Abstract
The objective of Inner Psychophysics is to provide a number or a metric, on ideas, with the number showing the magnitude of the idea on a specific dimension of meaning. We introduce a new approach to measuring the values of ideas, applying the approach to the study of responses to 27 different types of social problems. The approach to create this Inner Psychophysics comes from the research system known as Mind Genomics. Mind Genomics presents the respondent with the social problem, and a unique set 24 vignettes, viz., combinations of ‘answers’ to that social problem, these vignettes created by an underlying experimental design. The respondent rates each test vignette using a scale of solvability. The pattern of responses to the vignettes is deconstructed into the contribution of each ‘answer’, through OLS (ordinary least squares) regression. The OLS regression across a group of respondents provides the psychological magnitude of the solution offered as judged so to solve the particular problem. The approach opens up the potential of a ‘metric for the social consensus,’ measuring the value of ideas relevant to society as a whole, and to the person in particular.
Introduction
Psychophysics is the oldest branch of experimental psychology, dealing with the relation between the physical world (thus ‘physics’) and the subjective world of our own consciousness (thus ‘psycho’). The question might well be asked what is this presumably arcane psychological science dealing with up to date, indeed new approaches to science? The question is relevant, and indeed, as the paper and data will show. The evolution of an ‘inner psychophysics’ provides today’s researcher with a new set of tools to think about the problems of the world. The founder of today’s ‘modern psychophysics,’ encapsulated the opportunity in his posthumous book, ‘Psychophysics: An Introduction to its Perceptual, Neural and Social Prospects. This paper presents the application of psychophysical thinking and disciplined rigor to the study of how people ‘think’ about problems. Stevens also introduced the phrase ‘a metric for the social consensus,’ in his discussions about the prospects of psychophysics in the world of social issues [1-3].
The original efforts in psychophysics began about 200 years ago, with the world of physiologists and with the effort to understand how people distinguish different levels of the same stimulus, for example, different levels of sugar in water, or today, different levels of sweetener in cola. Just how small of a difference can we perceive? Or, to push things even more, what the is lowest physical level of a stimulus that we can detect? [4]. These are the difference and the detection threshold, respectively, both of interest to scientists, but of relatively little interest to the social scientist and research, unless we are dealing in psychology, food science, or perhaps loss of sensory function due to accident or disease.
The important thing to come out of psychophysics is the notion of ‘man as a measuring instrument,’ the notion that there is a metric of perception. Is there a way to assign numbers to objects or better to experiences of objects, so that one can understand what happens in the mind of people, when these objects are mixed, changed, masked, etc.? In simpler terms, think of a cup of coffee. If we can measure the subjective perception of aspects of that coffee, such as its coffeeness’, then what happens when we add milk. Or add sugar. Or change coffee roast, and so forth. At a mundane level, can we measure how much perceived coffeeness changes?
Steven’s ‘Outer’ and ‘Inner’ Psychophysics
By way of full disclosure, author HRM was one of the last PhD students of the SS Stevens, receiving his PhD in the early days of 1969. Some 16 months before, Stevens had suggested that HRM ‘try his hand’ at something such as taste or political scaling, rather than pursuing research dealing with topics requiring sophistication in electronics, such as hearing and seeing. That suggestion would become a guide through a 54-year future, now a 54-year history. The notion of measuring taste forced thinking about the mind, the way people say things taste versus how much they like what they taste. This first suggestion, studying taste, focused attention on the inner world of the mind, one focused on what things taste like, why people differ in what they like, whether there are basic taste preference groups, and so forth. The well-behaved laws of psychophysics – ‘change this, you get that,’ working so well in loudness, seem to break down in taste. Change the sugar in cola or in coffee, and you get more/less coffee flavor, but you like the coffee more, and so forth. Here was the next level of exploration, a more ‘inner-focused world’.
If taste was to be the jumping off portion from this outer psychophysics to the measurement of feelings, such as liking, then the next efforts would be even more divergent. How does one deal with social problems which have many aspects to them? We are no longer dealing with simple ingredients, which when mixed create a food, and whose mixtures can be evaluated by a ‘taster’ to find out rules. We are dealing now with the desire to measure the perception of a compound situation, with many factors. Can the spirit of psychophysics add something, or we stop at sugar coffee, or salt in pickles?
Some years later, through ongoing studies of perception, it became obvious that one could deal with the inner world, using man as a measuring instrument. The slavish adherence of systematic change of the stimulus in degrees and the measurement, had to be discarded. It would be nice to say that a murder is six times more serious than a bank robbery with two people injured, but that type of slavish adherence would not create this new inner psychophysics. It would simply be adapting and changing the hallowed methods of psychophysics (systematically change, and then measure), moving from tones and lights to sugar and coffee, and now to statements about crimes. There would be some major efforts, such as the utility of money [5], efforts to maintain the numerical foundations of psychophysics because money has an intrinsic numerical feature. Another would be the relation between perceived seriousness of crime and the measurable magnitude punishment.
Enter Mathematics: The Contribution of Conjoint Measurement, and Axiomatic Measurement Theory
If psychophysics provided a strong link to the empirical world, indeed a link which presupposed real stimuli, then mathematical psychological provided a link to the world of philosophy and mathematics. The 1950’s saw the rise of interest in mathematics and psychology. The goal of mathematical psychological in the 1950’s and 1960’s was to put psychology on firm theoretical footing. Eugene Galanter became an active participant in this newly emerging, working at once with Stevens in psychophysics at Harvard, and later with famed mathematical psychologist R. Duncan Luce. Luce and his colleagues were interested in ‘fundamental measurement’ of psychological quantities, seeking to measure psychology with the same mathematical rigor that physicists measured the real world. That effort would bring to fruition the Handbook of Mathematical Psychology, and well as the efforts of psychologist coining the term ‘functional measurement [6-9].
The simple idea which is relevant to us is that one could mix test stimuli, ideas, not only food ingredients, instruct the respondent to evaluate these mixtures, and estimate the contribution of each component to the response assigned to the mixture suggested deeply mathematical, axiomatic approaches to do that. Anderson suggested simpler approaches, using regression. Finally, the pioneering academics at Wharton Business School, showed how the regression approach could be used to deal with simple business problems [10-12].
