Abstract
The paper presents a new approach to optimizing the shopper experience, combining easy-to-implement tools for understanding shopper mind-sets at the granular, specific level (Mind Genomics; www.BimiLeap.com) with a simple, rapid way which assigns any shopper or prospective shopper to the relevant mind-set for that granular topic (www.PVI360.com). The approach begins with a simple study of the motivating power of relevant messages, and thus uncovers mind-sets or groups of respondents showing similar patterns of what motivates them. Then, using the same data, the approach creates a simple questionnaire comprising six questions taken from the original study, the pattern of answers to which assign a new person to a mind-set. Once the mind-set of the shopper is ‘identified’ for the granular topic using the PVI (personal viewpoint identifier) it is a matter of giving the shopper the appropriate motivating message, either at the time of shopping in brick and mortar store or e-store, or sending the message on the Internet in the form of an advertisement or individualized coupon.
Introduction
The past two decades have seen an explosion of knowledge about the consumer, the knowledge emerging from the speed and affordability of internet-based surveys, the sophisticated analysis of masses of cross-sectional data known as Big Data, and the application of artificial intelligence to uncover patterns. What continues to emerge is that nature is simultaneously tractable and intractable. As the macro level we know what to expect in terms of purchase patterns and expected time to repurchase, some of which knowledge may transfer to the level of the individuals, only for the general pattern just exposed to be disrupted by the idiosyncrasies of each individual. The world at the time of this writing (Fall, 2023) is quite different from the world of just a decade ago, and most certain far different from the earlier decades. The notion that one could change advertisements is well-accepted, easily and widely done. Outdoor advertisements and LED technology assault us everywhere we go. We are accustomed to see large billboards with attention-grabbing sequences advertisements, the modern day evolution of signage of decades ago, once static, now plastic, and changeable at will. Now technology makes it possible to individualize the messaging for an individual, much as is done on a cell phone. This paper presents one approach. The organizing nature of this paper is how one might advertise to a single customer, using science to uncover the ‘mind’ of that customer ahead of time. The objective of this study was to understand the different types of messages which might appeal to shoppers of cereal in the middle isle, and shoppers of yogurt in the refrigerated dairy section. Could the technology of 2023 be set up to deliver the proper messages to an individual who is walking along the store? And could the approach be set up to be done at scale, affordably, quickly, with scientific precision rather than with guessing about what the person wants based upon who the person is. This latter condition is important. It means that the messages must be delivered to the person most likely to respond to the specific messages. The studies reported here were done with the intention of testing out the possibility that one could create a knowledge-based system about messaging for simple, conventional, familiar products. The paper does not deal with new to the world products which have their own mystique, and both positive and negative messaging attached. Rather, the paper deals with what one might call ‘tired, old, utterly familiar’ products that may not be susceptible to the romance of the new and different.
A Short Historical Overview to ‘Messaging the Shopper’
The notion that one can influence the shopper by proper messaging is decades old, and the subject of numerous experiments. Indeed, the real-world behaviors of shoppers and the change in behavior resulting from the proper messaging opens up the topic to anyone interested in messaging, whether the interest be theory such as experimental psychology, to applied science such as consumer psychology, and of course the world of business applications. As a consequence, there have been a number of different studies focusing specifically on shopping.
- Schumann et al. (1991) reported only modest effectiveness of signage in shopping cart [1]. To summarize their results: “Findings from both studies reflect that over 60% of the 2 samples noted the presence of the signs in their carts. When Ss were questioned about their awareness of cart advertising on a specific occasion, only 3.0-6.5% recalled the product. There was no evidence that cart signage acts in a subliminal fashion that results in the purchase of the brand.” It may well be the signage in the cart was general information about the product, not necessarily information that would tug at the heartstrings of the shopper.
- Dennis et al. (2012) confirmed the efficacy of digital signage but argued for emotional content [2]. They noted that the typical content of digital signal is ‘information-based’ whereas digital signage might be more effective if it were to comprise emotional messaging as well, or even instead of simple information. Results are limited as the DS (digital signage) screens content was information based, whereas according to LCM, (Limited Capacity Model of Mediate Messaging) people pay more attention to emotion-eliciting communications. The results have practical implications as DS appeals to active shoppers.
- Buttner et al. (2013) proposed at two types of shopping orientations (mind-sets), task focused and experiential shopping, respectively [3]. They report that “Activating a mindset that matches the shopping orientation increases the monetary value that consumers assign to a product. ….marketers and retailers will benefit from addressing experiential and task-focused shoppers via the mindsets that underlie their shopping orientation.”
