Abstract
Using a combination of the Mind Genomics platform BimiLeap.com and AI, the paper shows how one can rapidly explore ideas in today’s unstable world of political instability coupled with social instability. The paper shows by means of simulation how the investigator can identify a problem by using AI to create a ‘situation backgrounder’, and then use that backgrounder in turn to create classification questions about people, questions about responses to situations calling for betraying one’s country, and then answers to those questions. The questions never appear in the analysis, but simply act as guides to generate answers, which are presented as statements. Synthetic respondents, created by AI, are then exposed to vignettes comprising 2-4 of these above-mentioned answers. The respondents are also given personas by AI, as well as given different types of background instructions. The effort provides an instructional database showing how response classified as either ‘loyal’ or ‘tempted’ can be traced to the types of messages a person receives, the persona of the person created by AI, and finally the type of situation which prevails (e.g., public feelings shortly after DOGE, Department of Government Efficiency has made its cuts). The process is quick (hours and days), affordable (only costs are AI), and deep information, allowing the simulation to give a sense of what may happen.
Introduction
In President Trump’s second term as US President, he created DOGE. Dept of Governmental; Efficiency. The goal was to audit government expenditures and cut waste, doing so dramatically by firing people who had spent years and even decades as civil servants and as other ways of working for the US government. The outcome was that many government employees lost their jobs. There were, of course, negative feelings by the fired people (and others) towards the government. The topic here is to simulate what might be the actions of these disaffected, fired people, were they to be approached by individuals by another country to take money for selling what they know, and possibly learned during their tenure with the US government [1,3,7,8].
During this same period, research in the emerging science of Mind Genomics continued to show the ability of this science to understand the way people think about the topics of ordinary life and make decisions of the ordinary [4]. The Mind Genomics process of creating elements (messages) about a topic and combining these messages into vignettes according to an underlying plan called an experimental design ended up revealing many facets of how people think about topics. The strategy was to avoid having people ‘intellectualize’ about a topic. Rather, one would create simple combinations of messages, so-called vignettes, and have the respondent rate the vignette. The respondent was not challenged at all to defend the choice or even to verbalize the reasons for the choice of rating scale value for a particular vignette). The subsequent analysis, using standard statistical methods like regression and clustering, revealed in clear detail the criteria that the respondent used to rate the individual elements in the vignette [9,11].
The happy outcome of the above was a way to simulate the compound nature of reality. Much like in daily life, the respondent simply made decisions, almost without thinking. We should not be surprised at this behavior, and how natural it is easy. What is important comes down to the simple reality that here is a more natural way to measure thinking about a topic, and in fact one which is becoming increasingly cheaper, faster, and simpler from the user’s point of view.
A historical note is in order here: The original efforts began in the 1980’s, four decades ago. The process was simple although convoluted and effortful by today’s standards. In an era when the personal computer was starting, the researcher would assemble the material, usually sentences, but sometimes pictures. The user would then create one experimental design, with 2-3 times the number of fixed vignettes as elements. That is, the researcher might have 96 elements. The researcher would then create 192 combinations, which each element appearing 4-5 times across the 192 combinations. These combinations were fixed. The design was ‘tested’ ahead of time to make sure that it was amenable to analysis by OLS (ordinary least squares) regression [12]. The creation of one experiment allowed the researcher to manually check each vignette, each combination of elements, to make sure no vignette contained prohibited combinations, viz, elements which contradicted each other.
Today’s version of BimiLeap has evolved from those early days of forty years ago. Today’s version has evolved from a starting idea about 36 elements requiring 60 combinations or vignettes (4 categories, each with 9 elements), then 36 elements requiring 48 combinations or vignettes (6 categories, each with 6 elements), and finally today’s time- starved design of 16 elements requiring 24 combinations (4 categories, each with four elements).
Incorporating AI into the Process
AI interacts with Mind Genomics at least four levels, all ow which are currently available on the Mind Genomics platform, www. BimiLeap.com.
Step 1: Create a Backgrounder to Develop a Deeper Sense of the Topic
Our first step is to assemble information about the topic, more for general knowledge than for the framing of specific questions. Any of today’s LLM models, e.g., Chat GPT or Co-Pilot can provide a useful backgrounder to the topic. The backgrounder shown in Table 1 was developed by Microsoft’s LLM, Co-Pilot. The request was to provide a 10-paragraph composition on the likely feelings, opportunities and vulnerabilities of those civil servants who were summarily dismissed without cause from their jobs as part of the DOGE effort. As we will see below, this first effort need not be made, but it is advisable to do so just for the purposes of creating an overview of the topic.
Table 1: Using AI to create a general story.
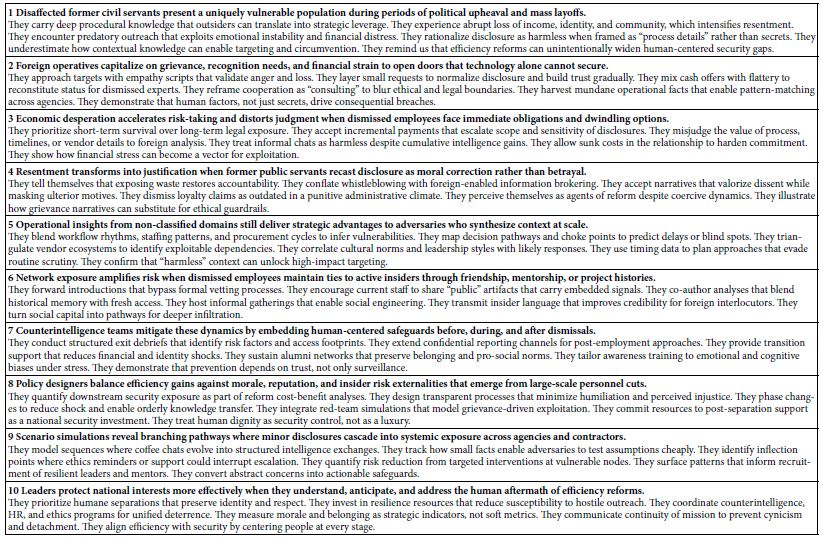
Moving beyond the orientation to the problem is using AI to sharpen one’s ideas about how the Mind Genomics approach should be used. Table 2 shows how Microsoft’s CoPilot provides a way to focus the user on what might be the most effective way to use Mind Genomics. The information in Table 2 is not necessary for the project and indeed was never codified in such a short form until AI was available. Table 2 may provide material already known to experts, but at the same time the user can benefit from a reiteration of basic ideas provided by reinterrogating AI.
Table 2: AI introduction to the process of Mind Genomics.

Step 2: Set Up the Mind Genomics Study
- Develop a series of questions which ‘tell a story’,
- For each question create four answers, the four answers (or elements) differing as much as possible from each other.
