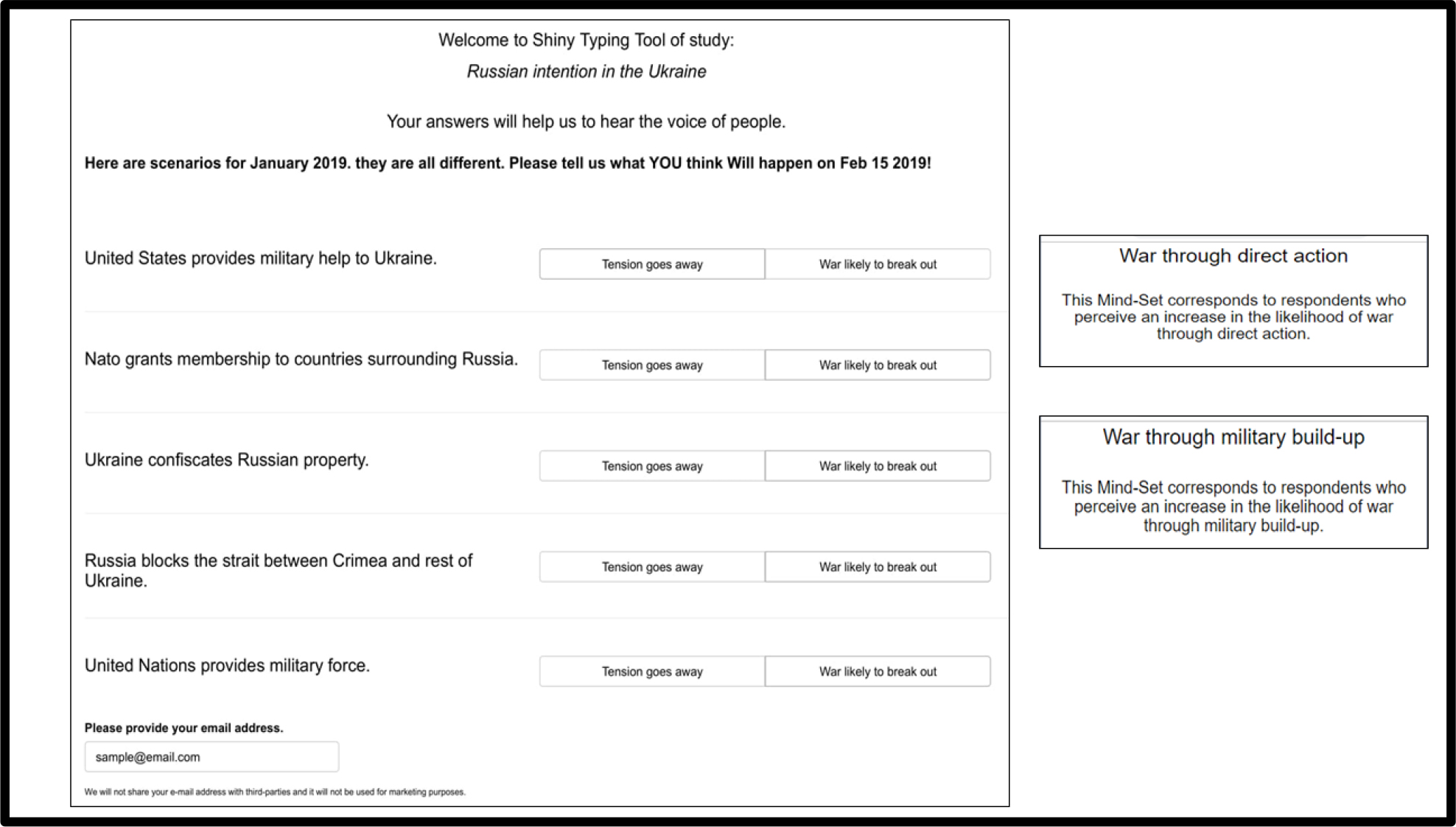
Figure 5. The PVI, the personal viewpoint identifier, showing the questions and simple answers, used to assign a new person to one of the two mind-sets. The platform independent, online-based personal viewpoint identifier of the study is currently available directly through the following link: http://162.243.165.37:3838/TT03/.