- Chang and Chen (2015) reported that mind-sets are important, and that the communication should consider the different mind-sets [4]. Their notion was that people may or may not be skeptical to advertising. Those who have a ‘utilitarian orientation’ and an ‘individualistic’ mind-set tend to be skeptical about advertising, and need messages which are different from those individuals who have a ‘hedonic’ and a ‘collectivistic’ mind-set. Chang and Chen bring this topic into discussions about CRM and donating, but their notions can be easily extended to the right type of messaging for digital signage
The Contribution of Mind Genomics to the Solution
Mind Genomics is an emerging science which grew out of the need to understand how people make decisions about the issues of the ‘everyday’. Mind Genomics rests on the realization that the ‘everyday’ situations are compounds of different stimuli. To study these stimuli requires that the respondent, the test subject, be confronted by compound test stimuli which comprise different aspects of everyday situation, stimuli that the respondent ‘evaluates’, such as rating the combination. Through statistics, applied after the researcher properly sets up the blends, it becomes possible to understand just exactly what features ‘drive’ the rating. Properly executed, this seeming ‘roundabout way’, testing mixtures, ends up dramatically revealing the underlying mind of the respondent [5]. The foregoing process, testing systematically created mixtures and deconstructing through statistics, stands in striking opposition to the now-hallowed approach of ‘isolate and study.’ The traditional approach requires that the features of the everyday be identified, and separately evaluated, one feature at a time. Typically the evaluation ends up presenting each of the features separately, getting a rating, analyzing the pattern of ratings across people, and then identifying the key variables which a difference.
Attractive as the traditional methods may be, the one-at-a-time is severely flawed for several reasons:
- Combinations of features are more natural. It may be that a feature will receive a different score when evaluated alone compared to the evaluation of the feature as part of a mixture. And it may be that the feature will receive different scores when evaluated against backgrounds provided by a variety of other features. Thus, the wrong answer may emerge.
- People may change their criterion of judgment when presented with an array of different types of features, such as features dealing with product safety versus features dealing with branding, with benefits, and so forth. All too often the researcher AND the respondent fail to recognize the underlying shifts in these criteria.
- It becomes very difficult to ‘game the system’ when the test stimulus comprise a combination. Often, and perhaps even without knowing it, the respondent tries to assign the ‘correct’ or ‘socially appropriate’ answer. Such effort to ‘be right’ is doomed to failure when the respondent is presented with a combination. Often the respondent asks the researcher or interviewer for ‘help’, such as asking ‘what do I pay attention to in this combination?’
Mind Genomics works with the response to combination of text messages, called vignettes. The vignettes comprise specified combinations of elements, viz., verbal messages. Table 1 below (left part of table) shows these messages. The messages are sparse, to the point, paint a word picture. The vignettes are created according to an underlying plan called an experimental design. The experimental design may be thought of as a set of different combinations, different recipes, combining the same messages, the same elements, in different ways. A key difference between Mind Genomics and conventional research is how Mind Genomics considers variability among people and how it deal with that variability. We start the comparison by considering conventional research, which often considers variability in the data to be error, usually unwanted error which masks the ‘signal’. Occasionally the variability can be traced to some clear factor, such as the nature of the respondent, in which case this irritating variation hiding the signal is actually a signal itself. For the most part, however, researchers consider variability to be unwanted, and either suppress it by meticulous control of the test stimulus/situation, or average out the variability by working with a lot of respondents, and assuming that the variability is random, and so will cancel out. In the world of Mind Genomics variability is considered in a different light. Certainly there is the appreciation of error, but there is also the acceptance of the fact that people differ from each, and that these differences may be important. The differences between people are not necessarily random error, but rather point to potential profound differences among people, albeit differences which exist in a small, granular aspect of daily life. In other words, sometimes the differences are important, and sometimes the differences are merely random noise.
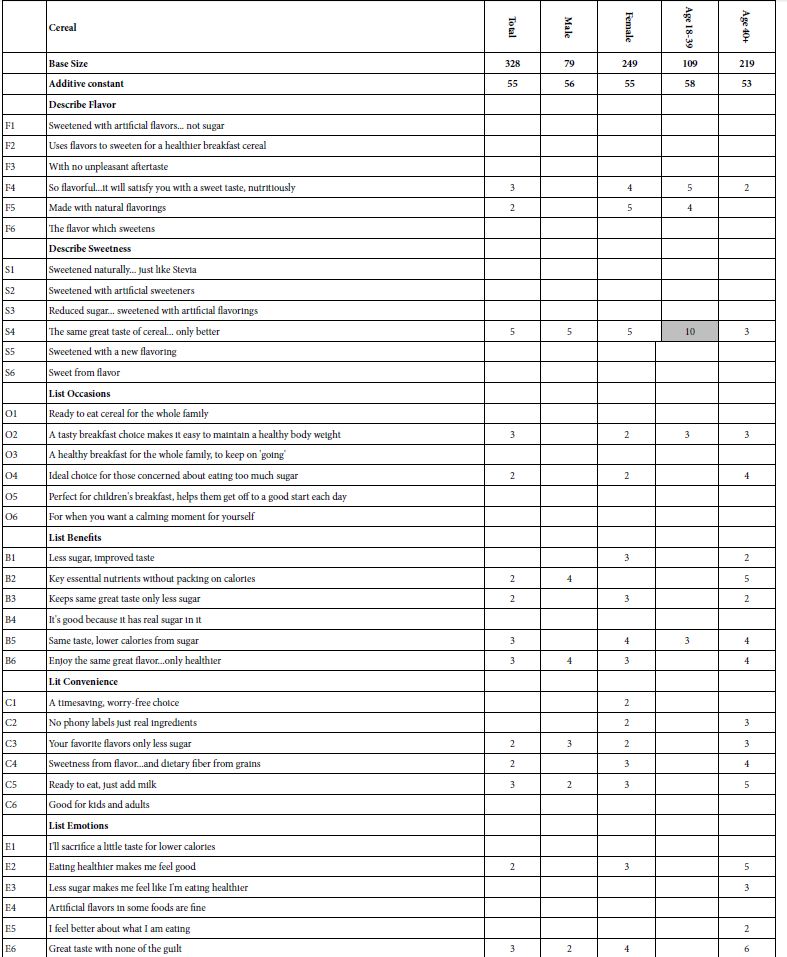
Table 1: Positive elements for cereal, viz., those elements which drive the rating of a vignette towards definitely buy/probably buy). All elements shown have positive coefficients of +2 or higher.
