Abstract
98 respondents each evaluated unique sets of 60 vignettes, combinations of messages created from a base set of 36 different messages. These messages dealt with the reaction to aging. Respondents rated the vignettes in terms of the anxiety specifically about aging that the vignette provoked, using an anchored 9-point scale (1=Can deal with it … 9=Cannot deal with it). Transformation to a binary scale and then analysis by regression revealed that the greatest sources of anxiety came from three different messages dealing with different aspects (living in an old age home, treatment by a plastic surgeon, reliance on one’s employer). These three messages were strong performers for virtually all groups, although for groups defined by geo-demographic other messages occasionally emerged as strong, but in an inconsistent manner. Three mind-sets emerged, but were not radically distinct from each other, suggesting that when people think about age they think about the cluster of above-mentioned issues, viz., loss of independence (living in an old age home), loss of physicality (plastic surgeon), and betrayal (one’s own company).
Introduction
The ongoing advancement of medicine and a newfound focus on a healthier lifestyle has allowed us to live longer, but not without consequences. The issue of ‘aging’ is becoming increasingly important. The popular press is filled with the repercussions of getting older reflected in stories from individuals and their linkage with the issues of aging. The increase in the number of senior residences, retirement homes, and at-home care further portrays tangible evidence of the growing aging population as these are being built to reflect the demand for these services.
As a society, we are well aware of the issue of aging, ranging from the practical worries about one’s health, one’s mobility in daily life, the loss of loved ones, and the host of legal issues which require attention for the orderly transfer of one’s estate [1-3]. To offset these anxieties, we often see the aging population utilizing plastic surgery, dyeing their hair, or not associating with other elderly people to hide the fact that they are ‘getting old’ (https://journals.sagepub.com/doi/pdf/10.2190/1U69-9AU2-V6LH-9Y1L). The aging population often also refuses retirement homes or senior community living to feel independent from others their age who are aging too. When confronted with no other option but to accept the inevitable, elderly individuals that are subjected to assisted living often face higher levels of anxiety about aging [3].
If these worries are not enough, there are the nagging expected but dreaded major events on the road to aging, often manifested in jokes among friends, jokes which attempt to defuse the grimness of getting old. With this, the stereotype of ‘getting old’ begins early on and, if accepted, leads to higher anxiety about aging later in life. These jokes may seem harmless but can lead to serious consequences [2].
Mental health issues in the elderly population are real and often overlooked. With social media and mental health awareness coinciding, the spotlight on mental health issues often falls on the youth. The aging population, whether it be due to fear, inability or stubbornness, often lacks access to social media and therefore many mental health resources. The mental health crisis for the elderly may seem minimal, but studies show it is present and neglected. As one’s physical health begins to deteriorate, their mental health is at risk of following quickly. The anxieties about aging can be life-threatening leading to, in extreme but not uncommonly death by suicide https://jamanetwork.com/journals/jamainternalmedicine/article-abstract/217074). Although a universal problem, it is important to note that the levels of anxiety about aging differs based on qualities such as race, gender, age, sexual orientation, and socioeconomic status [1,4,5].
There is significant popular press on the issues of getting old, these topics becoming more frequent over the past ten years. One need only look at the number of articles on ‘aging’ using Google® as a measure to demonstrate this increasing frequency. As of this writing (July, 2022), Google® reported 103 million hits or sites (July, 2022). The Google® list is led by the scientific definition of anxiety about aging, gerascophobia, taken from the Wikipedia article:
Gerascophobia is a clinical phobia generally classified under specific phobias or fears of a single specific panic trigger. Gerascophobia may be based on anxieties of being left alone without resources and incapable of caring for oneself due to age-caused disability]
Due to humans being mortality salient, sufferers will often feel as though aging is the first sign that their immune systems are starting to weaken, making them more vulnerable and prone to diseases… Some sufferers seek plastic surgery to make them look more youthful while the main concern of others is a fear of internal, biological long-term damage caused by the aging process.
Source: https://en.wikipedia.org/wiki/Gerascophobia
The Mind Genomics Approach to the Way People Think
A great number of the published studies on aging deal with the nature of the fear, its causes, manifestations, and suggestions about how to reduce it. The studies in the scientific literature focus on the nature of anxiety about aging [2,4,6], its manifestations [7] and the construction of scales to measure anxiety [5]. The papers published paint a rich picture but can be augmented by other research approaches with a history founded in consumer research. We present one way, using Mind Genomics.
During the past forty years, the emerging science of Mind Genomics has attempted to understand the way people respond to the information of everyday life. Our daily lives are filled with situations which cause angst and discomfort, as well as being filled with situations which do the exact opposite, bring us joy. How can we quantify the experience of everyday life, merging the richness of experience and the discipline of quantitative science? And, to go one step further, how can we create a living ‘database’ about the features of everyday experience, a database that can be used to study differences among people, among situations, and over time?
Mind Genomics was designed with the foregoing vision in mind. When studying people over the past century, psychologists have been able to understand a person as an individual or a small group of individuals acting together. This is known as the idiographic approach, studying the person (or small group) in detail. The information obtained is deep, but not scalable, not general, and usually not quantitative. Psychologists have also studied people in larger groups, using the nomothetic approach, looking for general laws of group and individual behaviors. It is from these roots in psychology that Mind Genomics emerged.
One can trace the evolution of Mind Genomics, and its application in this specific paper on aging, to three different sciences/disciplines: consumer behavior, psychophysics (a branch of experimental psychology), and statistical model building, respectively. Together, in this emerging science of Mind Genomics, these three disciplines shed light on motives and drivers of human behavior, doing so in a way which invites experimental science to contribute, and which allows a rich database of information to be created, and continually updated in a cost-effective, rapid, and scalable fashion.
