Abstract
The study reported here deals with the creation of questions about what a doctor wants to hear when interacting with a patient, and the evaluation of that question to those questions. The questions, answers and respondents (survey takers) were all generated through artificial intelligence. The results revealed the possibility of AI support in all three areas, and revealed meaningful results when the study was run using the procedure of Mind Genomics. Systematic combinations of messages (elements) according to an experimental design revealed clearly different patterns of responses to the messages based upon who the response personas were designated to be. Three clearly different mind-sets emerged, groups of synthesized respondents whose pattern of coefficients were similar to each other within a mind-set, with the centroids of the mind-sets differing in a way which made intuitive sense.
Introduction
The introduction of artificial intelligence (AI) has created a level of interest perhaps unrivalled in the history of technology, but also spilling over into all areas of human endeavor as well as issues of philosophy [1]. As the use of AI has become easier, more widespread, various uses have emerged, almost beyond counting.
At the same time that technology and society has focused on AI, the author and colleagues have been working with a different, somewhat new way of fathering data about the world of the everyday. The science is called Mind Genomics. The notion is that everyday experience is worth studying for the way it allows us to understand people. Furthermore, rather than studying people by asking them about topics using questionnaires, or by talking directly to them as do qualitative researchers, an intermediate way is to present people with different descriptions, or vignettes, really combinations of phrases to paint a word picture, and then ask the people to rate the vignettes on a scale. The results generate a database of impressions of these vignettes, with the impressions able to be deconstructed into the driving power of each of the element or phrases. The respondent, or survey taker doing this task, cannot ‘game the system’ because the combinations change from person to person, based upon an underlying set of planned combinations, the so-called experimental design [2].
Up to now the test takers in these Mind Genomics studies have been real people, whether of school age or older. The extensive data which has emerged from these studies range from evaluation of descriptions of foods [3,4] and onto education [5] the law [6], social issues [7], and beyond. The Mind Genomics approach has proved fruitful in its ability to allow different ideas to emerge from these studies, as well as uncover new to the world groups of people who think of the world differently. These groups are called mind-sets.
The Mind Genomics Platform and AI as a Generator of Ideas
In the Mind Genomics platform AI has already been used to create questions, and from those questions create sets of answers. It is these ‘answer’s or elements, that Mind Genomics combines into small, easy to read combinations called vignettes. These vignettes, comprise a maximum of four elements and a minimum of two elements, created by an underlying experimental design The vignettes are created in a rigorous fashion, so that:
- Each vignette has at most one element or answer from a question, never two or more answers from a question, but occasionally no answer from a question. It is this property of incompleteness that will allow the researcher to use statistical (regression analysis) to show how the elements or answers ‘drive’ ratings
- Each vignette is different from every other vignette. The vignettes a systematically changed by a permutation program [8].
- Each respondent evaluates a specific set of 24 vignettes, with each element appearing four times. Each set of 24 vignettes is reserved for a specific respondent
During the early part of 2023 the Mind Genomics platform was enhanced by AI, first to provide questions, and then to provide answer to the questions. The enhancement used ChatGPT3.5 [9,10]. The researcher was presented with a screen which requested four questions, and afterwards four screens, each of which requested four separate answers to each question that the research would provide. Though one might not think that the request to provide four questions is particularly daunting, the reality is that it is quite daunting. As a consequence, many nascent uses of Mind Genomics simply abandoned the task. The reality began to become apparent, viz., that people may be good at answering questions, but they are not good at formulating a story in terms of a set of questions to ask which will get at the answer(s). Some may call this a deficit in so-called critical thinking, but for the purposes of this paper it is simply a stumbling block in usability of Mind Genomics.
The creation of a series of built in prompts, provided to the researcher in a non-threatening, rather easy way, ended up producing Idea Coach. We will show the use of Idea Coach in this paper, as part of the specific treatment of the topic, ‘what doctors want in patients’,. We will use Idea Coach to show how the questions are generated, and how data from synthetic respondents are created and analyzed. This paper shows the method, and the nature of the answers that one might get.
The underlying motivation is to see what might emerge from these initial trials with AI acting as a synthetic respondent. The important issue is do the data ‘make sense’ to the reader. The issue about whether the data matches external results must be addressed later, when the approach of creating synthetic respondent has been well worked out. This study is only the first step I that process, not the external validation step. To summarize, the validity considered here is the simplest one of all, namely ‘face validity.’ Do the data generated by AI ‘make sense’
Running the Mind Genomics AI Experiment from Start to Finish
The Mind Genomics process is templated from start to finish. The study presented here deals with what a doctor wants from a patient. The synthesized respondents are going to be medical professionals. The actual study can be found in the website. Much of the set-up of the study has been taken from the senior author’s previous Mind Genomics website, www.BimiLeap.com. The synthetic respondents are created within a new website, Socrates as a Service ™, which uses many of the feature of the Mind Genomics platform, but adds the ability to synthesize respondents simply by describing the way they think, what they do, etc.