Explicating the Research Process
For the project reported here, the researcher selected two products (cereal, yogurt), asked six questions about the product, questions that could be used to create consumer-relevant messages, and then developed the database of 36 possible consumer messages for each product. Thus far, the process is quite simple, requiring only that the researcher do a bit of thinking about what types of messages might be relevant to consumers. One of the in-going ‘constraints’ from the perspective of marketing and the trade was that the messages had to be of the type which drive purchase. It was not an issue of building one’s brand through advertising. Rather, the messages were chosen so that they could be put on a coupon, or flashed on an LCD panel as the respondent ‘walked by.’ The actual process of developing the raw materials can be daunting for those who are not professionals. In the two studies reported here, a significant effort was expended to develop the six ideas which tell a ‘product story’. One the six ideas are developed, the most intellectually intense part of the effort, the creation of six messages for each idea becomes much easier. Recently, the creation of these basic ideas (or questions), and the elements (or answers) has been improved by a process called Idea Coach, which provides different options, using artificial intelligence (www.BimiLeap.com). The data reported here were collected before the Idea Coach system was incorporated into Mind Genomics.
- The actual selection of messages generated six groups of six message, one set of 36 such messages for cereal (Table 1), and another set of comprising different messages, for yogurt (Table 2).When looking at the table, the reader should keep in mind that the elements either pain a simple word picture, or specify a specific a specific claim that could be turned into ‘copy.’
- When creating the messages and assigning them to groups, The only requirement for the researcher is to ensure that all of the messages in a single idea (viz., all the answers given to a single question) remain together. For example, messages about ‘calories’ must all be put into one group or idea, and not split across two groups or questions. The rationale for this requirement comes from the fact that the underlying experimental design will need to combine elements from different questions (described below). When the researcher puts a calorie message in one group, and another calorie messages in a second group, there is the likelihood that the underlying experimental design may put these mutually incompatible messages into the same combination.
- Once the elements are created, comprising the question and the six answers, as shown in Tables 1 and 2, the next step is to use the basic experimental design, which specifies 48 combinations, each combination comprising either three or four elements. Each combination or vignette contains at most one element from any question. The vignettes are by design incomplete, since there are six questions, but a vignette can only have three or four answers, one from three or four questions. As noted above, each respondent evaluates a unique set of 48 combinations. The underlying mathematics remains the same. What changes is the assignment of a message to a code. For example, for one person, element A1 may be assigned as A1, whereas for another person a permutation is done, so the former A1 becomes A2, A2 becomes A3, et. the experimental design is maintained, but the combinations change [6].
- The final steps comprise the introductory message and the rating scale. In Mind Genomics studies most of the judgment must be driven by the individual elements, and not by the introductory statement. It is better to be vague about the product, and let the individual elements drive the reaction, rather than to specify too much in the general introduction. For this study, the introduction was simply ‘Please read this description of cereal and rate it on the 5-point scale below. For yogurt the introductory statement was virtually the same ‘please read this description of yogurt and rate it on the 5-point scale below’
- The five-point rating of purchase is anchored: 1: definitely not buy, 2: probably not buy, might not/might buy, 4: probably buy, 5: definitely buy. The anchored five point purchase intent scale has been used for many decades in the world of consumer research, both because the scale is sensitive to differences and because managers understand the scale, and generally look at the percentage of responses that are 4 and 5 on the 5-point scale. These two rating scale points are probably buy and definitely buy. The scale is often transformed to a binary scale, as was done here. Ratings of 4 and 5 were transformed to 100. Ratings of 1, 2 and 3 were transformed to 0. Managers who use the data more easily understand a yes/no scale, buy/not buy.
- Following the evaluation of 48 vignettes, the respondent completed a short self-profiling questionnaire, providing information about gender and age.
