Abstract
54 respondents from an internet-based panel across the United States each evaluated uniquely different sets of 24 systematically varied ‘vignettes,’ (combinations of messages) about elderberry wine. The messages were created by artificial intelligence (Idea Coach), and afterwards combined into the vignettes according to an underlying experimental design which prescribed the appropriate combinations to use for subsequent regression analysis. Respondents rated each vignette using a two-dimensional rating scale, one dimension representing fit to the respondent (for me vs not for me), the second dimension representing understandability of the message. The data reveal three mind-sets. The study demonstrated the simplicity, speed, and economics of combining artificial intelligence, experimental design, and subsequent human evaluation. The output becomes a scalable bank of subjective information on a topic which is unfamiliar (elderberry wine), with this bank of information combining Socratic learning in a new topic coupled with feedback from real consumers about the information developed through artificial intelligence.
Introduction
The development of new products in the world of commerce is often costly, error-filled, and unduly long. Some of the issues may result from risk-avoidance, a phenomenon rampant in corporations, especially in slow-moving categories such as foods and beverages. When a company in electronics, for example, fails to avail itself of important technology to create new products that company is likely to suffer, often quickly, as its competitors rush to overtake it, doing so at hot speed. Not so in the world of food, even the world-of food start-ups, where the feeling is that there is not really much risk, that the competition moves slowly, and the technology is really not as valuable as the instincts and intuitions of the entrepreneur or the corporate president. The foregoing holds in classic, multi-layer multi-nationals as well as in the starts powered by the ingenue entrepreneur.
At the same time that the world of food development moves cautiously, there is an evolving world of speed, at almost any price. This world has emerged during the past decades due to the confluence of three factors, respectively the computer for processing, the internet for connection, and most recently artificial intelligence (AI) for rapid ‘thinking’ or at least rapid and seeming intelligent processing of text information in a way which seems intelligent. These three factors are making it possible to create ideas, test these ideas, and even expand them in what figuratively be an ‘eyeblink’ in the corporate timeline. What took hours, days, weeks, now can take minutes and seconds.
With the foregoing paragraphs as background, the author has begun a series of studies, small studies to be sure, on topics of daily life. The approach uses experimental design of ideas, mixtures of ideas presented to the respondent, the ratings of these mixtures revealing how each idea or message ‘drives’ the interest of the respondent. Using these tools of computer, internet, and now artificial intelligence, the author has pushed the study of ideas in the food industry down from a pedestal of scientific perfection to an act that even a grade school student can do, and even master after a moderate amount of practice [1-3].
The Mind Genomics Approach – Steps Towards Rapid Ideation
In order to demonstrate the power of new methods for product design, the author conducted a class experiment in April 2023, with students from the University of Florida in Gainesville. The approach was a DIY (do-it-yourself) approach for an advanced version of conjoint measurement, Mind Genomics. The specifics of Mind Genomics have been presented in detail in various papers published since the early days of the 21st century. The reader is encouraged to look at the different topics covered. This paper will once again present the method, and the new development enabled by popular and available methods for artificial intelligence using the popular Chat GPT [4-6].
The ingoing, perhaps heretical and counterintuitive assumption, was that one could do a study within two hours, a study beginning with little or no knowledge about a field and emerge after those two hours with deep information about a topic. The topic chosen during the active initial back and forth was ‘elderberry wine,’ a wine of Asian origin (No et. al., 1980). The students who designed study had heard of elderberry wine, but were not familiar with the wine, making the exercise a challenge and enjoyable learning experience. The choice of elderberry wine emerges after about an unmoderated, 20-second class ‘discussion’ about ‘a topic, any topic having to do with foods.’
There is a modest-sized literature about elderberry wine, but a growing one, because of due to evolving consumer interest. At the same time, elderberry has received attention by horticulturists as well in part because of the increasing recognition of its health properties [7-11].
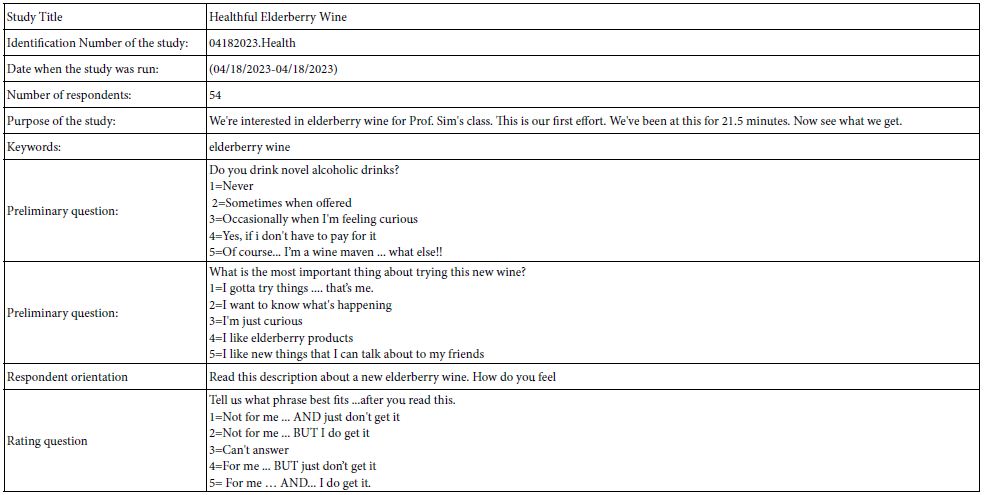
Table 1 presents the input information about the study. The table comes from a summarized report of the study automatically generated at the completion of the field work. The table provides the study title, date, purpose of the study as the researcher defines it, keywords for later sorting, self-profiling attitude questions, the respondent orientation (kept very simple), and the rating scale. All of this information is automatically incorporated into the Excel report.
