Abstract
927 respondents each rated purchase interest for each of 48 vignettes about a carpeting product, each vignette comprising 3-4 phrases from a set of 36 phrases, each vignette specified by an underlying experimental design. The results suggest that using terms written by copyrighters for advertising produces strong performing elements, leading to the conclusion that both the ideas in the study and the writing execution make a difference. Two clustering analyses were done, the first using the data from all 36 elements (FULL), the second using six orthogonal factor generated to replace the original 36 elements (FACTOR). The FULL clusters were more intuitive, and easier to suggesting that despite the attractiveness of using orthogonal variable in clustering, it may be better at a practical level to use the original data.
Introduction
The world of business operates on the recognition that people differ from each other. These differences can emerge from who the people ARE, what the people DO, how the people THINK, and so forth. The discovery of meaningful differences across people comprises on of the basic tenets of science, as well as differences in how one will behave, viz., important both at the level of theory and the level of application. One need only look at the Greek philosophers Plato to discover the importance of differences among people in the nature of their ‘rulers,’ [1], or at Aristotle’s science oeuvre [2], which based itself on classification as the first step.
The importance of difference among people found its key business use in the world of marketing. Consumer researchers, tasked with ‘understanding the market’ would instruct respondents to profile themselves on a variety of different characteristics, these ranging from geo-demographics (Who they are), to behavior (what they do, e.g., on the internet search and purchase), to what they believe.
Since the 1960’s consumer researchers have formally recognized the emerging discipline of psychographics, the method dividing people by how they think about the world The early efforts in psychographics assumed that the divisions among people provided a strong new way to think about marketing [3,4]. This belief in major divisions would lead to books such as the Nine Nations of North America [5], and at the most complex, the dozens of different groupings of people in the Prizm, offered by Claritas [6]. The recognition that people differ as much or more by their proclivities, by how they thank rather than by who they are, is to be applauded, even if the massive divisions of people into groups do not predict the precise language to which each group will be attracted when a particular product is offered.
The efforts of consumer researchers to find ‘basic groups’ in the population was not driven as much by science as by the effort to find the ‘magic key’ to a product. It was clear in concept tests (about new products), in product tests (how well did a product perform), and in tracking studies (attitudes and practices) that people who bought the same type of product, or even the same product, often differed in terms of who they were. That difference was an obstacle to even better product performance, because the marketer and the product developer were left with two or more groups wanting the product but wanting substantially different variations.. If the researcher could discover the ‘nature’ of the different physical product and then communication desired by a group of targeted consumers, it would be possible to create the best product for each group and communicate what each group needed to here. Such would be the opportunity for better market performance, especially when talented product designers and talent advertising agencies could work together after understanding the range preferences in a population for this same product. The knowledge-specifics about these different ‘mind-sets’ has a practical consequences of a positive nature in the in the business world.
Mind Genomics and the Focus on the Everyday
The discovery of mind-sets for a product or service has been a long, expensive research task, one which deals with high level issues, then brought to the level of the individual product or service through subsequent smaller scale research building off these large studies. One consequence of the size and expense of the studies is that they are buried in the corporate archives, used well or poorly for business purposes, to guide advertising/marketing, and even new product development. The result ends up being little knowledge about these mind-sets that a non-businessperson can access.
Mind Genomics, the emerging science of the everyday, has as its focus the study of what is relevant in terms of the specifics of everyday experience, as well as the discovery of mind-sets revolving around that experience. The approach differs dramatically from the conventional efforts. Conventional efforts, reflected in big studies, attempt to divide the minds of the consuming public in a grand way, to establish basic groups applicable to many aspects of a person’s behavior The goal is to find a few mind-sets which are relevant across a many different but related topics, such as mind-set of house decorating, mind-sets of the automobile experience, mind-sets of the financial experience, and so forth. In contrast, .Mind Genomics works in the opposite way, from the bottom up, in the style of a pointillist painter. For the Mind Genomics researcher, the focus is the basics, the specifics of a situation, and the existence of mind-sets relevant to that situation.
A great deal has been appeared on Mind Genomics, especially since 2006 [7,8]. The topic of this paper is in the spirit of ‘methodology,’ specifically the study of methods. The essential output of Mind Genomics is the reduction of the population of different people into a set of non-overlapping groups, these groups emerging from the pattern of responses to a set of stimuli emerging from a choice experiment. We will use the templated approach, considering two topics, the nature of mind-sets emerging when the clustering method generates 2, 3 or 4 mindsets, and the type of information and useful of the results if one tried to pre-process the data ahead of time to make the inputs more statistically robust.