Step 1
Give the study a name, select a language for the prompts, and accept the terms for privacy.
Step 2: Create Four Questions Which ‘Tell a Story’
As noted above, it is at this point in the process that many researchers are stymied, and where the researcher can use AI to help formulate questions. The instructions to ‘tell a story’ are simply meant as a help to the research. The underlying idea is that the questions should deal with different aspects of the topic.
Figure 1 shows the screen requesting the four questions, and the next screen invoked when the request is made to use AI in the form of Idea Coach. The ‘box’ in Panel B of Figure 1 is filled out by the researcher. Typically, the request should comprise an introduction (e.g., explain in detail), the issue (the specific request), and then prompts asking the Idea Coach to produce a question of no more than 15 words, and a question understandable to a person of younger age. For this project the age was ‘12’ years, but in other projects the age has been higher (e.g., around 21 years old). Finally, Panel C shows the return of a subset of the 15 questions produced by AI, with the remaining questions requiring the researcher to scroll down. Panel D shows the final set of questions, edited, and in preparation for the next step in AI empower Idea Coach.

Figure 1: Four questions and Idea Coach
The researcher can repeat the request to Idea Coach as many times as desired, with each return by Idea Coach comprising 15 questions, some new, some repeats. At the end of the process, the researcher will have selected four questions, and inserted them into the template, and, if necessary, editing these questions to ensure the proper format of answers to be produced by Idea Coach in the next step. Table 1 presents one set of questions, along with an AI based ‘summarization’ of the questions as well as further extension of the questions into new opportunities. Note that Table 1 is created for every set of 15 questions developed through Idea Coach, as well as for every set of 15 answers to a question produced by Idea Coach (see below). Excel booklet from which Table 1 is extracted is called the project ‘Idea Book.’ Each separate iteration, either to generate questions or answers, generates 15 results. The full Idea Book is available after the project passes the stage of creating questions and answers.
Table 1: The Idea Coach prompt, the first set of 15 questions, and the AI elaboration of those 15



Step 3: Create the Answers
Once the questions have been created and edited (polished to increase the quality of the AI output), it is time to create answers. The same process occurs, with the researcher presented Idea Coach with the edited question, and then 15 answers returned. Again, the researcher has the task of selecting up to four answers and re-running the Idea Coach again for new answers to address the now polished/edited question. During the process it is always possible to revise the question. Figure 2 shows the different steps for the creation of answers. Once again, the Idea Coach can be invoked as many times as desired. Table 2 shows an example of the 15 answers to the first question.
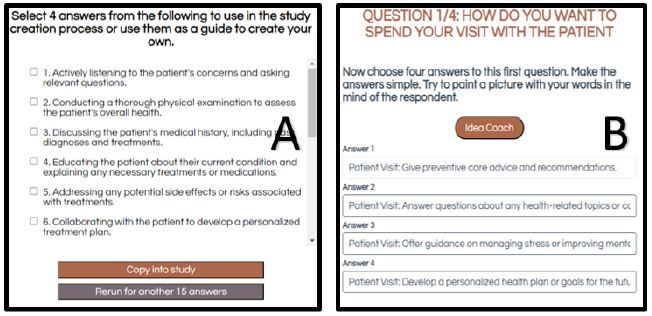
Figure 2: Screenshots showing the process for creating the four answers to a question. Panel A shows the partial output from Idea Coach. Panel 2 shows the four answers actually selected, and then slightly edited for use in the study.
Table 2: First set of answers to question #1



Step 4: Select the Final Set of Questions and Answers
Table 3 shows this selection. All text comes from Idea Coach, but with edits at each step of the way to make sure that the elements can be understood in a meaningful way by people, and presumably in that case by AI as well.