The history of psychophysics and the history of mathematical psychology met in the systematics promised by and delivered by Mind Genomics. The mathematical foundations had been laid down by axiomatic measurement theory. The objective, systematized measurement of experience, had been laid down by psychophysics at first, and afterwards by applied psychology and consumer research. What remained was to create a ‘system’ which could quantify experience in a systematic way, building databases, virtually ‘wikis of the mind’, rather than simply providing one or two papers on a topic which solved a problem with an interesting mathematics. It was time for the creation of a corpus of psychophysically motivated knowledge, an inner psychophysics of thought, rather than the traditional psychophysics of perception.
Reflections on the Journey from the Outer Psychophysics to an Inner Psychophysics
New thinking is difficult, not so much because of the problems as the necessity to break out of the paradigms which one ‘knows’ to work, even though the paradigm is not the best. The inertia to remain with the tried and true, the best practices, the papers confined to topics that are publishable, is endemic in the world of academics and thinking. At the same time, inertia seems to be a universal law, whether the issue is science and knowledge, or business. This is not the place to discuss the business aspect, but it is the place to shine a light on the subtle tendency to stay within the paradigms that one learned as a student, the tried and true, those paradigms which get one published.
The beginning of the journey to inner psychophysics occurred with a resounding NO, when author HRM asked permission to combine studies of how sweet an item tasted, and how much the item was liked. This effort was a direct step away from simple psychophysics, with the implicit notion of a ‘right answer’. This notion of a ‘right answer’ summarizes the world view espoused by Stevens and associates that psychophysics was searching for invariance, for ‘rules’ of perception. Departures from the invariances would be seen as the irritating contribution of random noise, such as the ‘regression effect’, wherein the tendency of research is to underestimate the pattern of the relation between physical stimulus and subjective, judged response. “Hedonics” was a complicating, ‘secondary factor’, which could only muddle the orderliness of nature, and not teach anything, at least to those imbued with exciting Harvard psychophysics of the 1950’s and 1960’s.
The notion of cognition, hedonics, experience as factors driving the perception of a stimulus, could not be handled easily in the new outer psychophysics except parametrically. That is, one could measure the relation between the physical stimulus and the subjective response, create an equation with parameters, and see how these parameters changed when the respondent was given different instructions, and so forth. An example would be judging the apparent size of a circle of known diameter versus judge the actual size. It would be this limitation, this refusal to accept ideas as subject to psychophysics, that author HRM, would end up attempting to overcome during the course of the 54-year journey.
The course of the 54-year journey would be marked by a variety of signal events, events leading to what is called in today’s business ‘pivoting.’ The early work on the journey dealt with judgments of likes and dislikes, as well as sensory intensity [13]. The spirit guiding the work was the same, search for lawful relations, change one parameter, and measure the change in a parameter of that lawful relation. The limited, disciplined approach of the outset psychophysics was too constraining. It was clear at the very beginning that the rigorous scientific approaches to measuring perceptual magnitudes using ‘ratio-scaling’ would be a non-starter. The effort of the 1950’s and 1960’s to create a valid scale of magnitude was relevant, but not productive in a world where the application of the method would drown out methodological differences and minor issues. In other words, squabbles about whether the ratings possessed ‘ratio scale’ properties might be interesting, but not particular productive in a world begging for measurement, for a yet-to-be sketched out inner psychophysics.
The movement away from simple studies of perceptual magnitudes was further occasioned by the effort to apply the psychophysical thinking to business issues, and the difficulties ensuing in the application of ratio scaling methods such as magnitude estimation. The focus was no longer on measurement, but on creating sufficient understanding about the stimulus, the food or cosmetic product, so that the effort would generate a winner in in the marketplace.
The path to understanding first comprises experiments with mixtures, first mixtures of ingredients, and then mixtures of ideas, steps needed to define the product, to optimize the product itself, and then to sell the product. Over time, the focus turned mainly to ideas, and the realization that one could mix ideas (statements), present these combinations to respondents, get the responses to the combinations, and then using statistics such as OLS (ordinary least-squares regression) one could estimate the contribution of each idea in the mixture to the total response.
Inner Psychophysics Propelled by the Vision of Industrial-scale Knowledge Creation
A great deal of what the author calls the “Inner Psychophysics” came about because of the desire to create knowledge at a far more rapid level than was being done, and especially the dream that the inevitable tedium of a psychophysical experiment could simply be eliminated. During the 20th century, especially until the 1980’s, researchers were content to work with one subject at a time, the subject being call the ‘O’, an abbreviation for the German term Beobachter. The fact that the respondent is an observer suggests a slow, well-disciplined process, during which the experimenter presents one stimulus to one observer, and measures the response, whether the response is to say when the stimulus is detected as ‘being there’, when the stimulus quality is recognized, or when the stimulus intensity is to be assigned a response to report its perceived intensity.
The psychophysics of the last century, especially the middle of the 20th century, focused on precision of stimulus, and precision of measurement, with the goal of discovering the relations between variables, on the one hand physical stimuli and on the other subjective responses. It is important to keep in mind the dramatic pivot or change in thinking. Whereas psychophysics of the Harvard format searched for lawful relations between variables (physical stimulus levels; ratings of perceived magnitude), the application of the same thinking to food and to ideas was to search for lawful, usable relation. The experiments need not reveal an ‘ultimate truth’, but rather needed to be ‘good enough,’ to identify a better pickle, salad dressing, orange juice or even features of a cash-back credit card.
The industrial-scale creation would be facilitated by two things. The first was a change in direction. Rather than focusing one’s effort on the laws relating physical stimulus and subjective response (outer psychophysics), a new, and far-less explored area would focus on measuring ideas, not actual physical things (inner psychophysics).