Psychophysics is the branch of experimental psychology interested in the relation between stimuli and perceptions. It is from psychophysics that we learn how to quantify perceptions, such as the sweetness of different concentrations of sugar dissolved in water. The founder of modern-day psychophysics, S.S. Stevens of Harvard University, called this effort ‘outer psychophysics,’ because the effort was to measure the subjective magnitude of a physically-measurable stimulus, e.g., the aforementioned sweetness of different concentrations of sugar solutions. Mind Genomics uses somewhat similar methods to measure the intensity of ‘thoughts, which are not physically measurable, but which are real. This is the so-called ‘inner psychophysics’ of Stevens ([8], personal communication). It is important to note that the research does not use physiological measures of body reactions, such as EEG (brain waves), GSR (skin resistance, the galvanic skin response), eyeblink, and so forth. We may summarize the contribution of psychophysics to Mind Genomics as the objective to quantify experience at the conscious, rational level.
Consumer Research is a growing branch of applied science, focusing on how people make decisions about the practical world of daily life. The emphasis here is on ‘practical’ and ‘daily.’ For example, how do people trade-off different features of products, knowing that they cannot afford all of them? For products, what is important, what is not important. Is there a willingness to pay more for items that one likes? And, of course, when we read information about something and react to that information, can we be said to follow one of several different patterns of behavior? Consumer behavior lies at the nexus of applied psychology, marketing research, sociology, behavioral economics and other social sciences. It is from consumer research that Mind Genomics takes the approach of testing combinations of stimuli, combinations that present scenarios, situations, rather than testing one idea at a time. Names such as Paul Green and Jerry Wind at Wharton School of Business at the University of Pennsylvania deserve mention here for their population of these approaches [9], along with Norman Anderson who did similar types of investigations, calling the approach ‘functional measurement’ [10].
Our final area of foundational work comes from the world of statistics, and specifically the efforts of those who create experimental designs [11]. These designs are specified combinations of factors, set up so that the respondent evaluates the combinations in a way that the evaluation of a number of such combinations allows it to become possible to deconstruct the rating to the part-worth contribution of each element of the set originally combined. In other words, the world-view of psychology and consumer research, that the measurement should be taken on the combination of factors, is delivered through statistics, through the experimental design. It takes only the effort to combine the independent variables into combinations, so-called vignettes, and have the respondent test the vignettes, that Mind Genomics can actually measure the cognitive response to ideas, the inner psychophysics, in a far less biased, more effective way.
The Mind Genomics Paradigm Applied to the Personal Experience of Anxiety
The Mind Genomics paradigm has been worked out and simplified over the past thirty years. The approach uses an underlying experimental design, in which the research begins with a single topic, asks a series of questions which ‘tell a story,’ and for each question creates a set of answers, ‘elements’. The Mind Genomics approach has been used extensively for a variety of topics, ranging from studying response to objects (e.g., foods; [12]) to situations [13], and even to the law [14], and health [15].
The experimental designs used by Mind Genomics are created to possess the following critical properties:
Basic Approach
Mind Genomics ‘works’ by combining phrases, presenting these combinations (called vignettes) to respondents, getting the reaction to the combinations from a respondent, and then deconstructing the responses to the contribution of the individual elements. All of this is controlled by an underlying structure called the experimental design.
The Basic Design
The experimental design for the study calls for 60 vignettes, each element appearing five times and absent 55 times. Furthermore, ‘doing the math’ shows that each question, with nine answers, ends up contributing to 45 of the 60 vignettes, and thus by design is absent from 15 of the 60 vignettes. The absence of elements is controlled by the design, producing mainly vignettes comprising four answers (one from each question) but also vignettes comprising three answers, and vignettes comprising two answers. In no case are there vignettes comprising only one answer. The statistical benefit of working with incomplete vignettes of 2-3 elements, along with complete vignettes of four elements is that the structure avoids statistical multi-collinearity, where knowing the status of 8 answers to a question (vignette) automatically determines the status of the ninth element. Were that to be the case, the regression modeling would fail.
Permutation
The experimental design is a structure whose form is maintained, but the specific elements can be permuted, as long as the element does not change the question that it answers. This permuted design means that the same element can one time be ‘A1” but another time ‘A2’, and a third time ‘A3’, etc. As a result, the vignettes evaluated by one respondent will be different from the vignettes evaluated by another respondent. The benefit is that the researcher can use Mind Genomics to ‘explore’ the topic, rather than select a limited, specific set of combinations [16].
Different-size, Often Incomplete Vignettes, Allowing for More Powerful Regression Analysis
The vignettes are small but of different sizes. The underlying experimental design specifies which particular elements are combined in a vignette. Typically, the vignettes comprise as few as two elements, and as many as four elements (or in some designs five elements). The underlying experimental design ensures that the elements are statistically independent of each other. The design also ensures that the data from each individual respondent can be analyzed without reference to any other data in the study. This is called a ‘within subjects’ design.
For the data set we explore (Aging, in the Deal with It! study) we use an experimental design comprising four questions, each question with nine answers (36 elements). The elements were combined by the underlying design into a total of 60 different vignettes, each element appearing five times and absent 55 times from the 60 vignettes. Although the design is permuted, no element (answer to one of the four questions) is allowed to change the question that it is answering. That is, an element can start as A1, be permuted to A2, or A8, but never jump into the B, C, or D questions.
This study on aging comes from a set of parallel studies run in 2003, called the It! Studies [17]. The objective of the studies was to create a database about reactions to common products or events, with each topic covered by one study. The earliest studies dealt with food and beverages (Crave It!, Drink It!, Good for You!). The later set of studies, run a year or two later, dealt with shopping (Buy !), with insurance (Protect It!), and finally with topics likely to cause anxiety (Deal With It!; [18]).
The study on anxiety and aging with it was one of 15 different studies, as shown in Figure 1.
The topics of these It! studies were open to respondents recruited by an online panel provider, Open Venue Ltd., in Toronto, which provided US respondents. The respondents were invited to the study by email containing an embedded link. The wall showed the respondents the 15 different studies. Respondents chose the study which interested them or simply deleted the invitation. In contrast to the typical studies in the It! series, viz., those dealing with pleasant subjects like food, beverages, shopping, etc., where the studies ‘fill’ rapidly and disappear from the wall in Figure 1, those studies in the Deal With It! series took an unusually long time to reach 100 respondents, often more than a week. Furthermore, a large number of respondents dropped out of these studies because of the unpleasant nature of the topic. The dropout rate often exceeded 50%, a very unusual number.