Table 3: The final set of questions and answers
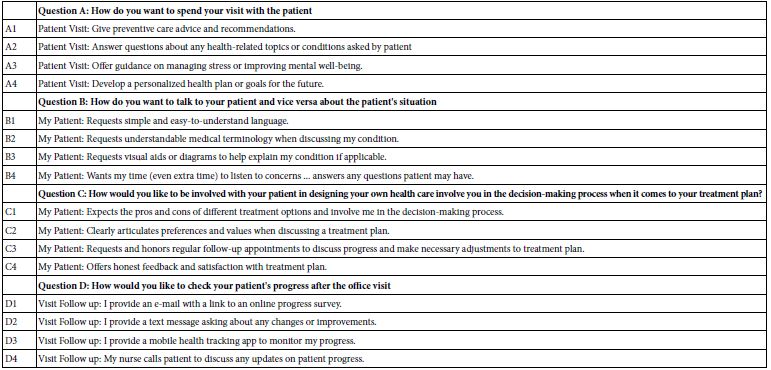
Step 5: Create the Self-profiling Questions
The personas of the synthetic respondents are created from combinations of the self-profiling questions. The underlying process is systematically one randomly selected answer from each question to create the persona. The personas were created by “Socrates as a Service ™,” the next generation of program in the Mind Genomics platform. Figure 3 shows an example of a classification question, with Panel A having no information, and Panel B showing the same template, but filled out to define the respondent. Note that the self-profiling classification allows the researcher to specify anything desired about the to-be-synthesized respondent. Table 4 shows the actual set of self-profiling questions.
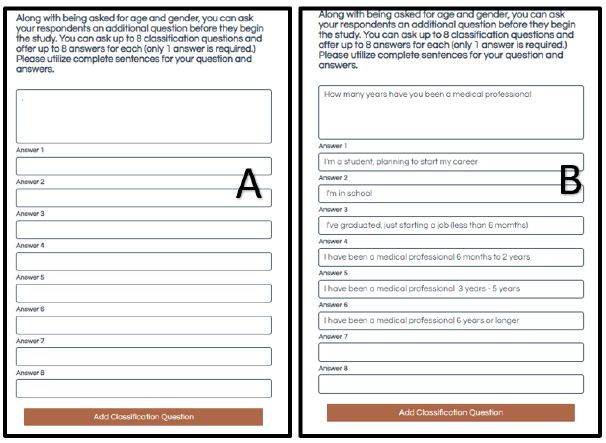
Figure 3: Example of one question filled out for the self-profiling classification. Panel A shows the empty placeholder. Panel B shows the first self-profiling classification as filled out by the research. There are up to eight of these questions, each with a possible 2-8 alternative answers.
Table 4: The set of self-profiling questions and answers. The personas were created from combinations of the answers

Step 5: Create an Open-ended Question
As part of the Mind Genomics effort, the platform allows the respondent to complete two open ended questions, one before doing the evaluation of the vignettes the other after doing the evaluation of the vignette. Figure 4 shows the request for the open-ended question to be done after the synthetic respondent has ‘evaluated’ the 24 vignettes comprising combinations of elements or ‘messages’.. The normal human respondent generally has a lackadaisical attitude towards filling out these open-ended questions, unless the topic is deeply emotional, such as breast cancer. The inclusion of the open-ended question was done to explore what might emerge from AI. Those results are discussed below.
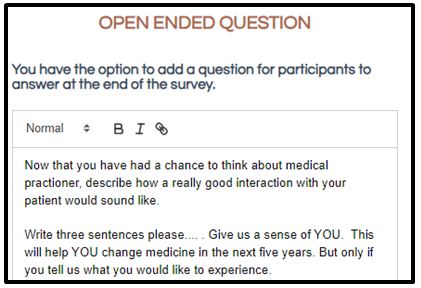
Figure 4: Templated screen for the open-ended question, with the question filled out
Step 6: Create the Respondent Orientation and Rating Scale
Figure 5, Panel A shows the very short respondent orientation. The Mind Genomics process has been set up with the guiding vision that the information needed to rate the vignette would be presented in the combinations of the elements or test messages, as well as influenced by who the respondent ‘IS’ and how the respondent ‘THINKS’. Consequently, the very short introduction simply instructs the respondent to read the vignette. Figure 5, Panel B shows the two-sided scale as presented to the researcher during the set-up. Table 5 shows the actual text of the scale, emphasizing the two sides or dimensions embedded in each scale point.
Figure 5: The respondent orientation (Panel 5A), and the rating scale (Panel 5B)
Table 5: The text of the 5-point binary scale used by the synthetic respondent to rate the vignette

Step 7: Select the Source of Respondents
The new Mind Genomics platform, now named SaaS (Socrates as a Service™) has expanded the options to include synthetic respondents using AI. Figure 6 shows the choices. The newest choice is at the bottom, ‘I want to use simulated respondents.’ By making the synthetic respondent simply become another choice, the new Mind Genomics platform has created the opportunity for SaaS to become a simple, affordable teaching tool. The researcher can set up the study in the manner previously done, but ‘explore’ the response using AI, in order to learn. Research now becomes a tool to learn both through the combination of Idea Coach + Question Book at the start of the project, and through iterative explorations using AI in the middle or end of the project.