The Mind Genomics science traces its origins to methods known collectively as conjoint measurement. Originally an effort in mathematical psychology to create a better form of measurement (Luce & Tukey, 1964), conjoint measurement would go on to spur a great deal of creative work, but in method and in application, spearheaded first by the late Professor Paul Green of Wharton School of Business at the University of Pennsylvania), and carried out and expanded by his colleagues at Wharton and later at other universities around the world [9-13].
The Mind Genomics Process to Understand What to Communicate, and to Whom
At the level of execution, the process is templated, and straightforward. The remaining sections of this paper will deal with the issue of understanding the nature of what is learned, when the research extracts different numbers of mind-sets from the same data (viz., 2 vs 3 vs 4 mind-sets), and when the research pre-processes data to produce what might be thought of as a more tractable set of variables (viz., six orthogonal factors vs 36 original coefficients as inputs for clustering).
1. Choose the Topic
The researcher chooses a topic. typically, the topics of Mind Genomics are of limited scope. The limited scope comes from the conscious decision to create a science from specifics, hypothesis generating, not hypothesis testing. The limited topic, something from the everyday, is not typically of interest to the researcher trying to understand a broad topic such as human decision making under stress, but rather limited to a topic that is often overlooked, such as decision making about the purchase of a flooring item. That topic, usually relegated to the world of business, and often simply overlooked by scientists as irrelevant the larger proscenium arch of behavior, happens to be an important part, or at least a relevant part, of the real world in which people live and behave. The topic of floor coverings has been studied by academics and business because it is so important in daily life, because it has business implications for sales, and because the topics it touches range from ecology, to choice, to the fascination of the mind of the do-it-yourself amateur [14-17]
2. Create the Raw Material, following a Template:
Mind Genomics prescribes a set of inputs, following a template. The templated design selects a certain number of variables (called questions or dimensions). The variables or questions ‘tell a story’. The questions never appear in the study. The questions are used only to guide the researcher who must provide answers to the questions. Sometimes, such as the case with this study, the questions or dimensions are simply bookkeeping tools to make sure that mutually contradictory elements can never appear together in a vignette. For this study, the researchers selected the so-called 6×6 design. as shown in Table 1. The elements are stand-alone phrases, painting a word picture.
Table 1: The six questions and the six elements (answers) for each group (viz. answers). The structure is only a bookkeeping device to ensure that mutually contradictory elements will not appear together in a vignette

3. Use an Experimental Design to Specific the Combinations
Mind Genomics works by presenting the individual with a large set of vignettes created by the experimental design. The design prescribes the precise combinations, doing so in a which makes each element appear equally often, appear statistically independently of every other element, and in a manner that the combinations evaluated by one person differ from the combinations evaluated by another person. This approach, permuted experiment design [18] ensures that the study covers a great deal of the possible combinations. The experiment design combined these 36 elements into 48 vignettes, combinations of element, with the properties that 36 of the 48 vignettes comprised four elements (at most one element or answer from a question). whereas the remaining 12 of the 48 vignettes comprised three elements (again, at most one element from a question).
4. The Mind Genomics System Creates the Test Stimuli to be Evaluated by the Respondents
Figure 1 shows one of the vignettes. The vignette seems a haphazard collection of elements, presented in a strange, centered format without connectives. To professional marketers this type of format may best disconcerting. The reality, however, is that the format is exactly what is needed to present the relevant information. The respondent cannot ‘guess’ the right answer. Shortly after the start of the evaluation of 48 vignettes, the respondent stops trying to ‘be right’, and simply responds at an intuitive, gut level. it is precisely this gut response, which best matches the ordinary behavior of individuals faced with the task of selecting a product. Despite the feeling of marketers that their ‘offering’ is special, and engages the customer, and despite the best efforts of advertising agencies their ‘creative’ these mundane situations generate are generally faced with indifference. It is decision within the world of indifference that must be understood, not decision making occurring when a mundane situation is focused upon, and unusual amounts of attention to something that would be simply considered, a decision made, and the person then move on.