The Mind Genomics process is templated, following choreographed sets which set up the experiment, run the actual experiment, and automatically analyze the data.
Table 1: Information about the study provided by the Excel report returned to the researcher at the end of the field work.
Introduce to the Process and Select the Topic (Elderberry Wine)
The exercise was set up so that the students would be introduced to the Mind Genomics process through a two-minute ‘elevator pitch’. The class was told that they would choose a topic, run a study, get results, and discuss the preliminary results. The students we unprepared, but as noted above, the decision was made to study elderberry wine. It is important to note that in no way was the topic to be focused on a so-called ‘burning issue’ or ‘hole in’ literature. The topic was selected almost randomly. It was at this point that the study had been registered as ‘elderberry wine’, the class as researchers filled out some checklists on using English as the language, and agreeing to not obtain information that could identify the respondents, except with the permission of the respondents.
Create Four Questions through Idea Coach
Mind Genomics works by a Socratic method, posing questions to obtain answers, combining the answers, and having respondents evaluate the combinations. Figure 1 shows the screen requesting the four questions (left panel), and the four questions actually selected (right panel).
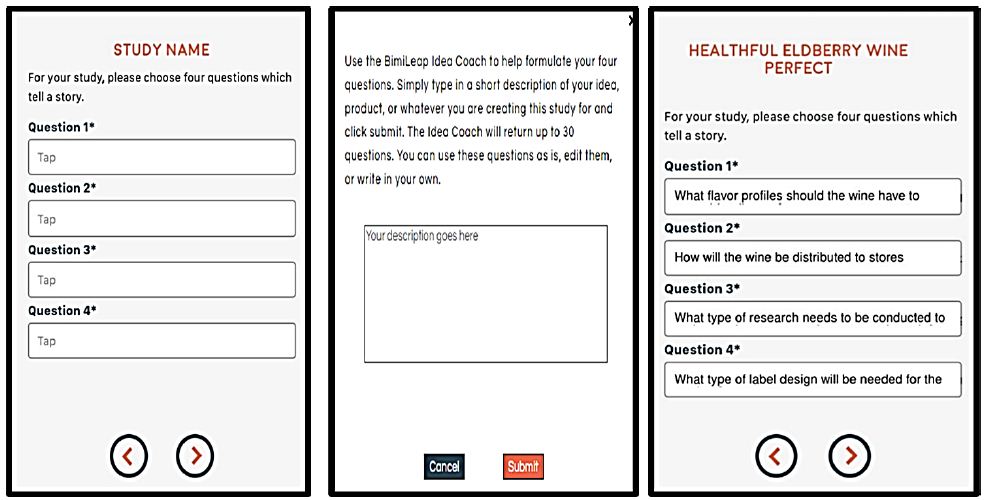
Figure 1: The request for four questions dealing with elderberry wine (left panel), the Idea Coach for generating questions through AI (middle panel) and the four questions selected from the AI suggestions (right panel).
To generate the four questions in Table 1 is generally a function of one’s familiarity with the topic, and the predilection of the research group to come to an agreement. Often the group is unfamiliar with the topic, necessitating what ends up being interminable discussion and delay as the individuals in the group grapple with the appropriate questions to ask. The issue becomes even more vexing when the parties feel that they only have ‘one chance’ to run the experiment. It is at that point, the feeling of one-chance-only, that the participants in the research program end up ‘freezing’, often with the unhappy consequence that the project falls apart.