- Respondents were sent one of two links, the first appropriate to the cereal study, the second appropriate to yogurt. Approximately 70% of the individuals who were invited ended up participating. The high completion rate can be traced to the professionalism of the on-line research ‘supplier’. As a general point of view, it is almost always better to work with companies specializing in on-line research. Trying to recruit the respondents oneself ends up with a completion rate much low, often lower than 15%.
Creating the Database and Analyzing the Data for a Study
Each respondent ended up evaluating 48 different combinations, called vignettes, assigning each vignette a rating on an anchored 5-point scale. The next step creates a ‘model’ or equation showing how each of the 36 elements about the product ‘drives’ purchase intent. Recall that all 48 vignettes of a respondent differed from respondent to respondent, although the mathematical structure was the same. This ‘permutation’ strategy allows the research to cover a large percent of the possible combinations [7].
In order to uncover the impact of the elements, the key variables, it is necessary to create an equation relating the presence/absence of the 36 text elements about the product to the rating. This can be easily done. The data are easily analyzed, first by OLS (ordinary least-squares regression) and then by clustering. OLS regression shows how the 36 elements ‘drive’ the response (purchase). Clustering identifies groups of respondents with similar patterns of coefficients groups that we will call ‘mind-sets.’
- The OLS regression, applied to either the individual data, or to group data, is expressed by the following: Positive Intent to Purchase=k0 + k1(A1) + k2(A2) . k36(F6).
- For regression analysis to work, the dependent variable, the transformed variable (either 0 or 100) must show some small variation across the different 48 ratings for each individual respondent. Often, respondents confine their ratings to one part of the scale (e.g. 1-2; 4-5, etc.). To avoid a ‘crash’ of the OLS regression program, and yet not affect the results in a material way, it is a good idea to add a vanishingly small random number (e.g. around 10-4) to every transformed rating. The random number ensures variation in what will be the dependent variable, but does not affect the magnitude of the coefficients which emerge from the OLS regression.
- The underlying experimental design for each individual respondent makes it straightforward to quickly estimate the equation, either for individuals or for groups. The coefficient, whether for individual or for group, shows the degree to the element drives the response the rating of ‘definitely or probably purchase.’ The individual coefficients, viz., for the hundreds of respondents, are typically ‘noisy’, but when the coefficients become stable and reproducible when the corresponding coefficients are averaged across dozens of respondents, or when the equation is estimated from the raw data of dozens of respondents.
- The additive constant (k0) shows the estimated proportion of responses that will be 4 or 5 (viz., definitely purchase or probably purchase), in the absence of elements. Of course the underlying experimental design dictated that all 48 vignettes evaluated by any respondent would comprise a maximum of four elements (at most one element from a group) and a minimum of three elements (again, at most one element from a group, not more).
- The 36 individual coefficients (A1-F6) represent the contribution of each element to the expected interest in purchasing. When an element is inserted into a vignette, we can estimate its likely contribution by adding together the additive constant and the coefficient for the element. The sum is the percent of the respondents who would assign a rating of 4 or 5 to that newly constructed vignette.
- One of the ingoing tenets of Mind Genomics is that there exist groups in the population which think about the same topic, but in different ways. The information to which these respondents react may be the same but these groups use the information in different ways. Some respondents may value the information so that the information appears to covary with their rating of purchase the product. In contrast, other respondents may completely ignore the information. These differences reflect what Mind Genomics calls ‘mind-sets’, viz groups of individuals with clearly defined and different ways of processing the same information.
- The mind-sets emerge through the well-accepted statistical analysis called clustering [8]. Briefly, the clustering algorithm computes the Pearson correlation between pairs of respondents, based upon their 36 pairs of corresponding coefficients. Respondents with similar patterns (high positive correlation) are assigned to the same mind-set. Respondents with dissimilar patterns (negative or low positive correlations) are assigned to different mind-sets.
- For this study the ideal number of mind-sets is as few as possible. The paper reports the results emerging from dividing the respondents into two mind-sets, and then into four mind-sets, to show the effect of making the clustering more granular. The focus will be on interpreting the results from the two mind-set solution, and creating a tool to assign a new person to the one of the two mind-sets.
Applying the Learning-Cereal
Our data with 328 respondents provides us a wealth of information about to say, what not to say, and to whom. Table 1 shows the results for cereal. The table is organized with the key subgroups of respondents across the top and the messages down the side. In order to make the table easier to read, and allow the patterns to emerge, the table only shows positive coefficients of 2 or higher. The other coefficients were estimated, but are not relevant to the presentation since they do not drive positive interest in purchase. Furthermore, Table 1 shows strong performing elements as shaded cells. Strong performing is defined as a coefficient of + 10 or higher. Table 1 is rich in detail. The table shows the results from running the aforementioned linear equation using the data from all respondents (total), then the data by gender, then by age
- The additive constants differ, neither by gender nor age. Again and again Mind Genomics studies reveal that for the most part, conventional methods dividing people fail to show dramatic differences in how these divisions generate groups which think differently. It is eternally tempting to divide people by who they are, and presume that because people are different they think differently.
