Abstract
The paper introduces a process to accelerate the mechanics of science and insight. The process comprises two parts, both involving artificial intelligence embedded in Idea Coach, part of the Mind Genomics platform.. The first part of the process identifies a topic (policy for the citrus industry), and then uses Mind Genomics to understand the three emergent mind-sets of real people who evaluate the topic, along with the strongest performing ideas for each mind-set. Once the three mind-sets are determined, the second part of the process introduces the three mind-sets and the strongest performing elements to AI in a separate ‘experiment’, instructing Idea Coach to answer a series of questions from the point of view of each of the three mind-sets. The acceleration can be done in a short period of time, at low cost, with the ability to generate new insight about current data. The paper closes by referencing the issues of critical thinking and the actual meaning of ‘new knowledge’ emerging from a world of accelerated mechanics of science and insight.
Introduction
Traditionally, policy has been made by experts, often consultants to the government, these consultants being experts in the specific topic, in the art and science of communication, or both. The daily press is filled with stories about these experts, for example the so-called ‘Beltway Bandits’ surrounding Washington D.C [1]. It is the job of these experts to help the government decide general policy and specific implementation. The knowledge of these experts helps to identify issues of importance to the government groups to whom they consult. The ability of these expert to communicates helps to assure that the policy issues on which they work will be presented to the public in the most felicitous and convincing manner. At the same time that these experts are using the expertise of a lifetime to guide policy maker, there is the parallel world of the Internet, source of much information, and the emerging world of AI, artificial intelligence, with the promise of supplanting or perhaps more gently, the promise of augmenting, the capabilities and contributions of these expert. Both the internet and AI have been roundly attacked for the threat that they pose [2]. It should not come as a surprise that the world of the Internet has been accused of being replete with false information, which it no doubt is [3]. AI receives equally brutal attacks, such as producing false information [4] an accusation at once correct and capable of making the user believe that AI is simply not worth considering because of the occasional error [5]. The importance of public policy is already accepted, virtually universally. The issue is not the general intent of a particular topic, but the specifics. What should the policy emphasize? Who should be the target beneficiaries of the policy? What should be done, operationally, to achieve the policy? How can the policy be implemented? And finally, in this short list, what are the KPI’s, the key performance indicators by which a numbers-hungry administration can discover whether the policy is being adopted, and whether that adoption is leading to desire goals.
Theory and Pragmatics: The origin of this Paper
This paper was stimulated by the invitation of HRM to attend a conference on the Citrus Industry in Florida, in 2023. The objective of the conference was to bring together various government, business and academic interests to discuss opportunities in the citrus industry, specifically for the state of Florida in the United States, but more generally as well. Industry-center conferences of this type welcome innovations from science, often with an eye on rapid application. The specific invitation was to share with the business, academic and government audiences new approaches which promised better business performance. The focus of the conference was oriented towards business and towards government. As a consequence, the presentation to the conference was tailored to show how Mind Genomics as a science could produce interesting data about the response to statements about policy involving the business of citrus. As is seen below, the material focused on different aspects of the citrus industry, from the point of view of government and business, rather than from the point of view of the individual citrus product [6-9].
The Basic Research Tool: Mind Genomics
At the time of invitation the scope of the presentation was to share with the audience HOW to do a Mind Genomics study, from start to finish. The focus was on practical steps, rather than theory, and statistics. As such the presentation was to be geared to pragmatics, about HOW to do the research, WHAT to expect, and how to USE the results. The actual work ended up being two projects, the first project to get some representative data using a combination of research methods and AI, AI to generate the ideas and then research to explore the ideas with people. The second part, done recently, almost five months after the conference, expanded the use of AI to further analyze the empirical results, opening up new horizons for application.