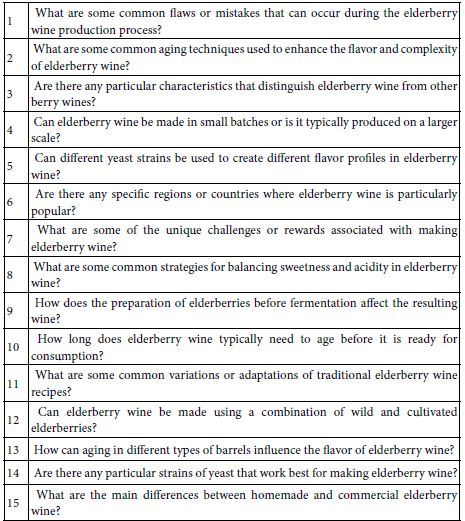
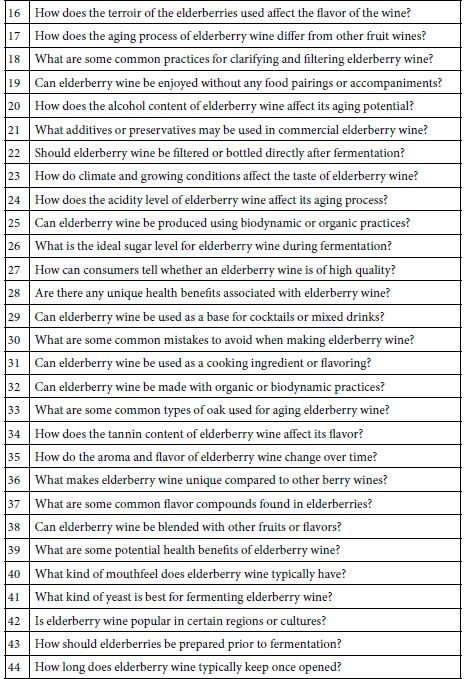
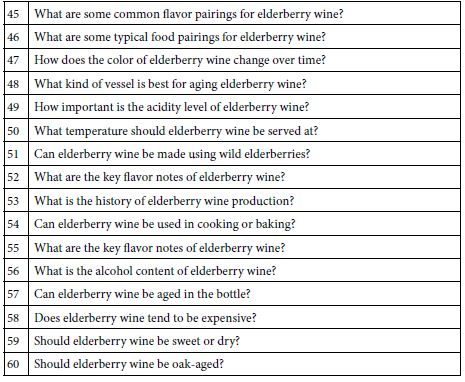
During the past several years users have continued to request, and eventually insist that the set-up of a Mind Genomics experiment be more ‘user-friendly.’ Almost all suggestions have included something about making it easier to generate questions, and to a lesser degree, to generate answers to the questions. As an aside, it appears that instead of trusting their own intuition and thinking, many individuals prefer ideas that have somehow been ‘vetted.’ This desire to have assistance in creating questions and answers, that assistance provided by an electronic ‘third party’, led to the creation of the Idea Coach. The Idea Coach is simply a set of AI prompts, based upon the ‘squib’ written about the topic. The squib is submitted to the AI program embedded in the setup, and generates 25-30 questions. Table 2 shows 60 unique questions emerging from four passes though the Idea Coach. With 30 questions there should have been 120 questions, but only 60 were different from each other.
Table 2: 60 unique questions emerging from four runs of the Idea Coach, each run returning a set of 30 questions about elderberry wine.
Create Four Answers to Each Question through Idea Coach
Idea Coach once again uses artificial intelligence to generate sets of 15 answers to each question. The researcher can select the answers of interest and edit them. Table 3 shows the answers for the first question (flavor profile) from three consecutive iterations of answers. In this case the 45 answers differ from each other. Figure 2 shows the screenshots of the final set of answers to the four questions selected.
Table 3: Three sets of answers to the first question (flavor profile)
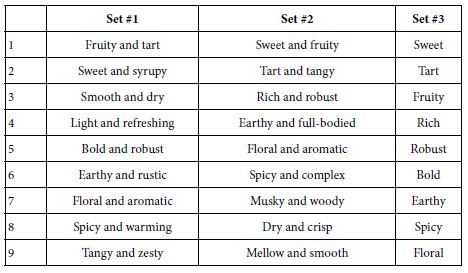
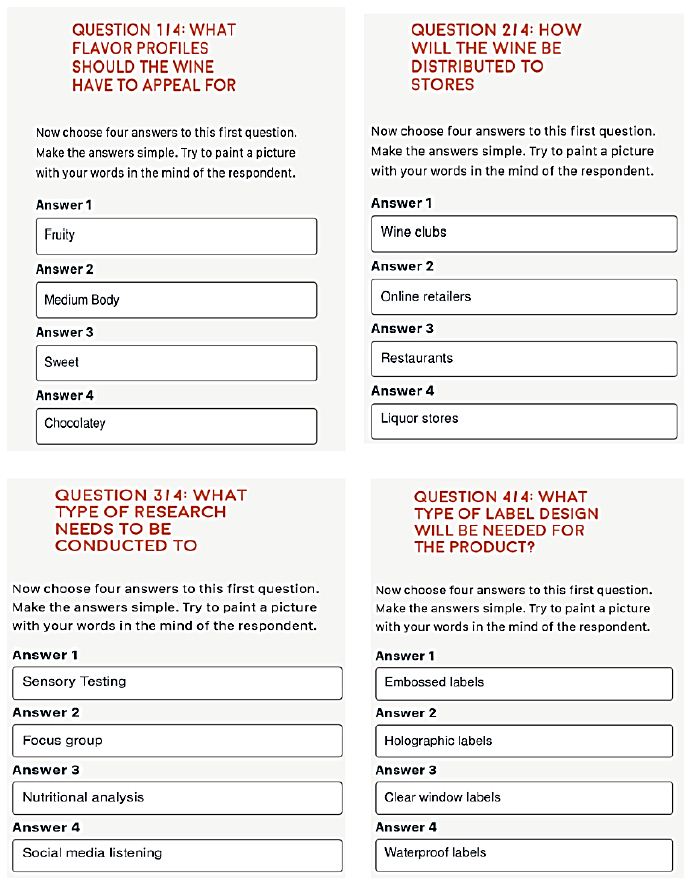
Figure 2: Screen shots of the four answers to each question
The mechanism by which Idea Coach provides the questions and answers remains a trade secret of the company providing the AI system. What is important, however, is the rapid ‘learning’ by the Socratic method, question-and-answer, although here the learning might be in from parallel questions and answers, as the squib generates 25-30 questions, and the question generates 15 answers. One might happily imagine the potential of educating oneself on a topic such as elderberry, simply by two, three, four, or even five iterations of squib → 25-30 candidate questions → 15 candidate answers for each candidate question.
