DOI: 10.31038/ALE.2024111
Abstract
The study focuses on how young males, ages 16-30, in the Virginia area respond to different scenarios of a police officer interacting with a prospective lawbreaker. The scenarios were created by systematic combinations of messages (elements), developed from human experience and artificial intelligence. The deconstruction of the ratings into the part-worth contribution of each of 16 elements showed the degree to which each element would be “listened to” by the prospective lawbreaker, as well as the degree to which the same element would lessen the anger. Three mind-sets emerged. The first mind-set is the police officer who creates empathy, which de-escalates the situation. The second mind-set is the take-charge officer, who clearly senses a developing problem, talks authoritatively. The third mind-set pays attention to community-oriented and empathic policing. These mind-sets represent the way ordinary people, young males, think about the police and what the police do when they read about these different potential crimes and interactions between perpetrators and police. The approach allows us to identify the way young people think about the information that they read. The results show that not everybody is the same and that there may be different strategies about the role of police officers depending upon the nature of that to which a person pays attention.
Keywords
Lawbreaker, Mind-sets, Police officer, Verbal judo
Introduction
The origin of this study can be traced to ongoing work by the authors in the world of working with police officers to figure out how to deal with the public, how to deal with active lawbreakers, prospective lawbreakers, situations which may turn violent, and finally, just as important, how to recruit police officers in a world where certain kinds of social activities have been set up to hamper police officers. The study that was done here concerns what the police officer should say to an individual who looks like that individual will engage in violence. The study is based upon a series of discussions with various police departments, as well as the recognition that there are different mind-sets of criminals. A detailed look through the literature of crime suggests that criminals, those who do violence for example, are not doing it all for the same motive [1-5]. This statement may seem like a truism, and it is to some extent. However, the ramifications of this truism are especially important. We are not dealing here with academic issues which will result in the same outcomes. Rather, we are discussing real-world situations in which violence may take place, in which people may get hurt or even killed. We are looking at a problem which is systemic all over the world, namely the interaction, and perhaps even confrontation, between a police officer and a lawbreaker. Crimes are committed for different reasons. What’s not necessarily obvious is the nature of the motivation of the criminal, and perhaps just as well, the type of communication to which the criminal or at least the prospective lawbreaker might be receptive. Negotiators recognize these differences in the types of language and the types of wording that might be effective, but all too often, such knowledge resides in the mind of the person who has had experience, who has been trained “on the job” through personal interactions.
We would like to bring this effort into the public eye by doing research on what people think will be effective communications [6]. The objective here is not necessarily to have an encyclopedia of those discussions. We leave that to the professionals. Rather, our objective is to use new research techniques, such as Mind Genomics, to discover the types of mind-sets of prospective lawbreakers and their situations in which things happen. And, for both of them to figure out what type of language might be effective as perceived by a person who’s asked to judge the situation.
The science of criminology has long recognized the existence of mind-sets or types of individuals. It could be no other way. People are different in the reasons underlying their commission of crimes or misdemeanors. We all operate within different life circumstances. Can we make a tool that the negotiator in a crime or the police officer can use for specific circumstances, named at the time of use? The objective would be to use that tool as a way to learn, and to instruct. We do not expect the work to be presented here to be anything other than a start of using Mind Genomics as emergent science to understand the mind of what we might call negotiation [7-10]
The Foundation and Approach of Mind Genomics
The foundation of Mind Genomics is the belief that it is possible to study the reactions to the world of the everyday in a scientific manner. When we look at the specific details of the everyday, we may often find that people react to these details in different ways, but in a limited number of different ways. These different ways are called mind-sets. The objective of Mind Genomics is to understand the world by understanding how people differ from each other in their response to features of and messages about the daily world [11]. Rather than assuming that there are a limited grand number of mind-sets — let’s say three or ten or sixty even — we assume that the mind-set emerges from the pattern of reactions or the pattern of potential reactions to a granular, everyday situation. That is, people can be in one mind-set when they think about how they’re going to order and eat breakfast but be in totally different mind-sets when they realize how they’re going to commute to work. The goal of Mind Genomics, therefore, becomes one to understand these mind-sets at the granular level, doing so in a way which is efficient, inexpensive, educational, reliable, powerful [12-14]. One ultimate goal is to create a “database of everyday life.” This paper presents one application, the messaging or “verbal judo” between a police officer and a prospective lawbreaker.