Project #1: Understanding the Mind of the Ordinary Person Faced with Messages about Citrus Policy
The objective of standard Mind Genomics studies is to understand how people make decisions about the issues of daily life. If one were to summarize the goals of this first project, the following sentence would do the best job, and ended up being the sentence which guided the efforts. The sentence reads: Help me understand how to bring together consumers, the food trade, and the farmer who raises citrus products, so we can grow the citrus industry for the next decade. Make the questions short and simple, with ideas such as ‘how’ do we do things. The foregoing is a ‘broad stroke’ effort to under what to do in the world of the everyday. The problem is general, there are no hypotheses to test, and the results are to be in the form of suggestions. There is no effort to claim that the results tell us how people really feel about citrus, or what they want to do when the come into contact with the world of citrus as business, as commerce, as a regulated piece of government, viz., the agriculture industry. In simple terms, the sentence in bold is a standard request that is made in industry all the time, but rarely treated as a topic to be explored in a disciplined manner. Mind Genomics works by creating a set of elements, messages about a topic, and mixing/matching these elements to create small vignettes, combinations comprising a minimum of two messages and a maximum of four messages. The messages are created according to an underlying structure called an experimental design. The respondent, usually sitting at a remote computer, logs into the study, reads a very short introduction to the study, and then evaluates a set of 24 vignettes, one vignette at a time. The entire process takes less than 3-4 minutes and proceeds quickly when the respondents are members of an on-line panel and are compensated for their participation by the panel company. The Mind Genomics process allows the user to understand what is important to people, and at the same time prevents the person from ‘gaming’ the study to give the correct answer. In most studies, the typical participant is uninterested in the topic. The assiduous researcher may instruct the participant to pay attention, and to give honest answers, but the reality is that people tend to be interested in what they are doing, not in what the researcher wants to investigate. As a consequence, their answers are filled with a variety of biases, ranging from different levels of interest and involvement to distractions by other thoughts. The Mind Genomics process works within these constraints by assuming that the respondent is simply a passive observer, similar to a person driving through their neighborhood, almost in an automatic fashion. The person takes in the information about the road, traffic, and so forth, but does not pay much attention. At the end, the driver gets to where they are going, but can barely remember what they did when asked to recall the steps. This seems to be the typical course of events. The systematic combinations mirror these different ‘choice points.’ The assumption is that the respondent simply looks at the combination, and ‘guesses’, or at least judges with little real interest. Yet, the systematic variation of the elements in the vignettes ends up quickly revealing what elements are important, despite the often heard complain that ‘I was unable to see the pattern, so I just guess.’
The reasons for the success of Mind Genomics are in the design and the execution [10-12].
- The elements are created with the mind-set of a bookkeeper. The standard Mind Genomics study comprises four questions (or categories), each question generating four answers (also called element). The questions and answers can be developed by professionals, by amateurs, or by AI. This paper will show how AI can generate very powerful, insight questions and answers, given a little human guidance by the user.
- The user is required to fill in a templated form, asking for the questions (see Figure 1, Panel A). When the user needs help the AI function (Idea Coach) can recommend questions once Idea Coach is given a sense of the nature of the topic. Figure 1, Panel B shows the request to Idea Coach in the form of a paragraph, colloquially called a ‘squib.’ The squib gives the AI a background, and what is desired. The squib need not follow a specific format, as long as it is clear. The Idea Coach returns with sets of suggested questions. The first part of the suggest questions appears in Figure 1, Panel C, showing six of the 15 questions returned by the AI-powered Idea Coach. The user need only scroll through to see the other suggestions. The user can select a question, edit it, and then move on. The user can run many iterations to create different sets of questions and can either edit the squib or edit the question, or both. At the end of the process, the user will have created the four questions, as shown in Figure 1, Panel D. Table 1 shows a set of questions produced by the Idea Coach, in response to the squib.
- The user follows the same approach in order to create the answers. This time, however, the squib does not need to be typed in by the user. Rather, the question selected by the user, and after editing, becomes the squib for Idea Coach to use. For this project, Figure 1, Panel D shows the four squibs, one for each question. Idea Coach once again returns with 15 answers (elements) for each squib. Once again the Idea Coach can be used, so that the Idea Coach becomes a tool to help critical thinking, providing sequential sets of 15 answers (elements). From one iteration to another the 15 answers provided by Idea Coach differ for the most part, but with a few repeats Over 10 or so iterations it’s likely that most of the answers will have been presented.