- Create up to 16 classification questions which allow the respondent to profile themselves.
- Create an introductory statement explaining the topic, and then provide rating scale.
The order of activities listed above has changed in different versions of the Mind Genomics program. `
Figure 1 (left panel) shows the first screen that the user fills. The left panel shows simply the name of the Mind Genomic study (really ‘experiment’) the language, and a disclaimer that no personal information will be taken.

Figure 1: User steps to set up a Mind-Genomics study (Panel A), and to create four questions (Panel B).
Panel B below shows the request for four questions. Up to the advent of LLM models such as Chat GPT, it was at this first step that the process often encountered is first resistance, and indeed many studies were aborted at this early stage. Panel B requests that the respondent generate four questions which tell a story. During the period of evolution, from approximately 1998 onwards, it seemed to be becoming increasingly harder for researchers, or at least those who wanted to use Mind Genomics, to come up with four questions which ‘told a story’ That observation, although subjective, corresponded to many people saying that they wished there were an easier way to develop these questions along. Indeed, by the year 2020 it seemed that Mind Genomics was destined to suffer a death because many prospective users felt simply that coming up with questions was beyond them. This observation tallies with the often- repeated observation by many that the thinking abilities of people seemed to be eroding.
Step 3: Generate the Four Questions Using AI
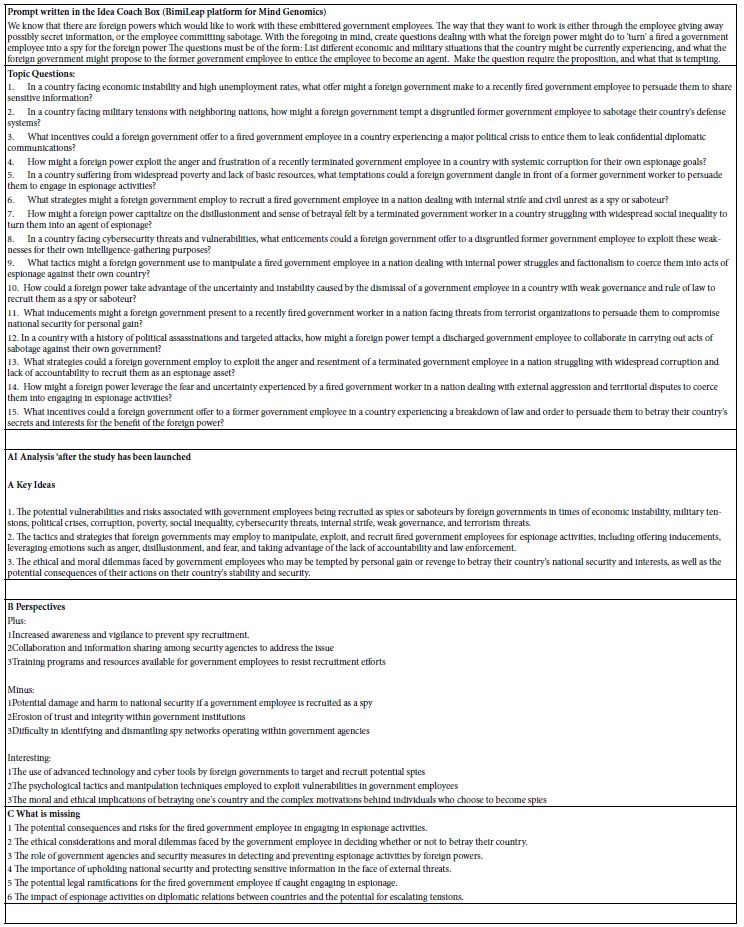
Figure 2 shows the Idea Coach section introduced in Figure 1. The left panel shows the request made to the AI embedded in the Idea Coach. The right panel shows the output from this initial iteration. Each iteration of the Idea Coach at this stage generates 15 different questions. The iterations may be repeated to generate a new set of 15 questions. Some of the questions will overlap. A strong introduction to the topic may emerge when the user runs many iterations, since later AI will analyze the output from AI, and offer new insights as Table 3 shows.

Figure 2: Idea Coach allowing user to write about the study (panel A), an intermediate output of 15 questions with the output comprising the first of possibly many iterations (panel B) and finally an example of four question finally selected from or even across several iterations (panel C).
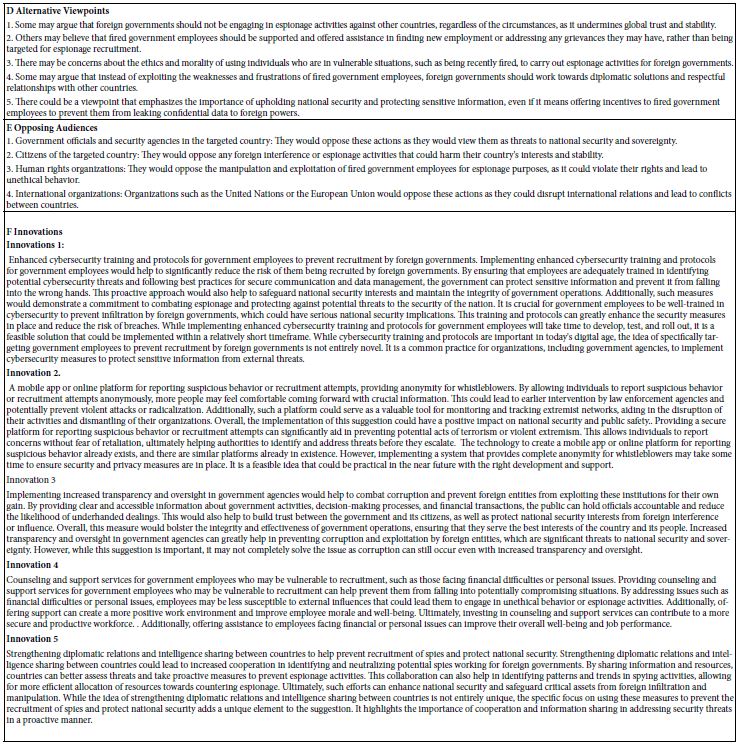
The actual output from the Mind Genomics set-up is much richer, with the analysis occurring as the study is being completed. An ‘iteration’ in the setup occurs when then the Idea Coach on the left is submitted. Table 3 shows the rich nature of the outcome, including the original input request the questions, as well as AI analysis of the output. The AI is once again Chat GPT.
Table 3: First iteration, viz., first set of questions generated by AI, based upon the information provided in the Idea Coach.