Setting Up the Mind Genomics Study Through a Templated System
The templated approach developed for Mind Genomics ensures that any user can do a study, whether the user knows the elements to be tested or whether the user wants to be “coached” by AI in the form. of an LLM (large language model) to create these elements. Figure 1, Panel A shows what confronts the user at the start of the study. The user is requested to tell four or select four questions which “tell a story.” Panel A is already filled in but one could imagine Panel A with no questions whatsoever simply with four blanks, one blank per question.
The prospect of course is quite daunting as has been the experience of the authors over the past decades. It is for that reason that we embedded artificial intelligence using ChatGPT 3.5 [15]. ChatGPT 3.5 was programmed to receive a small squib shown in the box on the right (Figure 1, Panel B). The squib describes the issue. From that squib ChatGPT 3.5 creates 15 questions for each iteration [16,17]. The user can iterate again and again, each time creating 15 questions, until the user selects a total of four questions across the various iterations. The user can select the questions, edit them, provide other questions, doing so for many iterations. The Mind Genomics process will record each iteration, whether the elements were selected or not. The result is an education simply through creating questions in each iteration. Thus, the four selected questions could come from a variety of iterations and reflect the results of editing the suggested questions [16,17].
What ends up of course is that the user can drop the questions into the study as shown in Panel A, can edit it, put it into different words, or even use the user’s own ideas (Figure 1, Panel A). Table 1 shows the types of questions which emerge when the user uses Idea Coach ChatGPT for creating the questions.
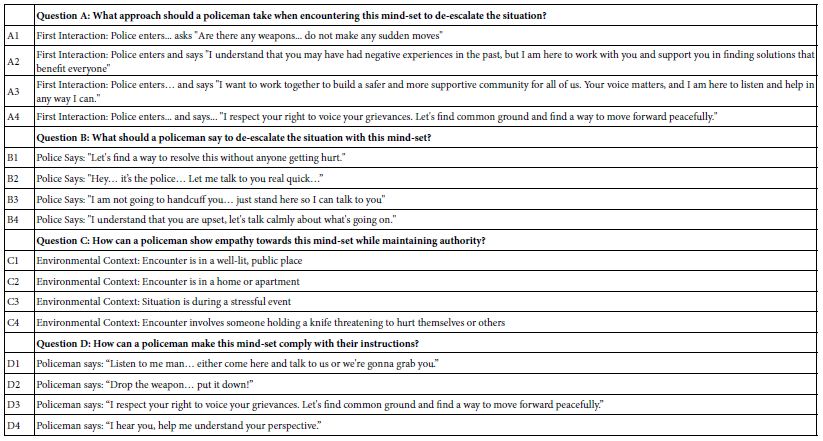
Table 1: Output of AI for the squib. Topic: A policeman is responding to a situation. What should I ask?

The same approach requiring the user to generate four answers to each question finally selected once again generates a sense of discomfort. The level of discomfort seems to be less, perhaps because it is easier to answer questions than to pose them. Once again AI proves valuable here, reducing the panelist. The user only needs to select Idea Coach and AI is prompted to return with 15 answers to each question. The process can go on several times for each question, resulting in a book of questions and answers to those questions. Table 2 shows the final set of four questions and four answers to each question.
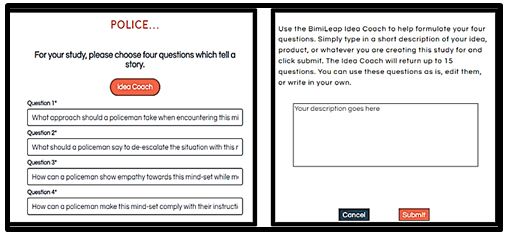
Figure 1: Panel A shows the user interface screen requesting four questions, with the questions filled in. Panel B shows the user interface box to write in the squib for the Idea Coach, using ChatGPT 3.5.