- Once the user has selected the questions, and then selected four answers for each question, the process continues with the creation of a self-profiling questionnaire. That questionnaire allows the user to find out how the respondent thinks about different topics directly or tangentially involved with the project. The self-profiling questionnaire has a built-in pair questions to record the respondent’s age (directly provided), and self-described gender. For all questions except that of age, the respondent is instructed to select the correct answer to the question, the question presented on the screen, the answers presented in a ‘pull-down’ menu which appears when the corresponding question is selected for answering.
- The next step in the process requires the user to create a rating scale (Figure 2, Panel A). The rating scale chosen has five points as show below. Note that the scale comprises two parts. The first part is evaluative viz., how does the respondent feel (hits a nerve vs hot air). The second part is descriptive (sounds real or does not sound real). This two-sided scale enables the user to measure both the emotions (key dependent variable for analysis), as well as cognitions. For this study, the focus will be on the percent of ratings that are either 5 or 4 (hitting a nerve). Note that all five scale points are labelled. Common practice in Mind Genomics studies has been to label all the scales for the simple reason that most users of Mind Genomics results really are not focused on the actual numbers, but on the meaning of the numbers.
Here’s a blurb you just read this morning on the web when you were reading stuff.. What do you think
1=It’s just hot air … and does not sound real
2=It’s just hot air … but sounds real
3=I really have no feeling
4=It’s hitting a nerve… but does not sound real
5=It’s hitting a nerve .. and sounds real - The user next create a short introduction to the study, to orient the respondent (Figure 2, Panel B). Good practice dictates that wherever possible the user should provide as little information about the topic as possible. The reason is simple. It will be from the test stimuli, the elements in the 4×4 collection, or more specifically the combinations of those elements into vignette, that the respondent will make the evaluation and assign the judgment. The purpose of the orientation is to make the respondent comfortable and give general direction. The exceptions to this dictum come from situations, such the law, where knowledge of other factors outside of the material being presented can be relevant. Outside information is not relevant here.
- The last step of the setup consists of ‘sourcing’ the respondents (Figure 2, Panel C). Respondents can be sourced from standing panels of pre-screened individuals, or from people one invites, etc. Good practice dictates working with a so-called online panel provider, which for a fee can customize the number and type of respondent desired. With these online panel providers the study can be done in a matter of hours.
- Once the study has been set-up, including the selection of the categories and elements (viz, questions and answers), the Mind Genomics platform creates combinations of these elements ‘on fly’, viz., in real time, doing so for each respondent who participates in the study. It is at the creation of the vignettes where Mind Genomics differentiates itself from other approaches. The conventional approach to evaluating a topic uses questionnaires, with the respondent present with stand alone ideas in majestic isolation, one idea at a time. The idea or topic might be a sentence, but the sentence has the aspects of a general idea, such as ‘How important is government funding for a citrus project.’ The goal is to isolate different, relevant ideas, focus the mind of the respondent on each idea, one at a time, obtain what seems to be an unbiased evaluation of the idea, and then afterwards to the relevant analyses to obtain a measure of central tendency, viz., an average, a median, and so forth. The thinking is straightforward, the execution easy, and the user presumes to have a sense of the way the mind of the respondent works, having given the respondent a variety of ‘sterile ideas’, and obtained ratings for each of the separate ideas.Figure 3 shows a sample vignette as the respondent would see it. The vignette comprises a question at the topic, a collection of four simple statements, without any connectives, and then the scale buttons on the bottom. The respondent is presented with 24 of these vignettes. Each vignette comprises a minimum of two and a maximum of four elements, in the spare structure shown in Figure 3. There is no effort made to make the combination into a coherent whole. Although the combinations do not seem coherent, and indeed they are not, after a moment’s shock the typical respondent has no problem reading through the vignette, as disconnected as the elements are, and assigning a rating to the combination. Although many respondents feel that they are ‘guessing,’ the subsequent analysis will reveal that they are not.