- The total panel of 328 respondents shows very few positive elements, and no strong elements. That is, knowing nothing else we cannot find elements which strongly drive purchase intent. Most of the elements are blank, meaning that the coefficients for those elements are either around zero or negative. In effect, ‘doing the experiment,’ viz. evaluating different messages, fails to uncover strong performing elements. No matter what experts might think, there are no apparent ‘magic bullets’ for cereal.
- A first effort to divide groups looks at gender. The additive constant is the same, but the females have a few more positive than do the males. Yet, none of the elements are strong drivers purchase when evaluated in the body of a vignette.
- The second effort divides the respondents by age. In terms of the additive constant, the younger respondents (ages 18-39) show a slightly higher additive constant than do the older respondents (age 40+; constants of 58 vs 53). The only strong performer (coefficient >1=10) is S4 for the younger respondents: The same great taste of cereal. only better.
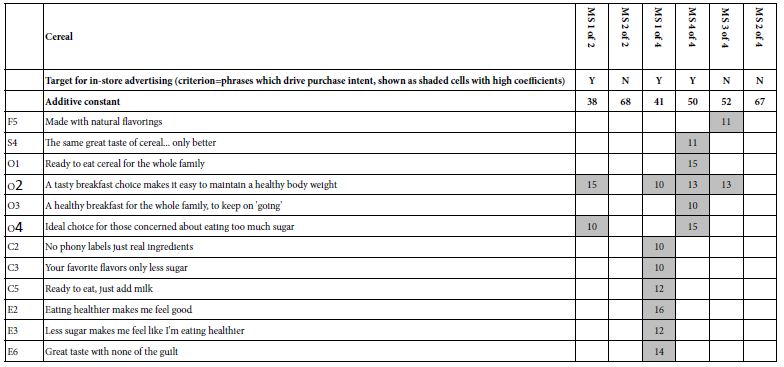
- The third effort divides the full set of respondents into exactly two mind-set and then into exactly four mind-sets using k-means clustering (Likas et al. 2003). To save space and make it easier for patterns to emerge, Table 2 shows the only those elements which perform strongly in at least one mind-set of the six created (two mind-sets + four mind-sets=six mind-sets). ‘Performing strongly’ is again operationally defined as a coefficient of +10 or higher. The groups with fewer strong performing elements will be harder to reach.
- Focusing just on the two mind-set solution, Mind-Set 2 is more primed than Mind-Set to be interested in buying the cereal (additive constant of 68 for Mind-Set 2, additive constant of 38 for Mind-Set 1). However, Mind-Set 1 shows two elements which excite its members: O2: A tasty breakfast choice makes it easy to maintain a healthy body weight O4: Ideal choice for those concerned about eating too much sugar.
Table 2: Strong performing elements for cereal, for divisions of respondents into two complementary mind-sets, and then into four complementary mind-sets. All elements shown have positive coefficients of +10 or higher.
Applying the Learning-Yogurt
Our second study, this time with 307 respondents, shows similar patterns. Table 3 shows the data for the total panel, gender, and age. Table 4 shows the strong performing elements for the mind-sets, viz., those with coefficients of +10 or higher.
- The total panel again does not show strong performing elements (coefficient ≥+10).
- The additive constants differ dramatically by gender. Recall that the additive constant is the basic level of purchase intent estimated in the absence of elements. Males shows a higher basic intent, females show a lower basic interest (74 vs. 54). This is a dramatic difference.
- Closer inspection of Table 3 reveals that the coefficients for the males are around 0 or lower whereas there are a number of coefficients for females which are moderately positive. Males have a basic higher acceptance, but do not show any strong performing elements. In contrast, females show the lower basic acceptance, but are more selective. The two elements which drive their purchase intent are:
F4: So flavorful. it will satisfy your sweet taste
F5: Made with natural flavoring - The second effort divides the respondents by age. In terms of the additive constant, the younger respondents (ages 18-39) show a lower additive constant, the older respondents show a higher additive constant (50 vs 62).
The younger respondents find five elements to drive purchase:
E6 Great taste with none of the guilt
F4 So flavorful. it will satisfy your sweet taste
O3 A refreshing healthy snack the whole family love
C1 Ready to eat when you are
F6 Flavor which sweetens
In contrast, the older respondents find only one element to drive purchase.