Figure 1: The 15 different studies in the Deal With It! Project
Table 1 presents a screenshot of the structure of the invitation as would be sent to the respondents. The invitation provides enough information about the study to engage respondents who are interested, but has no information about what might be an ‘appropriate answer.’ The invitation provides information about the length of time (15-20 minutes), and about the incentive (a drawing for money prizes).
Table 1: The draft version of the invitation to be sent to respondents.

The Raw Materials for the Study
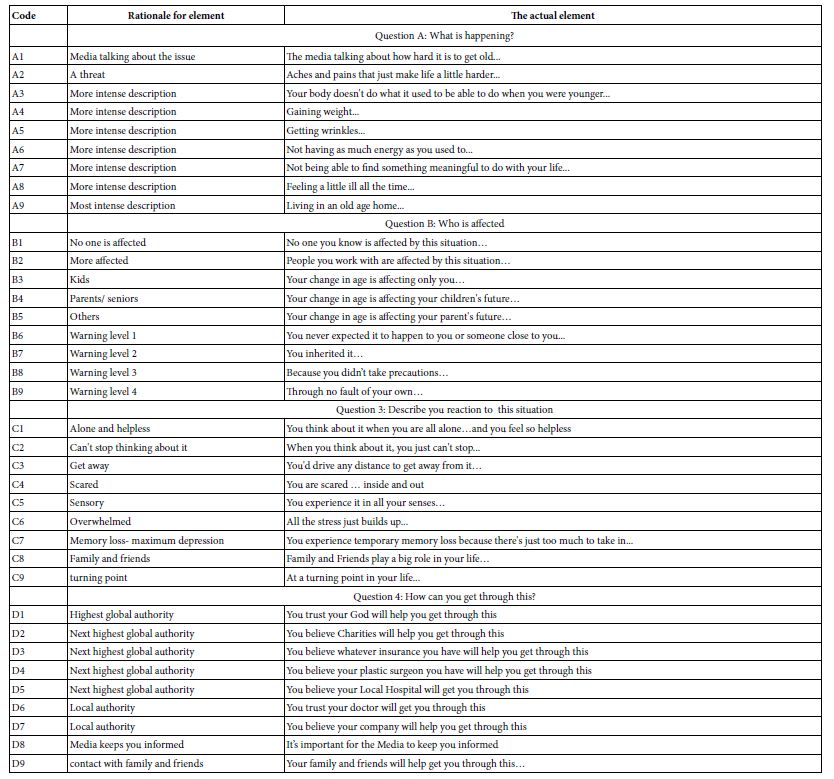
Table 2 presents the elements and the rationale for the elements. The driving force in the It! studies was to create a series of elements which represented different aspects of anxiety. Since the It! studies were to deal with 15 different topics, the elements were slightly modified by topic (e.g., aging vs obesity) in order to make ‘sense’ The elements were kept as parallel as possible across all 15 studies. The language of the element was made as colloquial as possible while maintaining clarity. Finally, some of the elements presented the information as a description, other elements presented the information as if one were talking to oneself, or describing one’s emotions to another, but always from the point of a third person.
The 36 elements or answers in Table 2 fall by design into four groups, four questions. The purpose of the question is to drive the answer, to make sure that the answer ‘fits’ the question. In the end, however, the question itself is only a bookkeeping device, to make sure that the question does not generate answers which ‘don’t belong’. That bookkeeping property, to keep the ‘meanings’ straight, means that two or more different answers, statements which are of the same type but convey mutually contradictory information, will never appear in the same vignette. The respondent need not see the questions. Only the response to the answers is important because that is where the relevant information lives.
Table 2: The four questions, the nine answers to each question, and the rationale for each element. The respondent never saw the rationale for the element, but only the element itself.
The actual interview required about 15-17 minutes. The interview was structured, beginning with the introduction to the topic shown in Table 1, followed by the presentation of 60 vignettes. The vignettes were absolutely different from one respondent to another, ensured by the ‘permutation’ of the basic experimental design. Finally, the respondent completed an extensive self-profiling questionnaire shown in Table 3. The self-profiling questionnaire will permit the correlation between how the respondent describes herself/him and the pattern of reactions to the elements.
Table 3: The self-profiling questionnaire


It is important to emphasize that the respondent cannot possibly ‘game’ the Mind Genomics system, simply because the elements are presented in groups of two, three, and four, respectively, in a way which seems utterly ‘random’ to most respondents. Indeed, when respondents describe their feelings about the study, doing so after the fact in follow-up contacts, many say that they feel that their answers are totally random, and they are guessing
Data Transformation at the Level of the Individual Respondent
A key benefit of Mind Genomics is the ability to create an individual-level model relating the presence/absence of the 36 elements to the ratings or to transforms of the ratings. The responses themselves may either be the original 1-9 rating or, more typically in Mind Genomics studies, a transform of the 1-9 scale. The transform changes ratings of 1-6 to 0, and ratings of 7-9 to 100, and afterwards adds a vanishingly small random number to each transformed number. The rationale for doing that is to prevent all 60 ratings from one respondent to be transformed into either 0 (in the case where all ratings lay between 1 and 6), or 100 in the case where all ratings lay between 7 and 9). The vanishingly small random number ensures that the transformed rating has some marginal degree of variability, allowing the OLS (ordinary least-squares) regression to work.
The scientific rationale for the conversion to a binary scale is that very few people really understand what the scale values actually mean. Thus, the typical manager will ask for clarification of the data, when all that is needed is an explanation of what the presented averages ‘really mean!. According to S.S. Stevens, the aforementioned founder of modern-day psychophysics, the hardest thing in science is to move from a continuous function to a discontinuous function, viz., to chop a continuum into meaningful components.