Discussion and conclusions
During the past decades scientific inquiries have grown more expensive, longer, often harder to implement, and with results limited to a specific topic, almost ‘filling a hole in the literature.’ Mind Genomics, as we have presented it here, is evolving in an independent direction. Mind Genomics takes a ‘snapshot of reality’ in terms of the reactions of people to cognitively meaningful messages or ideas about a single topic of experience, relevant to the person’s life. The ideas in this paper are issues which are best put into the world of ‘current events’ but the ideas can range from moral issues to economic issues, education, and so forth.
The positive news from the study is that is appears quite possible to use small, inexpensive, easy-to-run studies to quantify how people respond to the world around them, and at the same time prevent the system from being ‘gamed.’ The further positive news is that, even with the low base size, it is often quite easy and affordable to uncover emergent mind-sets, putting the potential of discovery in the hands of experimenters without the concomitant cost. Thus, Mind Genomics in the current format, the BimiLeap APP, democratizes research, putting research and discovery into the hands of everyone. The negative news is that Mind Genomics cannot uncover a general clear relation between response-time, a physiological measure, and the response to elements, a cognitive measure. The two mind-sets created according to response-times emerge, as they must from clustering, but they make only modest intuitive sense. Although we can easily see differences in response pattern to elements after segmenting the pattern of coefficients for ratings, we see no correspondingly clear differences between two mind-sets emerging from the pattern of coefficients for response-times. Our first effort, using the physiological measure of response-time to understand mental processing, must be considered only modestly successful. We emphasize here that the only difference in the two clustering efforts, the first based on coefficients for ratings, the second based on coefficients for response-time, is the nature of the measure, cognitive versus so-called neuro or physiological. It may be that response-time in this form has to be further analyzed, incorporating other variables besides the element itself. The predictor variables might be the element and some morphological features of the elements as well. That effort is left to future research [13–15].
References
- Galanter E, Pliner, P (1974) Cross-modality matching of money against other continua. In Sensation and measurement, Reidel Pg No: 65–76.
- Stevens SS (1975) Psychophysics: Introduction to its perceptual, neural and social prospects. New York, John Wiley.
- Box GEP, Hunter WP, Hunter JS (1978) Statistics for experimenters, New York, John Wiley.
- Moskowitz HR (2012) ‘Mind genomics’: The experimental, inductive science of the ordinary, and its application to aspects of food and feeding. Physiology & behavior 107: 606–613.
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2006) Founding a new science: Mind genomics. Journal of sensory studies 21: 266–307.
- Fugate DL (2007) Neuromarketing: a layman’s look at neuroscience and its potential application to marketing practice. Journal of Consumer Marketing 24: 385–394.
- Genco SJ, Pohlmann AP, Steidl P (2013) Neuromarketing for dummies. John Wiley & Sons.
- Charap S, Colton TJ (2018) Everyone loses: The Ukraine crisis and the ruinous contest for post-Soviet Eurasia. Routledge.
- Russell W (2018) Russian Relations with the “Near Abroad”. In Russian Foreign Policy Since 1990 (pp. 53–70). Routledge.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127–145.
- Moskowitz HR, Silcher M (2006) The applications of conjoint analysis and their possible uses in Sensometrics. Food quality and preference 17: 45–165.
- De Hoon MJ, Imoto S, Nolan J, Miyano S (2004) Open source clustering software. Bioinformatics 20: 1453–1454. [crossref]
- Bercík, Jakub, Elena Horská, Wang WY, Ying-Chun Chen (2015) How can food retailing benefit from neuromarketing research: a case of various parameters of store illumination and consumer response. In 143rd Joint EAAE/AAEA Seminar, March 25–27, 2015, Naples, Italy, no. 202714. European Association of Agricultural Economists.
- Lee N, Broderick AJ, Chamberlain L (2007) What is ‘neuromarketing’? A discussion and agenda for future research. International journal of psychophysiology 63: 199–204.
- Stipp H (2015) The Evolution of Neuromarketing Research: From Novelty to Mainstream: How Neuro Research Tools Improve Our Knowledge about Advertising. Journal of Advertising Research 55: 120–122.