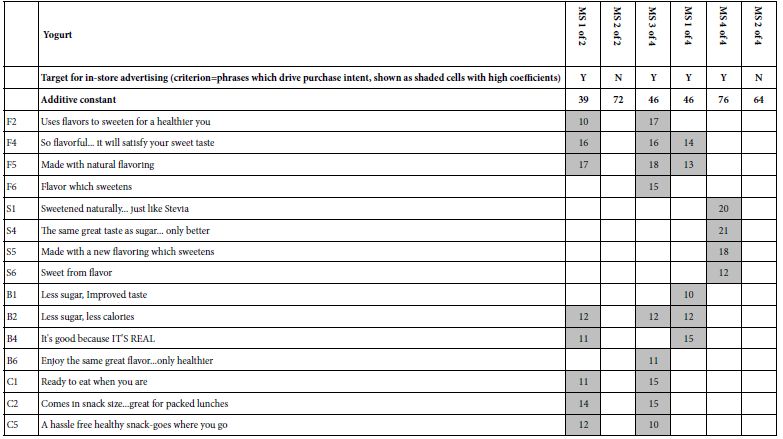
F5 Made with natural flavoring. - The results emerging from clustering show the two mind-sets (MS1 of 2, MS2 of 2) to have dramatically different additive constants (39 for MS1 of 2; 72 for MS2 of 2). Mind-Set 2 is prepared to purchase, even without messaging, whereas Mind-Set 1 must be convinced. Fortunately, eight of the 36 elements for yogurt perform strongly, two performing quite strongly (F4, F5):
F5: Made with natural flavoring
F4: So flavorful. it will satisfy your sweet taste
C2: Comes in snack size… great for packed lunches
B2: Less sugar, less calories
C5: A hassle free healthy snack-goes where you go
B4: It’s good because IT’S REAL
C1: Ready to eat when you are
F2: Uses flavors to sweeten for a healthier you.
Table 3: Positive elements for yogurt, viz., those elements which drive the rating of a vignette towards definitely buy/probably buy). All elements shown have positive coefficients of +2 or higher.
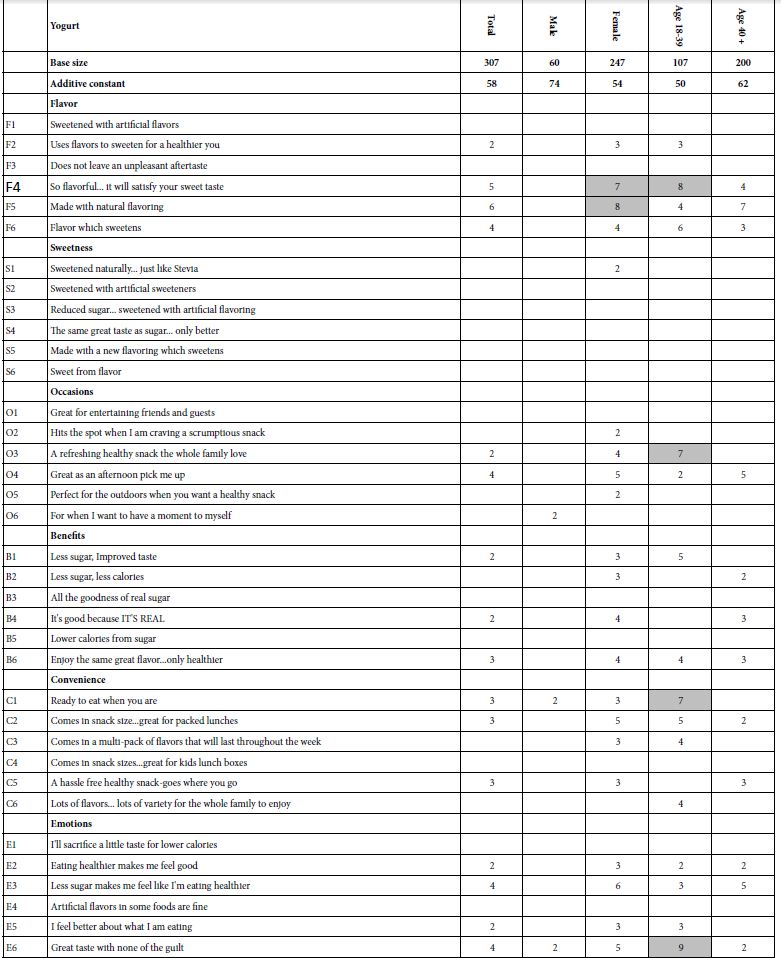
Table 4: Strong performing elements for yogurt, for divisions of respondents into two complementary mind-sets, and then into four complementary mind-sets. All elements shown have positive coefficients of +10 or higher.