Step 4: Use AI to Guide Thinking about the Questions and Answers to Choose
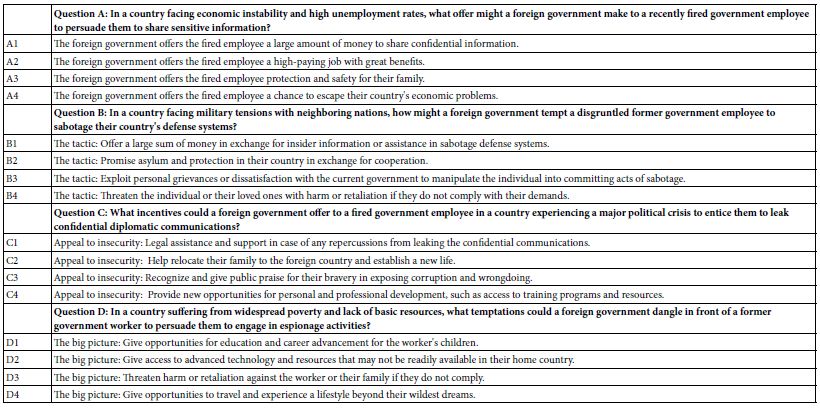
When AI was first incorporated into Mind Genomics in 2023, the principal use was to make researcher’s job less taxing, viz., by providing questions and then answers to the questions. Table 4 shows four questions generated by the AI in IDEA Coach, and for each question, four of the 15 answers further generated by Idea Coach. Table 4 need not contain questions from the same iteration. The BimiLeap program is set up so that the user can instruct the embedded AI to go through another iteration. Only when the user finally selects the four questions (from repeated iterations) and well as provides four answers to a specific question (from repeated iterations does the program move on.
The actual process to generate the questions and then select the answers was approximately 15 minutes, a speed unimagined even a decade ago. The actual study ended up being created in a matter of about an hour.
Table 4: The four questions and the four answers (elements) generated for the study.
Step 5: Create Self-proflling Questions as the Basis of ‘Personas’ to be Used by AI
It is by now a truism that people differ from each other. When working with Mind Genomics, whether using people or synthetic AI- created ‘personas’, it is instructive to find out about the respondent. This discovery may be about who the respondent IS, what the respondent DOES, how the respondent FEELS AND THINKS, etc. An efficient way to discover this information is to present the respondent with a closed end questionnaire, such as that shown in Table 5. The respondent, or in this case the AI, simply chooses the most appropriate answer for each question. To arrive at the nine questions shown in Table 5 we instructed AI to provide nine different questions that could describe a person involved in losing their job due to DOGE, and then for each question generate two radically different answers.
When people answer the questions in Table 5 we end with a sense of who they ‘are’. The thinking is different with AI. The AI program can be provided by a persona, created by an underlying program. In BimiLeap the underlying program randomly selects one of the three answers for each question in Table 5. The objective was to estimate the absolute contribution of answer in the subsequent analysis. It is for that reason that a final answer, “I cannot answer this question”, was added. With that type of answer, the AI ignores the topic in the creation of the persona.
Later, in the analysis, we will consider the contribution of the elements, as well as the contributions of the persona, to the rating. This analysis will allow us to understand the relative importance of the message versus of the nature of the ‘respondent, as a driver of the response.
Table 5: The nine questions used by AI to create a synthetic persona. The person emerged from the random (but ultimately balanced) choice of one answer from each question to generate the synthetic person.
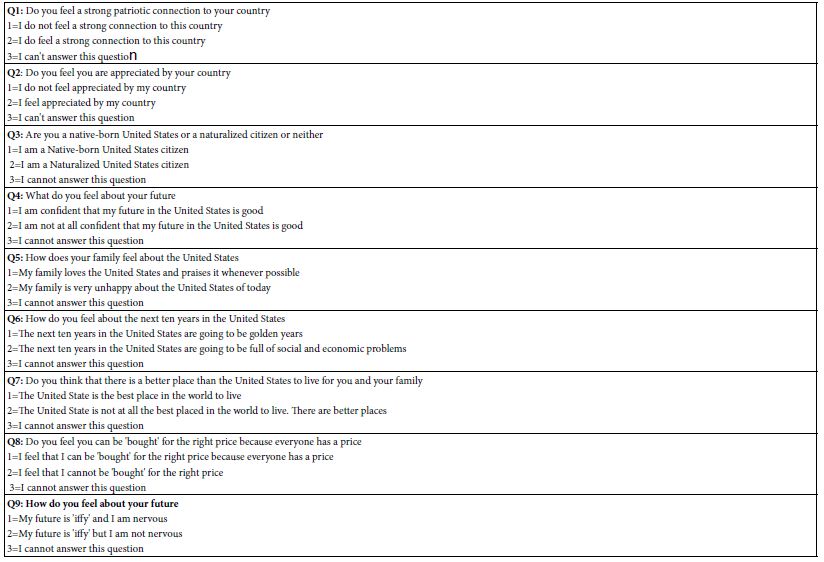
Step 6; ‘Orient’ AI in Terms of Four Introductions to the Situation, and the Five Point Rating Scale to Use to Evaluate the Vignettes
To obtain an even deeper understanding of how AI could integrate with Mind Genomics, we explored our different scenarios of introductions, with each introduction run in an experiment all its own. The top of Table 6 shows the four introductions, A-D. Introduction A talks about DOGE effort, combined with an upbeat mood. Introduction B talks about DOGE effort, with a downbeat mood. Introduction C talks about DOGE effort. All three introductions talk about foreign countries approaching laid-off government employees. Introduction provides no background at all but simply proceeds to the introduction about how to use the rating scale. The bottom of Table 6 shows the introduction to the vignettes, and the labelled five-point rating scale.
Table 6: The four introductions, one introduction for each of the four experiments and then introduction to the rating scale, and the five-point labelled rating scale.

Step 7: Prepare for Data Analysis by Regression by Specifying BDV’s (Binary Dependent Variables)
The original Mind Genomics studies were developed with a simple nine-point rating scale. The only labels were at the two extremes. The rationale for this form of scale was the popularity of top-and-bottom anchored scales in the world of applied science and consumer research. Author Moskowitz traces his roots to that field. The choice of a nine-point scale was based upon the belief that the respondents should have as much space on the scale to show the magnitude of their feelings.
Ongoing experience revealed that managers exposed to the research findings were uncomfortable with the scale. Most of the managers had been through business school, so they understood the general idea of the scale. The major problem emerging was that the scale simply could not be interpreted in a simple manner, as simple perhaps as the ‘no/yes’, is my product, my idea, even my vision ‘good’ or ‘bad.’ It became obvious that the precision to be offered by a scale did not give much to the users in terms of what the user of the scale information needed.