The second would focus on method, on working not with single ideas, but deliberately with mixtures of ideas, presented to the respondent in a controlled situation, and evaluated by the respondent. These mixtures would be created by experimental design, a systematic prescription of the composition of each mixture, viz., which phrases or elements would appear in each vignette. The experimental design ensured that the researcher would be able to link a measure of the respondent’s thinking to the specific elements. The rationale for mixtures was the realization that single ideas were not the typical ‘product’ of thought. We think of mixtures because our world comprises compound stimuli, mixtures of physical stimuli, and our thinking in turn comprises different impressions, different thoughts. Forcing the individual to focus on one thought, one impression, one message or idea, is more akin to meditation, whose goal is to shunt the mind away from the blooming, buzzing confusion of the typically disordered mind, filled with ideas flitting about.
The world view was thus psychophysics, search for relations and for laws. The world view was also controlled complexity, with the compound stimulus taking up the attention of the respondent and being judged. The structure of the mixtures appeared to be a ‘blooming, buzzing confusion’ in the words of Harvard psychologist William James. To create the inner psychophysics meant to prevent the respondent from taking active psychological control of the situation. Rather, the designed forced the respondent to pay attention to combinations of meaningful messages (vignettes), albeit messages somewhat garbled in structure to avoid revealing the underlying structure, and thus to prevent the respondent from ‘gaming’ the system.
As will be shown in the remainder of this paper, the output of this mechanized approach to research produced an understanding of how we think and make decisions, in the spirit of psychophysics, at pace and scope that can be only described as industrial scale. Some of the reasons for the term ‘industrial scale production of knowledge’ come from the manner that the approach was used, viz. evaluation of systematic mixture of ideas.
The Mind Genomics ‘Process’ for Creating an Experiment
The study presented here comes from a developing effort to understand the mind of ordinary people in term of what types of actions can solve well-known social problems. At a quite simple level, one can either ask respondents to tell the researcher what might solve the problems or present solutions to the respondent and instructed to scale each solution in terms of expected ability to solve the problem. The solutions are concrete actions, simple and relevant. The pattern of responses gives a sense of what the respondent may be thinking with respect to solving a problem.
The study highlighted here went several stages beyond that simple, straightforward approach. The inspiration came from traditional personality theory, and from cognitive psychology. In personality theory, psychologist Rorschach among many others believed that people were not often able to paint a picture of what was going on in their minds. Rorschach developed a set of ambiguous pictures, and instructed the respondent to say what they ‘saw’. The pattern of what the respondent reported ‘seeing’ suggested how the respondent organized her or his perceptions of the world. Could such an approach be generalized, so that the pictures would be replaced by metaphoric words, rich with meaning? And so was born the current study. The study combines a desire to understand the mind of the individual, the use of Mind Genomics to do the experiment, and the acceleration of knowledge development through a novel set of approaches to the underlying experimental design [14].
The process itself follows a series of well-choreographed steps, leading to statistical analyses and then to pattern recognition of possible underlying processes:
- The structure of the experimental design begins with a single topic (e.g., a social problem), continues with four questions dealing with the problem, and in turn uses four specific answers to each question. The three stages are easy to do, becoming a template. Good practice suggests that the 16 answers (henceforth elements) be simple declarative statements, each comprising 12 words or fewer, with no conjunctives. These declarative statements should be easily and quickly scanned, with as little ‘friction’ as possible.
- The specific combinations are prescribed by an underlying experimental design. The experimental design . The experimental design ensured that each element appeared exactly five times across the 24 vignettes, and that the pattern of appearances made each element statistically independent of the other 15 elements. A vignette could have at most one element or answer from a question. The actual design generates vignettes comprising a mixture of 4-element vignettes, 3-element vignettes, and 2-element vignettes, respectively, but never a 1-element vignette.
- The experimental design was set so that the data from each respondent, viz., the vignettes and their ratings, could be analyzed by ordinary least-squares (OLS) regression. That is, each respondent’s data comprised an entire experiment. The data could be analyzed in groups, or at the level of the individual. For this paper, the focus will be on the results emerging from the OLS regression at the level of each respondent.
- A key problem in experimental design is the focus on testing one specific set of combinations out of the large array of the underlying ‘design space’. The quality of knowledge suffers because only one small region of the design space is explored, usually that region believed to be the most promising, whether that belief is correct or not. . There is much more to the design space. The research resources are wasted minimizing the “noise” in this presumably promising region, either by eliminating noise (impossible in an Inner Psychophysics), or by averaging out the noise in this region by replication (a waste of resources).
- The solution of Mind Genomics is to permute the experimental design [15]. The permutation strategy maintains the structure of the experimental design but changes the specific combinations. The task of permuting requires that the four questions be treated separately, and that the elements within a question be juggled around but remain with the question. In this way, no element was left out, but rather its identification number changed. For example, A1 would become A3, A2 would become A4, A4 would become A2 and A3 would become or remain A3. At the initial creation of the permuted designs, each new design was tested to ensure that it ran with the OLS (ordinary least-squares) regression package. Each respondent ends up evaluating a different set of 24 combinations.
- The benefit to research is that research becomes once again exploratory as well as confirmatory, due to the wide variation in the combinations. It is no longer a situation of knowing the answer or guessing at the answer ahead of time. The answer emerge quickly. The data from the full range of combination tested quickly reveal what elements perform well versus what elements perform poorly.
- Continuing and finishing with an overview of the permuted design of Mind Genomics, it would be quickly obvious that studies need not be large and expensive. The ability to create equations or models with as few as 5-10 respondents, because of the ability to cover the design space, means that one can being to understand the ‘mind’ of people with so-called ‘demo studies’, virtually automatic studies, set up and implemented at low cost. The setup takes about 20 minutes once the ideas are concretized in the mind of the research. The time from launch (using a credit card to pay) to delivery of the finalized results in tabulated form, ready for presentation, is approximately 15-30 minutes.