After the conversion is made, the data from each respondent is subject to the statistical procedure of OLS (ordinary least=squares regression), colloquially called ‘curve fitting’ [19]. The objective is to deconstruct the transformed ratings for a given respondent to the contribution of each of the 36 elements. Recall that each respondent rated 60 unique vignettes and that the 36 elements were combined in ways that ensured that the elements would be statistically ‘independent of each other. This effort pays out handsomely, allowing the regression model to describe the relation between the elements and the ratings by the equation: Binary Rating = k0 + k1(A1) + k2(A2) … k36(D9).
This simple equation, estimated separately for each respondent, produces a matrix of data, one row for each respondent. Each row in the matrix comprises the additive constant, followed by 36 columns of numbers, each column corresponding to one of the 36 elements. The coefficients tell us the estimated contribution of each element to the binary transformed rating. One can imagine this column of data multiplied 98 times, to create 98 rows of data, one row for each of the 98 respondents who participated.
Table 4 shows the output of the regression modeling for three respondents, #1,#2 and #3, respectively. The model features an additive constant (estimated binary transformed rating in the absence of elements, a purely theoretical parameter, but a good baseline), and then 36 rows, one row per coefficient. Table 4 is ‘transposed,’ so that the rows correspond to the 36 elements. The transposition from row to column is made simply to show the large table in an easy-to-read format.
Table 4: Example of coefficients for three respondents< #1, #2, #3, emerging from individual-level regression, and the recoding of those coefficients (0 unless coefficient is greater than 8, in which case it is transformed to 100).
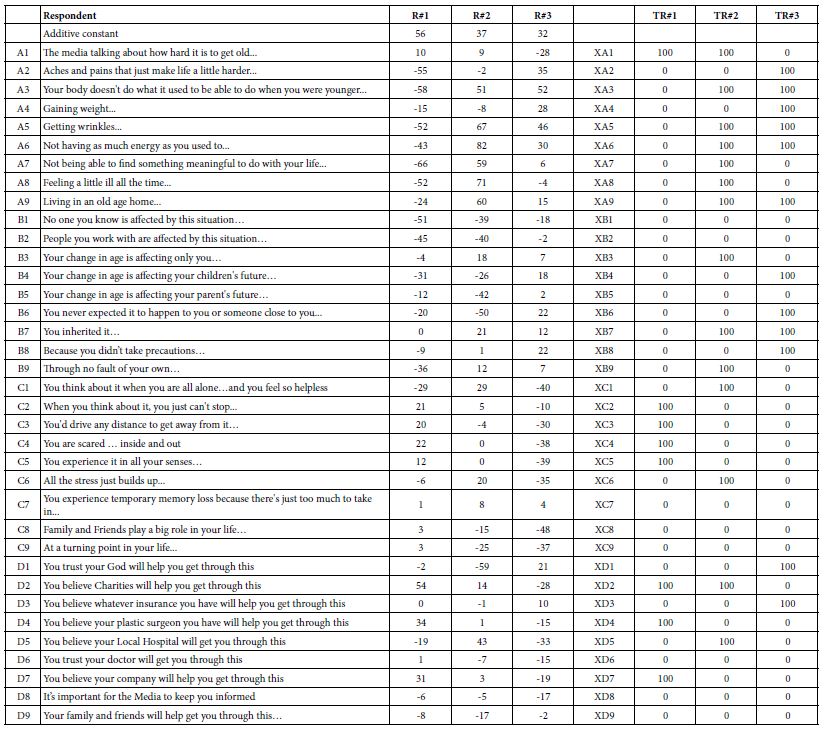
Statistical analysis of the modeling suggests that coefficients of +8 or higher are ‘statistically’ significant, viz., that they are probably not 0. In view of that, we end up learning more by ‘taming’ the wide range of coefficients. The taming consists of replacing all coefficients of 8 or higher by 100 to show that the element drives anxiety (cannot deal with it, viz., rating of 7-9). The transform further replaces all coefficients lower than 8 by 0, to show that the element does not drive anxiety (rating of 1-6 on the 9-point scale, the region where the respondent feels that the vignette does not drive the feeling of anxiety). In Table 4 the original coefficients for respondents 1-3 are labelled R#1, R#2 and R#3. In turn the transformed coefficients for the same three respondents are shown to the right, and labelled TR#1, TR#2, and TR#3, respectively. The elements are now renamed to be XA1, to denote that numbers associated with them are the newly transformed 0/100. The foregoing may seem to be a great deal of work, but the analysis will show the patterns far more easily.
Results
We begin with the average transformed coefficients from the total sample of 98 respondents (Table 5). For the total panel, we look at all 36 coefficients, as well as the additive constant, which was not transformed. The additive constant is 28, meaning that in the absence of anything else except knowing the topic is ‘aging,’ 28% of the respondents would rate a vignette 7-9. All vignettes comprised 2-4 elements by design, so the additive constant is an estimated parameter.
It is the averages of the transformed coefficients which are of major interest. In Table 5, as well as in the other tables of averages, those elements are shaded which generate a value of 50 or higher. This cut-off means that across all 98 respondents, 50% or more generate coefficients of +8 or higher for a specific element. We would conclude that this element drives anxiety.
Table 5: The averages of the transformed coefficients for the total panel. The 36 coefficients are sorted in descending order. Averages of 50 or higher are shaded.