Rather than using the scale as a measure of magnitude, the easier approach, and one already in use by other researchers, was to divide the scale into regions, usually two regions. The common use of many researchers during the time that Mind Genomics was developing (2000 – 21010) was to use a simple, anchored 5-point scale [5,10]. Rather than searching for the so-called precision of the 9-point scale, and an ability to reveal differences, the effort recognized that five points were enough. Further practice by researchers was to divide the scale into two parts, and convert the scale to two points, for example so-called ‘Top 2’ (ratings of 5 and 4 converted to 100, ratings of 3,2, and 1 converted to 0),
The nice thing about this conversion is that it tells the researcher what percentage of the researchers can be said to agree with the idea, like the idea, etc. the specifical words to interpret Top 2 come from the anchors of the scale. The benefit for researchers of this change is that it moves the data to a form that can be analyzed by different statistical methods, whether to compute averages, or use as input in regression, or clustering.
Step 8: Run Study Once with Each Introduction, Using ‘Synthetic’ (AI-Created) Respondents
Once the user creates the test elements, the introduction, the rating scale, and if desired the self-profiling classification, the rest is left to the BimiLeap.com program. The user can select human respondents, or instruct the program to simulate respondents, viz., create synthetic respondents. Figure 3 shows the instructions for the user. The third selection allows the user to work with synthetic respondents, these respondents to be constructed by the combination of answers to the nine questions shown in Table 5.

Figure 3: Screen shot showing the choice of respondents given to the user. The third row shows the option to use AI-generated synthetic respondents.
Results
The Distribution of Ratings Across the Set of Four Studies
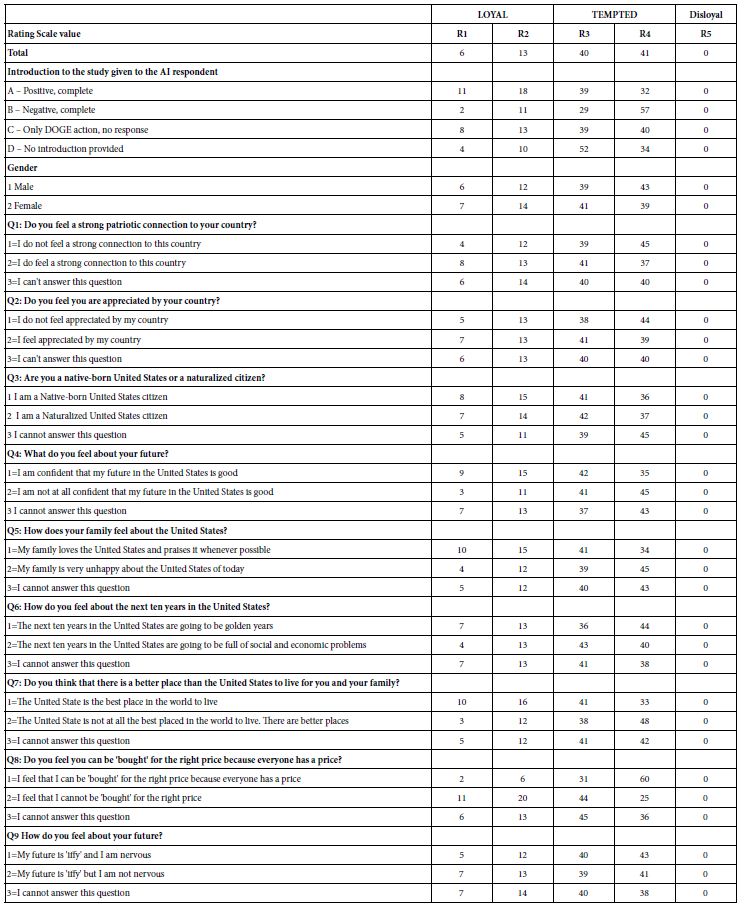
Our first analysis looks at the distribution of the five scale points across the different subgroups of usage. Table 7 shows the distribution of the five scale points for each classification statement. The classification statements were created to be independent of each other.
Across the total of four studies, each with 500 synthetic respondents, there were an altogether of 48,000 ratings (4 studies x 400 respondents/study x 24 vignettes/respondent = 48,000). Table 7 suggests that the AI did understand the meaning of the scales and chose rating 5 a vanishingly small number of times. Keep in mind that we are talking here about 48,000 independent decisions, with the AI presented with a persona, a scale, and then a vignette of 2-4 elements. A more fine-grained analysis would reveal further evidence that the synthetic respondents generated by AI make sense in terms of the linking of ‘who they are’ with what they end up rating.
The labelled 5-point can be divided into sections, one loyal (ratings 1 and 2), one disloyal (rating5), and one tempted (ratings 3 and 4). Table 7 reveals very few ratings of 5, viz., disloyal, but a substantial number of ratings for ‘tempted’ and a lesser but still substantial number of ratings for loyalty. For the remaining analysis we will consider two newly created BDV’s (binary dependent variables). R12 (Loyal) and R34 (Tempted).
Table 7: Distribution of ratings across the four sets of studies.
Relating the Presence/Absence of the 16 Elements to Positive Versus to Negative Responses
The use of an underlying permuted experimental design ensures that each synthetic respondent would test a different but appropriate set of 24 vignettes. The vignette comprises a specified combination of elements, at most one element or answer from each question, but with many vignettes comprising as few as two elements, and some vignettes comprising three elements. A vignette had at most one element or answer from a question. Across the 24 vignettes, each element appeared five times and was absent 19 times. Thus, a single question would contribute exactly one of its four answers to 20 or the 4 vignettes and be absent from the remaining four of the vignettes.
The above-mentioned design was modified so that each respondent would test a different set of 24 combinations. The mathematical structure of these 24 combinations was maintained from respondent to respondent. Only the specific combinations differed. This permutation scheme allowed the user to create individual-level models across respondents. The great benefit was the ability to analyze studies with few as well as with many respondents.