Create an Experimental Design Which Specifies the Combinations of Elements (Answers)
Rather than instructing the respondent to rate each of the 16 elements, one element at a time, the Mind Genomics approach presents combinations of these elements, short descriptions of the wine. Short descriptions are easier to judge because they tell a more complete story than do single elements. The respondent will evaluate a set of 24 vignettes, the aforementioned combinations.
In the experimental design element (viz., answer) appears five times in the 24 vignettes and is absent 19 times. No vignette comprises more than one element from any question. As a consequence, 20 of the 24 vignettes contain one answer from a question, whereas four vignettes of 24 are absent answers. Finally, across all 24 vignettes there are combinations comprising two answers, three answers, and finally four answers, but no vignette with only one answer. This specific design ensures that the researcher can analyze the data using standard statistical tools such as OLS (ordinary least squares) regression [12].
A unique, patented aspect of Mind Genomics is that each respondent evaluates a different set of combinations. The mathematical structure of the combination remains the same, but the specific combinations differ from one respondent to another. This difference is created by a permutation scheme described by [13]. The benefit of the permutation scheme is that the researcher need not know anything about the topic. The experiment allows the researcher to explore a great many combinations, analyze the data at the level of the individual respondent, and as a result uncover patterns that might not even have been imagined at the start of the study.
Create an Orientation and then Create the Rating Question that the Respondent Uses to Evaluate the Vignette. The Orientation is Simple: Read this Description about a New Elderberry Wine. How Do You Feel?
The rating scale actually comprises two dimensions. The first dimension is interest (Not for me vs For me). The second dimension is understandability (don’t get it versus get it). The two dimensions allow the researcher to understand the mind of the respondent more deeply, both in terms of emotion (for me / not for me) and intellect (get it / don’t get it).
Tell us what phrase best fits …after you read this.
1=Not for me … AND just don’t get it
2=Not for me … BUT I do get it
3=Can’t answer
4=For me … BUT just don’t get it
5=For me … AND… I do get it.
Create Self-profiling Questions
The Mind Genomics process enables the respondent to profile herself or himself on attitudes that would not be known from knowing who the response IS. At the start of the study the researcher can create up to eight such self-profiling questions. In addition, the Mind Genomics process automatically asks the respondent’s age and gender. The foregoing information (self-profiling as well as age and gender) are attached to the data provided by the respondent when rating the vignette. The self-profiling information will be used to create subgroups. Figure 3 shows an example of a self-profiling question. The Mind Genomics program allows the researcher to create up to eight such self-profiling questions, each with eight answers.
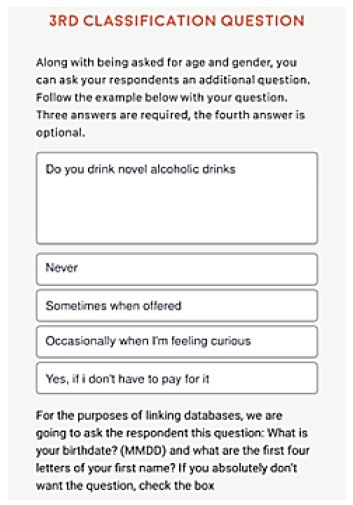
Figure 3: One of the self-profiling questions
‘Field the Study’ with Respondents
Figure 4 shows the information that the researcher provides to the Mind Genomics program. This information includes the number of respondents, how the respondents will be sourced, and whether or not the researcher wants to ‘privatize’ the respondent data. As of this writing (May 2023), the Mind Genomics platform is very low cost for the artificial intelligence (Idea Coach and summarization in the results). The researcher can either provide her or his own respondents at a low cost ($2/respondent for processing), use a third-party group ($2/respondent for processing), or use a Mind-Genomics approved supplier (Luc.id), with an approximate per respondent fee of $4-$6 for recruiting and processing. The researcher can make the data fully private for an extra $2/respondent. In this way the Mind Genomics fees can be kept very low, a boon to students who can explore a topic in depth, and actually run a small (or large study) on elements of interest, if desired.
Not shown is the set of screens which allow the researcher to specify country, age range, gender, education, income, children, and so forth for the respondent. The typical ‘field time’ to execute the experiment is about 60 minutes for 100-200 easy to find respondents.
Figure 4: The researcher specifies parameters about the field execution
Create the Database
Each record of the database corresponds to a vignette. The record has these columns:
Column 1 – Study name
Column 2 – Respondent identification number
Columns 3,4 – Age, Gender Columns 5-6 – Answers to the two self-profiling questions created by the researcher
Columns 8-23 – One column for each of th 16 elements. When the element is absent from the particular vignette, the cell has the value 0. When the element is present in the particular vignette the cell has the value 1. This is called ‘dummy coding’.
Column 24 – Test order of the vignette. Each respondent rated 24 vignettes, so the test order ranged from the first vignette tested (coded 01) to the last vignette tested (coded 24)
Column 25 – Rating assigned by the respondent to the vignette.
Column 26 – Response time in 100ths of a second, defined as the elapsed time between the presentation of the vignette on the screen and the time that the respondent assigned the rating.
Column 27-30 – Create four new binary variables by a re-code of the rating to a binary valuer 0 or 100 (as well as the addition of a vanishingly small random number to the newly created binary variable)
Column 27 – Create variable ‘For Me.’ Ratings 5, 4 re-coded to 100, rating 3, 2,1 re-coded to 0.