Part 2 – Messaging the Shopper
One thing we learn from Tables 1 and 3 versus Tables 2 and 4 is that when we look for a strong message for the total panel, we will not find any strong message for Total Panel, for either food. Tables 2 and 4 tell us that when we divide the shoppers in two mind-sets, the one mind-set for each food is ready to buy the food, whereas the other, complementary mind-set can be persuaded to buy, but only when the correct messages are ‘beamed’ to this second group of shoppers. It is to the task of finding this group of shoppers and then sending them the correct messages in the store to which the paper now turns. One of the perplexing problems of knowing mind-sets is the difficulty of assigning a random individual to a mind-set. The reason is simple, but profound. The mind-sets emerge out of the granularity of experience, and are based on the response of people to small, almost irrelevant pieces of communication. We are not talking about issues which are critical to the shopper, issues such as health, income, and so forth, and the decisions one makes about them. Those topics are sufficiently important to people to merit studies by academics and by interested professionals. A great deal of money is spent defining the preferences of a person, so that the sales effort can be successful. Not so with topics like cereal and yogurt, where there is knowledge, but little in the way of knowing the preferences of a particular shopper. Companies which manufacturer cereal and yogurt ‘know’ what to say, but the revenue to be made by knowing the preferences a randomly selected individual is too little to warrant deep investment. To understand the preferences of a randomly selected individual may require one of two things. The first is extensive information about that individual, and a way to link that knowledge to one’s preference about what to say about cereal or about yogurt. That exercise could happen, at least for demonstration purposes, although it does not lend itself to being scaled, at least with today’s technology. Another way is to present the person, our shopper, with the right messages for that shopper. This latter approach requires a way to identify the shopper, and to assign the shopper to the proper mind-set, with low investment, in a way that can be done almost automatically. This second approach has to reckon with practicalities, such as the reluctance of the shopper to provide personal information, the potential disruption of the knowledge-gathering step to the shopping experience, and of course the need to find the appropriate motivation. The proposed process has to be simple, quick, easy to implement. Most of all, the process should motivate the shopper to participate. The answer to the question of ‘how to assign a shopper to a mind-set’ comes from the use of a simple questionnaire called the PVI (personal viewpoint identifier; Gere et al., 2020; Moskowitz et al. 2019). The PVI uses the data from the Tables 2 and 4, to create a set of six questions having two answers (no/yes; not for me/for me, etc.) The questions come from the 16 elements, and are chosen to best differentiate between the two (or among the three) mind-sets. The important thing to keep in mind is that the PVI emerges directly from reanalysis of the data used to create the mind-sets. It will be the pattern of answers to the PVI which will assign a person to one of the mind-sets. With two products, and thus 12 questions, the PVI ‘step’ should take about a minute. The motivation might be lowered price for participants for some products, such as cereal and yogurt.
Figure 1 show the PVI, completed by the shopper at the start of the shopping effort or even ahead of visiting the store. Figure 2 shows a screen shot of the database, in which each shopper who participated is assigned to one of the two mind-sets for cereal, and one of the two mind-sets for yogurt.
Here is a sequence of four proposed steps to test the approach.
- At the start of the shopping the individual could be invited to participate, by completing a short questionnaire on a computer, the PVI tool shown in Figure 1. The incentive could a special ‘participant’s pricing’ for the cereal or the yogurt. The objective is to get the shopper to participate, discover the shopper’s membership in a mind-set (in return for the promise of a lower price), and have the shopper interact, with the program assigning the shopper to the correct mind-set for one or several products. The opportunity further remains to engage the shoppers off-line, ‘type’ their preferences for dozens of products, and place ‘intelligent’ signage with the proper message for the two or three mind-sets emerging for each product. Thus the data would be granular, by person, and by product.
- Once the data has been acquired and put into the database, the shopper should be furnished a device linked to the database, with the shelf location linked both to the database, and to the shopper’s portable device.
- When the shopper reaches the appropriate store location, an ad for the product should be flashed on to the screen of the device, the ad possibly paid for by a vendor of yogurt or cereal. The ad should be the name of the vendor, the product type, and the appropriate message for the shopper, based upon the shopper’s assignment to the mind-set.
- The performance of the system can be measured by comparing the purchases of cereals and/or yogurt, comparing those who participated versus those who did not.

Figure 1: The PVI (personal viewpoint identifier) for the cereal and yogurt, completed before the shopper begins, or completed at home. The website used to acquire the information is: https://www.pvi360.com/TypingToolPage.aspx?projectid=2317&userid=2.
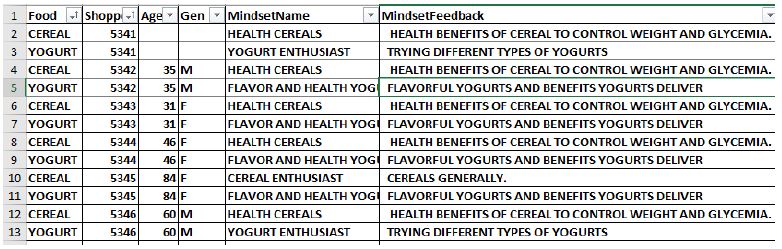
Figure 2: Example of a database attached to the PVI which records the mind-set to which the respondent belongs and the recommended types of messages for that mind-set.