- The final step, as of this writing (Fall, 2022), is to make the above-mentioned system work with a series of different studies of social problems, here, 27 studies. In the spirit of accelerated knowledge development, each study is a carbon copy of every other study, except for one item, the specific social issue addressed in the study. That is, the orientation, rating scale, and elements are identical. What differs is the problem. When everything else is held constant, only the topic being varied, we have then the makings of the database of the mind, done at industrial scale
Applying the Approach to the ‘Solution’ of Social Problems
We begin with a set of 27 social problems, and a set of solutions. The problems are ones which are simple to describe and are not further elaborated. In turn the 16 element or solutions are general approaches, such as the involvement of business, rather than more focused solutions comprising specific steps. The 27 problems are shown in Table 1, and the 16 solutions are shown in Table 2. For right now, it is just important to keep in mind that these problems and solutions represent a small number of the many possible problems one can encounter, and the solutions that might be applied. For this introductory study, using the Mind Genomics template, we are limited to four types of solutions for a problem, and four specific solutions each solution type. The number of problems is unlimited, however.
- Figure 1a and 1b shows two screen shots. Each problem is represented by a single phrase, describing the problem. That phrase is called ‘the SLUG’. In the figures, the words ‘ABORTION RIGHTS’ constitute the SLUG. The SLUG changes in each study, to present the topic of that study. There is no further elaboration of the topic as art of the introduction.
- The approach is templated, allowing the researcher to set up the study within 40 minutes, once the researcher identifies the social problem, creates the four questions, creates the four answers to each question (16 answers or elements), and then creates the rating scale. The researcher simply fills in the template as shown for one study, abortion, in Figure 1a and Figure 1b, respectively.
- Since the study is templated and of the precise same format except the topic, moving from one study to 26 copies becomes a straightforward task. The researcher copies the base study, but then changes the nature of the problem in the introduction, and the rating scale. This activity requires about 10 minutes per study. The activity simply requires the change of SLUGS. The total time for this ‘reproduction’ step is about two hours for the 26 remaining studies.
- Launch the 27 studies in rapid sequence. Each study requires about 1-2 minutes to launch, an effort accomplished in about one hour or less. The 27 studies run in parallel, each with about 50 respondents. With ‘easy-to-find’ respondents, the 27 steps take about two hours to run in the field, since they are running simultaneously, and require only a total of 1350 respondents.
- Using the ‘raw data’ files generated by the program, combine the raw data from the 27 studies into one comprehensive data file comprising all the data. Each respondent generates 24 rows of data. A study of one topic generates 24×50 or 1200 rows of data. The 27 studies generate 1200×27 rows of data. The effort to combine the data, ensuring that each study is properly incorporated into the large-scale database, requires about 2 hours.
- Convert the ratings so that ratings of 1-3 are converted to 0, to reflect the fact that the respondent does not feel that the combination of solutions will solve the social problem. Convert ratings of 4 and 5 to reflect the fact that the respondent does feel that the combination of solutions presented in the vignette will solve the social problem. Thus the ratings assigned by the respondent, a 5-point scale, are converted to a no/yes scale. To each converted value, viz., 24 binary values for each respondent, one per vignette, add a vanishingly small random number (~ 10-3). The small random number will not affect the results but will ensure variation in the newly created binary variable, (0=will not work, 100=will work). This type of conversion, viz., from a Likert Scale (multi-point category scale) to a binary scale, is a hallmark of Mind Genomics. The conversion comes from the history of consumer researchers and public opinion researchers working with YES/NO scales because managers do not understand what to do with averages of ratings. The averages have statistical meaning, of course, but have little built in meaning for a manager who has to make business decisions.
- Since the 24 vignettes evaluated by a respondent are created according to an underlying experimental design, we know that the 16 independent variables (viz., the 16 solutions) are statistically independent of each other. Create a model (equation) for each respondent relating the presence/absence of the 16 elements to the newly created binary variable ‘solve the problem.’ The equation does not have an additive constant, forcing all the information about the pattern to emerge from the coefficients. We express the equation as: Work (0/100) = k1(Solution A1) + k2(Solution A2) + …. K16(Solution D4). Each respondent thus generates 16 coefficients, the ‘model’ for that respondent. The coefficient shows the number of points on a 100-point scale for ‘working’ contributed by each of the 16 solutions.
- Array all the coefficients in a data matrix, each row corresponding to a respondent, and each column corresponding to one of the 16 solutions or elements. The data matrix is very large, comprising approximately 50 rows per study, one per respondent, and 27 blocks of rows, one block per study, to generate 1350 rows. Each row is unique, corresponding to a respondent, study, and comprises information about the respondent (age, gender, answer to classificaiton questions), and then the 16 coefficients.
- Cluster all respondents, independent of the problem topic, but simply based on the pattern of the 16 coefficients for the respondent. The clustering is called k-means [16]. The researcher has a choice of the measure of distance or dissimilarity. For these data we cluster using the so-called Pearson Model, where the distance between two respondents is based on the quantity (1-Pearson Correlation Coefficient computed across the 16 corresponding pairs of coefficients). Note that the clustering program ‘does not know’ that there are 27 studies. The structure of the data is the same from one study to another, from one respondent to another
- Each respondent is assigned to exactly one of the three large clusters (now called mind-sets), independent of WHO the person ‘is’, and the study in which the respondent participated. That is, the clustering program considers only the pattern of the coefficient. As a consequence, each of the three clusters can end up comprising respondents from each of the 27 studies. Finally, a respondent can be assigned to only one of the three clusters or mind-sets.
- Once the respondent is assigned to exactly one of the three mind-sets by the clustering program, the original raw data (24 rows of data for each respondent in each study) can now be augmented by an additional variable, namely the cluster membership of each respondent. The original raw data can be reanalyzed, first by total panel, then by mind-set, and then by mindset x study. With three mind-sets, there are now one grand equation with all the data, 27 equations for the 27 studies, and 81 equations for the 27 studies x 3 mind-sets.
- The analysis as outlined in Step 11 can be further strengthened by considering only those vignettes not rate ‘3’. Recall that ‘3’ corresponds to ‘cannot answer the question’. Eliminating all with ratings of ‘3’ eliminates these uncertain answers.