The vignettes are constructed by an underlying plan known as an experimental design. The experimental design for these Mind Genomics studies calls for precisely 24 combinations of elements, our ‘vignettes’. There are certain properties which make the experimental design a useful tool to understand how people think.
a. Each respondent sees a set of 24 vignettes. That set of vignette suffices to do a full analysis on the ratings of one respondent alone, or on the ratings of hundreds of respondents. The design is explicated in Gofman & Moskowitz.
b. The design calls for each element to appear five times in 24 vignettes and be absent 19 times from the 24 vignettes.
c. Each question or category contributes at most one element to a vignette, often no elements, but never two or more elements. In this way the underlying experimental design ensures that no vignette every present mutually contradictory information, which could easily happen if elements from the same category appeared together, presenting different specifics of the same type of information.
d. Each respondent evaluates a different set of vignettes, all sets structurally equivalent to each other, but with different combinations [13]. The rationale underlying this so-called ‘permutation’ approach is that the researcher learns from many imperfectly measured vignettes than from the same set of vignettes evaluated by different respondents in order to reduce error of measurement. In other words, Mind Genomics moves away from reducing error by averaging out variability to reducing error by testing a much wider range of combinations. Each combination tested is subject to error, but the ability to test a wide number of different combinations allows the user to uncover the larger pattern. The pattern often emerges clearly, even when the measurements of the individual points on the pattern are subject to a lot of noise.
The respondent who evaluates the vignettes is instructed to ‘guess.’ In no way is the respondent encouraged to sit and obsess over the different vignettes. Once the respondent is shown the vignette and rates it, the vignette disappears, and a new vignette appears on the screen. The Mind Genomics platform constructs the vignettes at the local site where the respondent is sitting, rather than sending the vignettes through the email.
When the respondent finishes evaluating the vignettes, the composition of the vignette (viz., the elements present and absent) is sent to the database, along with the rating (1-5, as show above) as well as the response time, defined as the number of seconds (to the nearest 100th) elapsing between the appearance of the vignette on the respondent’s screen and the respondent’s assignment of a rating.
The last pieces of information to be added comprise the information about the respondent generated by the self—profiling questions, done at the start of the study, and a defined binary transformation of the five-point rating to a new variable, called convenient R54x.. Ratings 5 and 4 (hitting nerve) were transformed to the value 100; . Ratings 3,2,1 (not hitting a nerve) were transformed to the value 0. To the transformed values 0 or 100, respectively, was added a vanishingly small random number (<10-5). The rationale for the random number is that later the ratings would be analyzed by OLS (ordinary least-squares) regression and then by k-means clustering, with the focus on the coefficients to emerge from OLS regression as inputs to the clustering. To this end it was necessary to ensure that all respondent data would generate meaningful coefficients from OLS regression, a requirement only satisfied when the newly created binary variables were all different from each other. Adding the vanishingly small random number to each newly created binary variable ensured that variation.
- The analysis of the ratings follows two steps once the ratings have been transformed to R54x. The first step uses OLS (ordinary least-squares) regression, at the level of the individual respondent. OLS regression fits a simple linear equation to the data, relating the presence/absence of the 16 elements to the variable R54x. The second step uses k-means clustering (Likas et. al., 2003) to divide the respondents into groups, based upon the pattern of the coefficients for the equation.
Table 1: Questions provided to the user by AI embedded in Idea Coach


Figure 1: Set up for the Mind Genomics study. Panel A shows the instructions to provide four questions. Panel B shows the input to Idea Coach. Panel C shows the first part of the output from Idea Coach, comprising six of the 15 questions generated. Panel D shows the four questions selected, edited, and inserted into the template.

Figure 2: Final steps in the set-up of the study. Panel A shows the rating scale; the user types in the rating question select the number of scale points, and describe each scale point. Panel B shows the short orientation at the start of the study. Panel C shows the request to source respondents.

Figure 3: Example of a four-element vignette, together with the rating question, the 5-point rating scale, and the answer buttons at the bottom of the screen.
The equation is expressed as: R54x = k1A1 + k2A2 … k16D4. The OLS regression program has no problem creating an equation for each respondent, based upon the prophylactic step of having added a vanishingly small random number to each transformed rating. That prophylactic step ensures that the OLS regression will never encounter the situation of ‘no variation in the dependent variable’, R54x.
Once the clustering has finished, the cluster program assigns each respondent first into one of two non-overlapping clusters, and second into one of three non-overlapping clusters. In the nomenclature of Mind Genomics these clusters are called ‘mind-sets’ to recognize the fact that they represent different points of view.