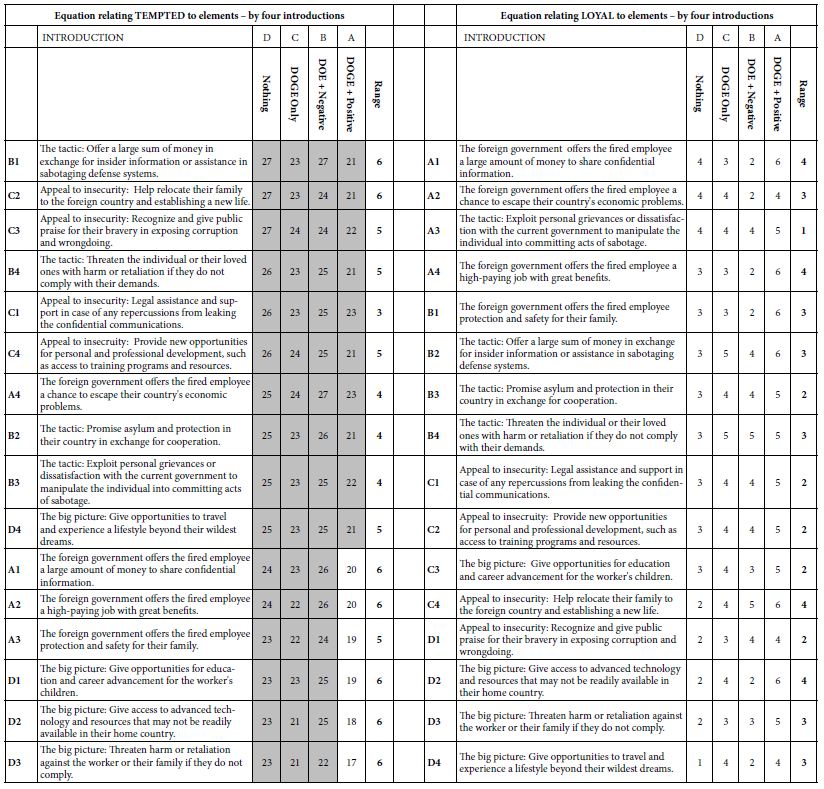
Our first analysis looks at contribution of the 16 elements to the two key BDVs, LOYAL (ratings of 1 or 2), or TEMPTED (rating 3 or 4). We eliminated rating 5 from consideration because it received vanishingly few ratings from the synthetic respondents. It is clear from Table 8A that the coefficients for Temptation are almost all high, with the cut-off of a coefficient of 21 being statistically significant (t statistic >2). Table further shows that the range of coefficients across the four introductions is usually quite small, a value of 6 or lower. Importantly, and quite remarkable, the coefficient for TEMPTED is highest when there is no introduction, and lowest for the introduction with presents DOGE along with the statement that the attitude of the citizen is upbeat, positive, and patriotic. We interpret this pattern to mean that for the same element, the most the country is described as positive and optimistic after DOGE has done its work, the (slightly) less tempting the element may be.
Table 8A: How the introduction and the elements interact to generate coefficients for equations relating the presence/absence of the 16 elements to ‘TEMPTED’ and ‘LOYAL’, respectively.
An ‘Integrative Model’ Incorporating Contributions of Messages, Introductions, and Feelings
Thus far the analysis has been of the 16 elements (A1-D4) as it has been affected by introduction to the synthetic respondent. We also know from Table 7 that there are differences in the patterns of ratings by WHO the respondent is (gender) and how the respondent profiles themselves (e.g., gender).
Our next analysis attempts to create a general, integrative model, using the variables for which there is a true zero, or for which a case can be made that variable has a meaningful zero. The model is straightforward. The independent variables are coded as ‘1’ if present, and ‘0’ if absent from the data. The elements were created by an underlying experimental design which ensured true 0’s. The first set of variables are the elements, specifically presence/absence of the elements in the vignette, with presence coded as 1, and absence coded as 0. The second set of variables are the three introductions (A, B, C) which present the DOGE action (all three introductions) as well as the emotional reactions (positive, negative, introductions A and B). The third set of variables are the nine self-profiling classification questions, each having three answers, two options, and the third option being the ‘zero’ case, presented as ‘I cannot answer this question).
Altogether, we have 16 elements, three introductions, and 18 self-profiling classifications, or 37 predictor variables. We have 2,000 respondents, each of whom provided 24 respondents on a scale which we define as either ‘loyal’ (ratings 1 and 2 transformed to 100; ratings 3,4, transformed to 0) or ‘tempted (ratings 3 and 4 transformed to 100, ratings 1 and 2 transformed t0 0). Rating 5 was entirely ignored in the analysis.
The integrated model provides a rapid way to understand the patterns in the data, and to uncover patterns that might have been missed because of the sheer volume of data (48,000 synthesized ratings). It may also be that the integrated model allows us insights that would otherwise be masked. Table 8B shows the integrated model for the Total Panel.
Table 8B: Integrated model for the total panel. The model relates relating the binary dependent variables of LOYAL and TEMPTED, respectively, to each of the elements, introductions, and self-descriptions of the way one feels. Only coefficients of +5 or higher are shown.
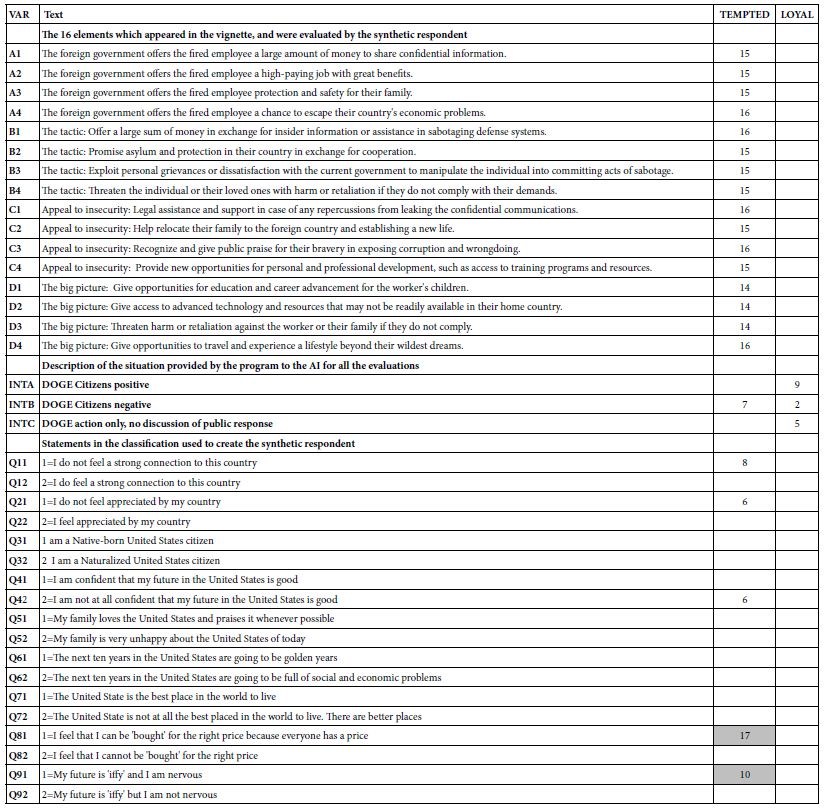
What drives loyal: No elements drive ‘loyal’
A positive reaction to DOGE and DOGE itself without any statement of citizen reaction
One specific answer in the self-profiling: Being native-born (Q31) and feeling the US is the best place to live (Q71)
What drives tempted: Most of the elements drive ‘tempted’, virtually to the same degree.