Figure 6: Screen shot showing how the researcher can source ‘respondents’.
Step 8: Define Respondent
For studies run with people the first step in the actual evaluation consists of a very short ‘hello’ followed by the pull-down menu for the self-profiling classification. Figure 7 shows this pull-down menu, showing the three answers for the question ‘How do you feel about the insurance companies and the medical health holding companies?’ Human respondents find this way of answering the self-profiling questions to be easy and not intimidating. When it comes to the synthetic respondents, there is no need for Step 8. The program automatically creates the personas, the synthesized combinations of the different answers, with each question contributing exactly one answer to the persona being developed.

Figure 7: The pull-down menu for self-profiling classification, used for human respondents, but not for synthetic respondents.
Step 9: Create Test Vignettes by Experimental Design
A hallmark of Mind Genomics is the creation of combinations of messages, these creations being called vignettes. Rather than instructing a respondent to evaluate each of the 16 elements, the Mind Genomics strategy is to combine these elements into small, easy-to-read combinations. There is no effort to link the elements together, an effort which would backfire because the ensuing paragraph of linked elements would contain too much connective material, verbal plaque, as it were.
The actual vignettes are created by an underlying experiment design which ensures that the 16 elements appear equally often (5x in a set of 24 vignettes). Furthermore, no vignette ever has more than one element or answer from a question, but many vignettes have only two or three answers, with other questions failing to contribute to the vignette. Finally, each respondent evaluates a mathematically equivalent set of vignettes by the permutation process, but the actual combinations evaluated by the individual respondents differ from one respondent to another [8].
The foregoing strategy lies at the basis of Mind Genomics. It becomes virtually impossible to game the system because the combinations are overwhelming. The real focus is on the performance of the individual elements. The vignettes are only the way to get the elements in front of the respondent in a way which resembles the seemingly discordant nature of everyday experience. Quite often exit interviews with respondents as well as discussions with professionals end up with the ‘complaint’ that it was simply impossible to figure out the; right answer’, an effect which mildly irritates people, but all too often infuriates academics.
Step 10: Present the 24 Vignettes for a Respondent to the AI and Obtain a Rating on the Five-point Scale
The AI system proceeds by creating a prompt for each vignette. The first part of the prompt defines WHO the respondent is. The respondent is some randomized combinations of answers from the six self-profiling classifications, with each answer appearing approximately equally often across the 801 respondents. This first part of Step 10 will produce a constant persona across the 24 vignettes.
The second part of Step 10 presents the rating question and scale to the AI. This second part of step 10 will produce a constant rating question and set of answers across the 24 vignettes for the synthesized persona.
The third part of Step 10 presents the AI with the vignette. The AI is instructed to assume the persona, to read the scale, and then to rate the vignette on the scale by choosing one of the five answers.