Figure 1: Example of a vignette comprising four elements. The rating scale appears below, showing a 9-point purchase scale (1=Not likely to purchase… 9=Very likely to purchase
5. Orient the Respondents
The respondents were oriented by a screen which provided just enough background information to alert the respondent to the nature of the product whose messages were being tested with Mind Genomics. For the purposes of this paper on method, it is not necessary to identify the manufacturer, but it was identified at the actual study. Figure 2 shows the orientation page.

Figure 2: The orientation screen
Analytics
6. Transform the Responses to a More Tractable Form
Our first step of analysis is to consider whether we will keep the 9-point scale, or whether we will change the scale to something more tractable. Most researchers familiar with the 9-point Likert scale, or indeed with any category scale or ratio scale, will wonder why the need for change. It is easier to begin with a good scale, with good anchors and stay with that scale. At the level of science, the suggestion is correct. At the level of the manager working with the data, nothing could be further from reality. Managers are interested in what the scale numbers mean. The statistical tractability of the 9-point scale is a matter of passing interest. It’s the meaning, the usefulness of the data as an aid to make decision which is important.
The conventional approach in consumer research is to transform the data, so that the data becomes a binary scale, yes/no. The manager is more familiar with, and more comfortable with yes/no decisions. There is no issue of ‘what do the numbers’ mean. In the spirit of this ease of use of binary scales, yes/no, the data were transformed. Ratings of 1-6 were transformed to ‘0’ to denote ‘no’, different gradations of not purchasing. Ratings of 7-9 were transformed to ‘0’ to denote ‘yes’. To each of these transformed numbers was added a vanishingly small random number (10-5). That action becomes prophylactic, preventing any individual respondent from generating all 0’s or all 100’s across the 48 vignettes evaluated by the individual. If the respondent were to rate all the vignettes 1-6, showing variation, the transformation would bring these to 0, and the regression analysis to follow would ‘crash.’ In the same way, were the respondent to rate all vignettes 7-9, the transformation would bring these to 100. In the actual data, 12 respondents generated all 0’s, but 284 respondents generated all 100’s because they found enough appealing in each vignette to assign the rating of 7-9.
7. Relate the Response (TOP3) to the Presence/Absence of the Elements Using ALL the Data
Mind Genomics uses so-called dummy variable regression, a variation of OLS (ordinary least squares regression Hutcheson, 2019). The analysis is first done at the level of the total panel. The independent variables are all 36 elements. Each respondent generates 48 rows of data, each row corresponding to one of the 48 vignettes the respondent evaluated. The data matrix for each respondent comprises 36 columns, one column for each element. The cell for a particular vignette has the number ‘0’ when the element is absent from the vignette, and the number ‘1’ when the element is present. There is no interest in the meaning the element. It is simply a case of being presence (1) or absent (0). The objective of the analysis is to determine the ‘weights’ or coefficients of the 36 elements, from the total panel.
The data are now ready for the first pass, viz., combining all the data into one database comprising 48 rows for each respondent, and 927 respondents. The equation is: TOP3 = k0 +k1(A1) +k2(A2) … k6(F6). Although the respondent evaluated combinations comprising three and four elements in a vignette, the OLS regression is easily able to pull out the part-worth contributions, the coefficients. The first estimated parameter, k0, is the so-called the additive constant. The remaining estimated parameters, coefficients k1-k36, are the weights for respective elements.
The coefficients are additive, viz., they can be added to the additive constant. The combination (additive constant + sum of elements in the vignette) provides a measure of how well the vignette is expected to perform. The only requirement is that the vignette comprises 3-4 elements.
8. Interpret the Results from the First Modeling
Table 2 shows the coefficients for the 36 elements as well as for the additive constant. Note that this will be the only time that the full set of 36 coefficients and the additive constant will be shown, to give a sense of the impact of each element. The Mind Genomics process produces what could become an overwhelming volume of data, the sheer wall of numbers disguising the strong performing elements.