Table 2: The final set of four questions, and the four answers (elements) for each question
Orienting the Respondents and Providing a Rating Scale
The next step in the setup of the Mind Genomics study involves the creation of the orientation for the respondent and an easy-to-use rating scale. Traditionally, the rating scale has been unidimensional, from low to high, from 1 to 5. More recent efforts have used two-sided rating scales, allowing the respondent to provide two pieces of information in the same scale. It is a two-sided rating scale that we use in this study. The first side involves ratings of listening. The second one involves ratings of reducing anger. Table 3 presents the text of the rating scale. Respondents typically have little problem assigning ratings using this type of scale, even though it would seem that they are making two types of judgments. Figure 2, Panel A shows the screenshot for the respondent orientation provided by the researcher. Figure 2, Panel B shows the set up for the rating scale, allowing the user to select the question itself (top), the number of scale points, and the optional anchoring phrase for each scale point.
Table 3: The rating scale

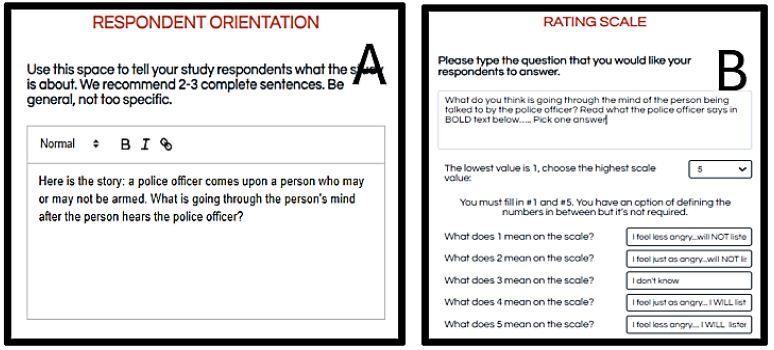
Figure 2: Panel A shows the user interface to create the respondent orientation. Panel B shows the user interface to create the rating question.
Table 4 shows the three self-profiling questions selected by the user, in addition to two additional standard questions (age, gender). These self-profiling questions allow the user to obtain otherwise impossible-to-obtain information about the respondent. Figure 3 shows the actual pull-down menu as presented to the respondent at the start of the evaluation session.
Table 4: The three self-profiling questions selected by the user

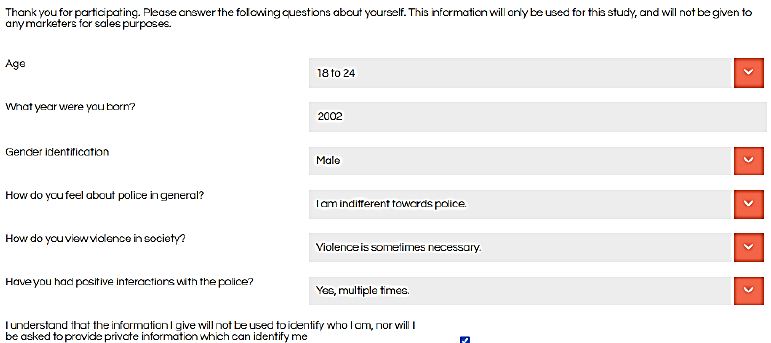
Figure 3: The pull-down menu presenting the self-profiling questions
Once the consumer respondent logs in and completes the self-profiling classification (Figure 3), the respondent is presented with an orientation and immediately evaluates 24 vignettes, one vignette after another (see Figure 4). The vignettes are created by experimental design, a systematized layout. Each respondent evaluates a unique set of the 24 vignettes, the uniqueness guaranteed by a permutation scheme which maintains the mathematical properties of the combinations (statistical independence, equal frequency of appearance, etc.).

Figure 4: Example of a vignette as presented to the respondent, who reads and rates the vignette. The vignette automatically advances to the next vignette after the respondent assigns a rating.
A vignette has two, three, or four elements, at most one element from each question or one answer from each question. According to the experimental design, the combinations of the vignettes are incomplete. That is, the vignettes are not created by the obsessive requirement that each vignette have exactly one element (viz., answer) from each question. That requirement would, in fact, end up being counterproductive in a statistical sense because the 16 elements would not be statistically independent of each other, and only relative value of coefficients would emerge, not the more desirable absolute values.