- The final data analytic step looks at the pattern of coefficients for the different groups (total, three mind-sets), considering the matrix of 16 elements (the solutions) x 27 studies. We will look only at strong performing elements, rather than trying to cope with a ‘wall of numbers’. For total panel, ‘strong’ is operationally defined as a coefficient of 25 or higher. For subgroups defined by the mind-sets, ‘strong’ is operationally defined as a coefficient of 30 or higher. These stringent criteria correspond to coefficients which are ‘statistically significant’ (P<0.05) through analysis of variance for OLS regression. All other coefficients will not be shown, in order to let the patterns emerge.
- The goal of the analysis is to get a sense of ‘what works’ for problems, solutions, and mind-sets. As we will see, most solutions fail to work for most problems. It is not that the solution is consciously thought to not work, but rather when the solution (an element) is combined with other elements, the patterns emerging suggest that the specific solution is simply irrelevant. As we will see, however, many solutions do work.
- The effort for one database, for one country, easy easily multiplied, either to the same database for different countries, or different topic databases for the country. From the point of view of cost, each database of 27 studies and 50 respondents per study can be created for $10,000 – $15,000, assuming that the respondents are easy to locate. That effort comes to about $400 – $500 per study. The time to create the database is equally impressive, days and weeks, not years.
Table 1: The 27 social problems. Each social problem was not further defined
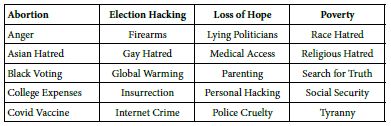
Table 2: The 16 solutions and their abbreviation in the data tables
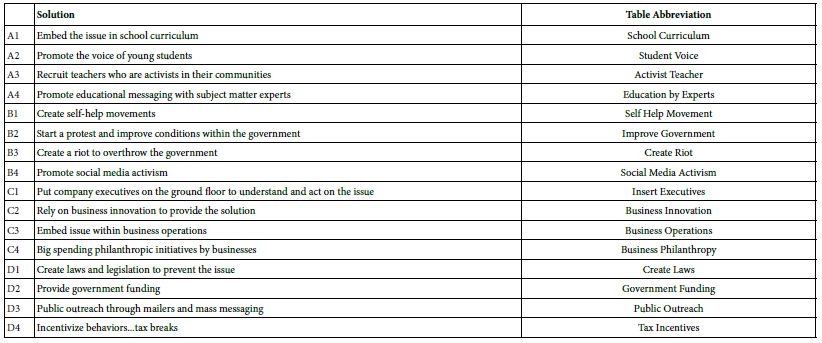
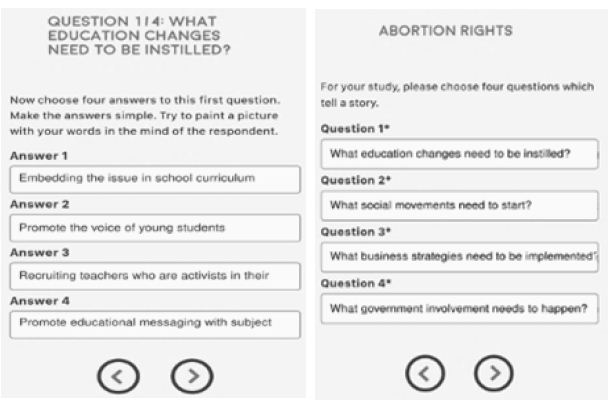
Figure 1a and 1b: Screen shots of the set up for one study (abortion rights)
Results for Total Panel and Three Emergent Mind-sets
Let us now look at the data from the total panel. In its full form, Table 3 would show 16 columns ( one per each of the 16 solution or elements), and 27 rows (one row for each of the 27 problems). Recall from #13 above that the strong performing combinations of problem (row) and solution (column) are those with coefficients of +20 or higher. The strong performing combination correspond to significant likelihood of the solution solving the problem, across all respondents, but excluding those vignettes assigned a rating of ‘3’ (cannot decide).
Table 3: Summary table of coefficients for coefficients emerging from the model relating presence/absence of 16 solutions (column) to the expected ability to solve the specific problem (row). Models were estimated after excluding all vignettes assigned the rating 3 (cannot decide). Only strong performing elements are shown (viz., coefficient of 25 or higher)
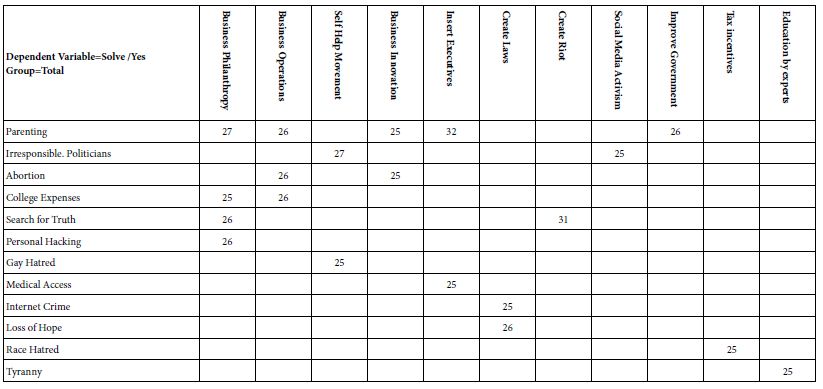
Only 20 of the possible 432 problem/solutions are perceived as likely to ‘work’. The strongest performing solutions come from business. The strongest performing problem is parenting. The rest of the combinations which ‘work’ are scattered. Finally, five of the 16 solutions never work with any problem, and 15 of the 27 problems are not amenable to any solution.
One of the key features of Mind Genomics is the search for mind-sets. The notion of mind-sets is that for each topic area, one can discovered different patterns of ‘weights’ applied by the respondent to the information. For example, when it comes to purchasing a product, one pattern of weights suggests that the respondent pays attention to product features, whereas another pattern of weights applied to the same elements suggests that the respondent pays attention to the experience of consuming the product, or the health benefits of the product, rather than paying attention to the features.