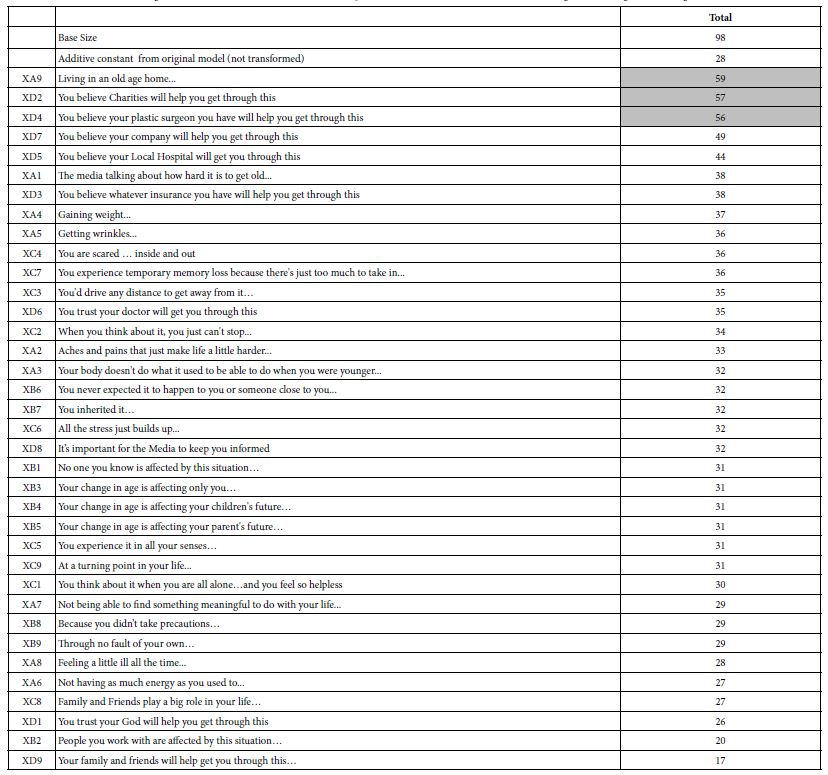
The averaging suggests three major worries:
a. Living in an old age home (viz., loss of independence)
b. You believe Charities will help you get through this (viz., loss of economic independence)
c. You believe your plastic surgeon you have will help you get through this (loss of attractiveness and vitality).
Table 5 suggests that there are some common, but not necessarily universal fears about aging. What is remarkable is that these fears ‘make sense’ and are easy to interpret, even though as noted above, the vignettes seem to be, in the words of Harvard psychologist William James, a ‘blooming, buzzing confusion’, leaving respondents feeling that they were just guessing when their data seems quite reasonable, at least in terms of the average.
Creating Easier to Read Tables of Data
Mind Genomics studies generate large tables of data, especially when the elements are ‘cognitively meaningful’ in and of themselves, rather than being points which make sense only in patterns. With Mind Genomics the individual elements carry with the richness of experience and an invitation to reflection and explanation.
The early Mind Genomics studies, of which this study is an example, comprise four questions, nine answers, and thus 36 elements. Thus, each subgroup to be considered generates 36 averages. That amount of data overwhelms, becoming a ‘wall of numbers.’ The way out of the quandary is to eliminate all data with averages less than 50 and to eliminate all elements which fail to generate an average of 50 for at least one subgroup. This first step, pruning, shortens the data tables, making the patterns easier to discern.
The second step ranks the elements and ranks the subgroups, both in descending order, so that the top element is the one with the strongest performance across the different subgroups (called Row Sum), and the strongest subgroup (is the one with the strongest performance across the different elements (called Column Sum). These two statistics, row sum and column sum allow the strong performing elements to emerge. The pattern is easy to identify since the only data in the table are averages of 50 or higher.
Differences by ‘Time of Day’?
The first question in the self-profiling questionnaire was the time of day in two hour sections. Although we don’t typically think of studies as influenced by when the respondent participated, part of the issue with the Deal With It! series was to search for deep, hitherto unexplored effects. Following the approach described above, Table 6 shows the strong performing elements by time of day.
Table 6: Average transformed coefficients by ‘time of day’. On strong performing averages of 50 or higher across the appropriate respondents appear in the table.
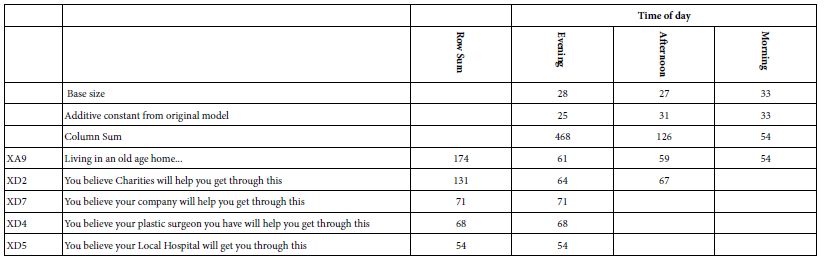
The first thing to notice about the data in Table 6 is that there are only five elements. One element is ‘living in an old age home…’, which will reappear in analysis after analysis. The other four strong performing elements are the response to statements that others (e.g., Charities) ‘will help you get through this.’ Clearly, relying on a second party outside of one’s control causes anxiety, even though the statement is meant to be a statement that there is someone else to help.
The second thing to notice is that the respondents who participate in the evening show far greater anxiety, whereas the respondents who participate in the afternoon and the morning show far less anxiety. We see that from the column sums of strong performing coefficients (468 for evening, 126 for afternoon, and only 54 for morning.
Finally, the additive constant from the original, untransformed model, average around 25-33, suggesting a low predisposition for an anxious response. Recall that the additive constant is an estimated parameter that shows the percent of responses 7-9 to be expected in the absence of elements. In other words, the additive constant is an estimated baseline.
Differences by WHO the Person is (Gender, Age, Income, Where the Person Lives)
The extended self-profiling classification shown in Table 3 allows us to learn a lot about who the respondent is. The questions, ranging from gender to age, income, and even neighborhood, may produce some new insights into what concerns the respondent. With that in mind, we now look at Tables 7-10.
Gender (Table 7): The respondents comprised primarily females, a distribution which often is corrected for by oversampling males until a balance is reached. In the It! studies, starting back in 2001 and continuing until 2004 for all of the It! studies, no effort was made to balance the genders. With 15 studies in the Deal With It! project, and with a limited budget, gender balancing might be laudable but unaffordable.
Table 7 shows the strong performing elements. Both males and females begin with modest basic anxiety (additive constant 31 vs 28, based on the original model, before transformation). It is when we get to the performance of the specific elements that we see the dramatic gender differences. The one element which makes both males and females very nervous is XA9, living in an old age home, with the value for the males 83, and the values for the females 56. We interpret that to mean that 83% of the males feel that living in an old age home is something with which they could not deal. Females were less responsive, with a coefficient of 45, meaning 56% of the females respond that they could not deal with it. Keep in mind once again that the respondents were not directly asked about living in an old age home, but rather than element was part of a set of 2-4 elements combined into a vignette.