The strategy of having each respondent evaluate a unique set of combinations was developed by Gofman and Moskowitz in the early 2000’s [18]. The objective was to ensure that Mind Genomics would explore many combinations and thus might be well used as a tool for exploration rather than a tool to confirm what was known. In traditional conjoint measurement, the typical user ends up testing known combinations, creating these limited numbers of combinations to test the hypothesis. It is important in traditional conjoint measurement to “know” the important elements ahead of time. In a complete about face, Mind Genomics was designed to explore the response to messages, elements, welcoming the absence of any ingoing knowledge about “what is important.” In Mind Genomics, the user may have absolutely no idea of what the important elements are, and therefore it makes far more sense to have each person test a unique set of combinations different from the combinations of everybody else. The consequence of that is that the Mind Genomics system is much like an MRI of the mind, looking at different areas, identifying things, and then putting everything together at the end of the experience with one grand computer analysis which shows exactly what every element contributes.
Transformation to Binary Scales and Creation of Equations Using OLS (Ordinary Least Squares) Regression
The analysis of Mind Genomics data follows a simple series of steps and like the setup is templated to make the approach easier for people to use. The rating scale has two dimensions. One dimension is listening, the second dimension is lessening anger. We want to capture both of these. The transformations create two new variables, each taking on the values of 0 or 100, as shown. Each rating thus generates these two binary variables. As a precautionary measure to ensure that every respondent generates some level of variation in these two binary variables, we add a vanishingly small random number (<10-5) to each newly created binary variable. By so doing we ensure that the subsequent analysis using OLS (ordinary least squares) regression will not “crash.”
R54 (Listen to Officer) Ratings 5 and 4 transformed to 100, ratings 1,2, and 3 transformed to 0.
R52 (Lessen Anger) Ratings 5 and 2 transformed to 100, ratings 1, 3 and 4 transformed to 0.
The effort put into creating the combinations now pays out. It is straightforward to apply OLS regression to the data, whether at the level of a single individual or at the level of a group. The equation shows how one deconstructs the rating, or more correctly the transformed binary variable, into the part-worth contribution of each of the 16 elements. The equation does not have an additive constant, meaning that the equation is forced through the origin. This simple expression contains within it all of the information about the driving strength of each of the 16 elements for Listen to Office or for Lessen Anger.
Binary Dependent Variable = k1A1 + k2A2… k16D4
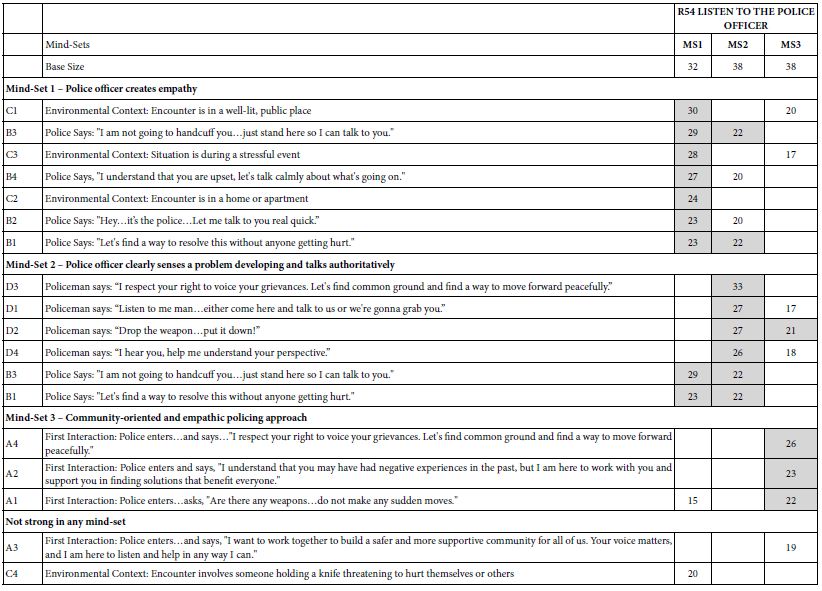
Table 5 shows the coefficients from the ordinary least squares regression. The coefficients are sorted by the magnitude for R54 (Listen to Police Officer). The convention for this analysis will be that any coefficient of 21 or higher will be shaded to highlight as being an extremely important, highly significant coefficient. The value 21 emerges from statistical tests of significance. The second column shows the coefficient for R52 the binary dependent variable for Lessened Anger. In neither case is any element shown as highly significant with a coefficient of 21, although D3 is close: Policeman says I respect your right to voice your grievances.