Our analysis proceeds by looking for ‘general’ mind-sets, across all 27 problems, and all 16 solutions. The coefficients for the three emergent mind-sets appear in Tables 4-6. Once again the only coefficients which appear in the tables are those coefficients deemed to be ‘very strong’ performers, this time with a value of +30 or higher. This increased stringency removes many coefficients. Yet, a casual inspection of Tables 4-6 shows that each table comprises more problems, more solutions, and more coefficients. The mind-sets do not believe that the key solutions will work everywhere, but just in some areas, in distinctly different areas, in fact. The mind-sets do not line up in an orderly fashion. That is, we do not have a simplistic set of psychophysical functions for the inner psychophysics. We do have patterns, and metrics for the social consensus.
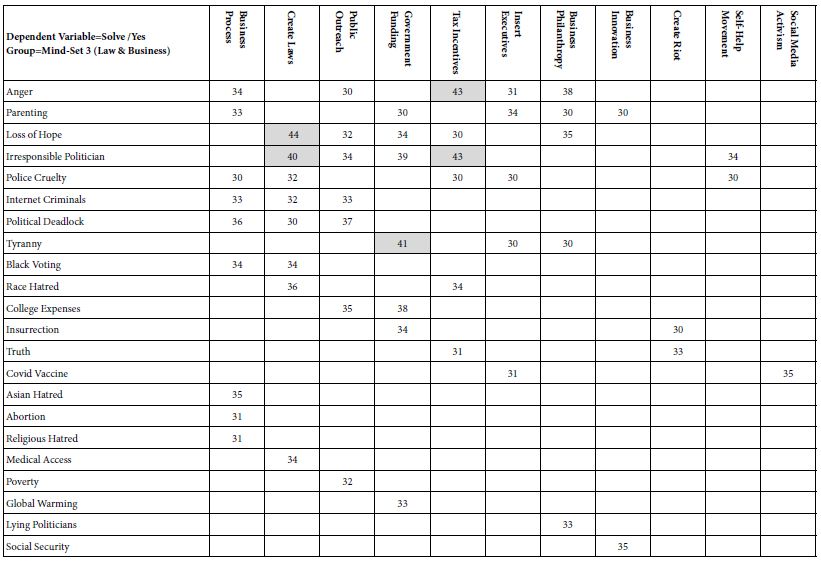
- Mind-Set 1 (Table 4) appears to feel that business and education solutions will work more effectively than will solutions offered by government. Mind-Set 1 does not believe strongly in the public sector is able to provide workable solutions to many problems. Mind-Set 1 shows 46 problem/solution combinations of 30 or higher, and three problems/solutions combination with coefficients of 40 or higher. The 46 combinations are more than twice as many as the 20 combinations for strong performing elements from the Total Panel, even with the increased stringency applied to the mind-sets.
- Mind-Set 2 (Table 5) appears to feel that education and the law will solve many of the problems. Mind-Set 2 shows 50 problem/solution combinations of coefficient 30 or higher, and three combinations which show a coefficient of 40 or higher,
- Mind-Set 3 (Table 6) appears to feel that law and business will solve many of the problems. Mind-Set 3 shows 50 problem/solution combinations of coefficient 30 or higher, and five combinations which show a coefficient of 40 or higher,
- The increased richness of Tables 4-6 arises from the fact that the clustering isolates groups of individuals who think alike at the granular level of specific problems. By separating the mind-sets, the clustering program ensures that the individual coefficients have a less likely chance to cancel each other. We attribute the increased range to the hypothesis that people may be fundamentally different in their mental criteria. Inner Psychophysics reveals those differences, in a way that could not have been done before.
Table 4: Summary table of coefficients for model relating presence/absence of 16 solutions (column)to the expected ability to solve the specific problem (row). The data come from Mind-Set 1, which appears to focus on business and education, respectively, as the preferred solution to problems
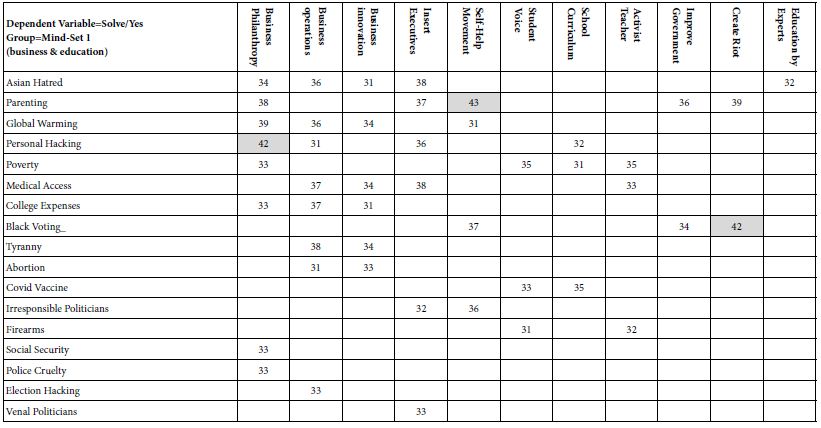
Table 5: Summary table of coefficients for model relating presence/absence of 16 solutions (column) to the expected ability to solve the specific problem (row). The data come from Mind-Set 2, which appears to focus on education and the law, respectively, as the preferred solution to problems
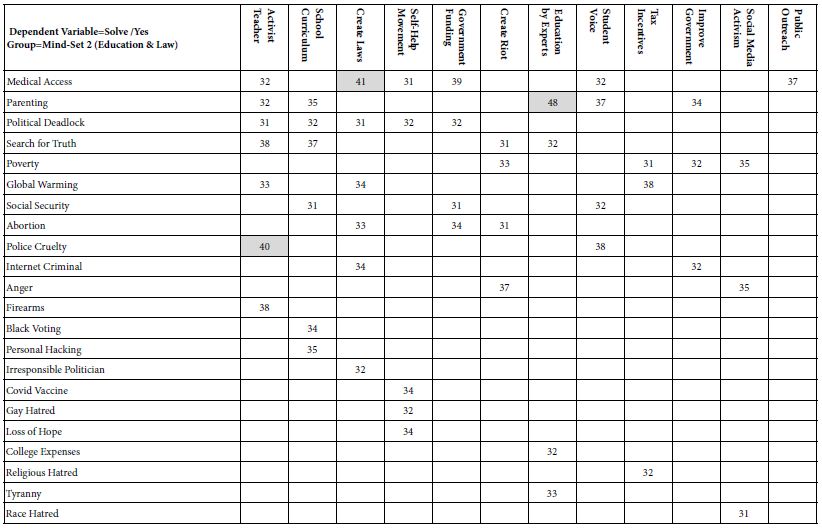
Table 6: Summary table of coefficients for model relating presence/absence of 16 solutions (column)to the expected ability to solve the specific problem (row). The data come from Mind-Set 3, which appears to focus on law and business, respectively, as the preferred solution to problems
The Inner Psychophysics and Response Time
Response time is assumed to reflect processes which occur. Longer responses times are presumed to suggest the involvement of more processes. So attractive is the study of response time as an indicator of internal processes that response time has moved from a simply a non-cognitive measure in behavior to a world of its own. Responses times are presented, along with hypotheses of what might be occurring [17]. Indeed, an entire division of applied consumer researcher has emerged to test ideas, the field being called implicit researcher after the work of Harvard psychologist Mazharin Banaji and her associates [18].