Table 7: Average transformed coefficients by ‘gender’. On strong performing averages of 50 or higher across the appropriate respondents appear in the table.
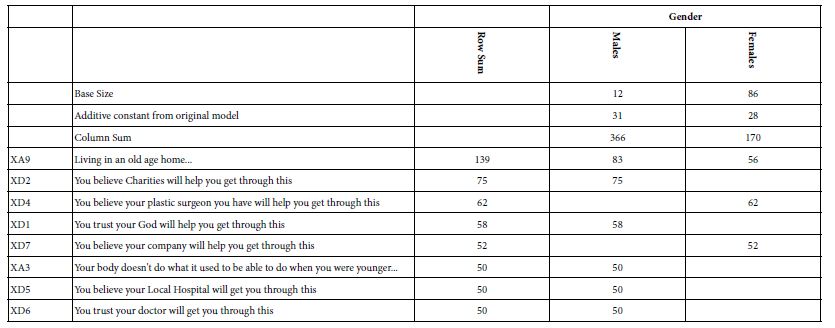
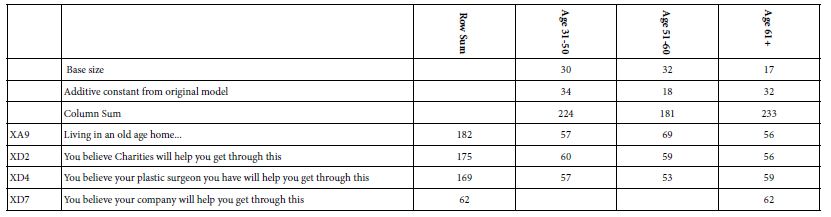
Table 8 shows the strong performing elements by age. The columns are arranged by age, rather than by column sum to allow any age-related pattern to emerge. Once again we see the same three elements emerging as most anxiety provoking (living in an old age hold, help from charities, help by plastic surgeon) The one major new entry, not surprisingly, is the response from the older respondents (age 61+) who are most frightened when they read ‘You believe your company will help you get through this.’ Their strong response to this element, even twenty years in 2003, suggests that older people near or past retirement are insecure and nervous when they think of their companies as providing any help to older employees or former employees.
Table 8: Average transformed coefficients by ‘age’. On strong performing averages of 50 or higher across the appropriate respondents appear in the table.
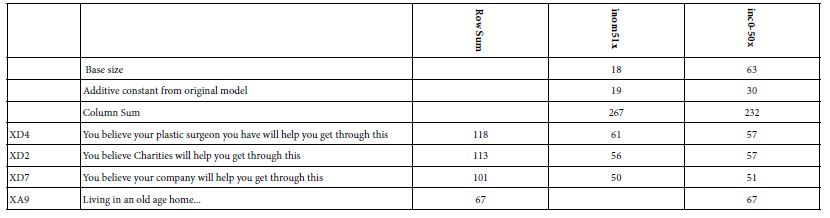
Income tells the same story as age, as shown in Table 9.
Table 9: Average transformed coefficients by ‘income’. On strong performing averages of 50 or higher across the appropriate respondents appear in the table.
Respondents selected the type of neighborhood in which they lived. Table 10 shows that there is a great disparity in the distribution of the strong responses by neighborhood. Those respondents identifying themselves as living in a city, but a suburban (residential) area in the city showed the greatest number of elements which drove anxiety.
Table 10: Average transformed coefficients by ‘type of neighborhood in which the respondent resides’. Only strong performing averages of 50 or higher across the appropriate respondents appear in the table.
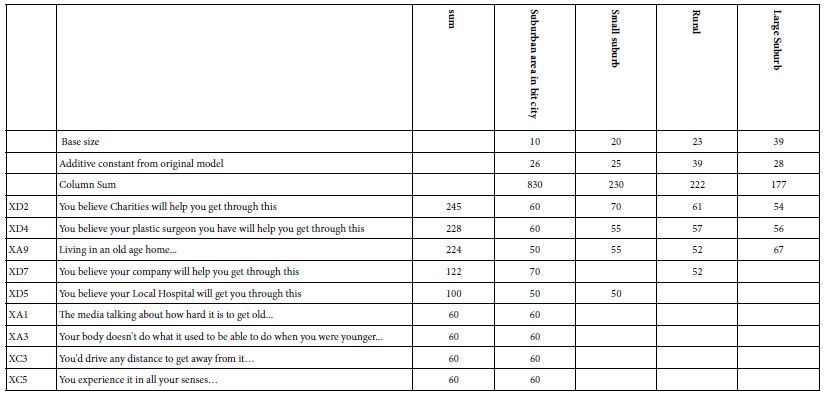
When we look at the data more deeply, however, we find that the strong performance is due to a few anomalies. These elements drive anxiety for only one or two groups of respondents
- You believe your company will help you get through this -Suburban area, Rural
- You believe your Local Hospital will get you through this – Suburban area, Small suburb
- The media talking about how hard it is to get old… – Suburban area
- Your body doesn’t do what it used to be able to do when you were younger… – Suburban area
- You’d drive any distance to get away from it… Suburban area
- You experience it in all your senses… Suburban area
If we discount these six elements are relevant to one subgroup, or at most two, we end up with the same elements which are responsible for the strongest anxiety, namely charities, plastic surgeon, and old age home.
Is There a Relation between What a Respondent ‘Feels’ and the Pattern of Elements Which Drive Anxiety?
Question 6 of the self-profiling questionnaire asked the respondent to introspect about how she or he feels and check all the emotions on a list which apply. The question did not attempt to link the feelings to the vignettes because the respondent had just evaluated 60 vignettes. Nonetheless, it is instructive to look at the covariation between what a respondent selects as anxiety product (rating 7-9) and what feelings the study leaves with the respondents.