Table 2: Coefficients of the 36 elements, sorted by the value in descending. The three strongest performing elements are shown as shaded cells
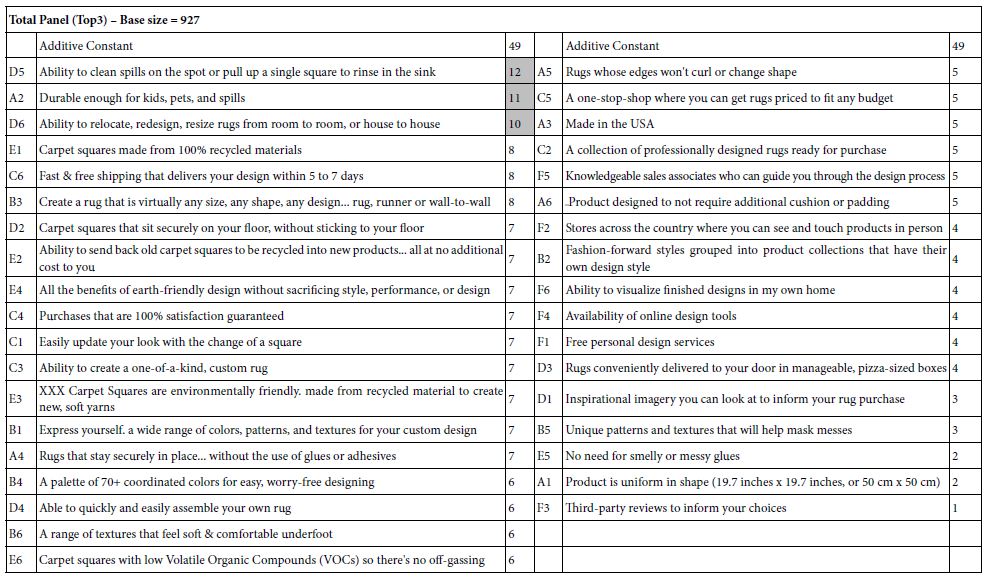
The additive constant, 49, is the estimated proportion of times people will rate the vignette as 7-9 (likely to purchase or very likely to purchase) in the absence of elements. The additive constant is a purely estimated parameter because by design all vignettes comprised 3-4 elements. Nonetheless, the additive constant gives a sense of the predisposition to buy. The value 49 means that about 49% viz., about half the people are likely to say to buy, even in the absence of elements which provide information. The additive constant of 50 is typical for a commercial product of moderate interest. s reference points, the additive constant for credit cards is around 10, the additive constant for pizza is about 65. Our first conclusion is that there is a moderate basic interest in the carpet design squares. The elements will have to do a fair amount of work to drive interest. The ‘work’ comprises the discovery of strong elements.
The coefficients in Table 2 may initially disappoint the researcher because out of 36 elements only three elements perform strongly from the total panel of 927 individuals. There might be at least two things going on to produce such poor performing elements. The first is that the messages are simply mediocre, despite the best effort of copyrighters and professionals to offer what they believe to be good messages. In such a case there is no option but to return to the drawing board and start again. The problem is in which direction, and how? The second is that we are dealing with groups of people in the population, mind-sets, who pay attention to different messages. The poor performance may emerge because we mix these people together, and their patterns of preferred elements cancel each, like streams colliding, preventing each other from continuing on their respective paths. In other words, the poor performance from the total panel may emerge from mutual cancellation of what otherwise be strong performance of some elements.
Clustering the Respondents into Two, Three, and Four Mind-sets
9. Create 927 Individual-levels to Prepare for Clustering into Mind-sets
The permuted experimental design is set up so that each respondent evaluated the precise types of combinations needed to run the OLS regression on the data of that individual. Thus, by running the 927 regressions, one per respondent, one gets a signature of the respondent in terms of the respondent’s mind-set regarding the product. The next step in the analysis runs the 927 different OLS regressions, storing them in a single matrix along with the self-profiling classification that the respondent did at the end of the evaluations.
10. Clustering the Respondents
Clustering is a popular technique to divide ‘things’ by the features that they have. Things, e.g., respondents, can be defined by the pattern of their 36 coefficients. Respondents with similar patterns belong in the same cluster, which will be called ‘mind-set’ because the clusters show what the respondents feel to be important for this flooring product. The respondents may not be similar at all in any way, but they are similar in their pattern of responses in this study.
11. Use K-Means Clustering (Likas et. al., 2003)
K-Means measures the distance between two respondents, based upon the similarity of their 36 coefficients. K-Means clustering tries to maximize the ‘distance’ between the two centroids of 36 numbers each computed on the respondents in the cluster, while at the same time minimize the sum of the pairwise distances within a cluster. ‘Distance’ between two respondents based upon the 36 coefficients was operationally defined as the quantity (1-Pearson Correlation Value). The Pearson correlation takes on the value of 1.00 when the 36 elements are perfectly linearly related to each other, making the distance (1-R)= 0. The Pearson correlation takes on the value 0f -1 when the 36 elements are perfectly inversely related to each other, making the distance (1-R)=2 (1 – – 1 = 2).