Let us take the same approach as above, relating the presence/absence of the 16 elements, not however to ratings of ability to solve the problem, but rather to the response time. The Mind Genomics program measured the number of seconds between the appearance of the vignette and the response assigned. When the respondent ‘dawdled’ in the self-pace experiment, the response time became unnecessarily long, for reasons other than reading and reacting. An operationally defined limit of six seconds was assumed for a participant. All vignettes with response times of nine seconds or longer were eliminated from analysis, as were all vignettes assigned the rating ‘3’ (cannot decide).
One might argue that by selecting data with responses times of 9 seconds or less, one is deliberately reducing the discrimination power of the analysis, by eliminating vignettes which required deliberation. This is correct removed a number of suspiciously long response times.
The Mind Genomics program then estimates the response time for each element (viz., solution) by using OLS (ordinary least-squares) regression. The equation is: Response Time = k1(A1) + k2(A2)…k16(D4). The equation is the same as the equations above for problem solving, other than the fact that there is no additive constant. The rationale for the absence of an additive constant is that the response time should be ‘0’ in the absence of any elements.
Table 7 shows the average coefficients for response times for three problems across 16 solutions. These problems are college expenses, COVID vaccination, and police cruelty. The average coefficients are shown by Total Panel, and then by three mind-sets. ‘Long’ response times (viz, high coefficients) of 2.0 seconds for an element (viz., solution) are shown by shaded cells. To allow the patterns to emerge, Table 7 presents only those coefficients which are 1.0 (seconds) or more.
Table 7: Estimated response times for specific elements, for the total panel and for the respondents in a defined mind-set. Only those response times for vignettes rating 1, 2, 4 or 5, were used in the computation. Only response times 9 seconds or shorter were used in the computation, under the assumption that longer response times meant that the respondent was multi-tasking
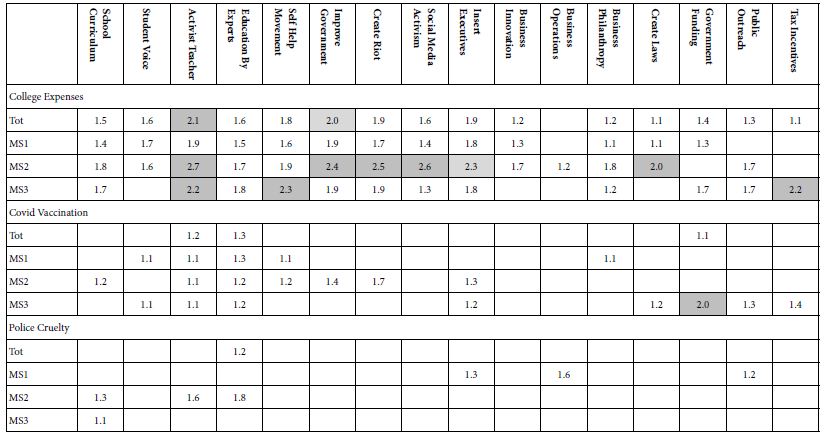
The pattern is obvious at the most general level…. People think about solutions when confronted with the topic of paying college expenses. People ponder the offered solutions. In contrast, there are fewer long response times for COVID vaccinations, and very few for Police Cruelty. In other words, it’s not only the solution, but rather the unique combination of problem and solution. We have here evidence of how the topic ‘controls’ attention.
Based upon the array of response times for elements shown in Table 7, we are left with the Herculean task of discovering an interpreting a coherent pattern, for Total Panel and then for mind-set. The pattern is, paradoxically, a lack of a pattern across mind-sets. That is, respondents may differ in what they believe will solve a problem, but difference in mind-sets does not manifest itself in the pattern of response times.
It is important to realize that the response times do not necessarily mean right or wrong, agree or disagree, and so forth. When confronted with data about Mind Genomics and its measurement of response time, the novice in Mind Genomics often asks whether a short response time (or conversely a long response time) is means that the person likes the topic, dislikes the topic, and so forth. We are so accustomed to judgments of dislike/like, bad/good, etc., that it is difficult to accept the fact that the response time (or other such metric, such as pupil size or galvanic skin response, GSR), are simply measures without any inherent meaning., viz., cognitively ‘poor.’ It is we who search for the meaning, wanting to contextualize observations of human non-conscious responses as clue to judgment, such as the extremely popular notion [19] patterns of thinking; System 1 (Fast) and System 2 (Slow Deliberate).