A negative reaction to DOGE in the introduction
Any of three specific answers in the self-profiling
I don’t know feel a strong connection to this country (Q11)
I do not feel appreciated by my country (Q21)
I am not at all confident that my future in the United States is good (Q42)
1=I feel that I can be ‘bought’ for the right price because everyone has a price.
Two Mind-sets and the Integrated Model Combining Elements, Personas, and Introductions
The final analysis of our data involves mind-set segmentation. A hallmark of Mind Genomics is at the level of granular experience; people differ from each other. These differences, once thought to be simply the intractable interpersonal variation which haunts ever study, turn out to be interpretable and important systematic differences between people in the way people evaluate the world of everyday. The differences end up pointing to the existence of so-called mind-sets, clusters of individuals with different ways of evaluating the stimuli of the everyday. It is not that all inter-individual variation can be traced to these mind-sets, but rather some part of the variation is due to systematic differences.
What these mind-sets are eds up emerging when we look at how people differ in what is important to them. The Mind Genomics process clusters respondents, dividing the full bank of respondents into smaller groups, based strictly on mathematical considerations. Once the respondents are divided into these smaller groups, it is straightforward to repeat the analysis on the different groups. These emergent groups, clusters in the language of statistics, are called mind- sets in the language of Mind Genomics.
Previous studies using the Mind Genomics method suggest that mind-sets abound in areas as diverse as food preferences, responses to legal issues, and the way one listens to one’s doctor and the type of information that drives patient compliance [2,6].
The Mind Genomics process lends itself to easy discovery of mind- sets. The process comprises the development of individual level models relating a specific BDV (binary defined variable) to the presence/ absence of the elements that were systematically varied. In this study we have 2000 respondents, each of whom evaluated the 16 elements combined into the 24 vignettes, with each respondent evaluating elements arranged in an experimental design. It is straightforward to create 2000 equations, one per respondent, to relate the 16 elements to Loyal (set 1) and then Tempted (set 2).
The first order of business is to create the BDV for each respondent. The BDV Loyal takes on the rating 100 when the original rating was 3 or 4. The BDV Tempted takes on the value 100 when the original rating was 1 or 2. Otherwise the BDV takes on the value 0. A vanishingly small number (<10-5) is added to every newly created BDV to ensure that there is some minimal level of variation in the BDV values when they serve as dependent variables in the regression which follows the transformation.
The foregoing modeling by OLS (ordinary least squares) regression generates two parallel sets of 2000 rows of coefficients, each row containing 16 coefficients with no additive constant. We can combine these two sets of data into one block of data of 2000 rows, one row for each respondent. In turn, the left side (columns 1-16) comprise the coefficients for Loyal, and the right side comprises the coefficients for the same respondent, this time for Tempted.
The next step in clustering uses so-called k-means clustering. The clustering program attempts to put the 2000 synthetic respondent into a minimal set of groups called clusters, or mind-sets in the language of Mind Genomics; The k-means algorithm does so by first computing the pairwise distance between every pair of the 2000 respondent. There are almost 4 million pairs of respondents. The distance between each pair is defined as (1-Pearson Correlation). In turn, the Pearson correlation is computed between every pair of respondents, based on the values of the 32 corresponding coefficients, the 16 coefficients for LOYAL and the 16 coefficients for TEMPTED.
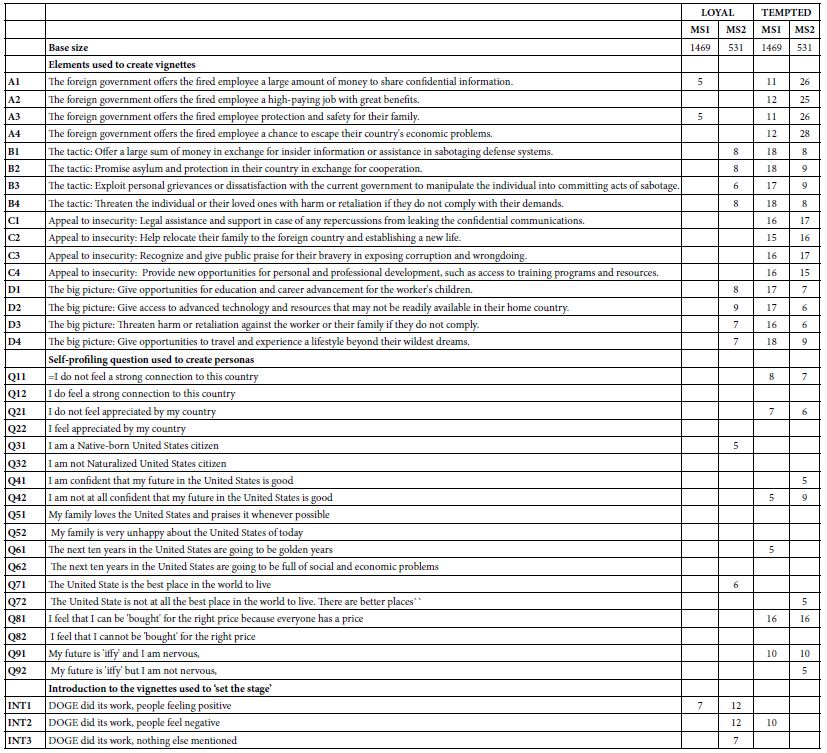
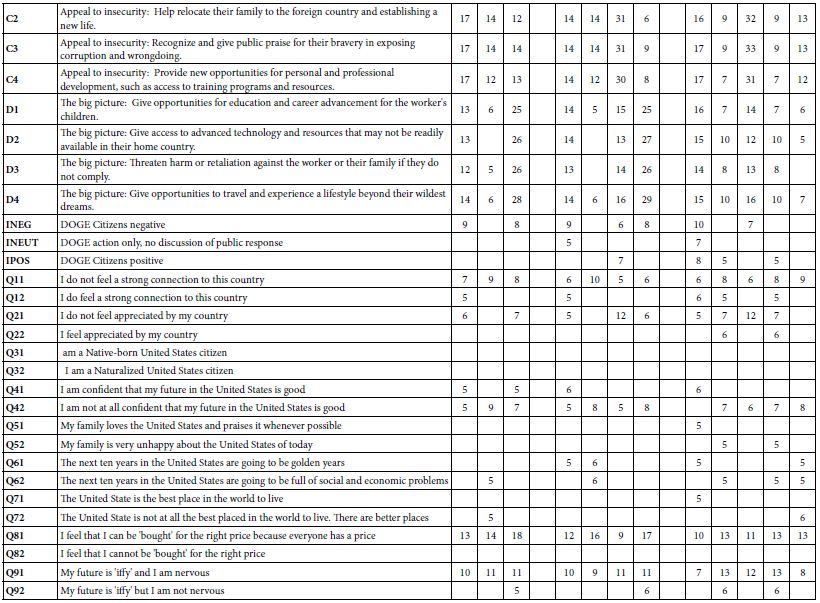
For exploratory purposes we begin with the two mind-sets, shown in Table 9. Mind-Se 1 comprises 1469 of the 2000 respondents, Mind-Set 2 comprise 531 of the 2000 respondents. Table 9 presents a great deal of data. To make the table easier to read we arbitrarily remove all coefficients of +3 or lower, leaving coefficients of 4 or higher. It is clear that the mind-sets differ dramatically on their reactions to LOYAL.