12. Interpret the Data
Table 3 shows the strong performing elements from three segmentation exercises: breaking the data into two mind-sets (clusters), breaking the data into three mind-sets,), and breaking the data into four mind-sets . There is an abundance of strong performing element within each cluster. We have created an artificial cutoff point of coefficients of 16 or higher being strong, and coefficients of 15 or lower being less relevant. The reality of the product, and the nature of the respondents presented with a real product show the strong performance of elements, performance hard to obtain with theory-based ideas. For this study, the elements in the table are selling points of real products, relevant to everyday life, not theory-based ideas lacking the life-giving power of reality and everyday importance.
Table 3: Strong performing elements four two, three, and four mind-sets emerging from the clustering the original 36 coefficients
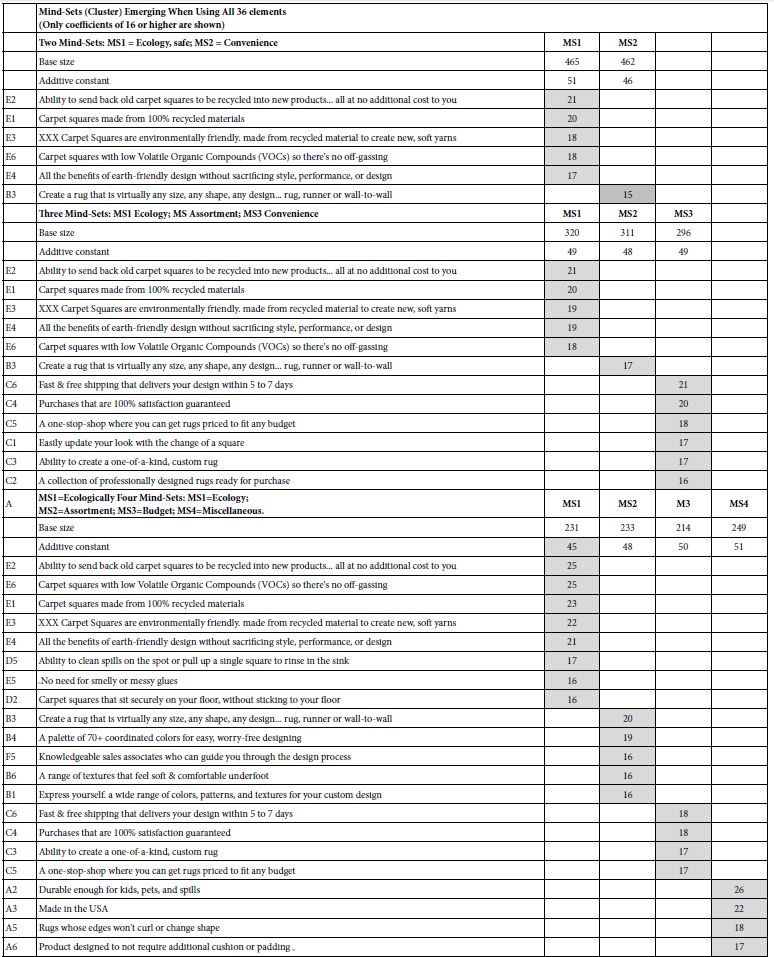
It is important to recognize that the mind-sets are easy to name. The strongly performing coefficients share some ideas in common. Based upon the strong performing elements one gets a sense of the respondent’s way of thinking in each mind-sets. it is also important to note that there is no ‘one correct’ number of mind-sets. The mind-sets tend to repeat but increasingly finer distinctions emerge between and among mind-sets as the number go from two to four
From 36 Down to 6 – Can We Improve the Clustering by Creating Fewer but Uncorrelated Predictors?
13. Hypothesis Based Upon the Efforts to Find ‘Primaries’
Although the 36 elements were put together in a way which may their appearances statistically independent of each other, the reality is that the elements might be skewed to one or another aspect, such as fewer elements in one topic area, and many more elements in another topic area. The Mind Genomics system tries to instill a balance in the nature of the elements used by forcing an equal number of elements or answers for each question. That strategy works for academic subjects but may not be the appropriate when the businessperson is trying to understand the mind of the customer.