Discussion and Conclusion
The early work in psychophysics focused on measurement, the assignment of numbers to perceptions. The search for lawful relations between these measured intensities of sensation and a physical correlate would come to the fore even during the early days of psychophysics, in the 1860’s, with founder [20]. It was Fechner who would trumpet the logarithmic ‘law of perception, viz., that the relation between physical stimuli and perceived intensity was a logarithmic relation. One consequence of that effort to seek regularity in nature using one’s measures was to focus on the relationships between external stimuli and internal perceptions. This ‘external psychophysics’ focused on the search for lawful relationships that could be expressed by simple equations. The effort would be continued and brought to far more depth and application by Harvard professor S.S. Stevens, known as the father of modern psychophysics.
This paper began with the desire to extend psychophysics to the measurement of internal ideas The contribution of this paper is the introduction of a simple method for presenting stimuli, doing so in a way which forces the respondent to act as a measuring instrument, prevents biases, and emerges with numbers representing metrics of the mind. There are undoubtedly improvement that can be had, but the key aspects of the objective to ‘measure ideas’ (viz., the ‘inner psychophysics).
If we were to summarize the effort, we would point out these features:
A. The notion of isolating a variable and studying it in depth simply does not work when the nature of people is to think about ideas which are compound and complex. Traditional psychophysical methods simply are too unrealistic in view of the fact that the researcher cannot control the stimulus, the mind.
B. True to the word ‘psycho-physics’ which links two realms, the stimuli must be controlled by the researcher, and capable of systematic variation. If not, we are not true to the vision of psychophysics, linking two domains. The approach presented here, evaluation of systematically created combinations of stimuli, is consistent with the methods espoused by psychophysics.
C. The response should be a metric of ‘intensity’. The Likert scale presented here is such a scale. For science, the Likert scale data suffice. For application, most people have trouble interpreting the ‘implication’ of values on the Likert scale. That is, the scale is adequate, but most managers don’t really know the ‘practical meaning’ of the scale values. The transformation of Likert values to a binary scale ensures that the user of the information can make sense of the data.
D. The same type of study can be used to assess the impact of a set of ideas evaluated against different contexts. In the world of psychophysics, this type of study reveals the influence of different ‘backgrounds’ to affect the response to the stimulus (e.g., the perception of various coffees when the amount of milk is systematically varied). The psychophysical ‘thinking’ re-emerges when the topic or general problem is systematically varied across the 27 experiments, and then the study executed with new respondents. The outcome generates parallel sets of measures for ideas, each set pertaining to a specific topic, but everything else remaining the same.
E. Psychophysicists often look for explainable differences in the pattern of reactions to stimuli, more so in the chemical senses than in other areas, perhaps because in the chemical senses it is well known that people differ in what they like. This notion of basic groups, mind-sets, developed for simple stimuli in psychophysics, transfers straightforward to studies in Mind Genomics. Using the coefficients emerging from the OLS deconstruction of the rating at the level of the individual, one can find these ‘mind-sets’ for any specific topic, or as in this people, search for mind-sets which transcend the particular problem. Ability to cluster the respondents en masse, to create groups of individuals who show similar patterns of coefficients, viz., similar ways of thinking about solutions to problems.
Ability to measure the response time and determine whether we can discover any relation between response time as a well-known variable in psychology, and importance in decision making. The data emerging from this study suggest that the use of response times will not be particularly productive, except as a general measure. That is, we learn a great deal from the pattern relating ratings (more correctly transformed ratings) to the solutions. We learn a lot less by using response time in place of ratings. It may be that these relations exist, but are covered up by the richness of data, so that the basic patterns between text and response times are too subtle to be revealed in a study of this type.
References
- Stevens SS, Greenbaum HB (1966) Regression effect in psychophysical judgment. Perception & Psychophysics 1: 439-446.
- Stevens SS (1975) Psychophysics: Introduction to its Perceptual, Neural, and Social Prospects, Psychophysics, New York, John Wiley.
- Stevens SS (1966) A metric for the social consensus. Science 151: 530-541. [crossref]
- Boring EG (1942) Sensation and Perception in the History of Experimental Psychology. Appleton-Century.
- Galanter, E (1962) The direct measurement of utility and subjective probability. The American Journal of Psychology 75: 208-220. [crossref]
- Miller GA (1964) Mathematics and Psychology, John Wiley, New York.
- Luce, R. D., Bush, R. R., Galanter, E. (Eds.) (1963) Handbook of Mathematical Psychology: Volume John Wiley
- Luce RD, Tukey JW (1964) Simultaneous conjoint measurement: A new type of fundamental measurement. Journal of Mathematical Psychology 1: 1-27.
- Anderson NH (1976) How functional measurement can yield validated interval scales of mental quantities. Journal of Applied Psychology 61-677.
- Green PE, Srinivasan, V (1978) Conjoint analysis in consumer research: issues and outlook. Journal of Consumer Research 5: 103-123.
- Green, Paul E, Wind Y (1975) New Way to Measure Consumers’ Judgments. Harvard Business Review 53: 107-117.
- Wind, Y (1978) Issues and advances in segmentation research. Journal of Marketing Research 15: 317-337.
- Moskowitz HR, Kluter RA, Westerling, J, Jacobs HL (1974) Sugar sweetness and pleasantness: Evidence for different psychological laws. Science 184: 583-585. [crossref]
- Goertz G, Mahoney J (2013) Methodological Rorschach tests: Contrasting interpretations in qualitative and quantitative research. Comparative Political Studies 46: 236-251.
- Gofman, A, Moskowitz, H. (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145.
- Dubes, R, Jain AK (1980) Clustering methodologies in exploratory data analysis. Advances in Computers 19: 113-228.
- Walczyk JJ, Roper KS, Seemann, E, Humphrey AM (2003) Cognitive mechanisms underlying lying to questions: Response time as a cue to deception. Applied Cognitive Psychology: The Official Journal of the Society for Applied Research in Memory and Cognition 17: 755-774.
- Cunningham WA, Preacher KJ, Banaji MR (2001) Implicit attitude measures: Consistency, stability, and convergent validity. Psychological Science 12: 163-170. [crossref]
- Kahneman, D (2011) Thinking, Fast and Slow. Macmillan
- Fechner GT (1860) Elements of Psychophysics Leipzig, Germany.