Table 2 presents the coefficients for the Total Panel, then for the two-mind-set solution, and then for the three-mind-set solution. Only positive coefficients are shown. The coefficient shows the proportion of time a vignette with the specific element generate a value of 100 for variable R54x. There emerges a large range in the numerical values of 16 coefficients, not so much for the Total Panel as for the mind-sets. This pattern of large difference across mind-sets in the range of the coefficients for R54x makes sense when we consider what the clustering is doing. Clustering is separating out groups of people who look at the topic in the same way, and do not cancel each other. When we remove the mutual cancellation through clustering the result is that all of the patterns of coefficients in a cluster are similar. The subgroup no longer has averages of numbers from very high to very low for a single element, an average which suppressed the real pattern. No longer do the we have the case that the Total Panel ends up putting together streams flowing in different directions. Instead, the strengths of different mind-sets becomes far more clear, more compelling, and more insights driven.
Table 2: Coefficients for the Total Panel, and then for the two-mind-set solution, and then for the three-mind-set solution, respectively.
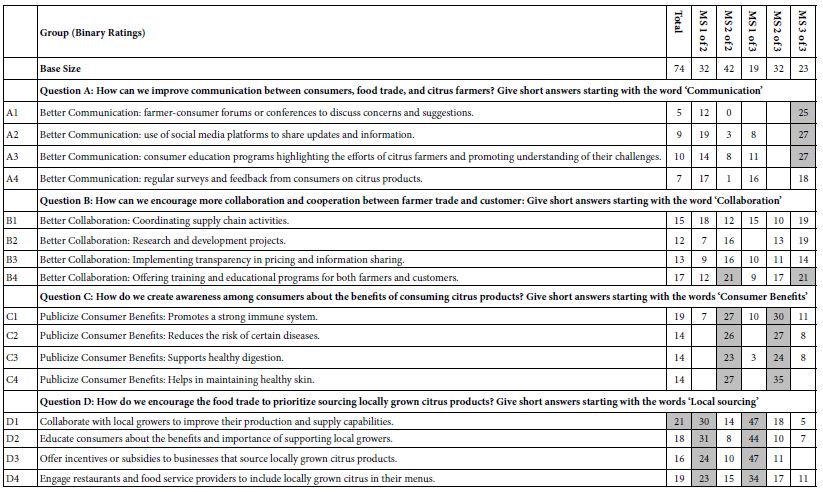
We focus here on the easiest take, namely, to interpret the mind-set. It is hard to name mind-sets 1 of 2 and 2 of 2. In contrast, it becomes far easier to describe the different mind-sets. We look only at the very strong coefficients; those score 21 or higher.
- Mind-Set 1 of 3-Focus on interacting with users, include local rowers, consumers, businesses which grow locally, and restauranteurs.
- Mind-Set 2 of 3-Focus on publicizing benefits to consumers.
- Mind-Set 3 of 3-Focus on communication.
Table 2 shows a strong consistency within the segments, a consistency which seems more art than science. The different groups emerge clearly, even though it would be seemingly impossible to find patterns among the 24 vignettes, especially recognizing that each respondent ended up evaluating a unique set of vignettes. The clarity of the mind-set emerges again and again in Mind Genomics studies, despite the continue plaint by study respondents that they could not ‘discover the pattern’ and ended up ‘guessing.’ Despite that plaint, the patterns emerging make overwhelming sense, disposing of the need of some of the art of storytelling, the ability to craft an interesting story from otherwise boring and seemingly pattern-less data. A compelling story emerges just from looking at what element are shade, for each mind-set. Finally, the reason for the clarity ends up being the hard-to-escape reality that the elements all are meaningful in and of themselves. Like the reality of the everyday, each individual element, like each individual impression of an experience, ‘makes sense’.