Column 28 – Create variable ‘Not for Me’. Ratings 1, 2 re-coded to 100, 3,4,5 re-coded to 0.
Column 29 – Create variable ‘Get It’. Ratings 5,2 recorded to 100, rating 4, 3, 1 re-coded to 0.
Column 30 – Create variable ‘Don’t Get It’. Ratings 4,1 re-coded to 100. Ratings 5,3,2 re-coded to 0.
The database is set up for dummy variable regression analysis, either at the level of the individual respondent or at the level of the group. The original experimental design specified 24 different combinations, with the combinations being precisely those which ensure that each element appears equally often, and that each of the 16 elements are statistically independent.
The analysis will focus only on the ‘For Me’ ratings.
Create Equations (Models) Relating the Presence/Absence of Elements to Ratings
The equations are estimated using OLS (ordinary least squares) regression. For this analysis we express the equation in the standard way, using an additive constant:
Binary Variable = k0 + k1(A1) + k2(A2) … k16(D4)
The additive constant, k0, shows the expected percent of responses to be assigned if there were no elements in the vignette. Of course, by design, all vignettes comprise a minimum of two and a maximum of four elements so that the additive constant should be considered a baseline.
Search for the Patterns
The patterns should emerge from the coefficients for the dependent variable ‘For Me’ (ratings 5 and 4 converted to 100, ratings 1,2 and 3 converted to 0). Table 4 shows the coefficients for total panel and for binary gender (male vs female). Mind Genomics returns with a great many coefficients. Table 4 and the remaining tables of coefficients (for mind-sets) show only the positive coefficients, viz, those 2 or higher.
Table 4: Performance of the elements by total and gender using R54 (For me) as the dependent variable. Only positive coefficients, 2 or higher, are shown.
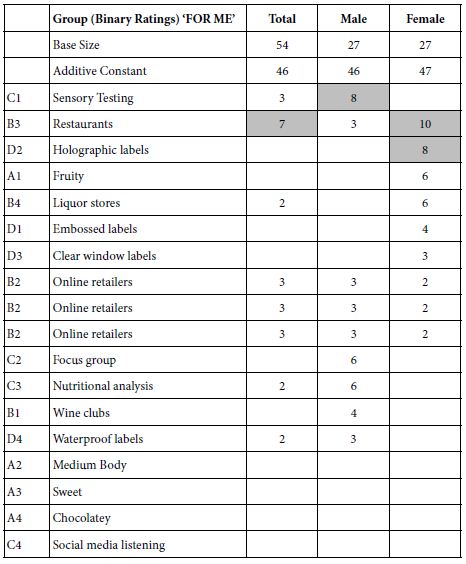
The additive constant gives a sense of the percent of responses that would be 5 or 4 for vignettes that were empty, viz, absent elements. By design this is not possible, but the regression process can estimate this additive constant, which is typically considered to be a correction factor (Burton, 2021). Table 4 shows the additive constant to be about 46-47, suggesting that half of the time we can expect a rating of 4 or 5 for vignette or concept about elderberry wine, even when no elements to deeper detail.
Table 4 suggests that in terms of ‘interest’ (viz., For Me), a few elements perform strongly, and in fact elements that might not have been even thought of without the use of the AI-powered Idea Coach. These are ‘sensory testing’ for males, and ‘restaurant’ and ‘holographic labels’ for females. The benefit of creating elements with the assistance of AI is just this ‘out of the box’ thinking, with the researcher having the power to accept the suggestion or reject the suggestion by simple choice, and indeed to test the suggestion again in an easily run of the study with some new elements, new respondents.
Uncovering New-to-the-World Mind-Sets through Clustering
It is in the DNA of the scientific mind to look for basic causes, fundamentals of a situation. Although scientists and consumer researchers have attempted to develop profiles of archetypes, idealized profiles, these archetypes are too general, and fail to capture the granularity of everyday experience. Indeed, any attempt to divide people from the ‘top down’ is destined to fail because at the level of actual experience there are so many idiosyncratic factors that the archetypes simply do not have the ability to address [14].
The Mind Genomics approach works in the opposite direction, starting at the level of granular for a specific issue or situation, looking at the different dimensions of that granular situation, testing alternatives or expressions of each dimension, and then uncovering parallel groups of individuals or clusters for that situation. The clusters can be thought of as archetypes, not general ones, but archetypes of a specific situation, mind-sets in the language of Mind Genomics.
The statistics of Mind Genomics readily enable the researcher to discover these mind-sets, even without any ingoing knowledge. The approach simply creates individual level models of the type above shown for the total panel, or for any subgroup. Each individual generates a model, a model which is statistically valid because the 24 vignettes for each respondent had been created according to an underlying experimental design. The 24 vignettes are precisely arrayed to allow for OLS regression to be done on the data from each respondent. Each respondent produces 16 coefficients and an additive constant. Afterwards, the respondents are clustered by k-means clustering [15] first into two non-overlapping and exhaustive groups, (2-mindset solution), and then into three non-overlapping and exhaustive solutions (3-indset solution).
Clustering it follows purely mathematical criteria, e.g., minimize the sum of ‘distances’ between people in a cluster while at the same time maximize the distances between the centroids of the different clusters. It is left to the researcher to choose the number of clusters or mind-sets, and to name each cluster. Two good criteria are parsimony (fewer clusters are better), and interpretability (the clusters must tell a reasonably clear story).