The actual study is now run, the total time for 801 respondents lasting 15-30 minutes. The time may be substantially shorter, but there is extensive back and forth with the AI modules and provider.
Step 11: Uncover the Distribution of the Five-point Scale Ratings across the Set of All Self-profiling Scales
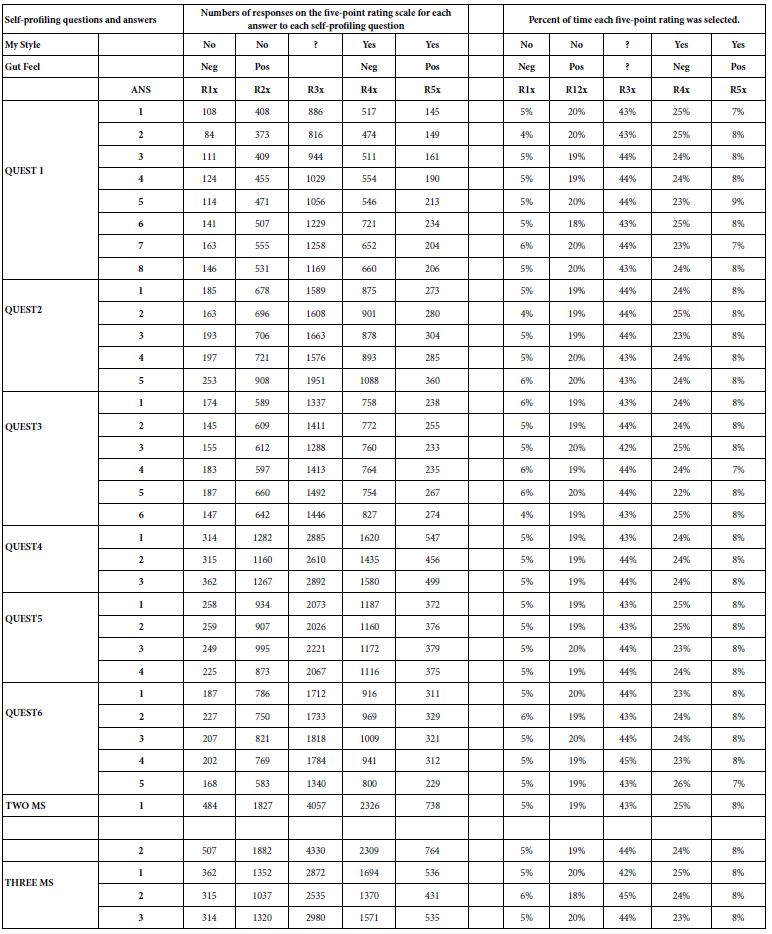
At the end of the process, we can look at the distribution of the ratings across the groups synthetic respondents, these groups defined by the how the synthetic respondent ‘identifies itself’. Table 6 shows a remarkable consistency across the different self-profiling groups. If we were to stop here, we would conclude that there is no discernible difference across the different self-profiling groups, and thus the effort to create synthetic respondents at this stage of AI development has failed. We would, however, be quite wrong in that conclusion, as the further tables will show.
Table 6: Distribution of the five rating scale points for each selection in the self-profiling classificaiton questionnaire
Step 12: Transform the Ratings into Binary Variables
A now-standard practice in Mind Genomics is to transform the rating scale. The rating scale created here provides two dimensions. Our focus here is on simulating the positive response ‘My style’, corresponding to the combination or union of ratings 5 and 4, respectively. The transformation makes ratings of 5 or 4 equal to 100, and in turn ratings of 1,2 or 3 equal to 0. To each newly transformed variable, now called R54x, is added a vanishingly small number (<10-4). This prophylactic step ensures some minimum level of variation in R54x, which will become a dependent variable in OLS (ordinary least-squares regression), discussed in Step 11. For other analyses, the system or the researcher can create different binary variables, such as R52X, a positive gut feel.
Step 13: Relate the Presence/Absence of the 16 Elements to the Newly Developed Binary Variables
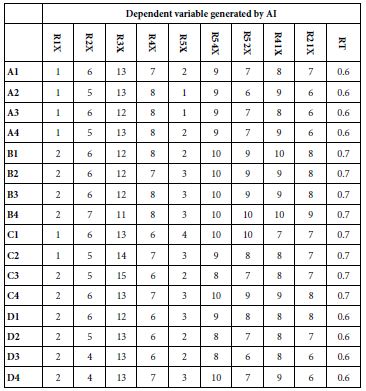
Table 7 shows the coefficients for the equations relating the presence/absence of each element to the following dependent variables, which have been coded 0 or 100.
R1x-Rating of 1 coded 100, ratings of 2, 3, 4 or 5 coded 0
R2x-Rating of 2 coded 100, ratings of 1, 3, 4 or 5 coded 0
R3x-Rating of 3 coded 100, ratings of 1, 2, 4 or 5 coded 0
R4x-Rating of 4 coded 100, ratings of 1, 2, 3, or 5 coded 0
R5x-Rating of 5 coded 100, rating of 1, 2, 3 or 4 coded 0
R54x-Ratings of 5 or 4 coded 100, ratings of 1, 2 or 3 coded 0
R52x-Ratings of 5 or 2 coded 100, ratings of 4, 3 or 1 coded 0
R21z-Ratings of 2 or 1 coded 100, ratings of 5, 4 or 3 coded 0
R41x-Ratings of 4 or 1 coded 100, ratings of 5, 3, or 2 coded 0
RT-Response time-with human being defined as the number of seconds elapsing between the presentation of the vignette and the response. Not definable for AI, although measurable.
It is clear from Table 7 that the coefficients within a column are quite similar to each other. There are some variations, but remarkably little. Furthermore, the answers seem to make intuitive sense. It does not pay to analyze each set of numbers, however, because within a column the numbers are simply too close. Finally, there is a response time emerging, although it is not clear what that means. The RT, response time, is measured in terms of seconds between the presentation of the vignette and the respondent’s rating. All response times are low, around 0.6, but do not know what is occurring.