With 36 elements, it may be advantageous to reduce the number of elements to a smaller set of ‘pseudo-elements,’ mathematical entities called factors which are uncorrelated with each other [19]. The application of principal components factor analysis to these data, with a moderate but not severe criterion for extracting a factor (eigenvalue > 2) produced a set of six uncorrelated ‘pseudo elements,’ the factors. The six emergent factors were uncorrelated with each other by the process of factor analysis. The factor structure was further simplified by rotating the six factors to a simple form, using Quartimax rotation. Finally, each of the 927 respondents become a point in this new six-dimensional space, where the rotated factor because the new ‘elements’, and thus name pseudo elements.
A Technical Note
The method of reducing the 36 elements to uncorrelated factors involves a great number of alternative choices, as does the method for creating the clusters of mind-sets. This paper simply chooses one way for exploratory purposes. Other factor analyses decisions might lead to different clusters, and a different decision. The foremost stated, this exploration is simply looking at a possible way to improve our knowledge emerging from the experiment, not as a method for ultimate discover of the ‘one array of mind-sets.
14. Interpret the Data
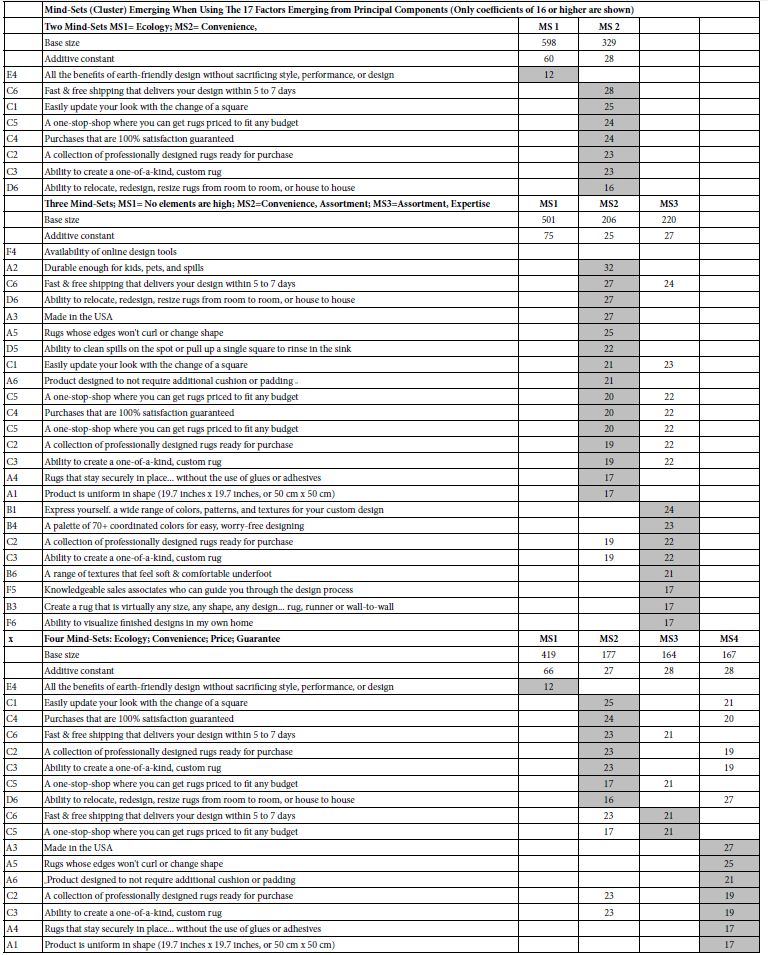
Table 4 recreates the two, three, and four mind-sets, this time using the clustering based upon the six factor scores of each of the 927 respondents, rather than on the original 36 coefficients for each of the 927 respondents. The results at first look promising in terms of many more elements emerging.. We see several interesting departures from what we saw in Table 3, which showed the same clustering, but with the full set of 36 coefficients. Returning to Table 4 we see that one of the additive constants is always high, suggesting that there is one mind-sets which is strongly predisposed to the items. Generally, this group will respond to most elements because their basic interest is high. The other one, two or three mind-sets show much lower constants, but many strong performing elements. The second observation is that these mind-set created after factor analysis are harder to name, because they comprise many more elements. The greater number of viable elements may have emerged because the additive constants are low, however.