Table 5: Coefficients for the Total Panel
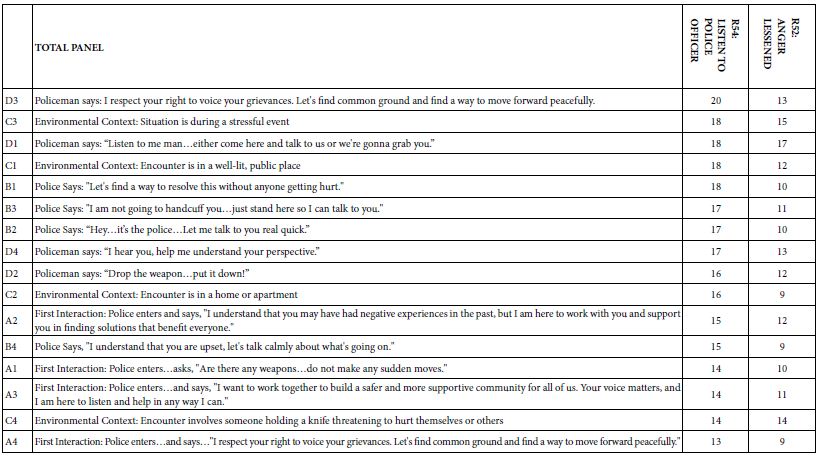
The fact that there are no very strong elements for R54 (Listen to Police Officer) or for R52 (Lessen Anger) may emerge because people have different criteria, and therefore their ratings may cancel each other out. We can think of two streams meeting another stream in opposite directions. A stream flows quickly, but if two streams meet together and they’re going in opposite directions, often the result is a pool with a lot of disturbance, but the pool is not going fast in any direction. It just becomes a maelstrom. The same thing may occur with the coefficients from the total panel. We may have different groups of people with different ideas, and the question is whether in fact these people are canceling each other out. We will see that when we come to mind-sets, but first we have to work our way through the differences between people as they have defined themselves in the classification questions.
Self-Profiling
The respondents were required to answer three questions at the start of the study, shown in Table 3. Mind Genomics can generate a wall of numbers because of the different binary dependent variables (R54, R52), the 16 elements, and the several groups self-defined by the respondent. To make understanding and discovering patterns easier, we focus from this point forward on one key dependent variable, R54.
Table 6 shows the coefficients based upon Question 1, attitude towards police. The story in Table 6 is clear. Only one of the three subgroups generate consistently high coefficients, viz., those who say they trust police.
Table 6: Coefficients for elements based on self-profiling Question 1 (Attitude toward police).
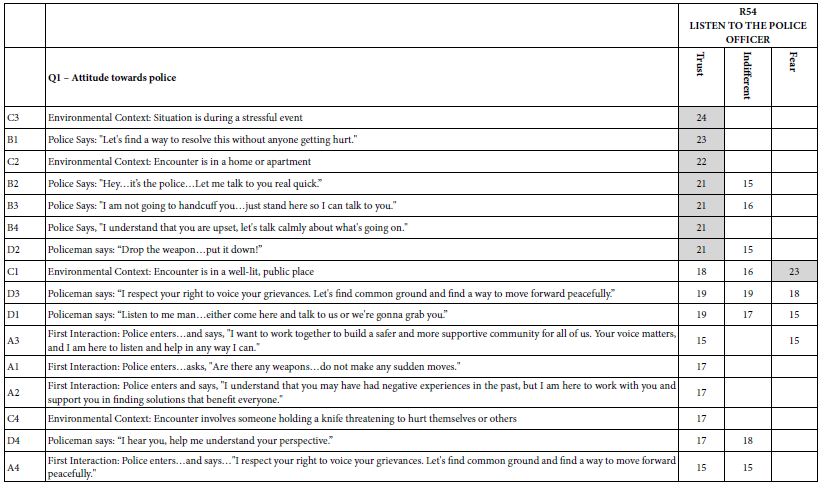
Table 7 shows the coefficients for R54, this time based on how the respondent feels about violence in society. Once again, a story emerges, although not one quite as clear as before. Those who feel that violence is never justified end up saying they will listen to direct statements to them by the police. Those who feel that violence is occasionally warranted say that they will listen in a number of situations, but the common link is not clear. Finally, those who feel that violence is simply part of everyday life do not end up saying that they will listen to the police officer.