Table 7: Coefficients for the Total Panel (801 respondents x 24 vignettes each)
Step 14: Show the Linkage between Elements and R54 for Different Levels of Each Persona Variable
A slightly more nuanced picture emerges when the total panel results are broken up into separate persona ‘levels.’ Table 4 shows the six different self-profiling questions, and the answers to each. Tables 8A-8F show the strong performing elements for each persona ‘level’. Each table, Tables 8A-Table 8F, corresponds to one of the six self-profiling questions. The columns correspond to the answers. The coefficients are strong performing values for element, with ‘strong performing’ operationally defined as a coefficient of +14 or higher.
Table 8A: Strong performing elements for persona Q1: How many years have you been a medical professional

Table 8B: Strong performing elements for persona Q2: What makes you dislike a patient?
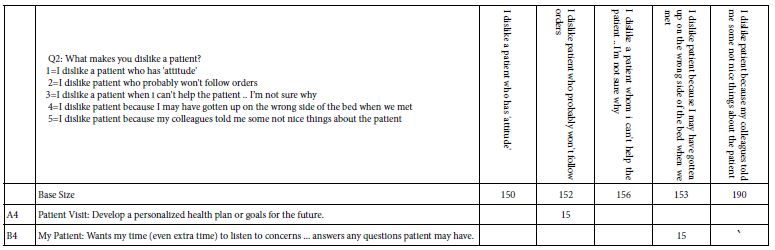
Table 8C: Strong performing elements for persona Q3: How long is a reasonable time with a patient?
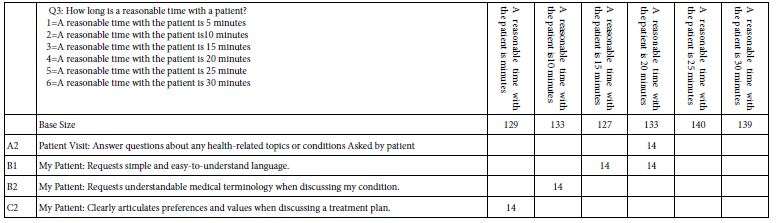
Table 8D: Strong performing elements for persona Q4: What is your feeing about telehealth. No strong performing elements emerged

Table 8E: Strong performing elements for persona Q5: How do you feel about the insurance companies and the medical holding companies
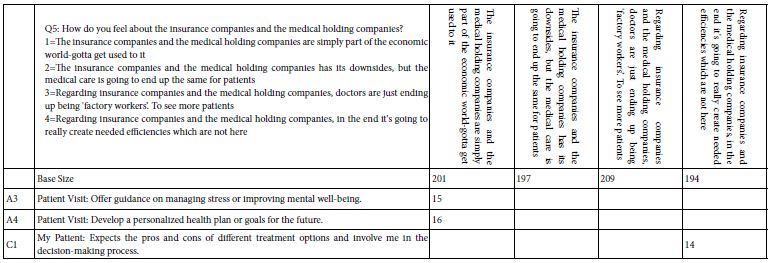
Table 8F: Strong performing elements for persona Q6: How do you feel when you start the day
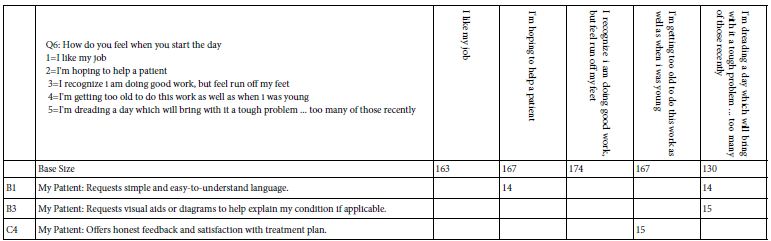
The development of Tables 8A-8F is straightforward, consisting of the isolation of the vignettes showing the specified persona option, and then running the OLS (ordinary least-squares) regression for all the cases having the appropriate self-profiling answer. Each table has a base size, referring to the number of respondents in the simulated set of 801 who are assigned the particular answer. Thus, in Table 8A, for example, 86 respondents were assigned to the answer 1 of question 1, namely: How many years have you been a medical professional, with the answer 1, ‘I’m a student, planning to start my career.’
The OLS regression [9] returns return with coefficients for each cell, based upon the rating: R54 = k1A1 k2A2… k16A16. The result is a wall of numbers. Table 7 suggests that the highest coefficient for R54 for the total panel is 10. Therefore, Tables 8A-AF shows only those coefficients of 14 or higher. Furthermore, Tables 8A-8F shows only those elements which have at least one coefficient of 14 in a row. This stringent criterion substantially reduces the number of data points that need to be considered.