Table 9: The integrated model showing the coefficients from the single model incorporating predictors of the elements, the nine self-profiling questions to establish the persona, and the three introductions which ‘set the stage’. The table shows four integrated models, one for each pair of mind-set and BDV (loyal vs tempted).
Expanded Integrated Models for Three, Four, and Five Mind-sets
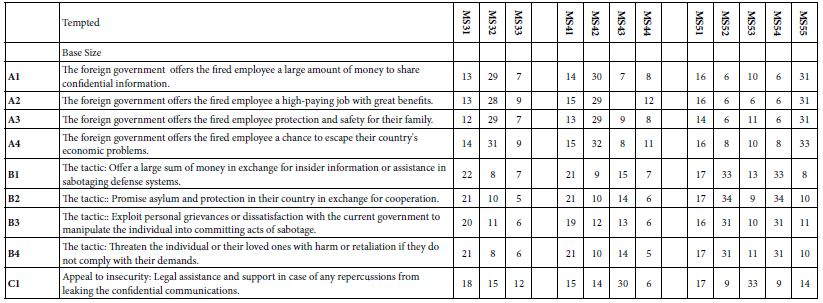
The final analysis in this exploration extracted three, four and then five mind-sets. The clustering program was precisely the same as done for the two-mind-set analysis. Table 10 shows the results. Once again, we remove any coefficients lower than 5. Table 10A shows the coefficient for LOYAL. Table 10B shows the coefficient for Tempted. Table 10 shows many more blank but also shows many higher coefficients. Furthermore, the mind-sets seem simpler in terms of the pattern of self-classifying questions, but more complex in terms of how the introduction fit into the model. The reader is invited to dive more deeply into the tables to extract additional insights about the way mind-set segmentation is influenced by personas developed by AI.
Table 10A: Coefficients for the integrated model for LOYAL, for three, four, and five mind-sets created through k-means clustering.
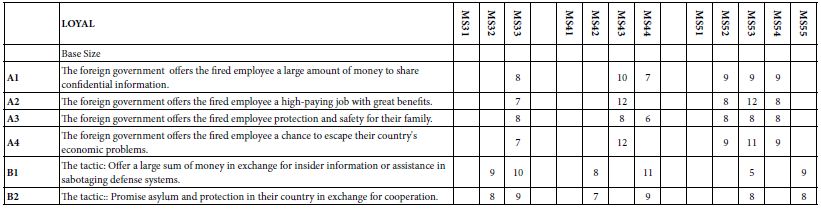
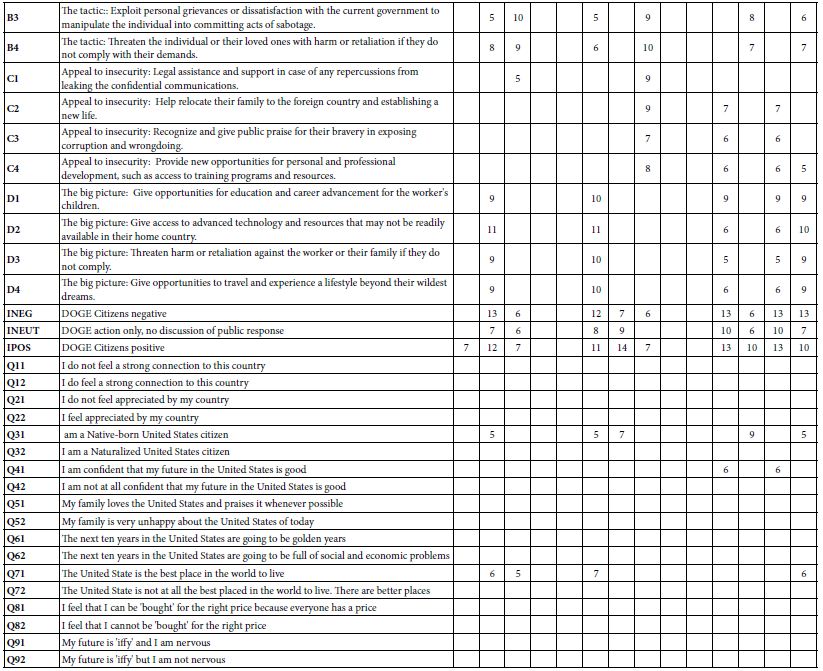
Table 10B: Coefficients for the integrated model for LOYAL, for three, four, and five mind-sets created through k-means clustering.
Discussion and Conclusions
This paper demonstrates, in example form, what might be learned about a totally new topic (effects of DOGE on loyalty vs temptation), doing so in the matter of a few hours, or at most a day or two. The approach merges the now standardized approaches used by Mind Genomics with the power of AI to synthetize personas and have those personas rate test stimuli (vignettes).
There are a variety of considerations, mostly positive, that should be kept in mind when evaluating the possible contribution of the approach presented here. These considerations range from today’s trends to today’s needs, and can be grouped into two major areas, ‘learning speed through simplicity’ and ‘learning from storytelling’.
Speed and Simplicity
1. Speed is the New Power in Learning
This approach teaches fast. A user can set up questions, answers, and stories in hours, not weeks. A child can test ideas about honesty in school rules and see results the same day. A police officer can test ideas about crime prevention and get insights before the week finishes. A political scientist can test ideas about public opinion and see patterns in one afternoon. Speed keeps attention strong. Speed makes learning exciting. Speed builds confidence.
2. Speed Builds Confidence
Fast results encourage learners. A student who sees patterns in one day feels proud. A police officer who sees insights in one week feels prepared. A researcher who sees trends in one afternoon feels informed. Speed keeps motivation high. Learners try repeatedly. Each cycle builds skill. Confidence grows with each fast success.
3. Simplicity is a Path to Increasing One’s Understanding
The system uses short stories called vignettes. Each vignette shows a situation and asks for a choice. This makes the lesson easy to follow. A teenager can read a vignette about loyalty and decide how they would act. A teacher can use vignettes to explain fairness without complex words. A police trainer can use vignettes to show how suspects might be tempted. Simple stories make hard issues clear. Simplicity opens the door to learning.