Selecting the Specific Messages to Show to the Shopper
Up to now we have focused on the science of the effort, figuring out the existence of mind-sets, the messages about cereal and yogurt to which they are most responsive, and then the creation of a simple tool, the PVI, to assign a person to a mind-set. We now face the most important task, selecting the messages that will be flashed to the shopper at the right time (e.g., when the shopper is passing the specific product, and the objective is to get the shopper to select the product). Keep in mind that up to now the effort to learn about the mind-set of the shopper has been brand-agnostic. That is, the objective has been to identify what messages differentiate the two kinds of cereal shoppers and the two kinds of yogurt shopper. In the real world, it is necessary to drive the shopper towards the appropriate brand, using the appropriate message. If we remain with two mind-sets, and concentrate on shopping, we need not worry about Mind-Set 2. Mind-Set 2 for cereal has an additive constant of 68. They are ready to buy. They should be directed to the ‘brand’. It is Mind-Set 1 which must be convinced, since Mind-Set 1 has an additive constant of 38. They need motivating messages. Here are the two strongest messages for Mind-Set 1
O2 A tasty breakfast choice makes it easy to maintain a healthy body weight 15
O4 Ideal choice for those concerned about eating too much sugar 10
The same dynamics hold for yogurt. The additive constant is 72 for Mind-Set2, and 39 for Mind-Set 1. Mind-Set 2 is already primed to buy yogurt, and again should be directed to the ‘brand’. Mind-Set 1 with a low additive constant of 39 needs motivating messages, along with the brand. They have eight messages which score well in expected motivating power, and of those eight, three which score very well with coefficients 14 or higher.
- F5 Made with natural flavoring 17
- F4 So flavorful. it will satisfy your sweet taste 16
- C2 Comes in snack size… great for packed lunches 14
- B2 Less sugar, less calories 12
- C5 A hassle free healthy snack-goes where you go 12
- B4 It’s good because IT’S REAL 11
- C1 Ready to eat when you are 11
- F2 Uses flavors to sweeten for a healthier you 10
Discussion and Conclusions
One need only read the trade magazines about the world of retail to recognize that the world is becoming increasing aware of the potential of ‘knowledge’ to make a difference to growth and to profits. Over the past half century, knowledge of the consumer has burgeoned in all areas of business, with the knowledge often making the difference between failure and success, or more commonly today, the magnitude of success. We are no longer living in a business world dominated by the opinions of one person in the management of a consumer-facing effort. Whereas decades ago it was common for the key executives to proclaim that they had a ‘golden tongue’ which could predict consumer behavior, today just the opposite occurs. Managers are afraid to decide without the support of consumer researchers, or as they title themselves, ‘insights professionals.’ At the level of shopping, especially when one buys something, or even searches for something, there are programs which ‘follow’ the individual, selling the data to interested parties that use that information to offer their own version of that for which the individual was shopping. The tracking can be demonstrated by filling out a form or a product or service, not necessarily buying such a product. The outcome is a barrage of advertisements on the web for that product, from a few different vendors offering their special version. The Mind Genomics approach presented here differs from the current micro-segmentation on the basis of previous behaviors demonstrated on the internet. Rather than watching what a person does to put the person into a specific grouping, or rather than applying artificial intelligence to the text material produced by the person, Mind Genomics moves immediately to granularity. The basic science of the topic (viz., messages for cereal, or messages for yogurt) is established at a convenient time, using language that the product manufacturer selects as appropriate for a customer. The important phrases and the relevant mind-sets are developed inexpensively, and rapidly, perhaps within a day. The PVI is part of that set-up. The next steps involve the shopper herself or himself. What emerges is a system wherein the shopper plays a simple but active role, and through a few keystrokes identifies the relevant group(s) to which she or he belongs. Once the shopper encounters the appropriate location, it is only a matter of sending the shopper the appropriate message. The ‘appropriate location’ can be the store shelf where the product is displayed, or on the web at an e-store, or even when the prospective shopper searches for the item. Both the item and the relevant motivating messages can be sent to the shopper, as long as the shopper’s membership in the appropriate mind-set can be determined.
References
- Schumann DW, Grayson J, Ault J, Hargrove K (1991) The effectiveness of shopping cart signage: Perceptual measures tell a different story. Journal of Advertising Research. 31: 17-22.
- Dennis C, Michon R, Brakus JJ, Newman A, Alamanos E et al. (2012) New insights into the impact of digital signage as a retail atmospheric tool. Journal of Consumer Behaviour 11: 454-466.
- Büttner OB, Florack A, Göritz AS (2013) Shopping orientation and mindsets: How motivation influences consumer information processing during shopping. Psychology, Marketing 30: 779-793.
- Chang CT, Cheng ZH (2015) Tugging on heartstrings: shopping orientation, mindset, and consumer responses to cause-related marketing. Journal of Business Ethics 127: 337-350.
- Gere A, Harizi A, Bellissimo N, Roberts D, Moskowitz H (2020) Creating a mind genomics wiki for non-meat analogs. Sustainability 12, 5352.
- Gofman A and Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145.
- Moskowitz H, Gere A, Moskowitz D, Sherman R, Deitel Y (2019) Imbuing the supply chain with the customer’s mind: today’s reality, tomorrow’s opportunity. Edelweiss Applied Sci Tech 3: 44-51.
- Likas A, Vlassis N and Verbeek JJ (2003) The global k-means clustering algorithm. Pattern Recognition 36: 451-461.