For Mind Genomics studies, the measure of distance is the expression (1-Pearson Correlation). The Pearson Correlation coefficient measures the strength and nature of the linear relation between two sets of numbers, in our case the numbers coming from the 16 coefficients. The distance is small, viz., 0, when the Pearson correlation is +1 (1-1 = 0), occurring when the two sets of coefficients are parallel to each other. The distance is greatest, viz., 2 when the Pearson correlation is -1 (1 – 1 = 2), occurring when the two sets of coefficients go in precisely opposite directions.
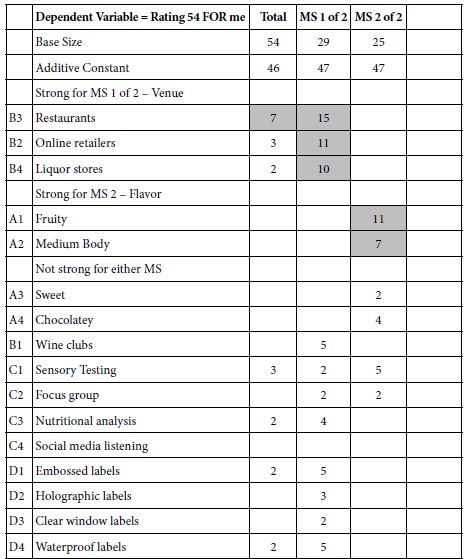
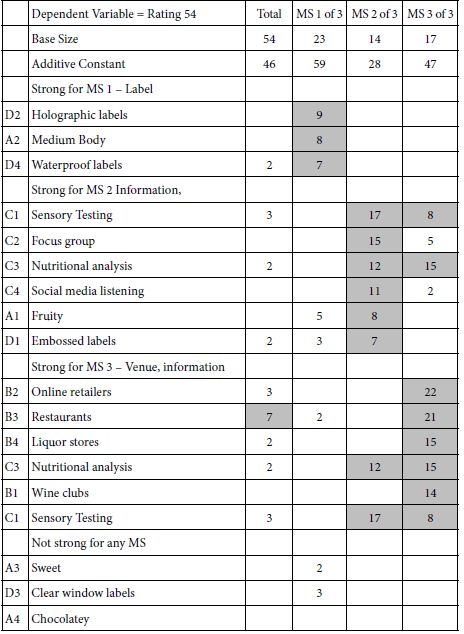
Mind Genomics clustering usually reveals quite simple groups, the patterns often clear, ‘jumping out’ at the researcher. Table 5 shows the strong performing elements for the two and then the three mind-sets (abbreviated MS). The two mind-sets solution shows a very simple pattern, namely that which is familiar (venue for MS1 versus flavor for MS2). The three-mind-set solution is more intriguing, suggesting Label, Information, Venue, respectively. The three-mind-set solution is not perfect, since there are some strong-performing elements appealing to the mind-set slightly ‘off’ from the main interest of the mind-set.
Table 5 once again shows the ability of the OLS regression to uncover relevant coefficients, often coefficients which ‘make sense’ in their similarity to each other for a specific mind-set.
Table 5: Performance of the elements by total and both two and three mind-sets. gender using R54 (For me) as the dependent variable. Only positive coefficients, 2 or higher, are shown.
How Good are the Results?
Experienced researchers working in the world of inferential statistics and hypothesis testing measure their ‘performance’ by the likelihood that their hypothesis has not been falsified (Sprenger, 2011). The hypothetico deductive system of science is geared toward the creation, testing, acceptance/abandonment of hypothesis as the science moves slowly along. As famed scientist Max Planck opined ‘science advances one funeral at a time’ [16]. an experienced-based aphorism similar to the somewhat longer, more poetic but equally powerful idea from Tennyson’s Le morte d’Arthur “The old order changeth, yielding place to new, … Lest one good custom should corrupt the world “ (Sider, 2013).
With the evolution of research and its introduction into the world of education and application, the introductions often geared to ‘newbies’ (people without research experience), a common question is ‘how did we do?’. These newbies, students, others, do not have the wealth of experience, the years of data analysis, and the know-how about going to the extant ‘literature’ to compare their findings with what has been done. These newbies, aspiring researchers, need reinforcement about their work, e.g., a ‘score’ which tells them just how good their data are. In our over-measured society people use scores as an index of performance and a measure of growth.
One of the developments of Mind Genomics is the IDT, the index of divergent thought. The organizing principal underneath the IDT is that the positive coefficients, or more correctly the weighted positive coefficients, show how strongly the element ‘drives’ the rating. In other words, the IDT show how ‘on target’ the researcher has been by choosing elements to drive a dependent variable, that dependent variable here being ‘For Me.’