Table 7: Coefficients for elements based on self-profiling Question 2 (Violence in society).
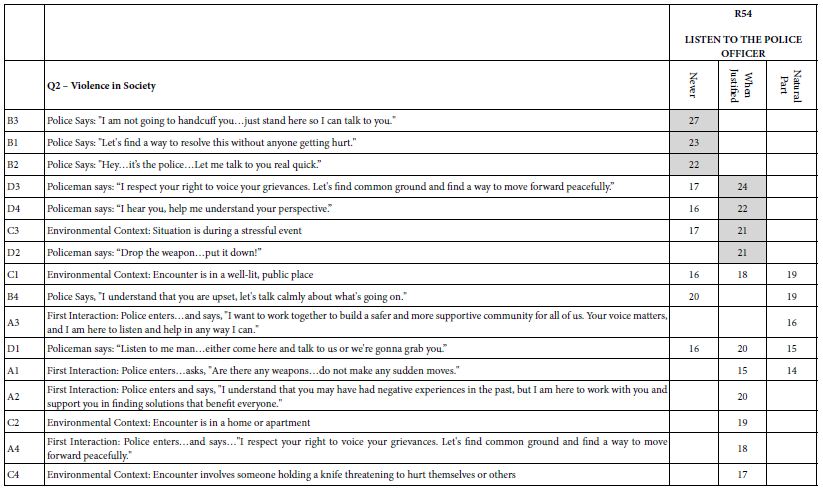
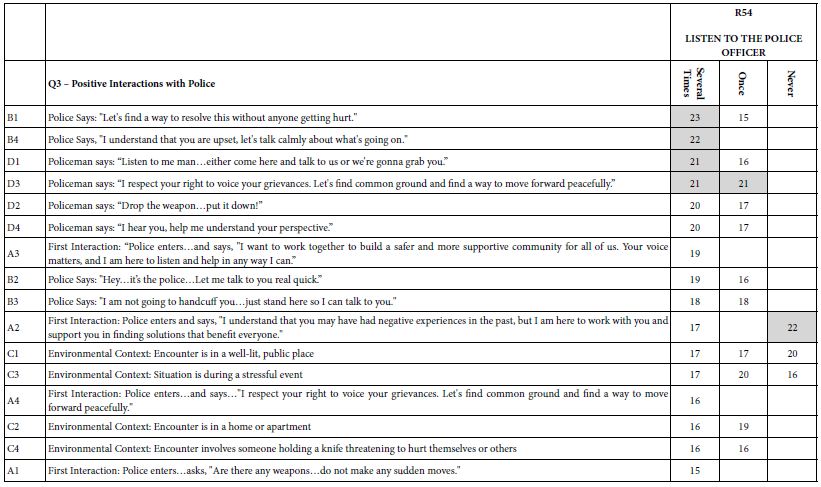
Table 8 shows the coefficients for R54, this time for self-profiling question #3, “positive interactions with police.” Those respondents who say that they have had several positive interactions with the police are likely to listen, especially when spoken to respectfully.
Table 8: Coefficients for elements based on self-profiling Question 3 (Positive interactions with police).
Mind-Sets
The last analysis creates mind-sets. Mind-sets are defined as clusters of individuals who respond in the same way towards a specific topic. Individuals within a mind-set find certain patterns to be extraordinarily engaging and other patterns to be virtually irrelevant. Mind-sets emerge from statistical analyses of the patterns of coefficients for the individuals. Ideally for a topic such as listening to police officers, the statistical analysis should generate a limited number of clusters of patterns, the mind-sets, with these patterns telling easy to understand “stories.” The former is parsimony, the latter is interpretability.
The creation of mind-sets for these data involved the estimation of 108 individual-level equations, one equation for each respondent. It is just as easy for the computer to create 108 equations as to create one equation, since each respondent’s 24 vignettes were arranged ahead of time to ensure that the 16 elements appeared in a statistically independent fashion. As before, the key dependent variable is R54, Listen to the police officer. The final analysis to generate the mind-sets used k-means clustering [19]. The outcome is two, and then three clusters or mind-sets. The three-mind-set solution was easier to interpret. Table 9 shows the three-mind-set solution, sorted from high to low for each mind-set separately. Elements which generate coefficients of 21 or higher in two mind-sets appear in each mind-set in the proper order, to make interpretation easier. Table 9 shows many more strong performing elements, with these elements telling simpler stories. It is important to keep in mind that these mind-sets emerge without the help of human interpretation except at the very end. All of the analyses come from pure mathematical considerations.