4. Simplicity Builds Trust
The system avoids complex math in the front view. Users see clear outputs like “loyal” or “tempted.” A student can understand without equations. A teacher can explain without formulas. A police officer can train without statistics. A researcher can share results without jargon. Simple outputs build trust. Learners believe what they see. Trust makes education strong.
5. Control Belongs to the Learner, and a Tool to Drive Education
The user decides the questions, the answers, and the scenarios. This control makes the process personal. A student can design questions about friendship. A researcher can design questions about corruption. A police officer can design questions about crime. Each user shapes the study to fit their interest. Control teaches responsibility. Control makes learning active, not passive. Control builds ownership of knowledge.
6. Control Builds Responsibility
When users design their own experiments, they learn to think carefully. A student who writes a question about honesty must decide what honesty means. A police officer who writes a question about crime must decide what crime means. A researcher who writes a question about loyalty must decide what loyalty means This reflection teaches values. Responsibility grows with control. Learners become thoughtful.
7. Education Can Inspire Better Action
Learning should not stop at knowledge. It should lead to wise choices. Simulation makes issues vivid, simple, and under user control. A student learns to act fairly. A police officer learns to act carefully. A researcher learns to act responsibly. Each user sees choices clearly. Each user imagines better futures. Education inspires action. Action makes society stronger.
Stories Teach Better than Simple Facts, Engaging Creativity and Thinking
8. Stories Build Memory
People remember stories better than lists of facts. A vignette about a worker facing temptation sticks in the mind. Later, the learner recalls the lesson about loyalty and risk. A student remembers the story about cheating. A police officer remembers the story about bribery. A researcher remembers the story about betrayal. Stories make lessons last. Memory grows stronger with stories.
9. Stories Bring Issues to Life
Numbers alone do not move the heart. Stories make issues real. A vignette about a fired worker tempted to share secrets feels alive. Readers imagine the worker’s choice and feel the tension. A child reading about a friend tempted to cheat feels the same pull. A police officer reading about a suspect tempted by money feels the risk. A political scientist reading about citizens tempted by anger feels the danger. Stories make lessons stick in memory.
10. Creativity Grows from Mixing Ideas
The system combines different answers into new vignettes. This mixing creates surprises. A student may see that anger plus money creates more risk than sadness plus flattery. A police officer may see that fear plus friendship creates more temptation than greed alone. A researcher may see that pride plus recognition creates stronger loyalty than rules alone. These surprises spark imagination. Creativity grows when people see new patterns. Mixing ideas makes learning playful and deep.
11. Young Learners can Explore Society
Teenagers curious about politics can use the system to test ideas. They can design questions about fairness, loyalty, or justice. They can see how synthetic personas respond. This builds civic awareness. A student may learn that anger leads to rash choices. Another may learn that kindness builds trust. These lessons prepare young people to think about society. Simulation gives them a safe way to explore big issues.
12. Simulation Teaches Without Danger
Real experiments with betrayal or crime would be unsafe. Simulation avoids risk. AI creates synthetic respondents who act like real people. Learners can explore sensitive topics safely. A student can study cheating without hurting classmates. A police officer can study bribery without risking real cases. A researcher can study espionage without touching secrets. Simulation makes dangerous lessons safe. Safety allows bold exploration.
13. Law Enforcement can Train with Realism
Police and security teams face real temptations and risks. Simulation lets them practice safely. They can design vignettes about suspects offered money or friendship. They can see how synthetic personas respond. This prepares them for real cases. A police officer may learn that suspects often justify betrayal as harmless. Another may learn that suspects respond strongly to flattery. These lessons improve training. Simulation builds readiness.
14. Political Scientists can Map Ideas
Researchers study how public opinion shifts. Simulation helps them test scenarios. They can design vignettes about economic crises or foreign threats. They can see how synthetic groups respond. This shows patterns of social change. A researcher may learn that fear increases loyalty. Another may learn that anger increases betrayal. These insights help predict society’s future. Simulation gives political science new tools.
15. Simulation Builds Bridges
The same tool works for young learners, police, and scholars. This connects groups. A high school project and a government training can use the same platform. A college class and a research lab can share methods. A police academy and a university can compare results. This shared method builds common understanding. Bridges grow between groups. Simulation unites society.
Acknowledgments
The authors would like to acknowledge the extensive use of AI (specifically Microsoft CoPilot) as an assistant helping to frame the ideas. The use of AI provides a way to incorporate an ‘objective’ way to help structure the data. The AI was extensively ‘trained’ on the Mind Genomics and Psychophysics publications of author Moskowitz, publications appearing from 1990 onwards.
The authors would like to thank Vanessa M. Arcenas for her ongoing participation as coordinator and editor of these efforts regarding Mind Genomics and its intersection with Psychophysics and with AI, respectively.
References
- Chohan UW (2025) DOGE A Public Value Critique SSRN.
- Coussa A, Bellissimo N, Poulia K-A, Karavetian M (2024) Use of mind genomics for public health and wellbeing Lessons from COVID 19 Advances in Biomedical and Health Sciences. [crossref]
- Gentry JA (2025) Strategic warning intelligence Revival Comparative Strategy. [crossref]
- Gere A, Papajorgji P, Moskowitz H, Milutinovic V (2019) Using a Rule Developing Experimentation Approach to Study Social Problems The Case of Corruption in International Journal of Political Activism and Engagement. [crossref]
- Gofman A, Moskowitz HR (2010) Isomorphic Permuted Experimental Designs And Their Application In Conjoint Analysis. Journal of Sensory Studies. [crossref]
- Harizi A, Trebicka B, Tartaraj A, Moskowitz H (2020) A mind genomics cartography of shopping behavior for food products during the covid-19 23rd International Conference on Multidisciplinary Studies Resilience for Survival.
- Makridis C (2025) Overcoming the Federal Talent Gap Evidence from Special Governmental Employees and Other Pathways SSRN.
- Monahan T (2025) Surveillance in Trump’s Surveillance & Society. [crossref]
- Moskowitz H, Kover A, Papajorgji P (2022) Applying Mind Genomics to Social IGI Global. [crossref]
- Moskowitz H, Wren J, Papajorgji P (2020) Mind Genomics and the LAP LAMBERT Academic Publishing. [crossref]
- Papajorgji P, Moskowitz H (2022) The ‘Average Person’ Thinking About Radicalization A Mind Genomics Cartography. Journal of Police and Criminal Psychology. [crossref]
- Zdaniuk B (2014) Ordinary Least-Squares OLS Model Encyclopedia of Quality of Life and Well-Being Research. Springer Netherlands.