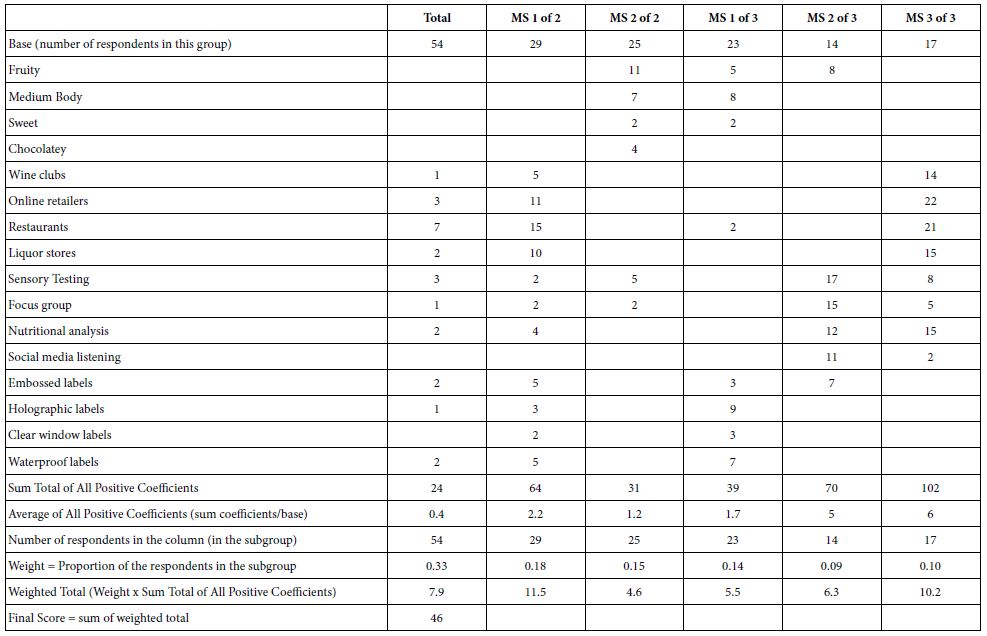
The IDT computations appear in Table 6. The total panel results account for 1/3 of the weight; the two mind-sets together account for 1/3 of the weight, and finally the three mind-sets together account for 1/3 of the weight. The stronger the performance of the coefficient for the total panel, the higher will be the IDT because that single high coefficient will in turn be multiplied by the value 0.33 for the total panel. In contrast, consider the value of that same high coefficient, but this time for MS 2 of 3, with 14 respondents, and a weight around 0.10. The contribution will be a lot lower. For this study the IDT is 46, reasonable. Unpublished values for the IDT in other studies have ranged from a high around to a low around 20.
Table 6: The IDT (Index of Divergent Thought)
Were the researcher to systematically vary aspects of the study and then measure the IDT for each aspect, the studies would move beyond informing about the world, and become a measure of the ‘impact’ of the different variables. Perhaps, most important for students is a measure of how well they understand the topic based upon the elements they select, the rating scale they use, the respondents they choose, and their experience as they iterate from one study to the next with clear human feedback. Much remains to be done.
Summarizing the Results Using Artificial Intelligence
The original objective of the study was to demonstrate the speed, power, and cost of Mind Genomics. As such, one of the goals was to see how quickly the key insights could be given to the reader in a format immediately ready for further efforts, including application or follow-on research. The first requirement was that the insight to be presented had to emerge in a robust way from the data, thus linking the insights to the actual experiment. The second requirement was that the insight had to be multifaceted, produced by clearly stated queries. The third requirement is that the insights had to be scalable, emerging from a few to many queries (many being > 10), with the insights emerging automatically. The effort stopped short of automatically creating a preliminary summarization document in the form of a ‘working paper’, but that next step is increasingly within reach. This first step to summarize the results used six queries provided to the AI program, with the instruction to look only at elements scoring +6 or higher for the subgroup.
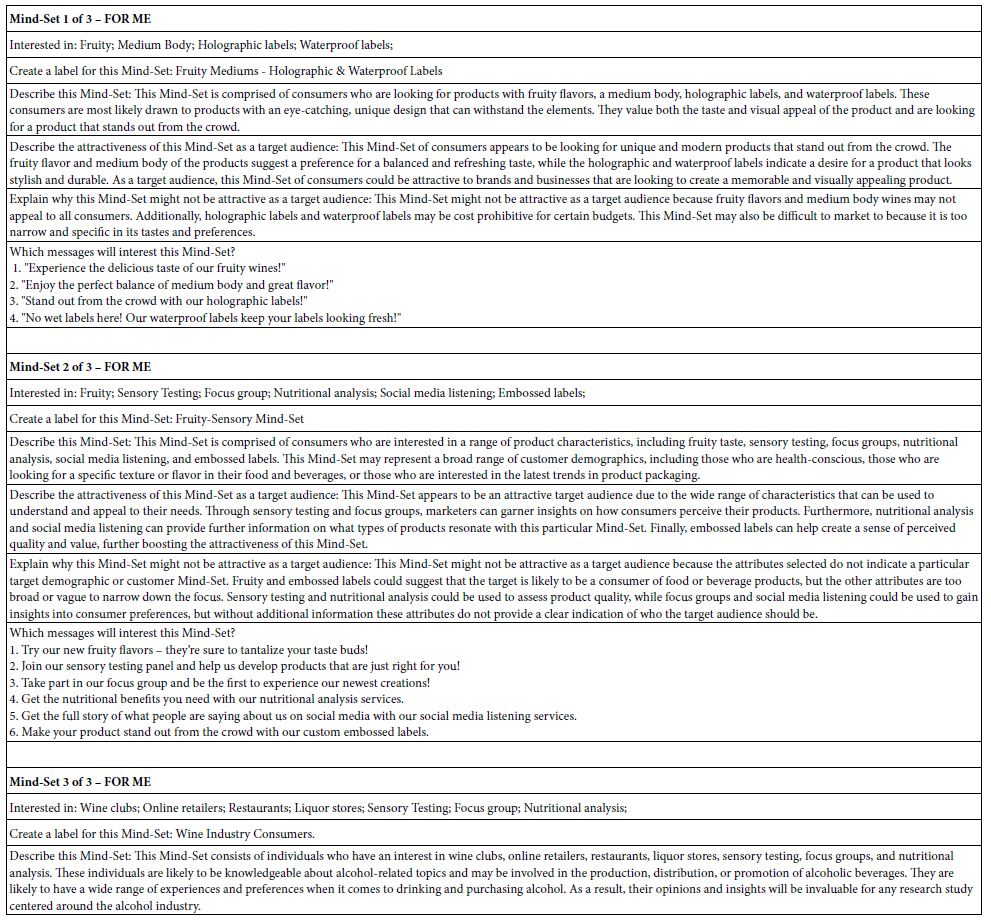
The six summarization queries were submitted to the AI program, with the summarization done for each defined subgroup in the population, and done twice, once for the ‘TOP” (ratings 5,4 → 100), once for the ‘BOT’ (ratings 1,2→ 100). The defined subgroups were gender, age, response to the various questions in the self-defining questionnaire at the start of the study and finally to the two and the three mind-set solutions. Table 7 shows the summarization of the results for each of the three mind-sets for the TOP values (Rating 5,4, for ME).