Table 4: Strong performing elements among four two, three, and four mind-sets emerging from the clustering the six factor scores emerging from the 36 coefficients
15. Basic Composition of Mind-sets, Gender and Age
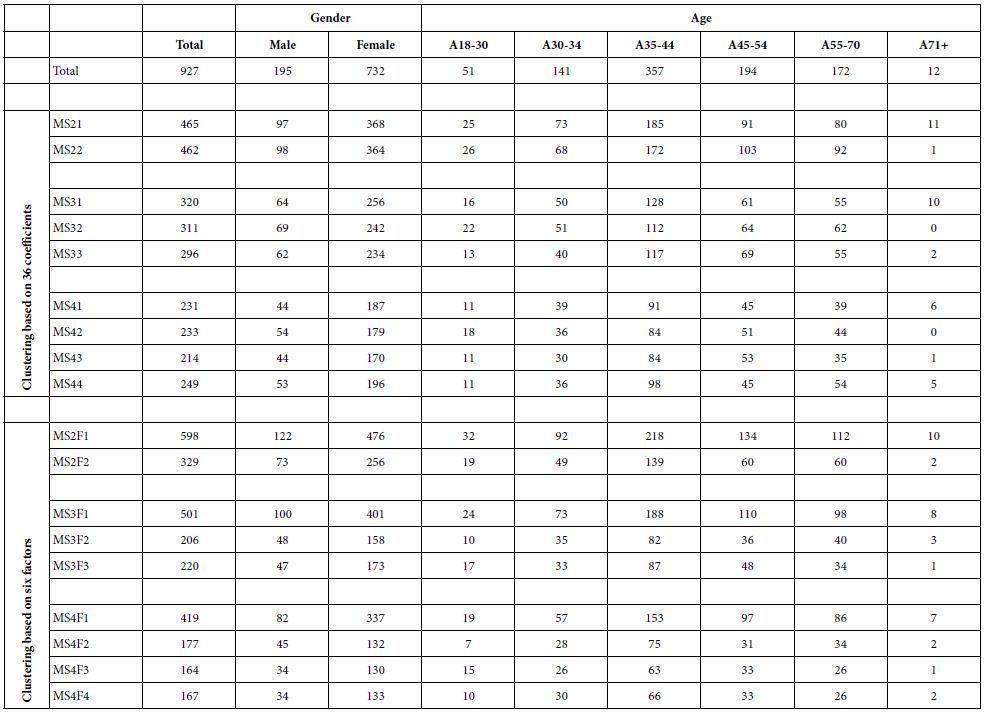
Mind Genomics continues to reveal that there is no simple relation between who a person IS and the mind-set to which a person belongs. Table 5 shows the composition of the mind-sets, by gender and by age. The patterns which emerge from Table 5 can be augmented by much more in-depth tabulations, beginning with more details about WHO the person is, what the person DOES at home regarding home decor, attitudes and behavior regarding SHOPPING, and so forth. The important thing is that by knowing more in-depth about the respondents, as well as the respondent membership, it might be possible to assign a new person to one of the segments.
Table 5: composition of the mind-sets by gender and by age, respectively
Discussion
16. The thrust of this paper is methodology, the study of method in the true sense of the word. The effort to understand method began with a simple question, ‘how many clusters or mind-sets to extract.’ It devolved into two questions of the same sort, one dealing with extracting mind-sets with the elements as is, and the other with extracting mind-sets after the elements have been reduced to orthogonality through factor analysis. And finally, the third and not directly stated question, why do the elements score so highly in this study, whereas in most Mind Genomics studies the elements rarely score this highly.
17. Question 1: Why do These Elements Score So Well, When in Most Mind Genomics Studies the Elements Score Poorly?
The answer to this comes from two aspects and can be best considered as conjectures. The topic of floor coverings is interesting, comprising interesting stand-alone elements which educate and intrigue people. In contrast, most of the topics worked on by Mind Genomics are more generic, deal with topics that are not so interesting, and fail to incorporate engaging information to present to the respondent. So, for the first answer the conjectures are we are dealing with an interested population, in a topic which can provide interesting information, rather than dealing with a topic whose ideas are usually watered down so that they provide little ‘juicy’ information to think about. In other words, it may be that conventional studies are simply bland.
18. Question 2: How Many Mind-sets to Extract
When we look at Tables 3 and 4, the results from the clustering our issue is that we just don’t know whether we should opt to call the mind-set by the most prevalent type of element in the mind-set, or whether we should accept the mind-set as comprising a mélange of different meanings. This problem of a mélange of different meanings will stop being a problem when we end up allowing six, seven eight or more clusters.