The Summarizer: Finding Deeper Meanings in the Mind-set Results
Once the study has finished, the Mind Genomics platform does a thorough ‘work-up’ of the data, creating models, creating tables of coefficients, etc. As part of this the Mind Genomics platform applies a set of pre-specified queries to the set of strong performing elements, operationally defined as those elements with coefficients of 21 or higher. The seemingly artificial lower limit of 21 comes from analysis of the statistical properties of the coefficients, specifically at what value of coefficient can user feel that the pattern of coefficients is statistically robust, and thus feel the pattern to emerge has an improved sense of reality. The Summarizer is programmed to write these short synopses and suggestions, doing so only with the tables generated by the Mind Genomics platform, as shown above in Table 2. Thus, for subgroups which generate no coefficients of 21 or higher, the Summarizer skips those subgroups. Finally, the summarizer is set up to work for every subgroups defined in the study, whether age, gender, or subgroup defined by the self-profiling classification question in which respondent profile themselves on topics relevant to the study.
Table 3 shows the AI summarization of the results for each of the three mind-sets. The eight summarizer topics are:
- Strong performing elements
- Create a label for this segment
- Describe this segment
- Describe the attractiveness of this segment as a target audience:
- Explain why this segment might not be attractive as a target audience:
- List what is missing or should be known about this segment, in question form:
- List and briefly describe attractive new or innovative products, services, experiences, or policies for this segment:
- Which messages will interest this segment?
Table 3: The output of the AI-based Summarizer applied to the strong performing elements from each of the mind-sets in the three-mind-set solution.







Part 2: AI as a Tool to Create New Thinking, Create New Hypotheses
During the past six months of experience with AI embedded in Idea Coach, a new and unexpected discovery emerged, resulting from exploratory work by author Mulvey. The discovery was that the squib for Idea Coach could be dramatically expanded, moving it beyond the request for questions, and into a more detailed request. The immediate reaction was to explore how deeply the Idea Coach AI could expand the discovery previously made. Table 4 shows the expanded squib (bold), and what the Idea Coach returned with later on. The actual squib was easy to create, requiring only that the user copy the winning elements for each mind-set (viz., elements with coefficients of 21 or higher). Once these were identified and listed out, squib was further amplified by a set of six questions. Idea Coach returned with the answers to the six questions for each of the three mind-sets, and then later did its standard analysis using the eight prompts. These appear in Table 4. It is important to note that Table 4 contains no new information, but simply reworks the old information. In reworking that old information, however, the AI creates an entirely new corpus of suggestions of insights. From this simple demonstration emerges the realization that the sequence of Idea Coach, questions, answers, results, all emerging in one hour or less for a set of 100 respondents or fewer, can be further used to springboard the investigations, and create new insights. These insights should be tested, but it seems likely that a great deal of knowledge can be obtained quickly, at very low cost, with no risk.
Table 4: AI ‘super-analysis’ of results from an earlier Mind Genomic study, revealing three mind-sets, and the strong performing elements for each mind-set.






Discussion and Conclusions
This paper began with a discussion of a small-scale project in the world of citrus, a project meant to be a demonstration to be given to a group at the citrus conference in September 2023. At that time, the Idea Coach had been introduced, and was used as a prompt for the study. It is important to note that the topic was not one based on a deep literature search of existing problems, but instead a topic crafted to be of interest to an industry-sector conference. The focus was not on science to understand deep problems, but rather research on how to satisfy industry-based needs. That focus explains why the study itself focuses on a variety of things that one should do. The focus was tactics, not knowledge. The former being said, the capability to accelerate and expand knowledge is still relevant, especially as that capability bears upon a variety of important issues. The first issue is the need to instill critical thinking into students [14,15]. The speed, simplicity, and sheer volume of targeted information may provide an important contribution to the development of critical thinking. Rather than giving students simple answers to simple questions, the process presented here opens up the possibility that the Idea Coach format shown here can become a true ‘teacher’, working with students to formulate questions, and then giving the students the ability to go into depth, in any direction that they wish, simply by doing an experiment, and then investigating in greater depth any part of the results which interest them. The second issue of relevance is the potential to create more knowledge through AI. There are continuing debates about whether or not AI actually produces new knowledge [16,17]. Rather than dealing with that issue simply in philosophy-based arguments, one might well embark on a small, affordable series of experiments dealing with a defined topic, find the results from the topic in terms of mind-sets, and then explore in depth the mind-sets using variations of the strategy used in the second part of the study. That is, once the user has obtained detailed knowledge about mind-sets for the topic, there is no limitation except for imagination which constrains the user from asking many different types of questions about what the mind-sets would say and do. After a dozen or so forays into the expansion of knowledge from a single small Mind Genomics project, it would then be of interest to assess the degree to which the entire newly developed corpus of AI-generated knowledge and insight is to be considered ‘new knowledge’, or simply a collection of AI-conjectures. That consideration awaits the researcher. The tools are already here, the effort is minor, and what awaits may become a treasure trove of new knowledge, perhaps.