The strong performance of elements in Table 9 should not surprise. The analogy given above for the total panel was of two or more streams, moving swiftly in opposite directions, clashing with each other and creating a pool of turbulent, but non-flowing flowing water. The mind-sets flow in different directions. We see weaker performance for the total panel (see Table 5, column for R54). Only when the different mind-sets emerge do we see how really strong the mind-sets are.
Table 9: The three-mind-set solution emerging from clustering the coefficient on the basis of values for R54 (Listen to the police officer).
Using AI to Understand the Mind-Sets More Deeply
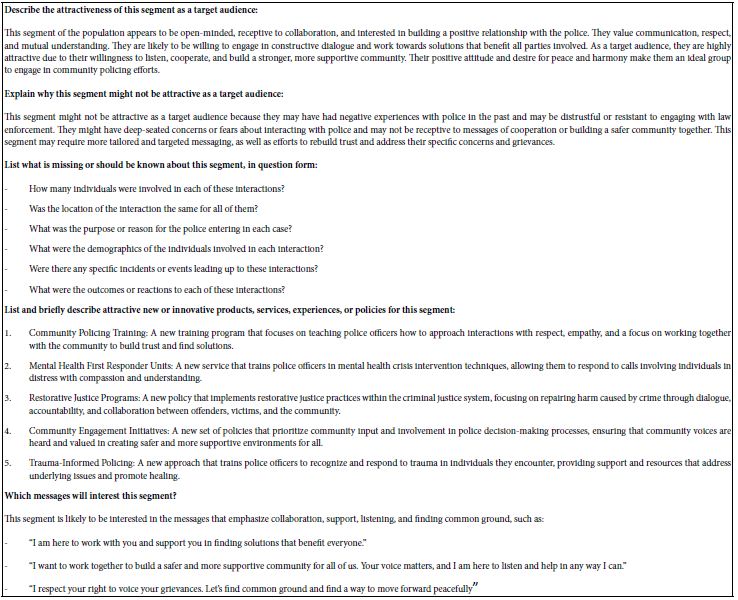
Our final analysis comprises the deeper interpretation of our mind-sets through artificial intelligence. We know the strong performing elements for the key binary dependent variable R54. Table 9 shows these elements in shade. The LLM embedded in BimiLeap.com, the Mind Genomics platform, “summarizes” the patterns behind these strong performing elements. Table 10 presents these summaries exactly the way they emerged from the LLM. It is important to keep in mind that the user does not have to accept the summarization. For example, the mind-set names used in Table 9 are not those recommended by AI. Rather, the summarization shown in Table 10 is meant as an aid to learning and to critical thinking, essentially acting as a “coach” to suggest other aspects meriting the user’s attention.
Table 10: AI-generated “automated summaries” of strong-performing elements for each of the three mind-sets shown in Table 9.


Discussion and Conclusions
The goal of this study was to demonstrate how a combination of artificial intelligence and Mind Genomics thinking can create different features of the interaction between a potential perpetrator of a violent act and the police. With the increasing power of artificial intelligence as manifested in large language models, it becomes straightforward to request these large language models to provide relevant questions and then for each question relevant answers. We demonstrated this through Idea Coach. Whether or not we created the correct questions and selected the correct answers becomes a minor issue when we realize that we can do an iteration in a minute or less. What would take months of thinking, now with the help of large language models, really takes minutes to do in terms of searching for new questions and in turn for new answers to those questions, the elements of our study.
The first half of the study was devoted to finding the test stimuli. The second half is devoted to finding the response of real people, in our case young males living in the Virginia area. The issue was whether these people would respond in a specific way to the various scenarios, to the different elements combined. The data from our 108 respondents suggest three different mind-sets. It’s important to know that this is our first foray. The first mind-set would be strong responses to listening when the place is familiar and when the police officer says to the effect that “I’m going to not do anything to you, just let’s talk.” The second mind-set stresses that the person says they will listen when there are clear actions that suggest a hostile nature. The police officer clearly senses a situation and the problem developing and talks authoritatively. It’s important to note that the police officer who talks authoritatively may also want to talk in a more peaceful manner to find common ground. The third mind-set is that the police officer really knows what’s going to happen and essentially threatens or orders the potential perpetrator not to do anything. As a closing comment, one should keep in mind that these mind-sets are not hard and fast divisions, but interpretable regions on a continuum. That itself is key learning, that sometimes there are strong differences, opposite or independent, orthogonal, and sometimes the mindsets fall along a continuum of power. It’s quite possible that in the case of police behavior in these situations we are dealing with positions on a continuum rather than radically different mind-sets. Only experimentation will tell us.