19. In the words of Harvard’s eminent psychology and founder of Modern-day Psychophysics, S.S. Stevens (d. 1973) ‘Validity is a matter of opinion.’ In Stevens’ words, as long as the experiments are performed correctly the answers are valid. All four solutions, Total, two, three and four mind-sets, would be equally valid if one were dealing with stimuli having no cognitive richness. The clustering algorithm does not pay attention to the underlying nuanced meanings of the element. If we were to assume that the elements are in some unknown language, and we extract two, three and found mind-sets, which solution would be correct? All would be equally valid in mathematical terms.
20. The issue is quite different when we work with elements. These elements have a great deal of meaning, cognitive richness. When we extract the clusters, we can look at the meaning of the element, and from the meaning decide upon the nature of the cluster. Based upon Table 3 the best strategy is work with four mind-sets, if these mind-sets can be identified. Each mind-set focuses on a different aspect of floor materials.
21. Question 3: Do Orthogonal Variables, Presumably Balancing Out Different Ideas, Produce More Interpretable, Tighter Clusters or Mind-sets?
Is it better to work with the original set of elements when creating mind-sets, or should we reduce the elements to a set of mathematically independent variables, such as our six factors? Table 4 suggests that it was difficult to find a simple guiding theme for each cluster or mind-set, despite the emergence of high positive coefficients. As a result, it is probably better to work with the original set of elements, and not perform the factor analysis to produce a smaller group. In the end, we want to make sure that the mind-sets we identify are real and meaningful, and that the combinations generated from these mind-sets make sense and score as high as possible.
References
- Kamtekar R (2013) Plato: Philosopher-Rulers. In: Routledge Companion to Ancient Philosophy (pp. 229-242). Routledge.
- Bayer G, (1998) Classification and explanation in Aristotle’s theory of definition. Journal of the History of Philosophy 36: 487-505.
- Gajanova L, Nadanyiova M, Moravcikova D (2019) The use of demographic and psychographic segmentation to creating marketing strategy of brand loyalty. Scientific Annals of Economics and Business 66: 65-84.
- Wells WD (1975) Psychographics: A critical review. Journal of Marketing Research 12: 196-213.
- Garreau J (1981) The Nine Nations of North America. Avon Books.
- Webber R, Sleight P (1999) Fusion of market research and database marketing. Interactive Marketing 1: 9-22.
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2006) Founding a new science: Mind Genomics. Journal of Sensory Studies 21: 266-307.
- Moskowitz HR, Silcher M (2006) The applications of conjoint analysis and their possible uses in Sensometrics. Food Quality and Preference 17: 145-165.
- Carroll JD, Green PE (1995) Green Psychometric methods in marketing research: Part I, conjoint analysis.” Journal of marketing Research 32: 385-391.
- Gofman A, Moskowitz HR (2010a) Improving customers targeting with short intervention testing. International Journal of Innovation Management 14: 435-448.
- Goldberg SM, Green PE, Wind Y (1984) Conjoint analysis of price premiums for hotel amenities. Journal of Business S111-S132.
- Green PE, Krieger AM, Wind Y (2001) Thirty years of conjoint analysis: Reflections and prospects. Interfaces 31: S56-S73.
- Wind J, Green PE, Shifflet D, Scarbrough M (1989) Courtyard by Marriott: Designing a hotel facility with consumer-based marketing models. Interfaces 19: 25-47.
- Laparra-Hernández J, Belda-Lois JM, Medina E, Campos N, Poveda R (2009) EMG and GSR signals for evaluating user’s perception of different types of ceramic flooring. International Journal of Industrial Ergonomics 39: 326-332.
- Macias N, Knowles C (2011) Examining the effect of environmental certification, wood source, and price on architects’ preferences of hardwood flooring. Silva Fennica 45: 97-109.
- Roos A, Hugosson M (2008) Consumer preferences for wooden and laminate flooring. Wood Material Science and Engineering 3: 29-37.
- Zamora T, Alcántara, E, Artacho MA, Cloquell V (2008) Influence of pavement design parameters in safety perception in the elderly. International Journal of Industrial Ergonomics 38: 992-998.
- Gofman, Alex, and Howard Moskowitz (2010b) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145.
- Cureton EE, D’Agostino RB (2013) Factor Analysis: An Applied Approach. Psychology Press.