Table 7: AI summarization of the three mind-sets
Discussion and Conclusions
The tradition of scientific research has become increasingly professionalized during the past centuries. What started out as the explorations of amateurs into a world hardly known has evolved into the world of science and academe that we know today., replete with societies, with journals, with the inevitable issue of who can publish what, and of course what exact constitutes publishable work. If that is not sufficient, the issues emerging involve the invisible networks of researchers who know each other and give each other help or in some unhappy cases just the opposite. And finally, there is the issue of funding research, funding publication and the need to survive the publish-or-perish world. In the words of an unnamed colleague, ‘we are all fighting for a sliver of the unpredictable funding pie.’
Within this world of discomfort and competitive behavior, the efforts of students, aspiring professionals, end up being crushed more often than not by an invisible college and rules of what makes science valid. All too often, the focus on being safe and correct ends up discouraging the researcher. Within this world, the Mind Genomics effort produces a system which expands the vision and hope of the amateur researcher, providing the potential of systematized, scientific, often even interesting exploration. It is within that spirit that this paper is presented, not so much as the convenient but hardly explored topic of elderberry wine as much as the exploration of what people just might do if given tools to empower their curiosity.
References
- Mendoza C, Mendoza C, Deitel Y, Rappaport SD, Moskowitz HR (2023) A. Empowering young people to become researchers: What does it take to become a police officer? Psychology Journal Research Open 5(2): 1-12.
- Mendoza C, Mendoza C, Deitel Y, Rappaport S, Moskowitz HR (2023) B, Empowering Young researchers through Mind Genomics: What will third grade mathematics look like in 10 years? Psychology Journal Research Open 5(3): 1-15.
- Mendoza C, Mendoza C, Rappaport S, Deitel Y, Moskowitz H (2023) C, Empowering young researchers: Cognitive economics and the features associated with minimum wage. Ageing Science and Mental Health Studies 7(1): 1-9
- Gere A, Radványi D, Moskowitz H (2019) Consumer Perspectives about innovations in traditional foods. In Innovations in Traditional Foods, 53: 84. Woodhead Publishing (2019).
- Lieberman, L.E, Moskowitz, D.I, Moskowitz, H.R (2012) Consumer research in the wine industry: New applications of conjoint measurement. In: Alcoholic Beverages. 395- Woodhead Publishing.
- Moskowitz, H.R. Gofman A. Beckley J, Ashman H (2006) Founding a new science: Mind genomics. Journal of Sensory Studies 21: 266-307.
- Cernusca, M.M. Gold, M.A, 7 Godsey, L.D (2011) Elderberry Market Research.
- Cernusca, M.M, Gold, M.A, Godsey, L.D (2012) Using the Porter model to analyze the US elderberry industry. Agroforest Systems 86: 365-377.
- Byers, P.L, Thomas, A.L (2005) Elderberry research and production in Missouri. N Y Berry News 4: 11.
- Charlebois D, Byers P, Finn, C.E, Thomas, A.L (2010) Elderberry: botany, horticulture, potential. Horticultural Review 37: 213-280
- Finn CE, Thomas AL, Byers PL, Kemal M (2008) Evaluation of American Sambucus canadensis and European S. nigra elderberry genotypes grown in diverse environments and implications for cultivar development. Horticultural Science 435: 1385-1391.
- Burton AL (2021) OLS Linear regression. The Encyclopedia of Research Methods in Criminology and Criminal Justice 2: 509-514.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 251: 127-145.
- Lloyd S, Woodside AG (2013) Animals, archetypes, and advertising A3: The theory and the practice of customer brand symbolism. Journal of Marketing Management, 29: 5-25.
- Likas A, Vlassis N, Verbeek JJ (2003) The global k-means clustering algorithm. Pattern Recognition 362: 451-461.
- Azoulay, P.Graff-Zivin J, Uzzi, B. Wang, D. Williams H, Evans, J.A, Jin, G.Z, Lu, S.F, Jones, B.F, Börner K, Lakhani, K.R, 2018. Toward a more scientific science. Science, 361: 1194-1197. [crossref]