Acknowledgment
The authors would like to thank Vanessa Marie B. Arcenas for helping to produce this manuscript.
Abbreviations
| Abbreviation | Definition |
| AI | Artificial Intelligence |
| ChatGPT | Chat Generative Pre-trained Transformer |
| LLM | Large Language Model |
| OLS regression | Ordinary Least Squares regression |
Competing Interests
The authors have no conflict of interest to disclose.
References
- Anshel MH (2000) A conceptual model and implications for coping with stressful events in police work. Criminal justice and Behavior 27(3): 375-400.
- Bazemore G, and Senjo S (1997) Police encounters with juveniles revisited: An exploratory study of themes and styles in community policing. Policing: An International Journal of Police Strategies & Management 20(1): 60-82.
- Hulderman MA (2003) Decision-making styles and learning strategies of police officers: Implications for community policing. Oklahoma State University.
- Ramshaw P (2012) On the beat: Variations in the patrolling styles of the police officer. Journal of Organizational Ethnography 1(2): 213-233.
- Wachi T, Watanabe K, Yokota K, Otsuka Y, and Lamb ME (2016) The relationship between police officers’ personalities and interviewing styles. Personality and Individual Differences 97: 151-156.
- Mendoza C, Mendoza C, Deitel Y, Rappaport S, Moskowitz HR (2023) Empowering young people to become Researchers: What does it take to become a police officer? Psychology Journal Research Open 5: 1-12.
- Cooper HHA (2005) Close Encounters of an Unpleasant Kind: Preliminary Thoughts on the Stockholm Syndrome. Journal of Police Crisis Negotiations 5(2): 81-109.
- Donohue WA, and Roberto AJ (1993) Relational development as negotiated order in hostage negotiation. Human Communication Research 20(2): 175-198.
- Greenstone JL (2013) The elements of police hostage and crisis negotiations: Critical incidents and how to respond to them. Routledge.
- Soskis DA, and Van Zandt CR (1986) Hostage negotiation: Law enforcement’s most effective nonlethal weapon. Behavioral Sciences & the Law 4(4): 423-435.
- Moskowitz HR, Gofman A (2007) Selling Blue Elephants: How to Make Great Products that People Want Before They Even Know They Want Them. Pearson Education.
- Moskowitz HR, Gofman A, Beckley J and Ashman H (2006) Founding a new science: Mind genomics. Journal of sensory studies 21(3): 266-307.
- Porretta S, Gere A, Radványi D and Moskowitz H (2019) Mind Genomics (Conjoint Analysis): The new concept research in the analysis of consumer behaviour and choice. Trends in food science & technology 84: 29-33.
- Radványi D, Gere A and Moskowitz HR (2020) The mind of sustainability: a mind genomics cartography. International Journal of R&D Innovation Strategy (IJRDIS): 2(1): 22-43.
- Wu T, He S, Liu J, Sun S, et al (2023) A brief overview of ChatGPT: The history, status quo and potential future development. IEEE/CAA Journal of Automatica Sinica 10(5): 1122-1136.
- Mendoza C, Mendoza C, Rappaport S, Deitel J, Moskowitz HR (2023) (c) Empowering young researchers to think critically: Exploring reactions to the ‘Inspirational Charge to the Newly-Minted Physician’. Psychology Journal, Research Open 2: 1-9.
- Mendoza C, Mendoza C, Rappaport S, Deitel Y, Moskowitz H (2023) Empowering Young Students to Become Researchers: Thinking of Today’s Gasoline Prices. Mind Genom Stud Psychol Exp 2(2): 1-14.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145.
- Likas A, Vlassis N, Verbeek JJ (2003) The global k-means clustering algorithm. Pattern Recognition 36: 451-461.