Our initial results here suggest that there are coefficients higher than others, although not many of them. Nor is the underlying story particularly clear. Finally, the highest coefficient is 17, hardly as strong as the results obtained with human beings, but yet suggesting that AI can differentiate among elements based upon the persona created.
Step 15: Create Mind-sets from Synthesized Respondent Data
Our final analysis for this study considers the existence of mind-sets, different ways of looking at the data. When Mind Genomics is executed with human respondents there is an almost universal emergence of mind-sets, with perhaps the exception of ‘murder [6].
When Mind Genomics data are clustered together on the basis of the coefficients, generally the meaning of the mind-sets becomes exceptionally clear, even though the process of creating mind-sets does not use any interpretation of the data. Rather, the process to create mind-sets is clustering, with the process easy to do with conventional data, and now just as easy to do with synthesized data. The process uses k-means clusters [11,12], and a measure of ‘distance’ between two objects (e.g., between two synthesized persons) defined as (1-Pearson R). The Pearson R, the correlation coefficient, shows the degree to which two sets of numbers co-vary. When the 16 coefficients of the two synthesized people co-vary perfectly, they are considered to be in the same mind-set, the Pearson R is 1.00, and the distance is 0. When they 16 coefficients vary perfectly inversely with each other, they are considered to be in different mind-sets, the Pearson R is-1, and the distance is 2.0.
Moving now to the results from the k-means clustering at the top of Table 9, we see coefficients around 9-11 for the total panel, coefficients 0-22 for two clusters or mindsets but not many high coefficients of 21+, and three mind-sets emerging from three clusters, two of the mind-sets being strong, with a number of coefficients 21 or higher. The value 21 has been chosen for simplicity, based upon observations over a two-year period working with human respondents in different topics.
Table 9: Coefficients for the total panel, and for the two and three mind-set groupings. Strong performing coefficients (21 or higher) are shown in shaded cells. Coefficients with negative or 0 values are not shown.
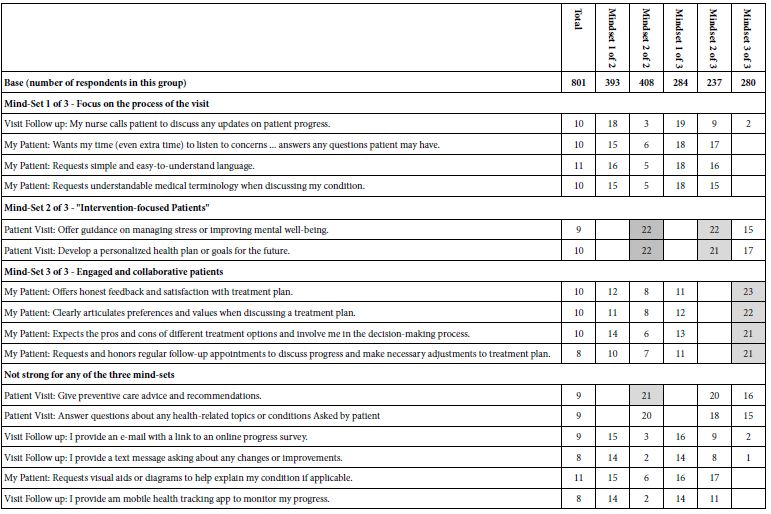
When we apply the criterion of 21 or higher we end up with three mind-sets, two of which show the requisite value of coefficients 21 or higher (Mind-Sets 2 of 3 and 3 of 3, respectively).
Mind-Set 1 of 3-Focus on the process of the visit (but no truly strong elements)
Mind-Set 2 of 3-“Intervention-focused Patients”
Mind-Set 3 of 3-Engaged and collaborative patients.
The three mind-sets can be interpreted more deeply through AI, using the same set of prompts as we used to summarize the ideas on each page of questions (see Table 1) and each page of answers (see Table 2). Table 10 shows the summarization for Mind-Sets 2 of 3 and 3 of 3, respectively. The summarization is based on the commonalities of all elements with coefficients of 21 or higher. Mind-Set 1 of 3 fails to meet that minimum level, and therefore the Idea Coach Summarizer was not applied.
Table 10: Summarization by Idea Coach (AI) of the strong performing elements for Mind-Sets 2 of 3 and 3 of 3. The names of the mind-sets were also suggested by AI.



Step 16: How well does the AI Perform When Synthesizing Respondents?