Table 11 shows the table, once again in the standard format. The dynamics of the data remain generally the same. That is, there are the three major aspects driving anxiety (charities, plastic surgeon and old age home, respectively). These generate the highest sum for the three most negative feelings (frustrated, depressed, bored). The other two elements which co-vary most strongly with these emotions deal with the local hospital and one’s own company. Based upon the data from the previous analyses, these strong performing elements do not surprise. Four of the elements deal with being helped, when one needs help (charities, plastic surgeon, hospital, one’s own company). There is once again a sense of being frightened that these presumed ‘allies in life’ will prove actually impotent, or unwilling to help. The fifth one, old age home, speaks to a sense of helplessness.
The right side of Table 11 shows the selected emotions with the lowest column sums, viz., the lowest degree of causing anxiety across the 36 elements. These four emotions/feelings, from the lowest up, happy, optimistic, energetic, and relaxed, four positive emotions. The elements which drive anxiety for people reporting these emotions are the ones that we have to come to expect, namely charities, plastic surgeon and old age home.
Table 11: Average transformed coefficients by selection of up to three emotions experienced by the respondent after having evaluated 60 vignettes. Only strong performing averages of 50 or higher across the appropriate respondents appear in the table.
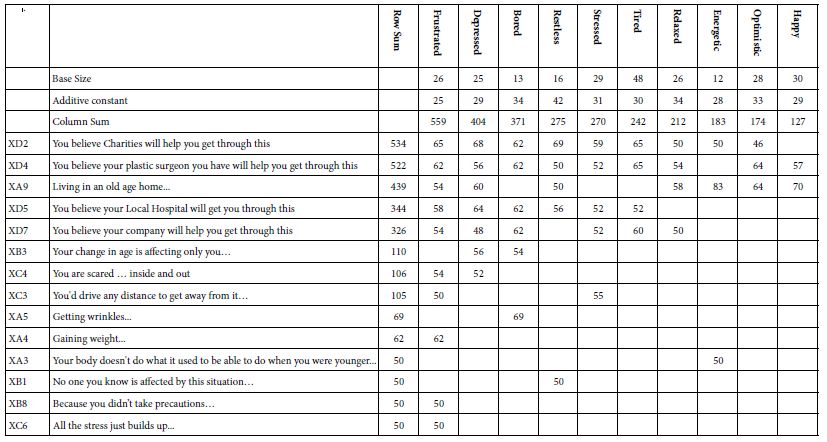
The ability to cross-reference one’s selected emotions at a given time with the elements driving anxiety creates a new opportunity for Mind Genomics. There is now the possibility of looking at the covariation of emotions and anxiety producers, in a situation where the respondent cannot possibly ‘game’ the system.
Deconstructing the Respondents into Mind-sets Based Upon the Pattern of the Coefficients
A hallmark of Mind Genomics is the ability to cluster the respondents into different groups, so-called mind-sets, based upon the pattern of coefficients. Clustering is a well-defined class of statistical processes which divide a group of objects (e.g., people) into non-overlapping groups, based upon the pattern of measures [20]. For our study clustering is done by dividing our 98 respondents into two and then into three groups, clusters, viz., mind-sets, based upon the pattern of their 36 coefficients.
The regression analysis already provides us with the additive constant and the 36 coefficients for each of our 98 respondents. This within-subjects modeling is feasible because each respondent evaluate the precise combinations needed to create a linear regression equation relating the presence/absence of the 36 elements to the binary transformed response. The 36 estimated coefficients from the individual-level OLS (ordinary least squares) become the 36 variables on which the k-means clustering is done. The analysis created two and then three clusters, or mind-sets, creating them by assigning each of the 98 respondents to one of the three non-overlapping cluster.
Table 12 shows the results for the two and three mind-sets. To maintain consistency, the mind-sets were created using the estimated coefficients emerging from regression. Afterwards, the coefficients were once again transformed, so that coefficients of 8 or higher were transformed to 100, coefficients below 8 were transformed to 0. In short, the clustering into mind-sets produces new subgroups, not based on who they say they are or what they feel, but rather based on how they respond to the different statements. The power of clustering is that it puts together people with similar points of view, and in effect gets rid of the extraneous material which may seem relevant but is not. As a consequence, the mind-sets are a great deal more focused with almost no extraneous elements.
Table 12: Average transformed coefficients by two and three emergent mind-sets resulting from k-means clustering. Only strong performing averages of 50 or higher across the appropriate respondents appear in the table.
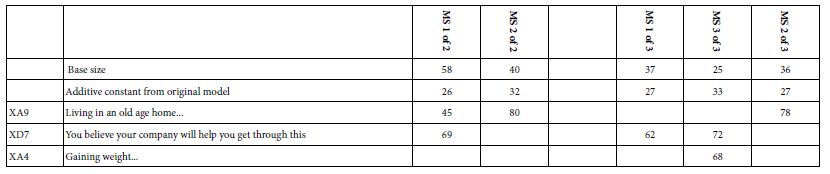
Based upon the strong performing elements we may offer these names to the mid-sets (MS)>
Two mind-sets:
MS 1 of 2 – Betrayal – Worry about being let down by one’s own company
MS 2 of 2 – Loss of freedom – Worry about living in an old age home
Three mind-sets:
MS 1 of 3 – Betrayal – Worry about being let down by one’s own company
MS 2 of 3 – Betrayal and Beauty – Worry about being let down by one’s own company AND gaining weight
MS 3 of 3 – Loss of freedom – Worry about living in an old age home
Discussion and Conclusion
The use of a combination of elements (vignettes) and the use of different combinations (‘permutations)’ scheme deserve their own notes because of the contribution that they make to science. In attitude and consumer research quite often the respondent is biased, either with awareness (viz., getting it right) or without awareness. Researchers have been aware of the biases involved when respondents feel that there is an expectation for them to be consistent, or for them to give the right answer, for whatever reason. Allowing the respondent to answer questions one by one gives the respondent a chance to reframe the criterion each time, to be appropriate to the question. The typical researcher may not even realize that the respondent is reframing, changing the criterion, given the right answer for some questions, and the true answer to others. One need only work with dietitians who, upon working with the client for the first and doing the ‘intake’ find the client to report being a model citizen with no ‘bad stuff’ in the house. That is the ‘correct’ answer, which should make the dietitian happy. Inspection of the house will reveal lots of foods which are never reported, overlooked. The use of vignettes prevents some of this changing criterion to always give the right answer. To once again quote the words of Harvard psychologist Wm James, the vignettes present a ‘blooming, buzzing confusion’ to the respondent. It is simply impossible with these 2-4 element vignettes to know what is the ‘right answer’. Most respondents end up guessing, or feel that they are guessing. Yet their data suggest just the opposite, viz., that they are consistent, but relaxed, maybe even bored.