References
- Butz EL (1989) Research that has value in policy making: a professional challenge. American Journal of Agricultural Economics 71: 1195-1199.
- Wang J Molina, MD, Sundar SS (2020) When expert recommendation contradicts peer opinion: Relative social influence of valence, group identity and artificial intelligence. Computers in Human Behavior 107, p.106278, https://doi.org/10.1016/j.chb.2020.106278
- Molina MD, Sundar SS, Le T, Lee D (2021) “Fake news” is not simply false information: A concept explication and taxonomy of online content. American Behavioral Scientist 65: 180-212.
- Dalalah D, Dalalah OM (2023) The false positives and false negatives of generative AI detection tools in education and academic research: The case of ChatGPT. The International Journal of Management Education 21: 100822.
- Brundage M, Avin S, Clark J, Toner H, Eckersley P, Garfinkel B, Dafoe A, Scharre P, et al. and Anderson H (2018) The malicious use of artificial intelligence: Forecasting, prevention, and mitigation. arXiv preprint arXiv: 1802.07228.
- Batarseh FA and Yang R (eds.) (2017) Federal data science: Transforming government and agricultural policy using artificial intelligence. Academic Press.
- Ben Ayed R, Hanana M (2021) Artificial intelligence to improve the food and agriculture sector. Journal of Food Quality, 1-7, ID 5584754 | https://doi.org/10.1155/2021/5584754
- Sood A, Sharma RK, Bhardwaj AK (2022) Artificial intelligence research in agriculture: A review. Online Information Review 46: 1054-1075.
- Taneja A, Nair G, Joshi M, Sharma S, Sharma S, Jambrak AR, Roselló-Soto E, Barba FJ, Castagnini JM Leksawasdi N, Phimolsiripol Y et.al (2023) Artificial Intelligence: Implications for the Agri-Food Sector. Agronomy 13: 1397.
- Harizi A, Trebicka B, Tartaraj A, Moskowitz, H (2020) A mind genomics cartography of shopping behavior for food products during the COVID-19 pandemic. European Journal of Medicine and Natural Sciences 4: 25-33.
- Porretta S, GereA, Radványi D, Moskowitz H (2019) Mind Genomics (Conjoint Analysis): The new concept research in the analysis of consumer behaviour and choice. Trends in Food Science & Technology 84: 29-33.
- Zemel R, Choudhuri SG, Gere A, Upreti H, Deite Y, Papajorgji P, Moskowitz H (2019) Mind, consumers, and dairy: Applying artificial intelligence, Mind Genomics, and predictive viewpoint typing. In: Current Issues and Challenges in the Dairy Industry (ed R, Gywali S, Ibrahim, T, Zimmerman), Intech Open, IntechOpen, IBSN: 9781789843552, 1789843553
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145.
- Guo Y, Lee D (2023) Leveraging chatgpt for enhancing critical thinking skills. Journal of Chemical Education 100: 4876-4883.
- Ibna Seraj, PM, Oteir I (2022) Playing with AI to investigate human-computer Interaction Technology and Improving Critical Thinking Skills to Pursue 21st Century Age. Education Research International, 2022. Article ID 6468995 | https://doi.org/10.1155/2022/6468995
- Schäfer MS (2023) The Notorious GPT: science communication in the age of artificial intelligence. Journal of Science Communication 22: Y02.
- Spennemann DH (2023) ChatGPT and the generation of digitally born “knowledge”: How does a generative AI language model interpret cultural heritage values? Knowledge 3: 480-512.