A continuing effort in Mind Genomics is the attempt to increase critical thinking. How does one measure critical thinking, however, and more importantly, how can one set up criteria to assess the development of critical thinking. One way to assess such thinking is by looking at the set of positive coefficients for the total panel, for the two mind-set solutions, and for the three mind-set solutions. The objective is to create elements with high coefficients, but also elements which are very high in one mind-set, but low in the in other mind-sets. Thus, higher may not be better because the elements do not score differently across the mind-sets. Some preliminary simulation suggest that strong performance occurs with an IDT value of 68-72. The IDT is the Index of Divergent Thought, shown in Table 11. The table shows the relevant parameters to compute the IDT.
Table 11: Computation specifics of the IDT, Index of Divergent Thought. A value between 68 and 72 may be optimal.
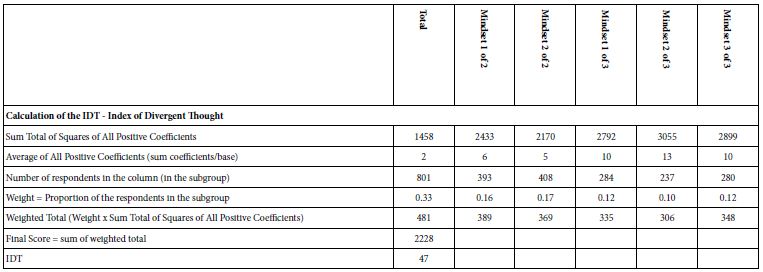
The results from this study and from several other parallel studies of the same type (doctor-patient) suggest that the IDT values for synthesized data are lower than what are obtained from people. That is, the synthetic respondents do generate easy-to-interpret mind-sets, but the inner structure is not as strong, based upon the IDT of 47 rather than the IDT’s of 70 often observed in the simplest of these Mind Genomics studies. In other words, synthetic respondents give answers, but the ‘deep structure’ is somehow not quite ‘human’.
Discussion and Conclusions
The appetite for AI as synthetic ‘people’ is increasing daily. Whether the topic be social issues [1], health [13], or politics [14] there appears to be a one-way push towards more sophistication in the application. We no longer question the utility or even the ‘validity’ of synthetic people. Rather, the focus is on the improvement of the application. Towards that goal of improvement, the study reported here suggests a new application, namely the use of AI to explore medical issues involving stated specifics of the doctor-patient interaction. The potential for Mind Genomics is this area is as yet unknown, but one might imagine doctors using Mind Genomics with synthetic patients to learn how to interact with patients. It may well be that the years of experience of a doctor in the so-called ‘bedside manner’ might be quickly learned with AI. Only time will tell, but fortunately the use of Socrates as a Service ™ may well shorten that time for learning.
References
- Bryson JJ, Diamantis ME, Grant TD (2017) Of, for, and by the people: the legal lacuna of synthetic persons. Artificial Intelligence and Law 273-291.
- Kirk RE (2009) Experimental design. Sage handbook of quantitative methods in psychology, pp. 23-45.
- Moskowitz HR (2012) ‘Mind genomics’: The experimental, inductive science of the ordinary, and its application to aspects of food and feeding. Physiology & Behavior 107: 606-613. [crossref]
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2006) Founding a new science: Mind genomics. Journal of Sensory Studies 21: 266-307.
- Moskowitz H, Sciacca A, Lester A (2018) I’d like to teach the world to think: Mind Genomics, big mind, and encouraging youth. In: Harnessing Human Capital Analytics for Competitive Advantage, IGI Global, pp. 55-90.
- Moskowitz HR, Wren J, Papajorgji P (2020) Mind Genomics and the Law. LAP LAMBERT Academic Publishing.
- Moskowitz H, Kover A, Papajorgji P(eds.) (2022) Applying Mind Genomics to Social Sciences. IGI Global.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145.
- Abdullah M, Madain A, Jararweh Y (2022) ChatGPT: Fundamentals, applications and social impacts. In 2022 Ninth International Conference on Social Networks Analysis, Management and Security (SNAMS) (1-8) IEEE. November.
- Spitale G, Biller-Andorno N, Germani F (2023) AI model GPT-3 (dis) informs us better than humans. arXiv preprint arXiv: 2301.11924. sci adv. [crossref]
- Burton AL (2021) OLS (Linear) regression. The encyclopedia of research methods in criminology and Criminal Justice 2: 509-514.
- Likas A, Vlassis N, Verbeek JJ (2003) The global k-means clustering algorithm. Pattern Recognition 36: 451-461.
- Loong B, Zaslavsky AM, He Y, Harrington DP (2013) Disclosure control using partially synthetic data for large‐scale health surveys, with applications to CanCORS. Statistics in Medicine 32: 4139-4161. [crossref]
- Sanders NE, Ulinich A, Schneier B (2023) Demonstrations of the potential of AI-based political issue polling. arXiv preprint arXiv: 2307.04781.