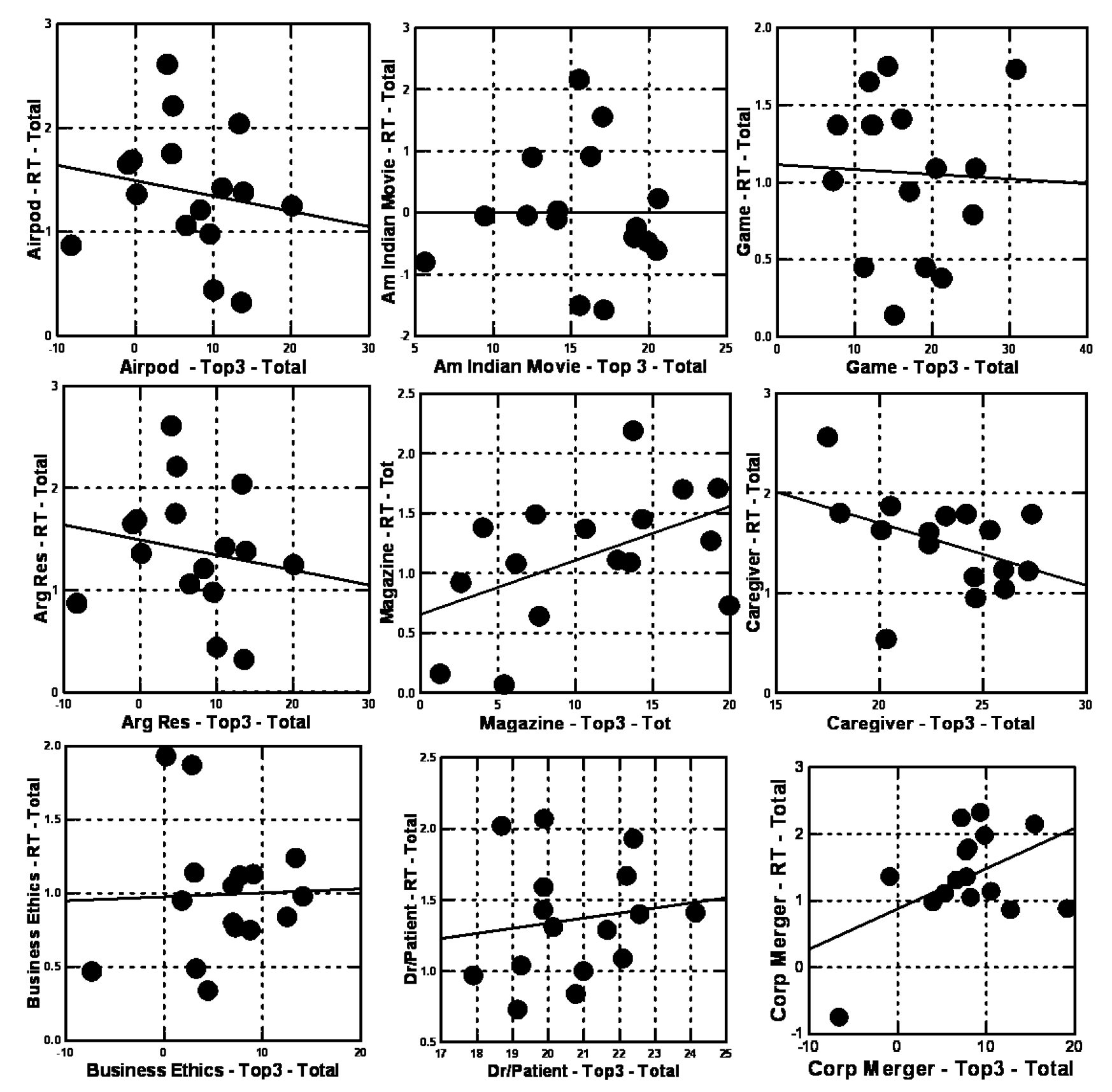
Appendix
Nine recent studies with base sizes of 25-50 respondents, conducted in the same way as the current study. The graphs show the relation for the total panel, between the coefficient of response-time (ordinate) and the coefficient for interest (binary transformed, abscissa). The models were created from the ‘total panel data’ after the data in the first position was eliminated from the data set, leaving only 23 vignettes evaluated by each respondent.