The second topic is the permutation. Typically, science works by choosing a promising area, testing in that area, and reducing the error of measurement by making many measurements of the same area. The ingoing but unspoken assumption is that this area is the ‘correct’ area, such assumption rarely eally questioned in terms of its validity because the effort to replicate is too difficult, expensive, and of course discouraging. In the meanwhile, no matter how the area is discovered, usually by prior knowledge and good guesswork, the researcher ends up shoring up the measurement of perhaps a wrong area by reducing the error of measurement. The reduction, not so much by exploring other possible areas in the ‘space,’ but rather piling on more respondents to test the same vignettes. The goal is to get a better measurement, a more precise measurement, but of course with the scarcely acknowledged possibility that the whole enterprise is looking into the ‘wrong’ area. This is the hypothetico-deductive method research [21].
Mind Genomics lies outside the standard realm of hypothetico-deductive research. One can think of Mind Genomics as a mapping exercise, a cartography, to discover information about how we think. One could use the method for hypothesis, but the research strategy is simply to create ideas about a topic, mix them, get reactions and determine how the ideas drive the reaction. There may be theory, or simply a mapping exercise. Like an explorer, one can study areas in which one is an expert or conversely areas in which one is completely ignorant. The data are accretive, as more and more of the topic area is explored by study after study. The end result is a database of the mind, created in what ends up being an efficient inexpensive, possibly results-directed manner or possibly random exploration, all at a lower price. In other words, the world view of Mind Genomics is to increase knowledge, and create a small or a large database about a specific topic. The topic may be virtually anything to which a person can respond after reading a description, as long as an underlying experimental design can create alternatives to the basic idea.
The third topic is simple. What did we find? It’s about old age homes, ineffective plastic surgery, and financial ‘betrayal.’
Acknowledgment
The author acknowledges the original efforts to collect the data though It! Ventures LLC, and is especially grateful to the late Hollis Ashman for her efforts at putting together the study, and doing the preliminary analyses in 2003, when the data were first collected.
References
- Barrett AE, Robbins C (2008) The multiple sources of women’s aging anxiety and their relationship with psychological distress. Journal of Aging and Health 20: 32-65. [crossref]
- Ramírez L, Palacios-Espinosa X (2016) Stereotypes about old age, social support, aging anxiety and evaluations of one’s own health. Journal of Social Issues 72: 47-68.
- Richardson TM, Simning A, He H, Conwell Y (2011) Anxiety and its correlates among older adults accessing aging services. International Journal of Geriatric Psychiatry 26: 31-38. [crossref]
- Lynch SM (2000) Measurement and prediction of aging anxiety. Research on Aging 22: 533-558.
- Lasher KP, Faulkender PJ (1993) Measurement of aging anxiety: Development of the anxiety about aging scale. The International Journal of Aging and Human Development 37: 247-259. [crossref]
- Noh JH, Lim EJ (2014) Factors influencing Rural Elderly Women’ Health Promotion Behavior. Advanced Science and Technology Letters 61: 44-47.
- Mehta KM, Simonsick EM, Penninx BW, Schulz R, Rubin SM, et al. (2003) Prevalence and correlates of anxiety symptoms in well-functioning older adults: Findings from the health aging and body composition study. Journal of the American Geriatrics Society 51: 499-504.
- Stevens SS (1966) Personal communication to Howard Moskowitz
- Green PE, Krieger AM, Wind Y (2004) Thirty years of conjoint analysis: Reflections and prospects. In Marketing research and modeling: Progress and prospects, 117-139, Springer, Boston, MA.
- Anderson NH (2014) Contributions to Information Integration Theory. Volume 1. Cognition. Imprint Psychology Press.
- Mead R (1990) The design of experiments: statistical principles for practical applications. Cambridge University Press.
- Moskowitz HR (2012) ‘Mind genomics’: The experimental, inductive science of the ordinary, and its application to aspects of food and feeding. Physiology & behavior 107: 606-613. [crossref]
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2006) Founding a new science: Mind genomics. Journal of sensory studies 21: 266-307.
- Moskowitz HR, Wren J, Papajorgji P (2020) Mind Genomics and the Law. Lambert Academic Publishers, Germany.
- Gabay G, Moskowitz H, Onufrey S, Rappaport S (2017) Predictive modelling and mind-set segments underlying health plans. In Applying predictive analytics within the service sector, 135-156. IGI Global.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145.
- Rabino S, Moskowitz H, Katz R, Maier A, Paulus K, et al. (2007) Creating databases from cross-national comparisons of food mind-sets. Journal of Sensory Studies 22: 550-586.
- Moskowitz HR, Beckley J, Ashman H (2009) Beyond anxiety and political correctness’: How experimental design trumps’ gaming it’ and gets more deeply into the mind. Available at SSRN 1438648.
- Craven BD, Islam SM (2011) Ordinary least-squares regression. The SAGE Dictionary of Quantitative Management Research 224-228.
- Likas A, Vlassis N, Verbeek JJ (2003) The global k-means clustering algorithm. Pattern Recognition 36: 451-461.
- Kell DB, Oliver SG (2004) Here is the evidence, now what is the hypothesis? The complementary roles of inductive and hypothesis-driven science in the post-genomic era. Bioessays 26: 99-105.